Ch17 多模态与生成¶
Agent 的眼睛和耳朵:视觉、语音、视频理解与生成
本章收录 30 篇实体,按深度递增排列。
本章导航¶
| Level | 含义 | 篇数 |
|---|---|---|
| ⭐ 入门 | 零基础可读 | 3 |
| ⭐⭐ 工程师 | 需编程基础 | 9 |
| ⭐⭐⭐ 专家 | 需ML基础 | 17 |
| ⭐⭐⭐⭐ 科学家 | 需研究背景 | 1 |
导读¶
纯文本 Agent 只是起点——多模态让 Agent 能真正"感知世界"。
本章覆盖多模态 AI 的核心领域:视觉理解(DeepSeek 的指代精度论文)、音频生成(Xiaomi Dasheng 通用声音基座模型)、视频质量评估(Netflix VMAF)、3D 生成(Gaussian Splatting)、以及文档解析(logics-parsing-v2)。
多模态不只是"给模型加个图片输入"——不同模态的对齐、融合、生成,每一个都是独立的研究领域。
这是通往具身智能的必经之路。
Ch17.001 Perceptron Mk1 shocks with highly performant video analysis AI model 80-90% cheaper than Anthropic, OpenAI & Google¶
📊 Level ⭐ | 9.0KB |
entities/perceptron-mk1-video-analysis-ai.md来源:原文存档
Summary¶
Perceptron Mk1 is a video analysis reasoning model priced at $0.15/$1.50 per million input/output tokens — 80-90% cheaper than Claude Sonnet 4.5, GPT-5, and Gemini 3.1 Pro — while achieving state-of-the-art performance on spatial reasoning (ER Benchmarks) and video benchmarks (EgoSchema, VSI-Bench). The model's core differentiation is "Physical Reasoning": understanding cause-and-effect, object dynamics, and the laws of physics in real-world video.
Key Points¶
- Video analysis AI model with "Physical Reasoning" capabilities
- Cost advantage: 80-90% cheaper than major providers ($0.15/$1.50 per million tokens)
- High performance: ER Benchmarks 85.1 (EmbSpatialBench), 72.4 (RefSpatialBench); EgoSchema 41.4, VSI-Bench 88.5
- Architecture: Native video processing at 2 FPS across 32K token context window
- Dual licensing: Closed-source Mk1 (API) + open-weight Isaac series
- Target: Industrial-scale physical AI applications → 原文存档
相关实体¶
- Google's Gemini Omni video model surfaces ahead of I/O debut
- Google's Gemini Omni video model surfaces ahead of I/O debut
- Anthropic Computer Use 最佳实践
深度分析¶
「效率前沿」:新的竞争维度¶
Perceptron 的核心市场定位是「Efficiency Frontier」——一个以「视频/embodied reasoning 平均分数」为 Y 轴、「每百万 token 混合成本」为 X 轴的象限图。 这一定位揭示了一个关键趋势:AI 模型的竞争正在从「单纯性能」向「性价比」迁移。Frontier 模型(如 GPT-5、Gemini 3.1 Pro)在原始性能上仍然领先,但 Mk1 的策略是在「足够好」的推理质量上大幅压低价格。 对于企业采购决策,这意味着视频理解模型的评估框架需要重新设计:不再只看 SOTA 分数,而是在特定用例下评估「性能/成本比」。
Temporal Continuity:视频理解的核心技术突破¶
传统 Vision-Language Models (VLMs) 将视频处理为「离散图像序列」,而 Mk1 的架构设计强调「temporal continuity」—— 这使其能够在物体被遮挡时维持身份一致性。 关键技术规格:
- 视频处理速度:2 FPS
- Context window:32K tokens
- 支持像素级定位(pixel-precise pointing)和计数(可达数百) 这种能力对机器人(robotics)和监控(surveillance)应用至关重要——这些场景需要模型「追踪」场景中物体的持续存在,而非仅识别单帧内容。
Physical Reasoning:超越模式识别¶
Perceptron 强调的「Physical Reasoning」是比标准视觉理解更高级的能力——模型需要理解物体运动规律和物理因果关系。 文章给出的例子:判断篮球投篮是在蜂鸣器响之前还是之后,需要联合推理「球在空中的位置」和「计时器读数」。这超越了纯粹的模式识别,要求模型具备对「物理定律」的理解。 这是「Physical AI」与「Digital AI」的本质区别:数字 AI 可以在离散 token 空间运行,而物理 AI 必须处理连续的时间-空间动态。
创始团队的技术谱系¶
Perceptron 的创始人背景清晰指向 Meta 的研究脉络:
- Chameleon (May 2024):早期融合的 mixed-modal 模型家族,被 Perceptron 描述为自身模型的 lineage 之一
- MoMa (July 2024):更高效的 early-fusion 训练方法 这意味着 Perceptron 并非从零开始,而是直接继承了 Meta 核心团队的多年研究成果。这种「research lineage → startup」的路径在 AI 领域越来越常见。
定价策略:工业级可及性¶
Mk1 的定价($0.15/$1.50 per million tokens)处于「Lite」价格区间,但性能对标「Pro」级别。 这个策略的目标市场是:
"large-scale industrial use rather than just experimental research" 对于工业用户(制造质量检测、机器人训练数据标注、安防监控),这种成本结构使 AI 视频分析首次具备了规模化部署的经济可行性。
实践启示¶
对计算机视觉/机器人产品经理¶
- 重新评估视频理解供应商:如果你的产品需要 2 FPS + 32K context 的视频分析能力,Mk1 的定价策略值得 POC 验证。80-90% 成本优势对预算敏感的大规模部署是决定性的。
- Physical Reasoning 用例筛选:不是所有视频理解任务都需要「物理推理」能力。对于需要理解物体因果关系、追踪跨遮挡物体身份、读模拟仪表等场景,Mk1 的架构优势明显;对于简单分类/检测任务,常规 VLM 可能足够。
- Temporal continuity 需求评估:如果你的用例需要「即使物体暂时离开画面也能保持追踪」(如多人场景中的身份维护),考虑支持 temporal continuity 的模型。
对 AI 基础设施团队¶
- 边缘部署选项:Isaac 0.2-2b-preview 专门优化至「sub-200ms time-to-first-token」,适合实时边缘设备。 如果你的场景有实时性要求,这是比 Mk1 API 更好的选择。
- 自托管 vs API 成本对比:Mk1 API 定价约 $0.30 blended cost。如果你的用量足够大(每月数十亿 token),自托管 Isaac 模型可能更经济——但需要评估运维复杂度和 6-12 个月的能力差距。
- 混合架构:对于高价值帧使用 Mk1 API 进行精确分析,同时用 Isaac 边缘模型处理实时筛选,可以实现质量和成本的平衡。
对创业者和投资人¶
- Physical AI 是真实的细分市场:Perceptron 明确聚焦「physical world AI」,而非泛化的「多模态」。对于 AI 创业公司,这指明了一个差异化路径——避开与 Frontier Labs 在通用能力的正面竞争,在物理世界理解这一细分领域建立壁垒。
- 开源权重 + 商业许可的双轨策略:Isaac 系列开放权重但提供商业许可。 这种模式允许生态参与者低成本实验,同时 Perceptron 通过工业客户获得收入。评估任何「开源模型 + 商业化」机会时,注意这种双轨结构的可持续性。
- 关注「每任务成本」而非「每 token 成本」:文章警告,reasoning models 消耗 10-100x 更多 token。评估 AI 视频分析的真实成本时,应该测量端到端任务(如「分析一小时监控视频并标记异常」)的总体 token 消耗,而非单纯比较 $/token。
对研究人员¶
- Benchmark 验证:Mk1 在 EmbSpatialBench (85.1)、RefSpatialBench (72.4)、EgoSchema Hard Subset (41.4)、VSI-Bench (88.5) 上的分数需要独立验证。 关注这些分数是否在公开标准 dataset 上可复现。
- Meta 嫡系技术的跟随:Perceptron 的技术路径来自 Chameleon 和 MoMa,这意味着 Meta 的某些研究思想可能已经在商业化上领先。如果你的研究与 early-fusion multimodal 或 efficient training 相关,关注 Perceptron 的技术博客可能获得 insight。
Ch17.002 ImageToVideoAI - #1 Image to Video AI Generator Online¶
📊 Level ⭐ | 4.5KB |
entities/imagetovideoai-generator.md
核心要点¶
- 上传即动画 — 将静态图片转换为视频,支持 JPG/PNG/WebP
- 多种动画风格 — 视差效果、缩放平移、肖像动画等多种预设
- 分辨率选项 — 多种分辨率输出,适应不同平台需求
- 商业授权 — 生成视频含商业使用权
- 速度 — 云端处理,分钟级完成
技术洞察¶
AI 图像转视频的民主化: ImageToVideo.ai 代表了 AI 生成媒体的一个具体方向:静态图像的动态化。 技术意义: 1. 降低视频创作门槛 — 无需昂贵设备或技术技能即可制作视频内容 2. 内容创作加速 — 社交媒体和营销内容生产效率大幅提升 3. 商业应用场景 — 商业授权使企业营销应用成为可能 技术局限:
- 质量可能不如专业视频制作
- 动画效果受限于输入图像质量
- 创意控制有限 这是 AI 工具民主化趋势的一个案例,使小企业和个人能够访问以往只有大型制作公司才能获得的视频制作能力。
深度分析¶
ImageToVideo.ai 代表了 AI 生成媒体民主化的一个具体方向:静态图像的动态化。 这类工具的核心价值主张不是"替代专业视频制作",而是"让非创作者也能做视频"——降低的是技能门槛和资金门槛,而非质量上限。 从技术成熟度看,Image-to-Video 赛道正处于"可用但有限"阶段。与 Text-to-Video(Sora、Runway)不同,静态图生视频的关键约束是输入图像本身的质量和构图,而非模型的生成能力上限。如果输入图像构图混乱、主体不明确,即使最强模型也难以生成有意义的动画。这决定了该类工具更适合结构化素材(产品图、肖像图、平面设计图),而非随意拍摄的照片。 商业层面的观察:商业授权是该工具定价策略的关键差异化。内容创作工具的免费增值模式(Freemium)已经饱和,但商业授权的清晰化是 B2B 采购的关键——企业需要明确的版权合规保障,这让"商业授权包含在内"成为企业采购决策的正向信号。 对 AI 视频赛道竞争格局的影响: Image-to-Video 本质上是 Text-to-Video 的上游依赖——很多专业视频工作流的前置步骤是把静态素材视频化。随着 GPT-Image-2 等多模态模型同时支持图像生成和视频生成,未来"静态图像 → 视频"和"文本 → 视频"可能合并为统一的多模态生成 pipeline,这对 Luma AI、Kling等专业图生视频工具构成压力。
实践启示¶
对内容营销团队: ImageToVideo.ai 适合用于社交媒体内容的规模化生产(产品展示、日常分享的动态化),而非品牌级视频制作。最佳使用场景:已有的高质量产品图/海报,通过工具添加视差/缩放平移效果,快速生成短视频脚本素材。 对开发者: 如果你正在构建一个涉及内容生成的 AI 应用,需要评估图生视频作为中间步骤的必要性——是用户真正需要视频,还是 GIF/交互式动画也可以满足需求?视频的后期处理成本(字幕、转场、音效)往往比生成本身更耗时。 对企业采购者: 关注工具的输出格式和分辨率选项——不同的社交平台(Instagram、TikTok、LinkedIn)对视频规格有不同的要求。能直接输出多种分辨率的工具减少后期转码的工作量。 ^[(来源:raw)] → [(来源:raw)]
相关实体¶
→ 原文存档
Ch17.003 FLAT: Feedforward Latent Triangle Splatting¶
📊 Level ⭐ | 2.8KB |
entities/flat-feedforward-latent-triangle-splatting.md
FLAT: Feedforward Latent Triangle Splatting¶
Background: Google Research + Oxford VGG + TU Munich, 2026-06-24. A new approach to 3D scene reconstruction that maps video diffusion latents directly to surface-aligned triangle splats in a single forward pass.
Core Innovation¶
From Gaussians to Triangles¶
Traditional 3D Gaussian Splatting (3DGS) uses volumetric primitives that can produce floaters and lack geometric accuracy. FLAT proposes a fundamentally different approach:
- Triangle splats instead of volumetric Gaussians
- Surface-aligned representation that better captures actual geometry
- Single forward pass from video diffusion latents to explicit scene parameters
Architecture¶
Video Diffusion Latents
|
v
FLAT Decoder (single forward pass)
|
v
Triangle Splats (position, orientation, color, opacity)
|
v
Standard Triangle Rasterizer
|
v
Rendered Views
Key Technical Contributions¶
- Latent-to-Triangle Mapping: Directly maps compressed video diffusion latents to explicit non-volumetric scene parameters
- Geometric Accuracy: Triangle primitives naturally align with surfaces, reducing floaters and improving geometry
- Rendering Efficiency: Compatible with standard triangle rasterization pipelines (OpenGL, Vulkan)
- Competitive Visual Quality: Maintains visual quality comparable to Gaussian splatting while significantly improving geometry
Comparison with Existing Approaches¶
| Method | Primitives | Geometry | Rendering | Speed |
|---|---|---|---|---|
| NeRF | Implicit | Good | Slow (ray marching) | Slow |
| 3DGS | Volumetric Gaussians | Fair | Fast (splatting) | Fast |
| FLAT | Triangle Splats | Excellent | Fast (rasterization) | Fast |
Implications for 3D/AI Research¶
- Video-to-3D pipeline simplification: Single forward pass eliminates multi-step optimization
- Better geometry for robotics/AR: Surface-aligned representation is more suitable for physical applications
- Standard rendering pipeline: No custom splatting renderer needed
Related¶
Ch17.004 Xiaomi Dasheng — 通用声音基座模型 5 阶段工程实践¶
📊 Level ⭐⭐ | 17.2KB |
entities/xiaomi-dasheng-audio-foundation-model-2026.md
概述¶
Xiaomi Dasheng 是小米发布的通用声音基座模型——让一个模型同时听懂语音、环境声和音乐。从一台 8 卡机器起步,经过 MAE 预训练 → 大规模数据工程 → 6 维标注语义拓展 → DashengTokenizer 理解+生成统一 五个阶段,把音频领域从"语音 / 声音 / 音乐三套独立模型"推进到"通用声音基座 + 通用描述 + 统一架构"。
核心数字:300T 原始数据 / 146 包 / 1 年搬运 / 1 机 8 卡训练 / Base 86M (78.88) → 1.2B (81.25) / 音频标记首次突破 AudioSet 50+ mAP / MiDashengLM 22 SOTA / TTFT 1/4 / 吞吐 20x。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
核心洞察:3 个反直觉判断¶
1. 增量优化 vs 底层重建 = 方向差异,非程度差异¶
增量优化和底层重建不是程度的差异,是方向的差异。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"] 预研的价值之一,是帮团队识别什么时候该换方向。
实证:已有的语音识别路径在特定任务上做增量优化,可以做到极致,但做不到通用声音理解——必须从底层重建。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
2. 更高的训练损失 = 更丰富的学习信号¶
| 训练任务 | 损失 | 学习信号 |
|---|---|---|
| ASR 训练 | 低 | "从左到右"简单映射,学到的东西可能比较有限 |
| 通用音频描述 | 高 | 融合语音摘要 / 环境声描述 / 音乐描述,需要理解更复杂的语义 |
在通用音频理解中,更高的训练损失可能意味着更丰富的学习信号。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"] 损失值本身不说明全部问题,损失在度量什么可能更值得关注。
3. 挑战行业假设是为了搞清楚它的边界¶
挑战行业假设不是为了推翻它,而是为了搞清楚它的边界在哪里。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"] DashengTokenizer 的价值不是否定了 VAE,而是证明了 VAE 不是唯一解。
5 阶段技术栈¶
阶段 1:MAE(掩码自编码)预训练¶
关键决策:选择 Meta 的 MAE 框架(视觉领域 → 音频迁移),而非在已有语音识别路径做增量改进。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
| 维度 | MAE 思路 |
|---|---|
| 原理 | 把音频频谱部分遮掉,让模型补全被遮挡区域 |
| 优势 | 模型被迫学习声音的本质结构,而非特定任务的表面特征 |
| 结果 | 通用声音表征,不针对任何单任务优化 |
判别式 vs 生成式编码器(GLAP 实验): ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
| 编码器类型 | 语音 | 声音 | 音乐 |
|---|---|---|---|
| 判别式(CED / Beats) | 偏科 | ✅ | ✅ |
| 生成式(Xiaomi Dasheng) | ✅ | ✅ | ✅ |
判别式编码器针对特定任务优化,遇到语音就"偏科";生成式编码器通过"补全被遮挡的频谱"学到更本质的音频结构,三大领域都能兼顾。
阶段 2:大规模数据工程¶
工程挑战¶
| 维度 | 数据 |
|---|---|
| 原始数据量 | ~300T(几百万小时) |
| 存储 | 严重不足 |
| 分包 | 146 个包(语音/音乐/环境声/机械噪声) |
| 搬运方式 | 多机错峰下载上传 |
| 搬运周期 | ~1 年 |
| 训练资源 | 1 机 8 卡完成 Base → 1.2B 全部训练 |
视频-音频同步筛选¶
用视觉信号校验音频语义有效性(画面中出现狗的同时有狗叫声 = 语义有效)。原始数据无监督、无标注,通过同步信号伪标注。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
规模扩展的实证收益¶
HEAR 基准: ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
| 模型规模 | 参数量 | 性能 |
|---|---|---|
| Base | 86M | 78.88 |
| 1.2B | 1.2B | 81.25 |
训练数据扩量(AudioSet 5K → 27 万小时): ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
| 模型规模 | 额外提升 |
|---|---|
| 小 | +6.37 pp |
| 中 | +8.69 pp |
| 大 | +8.45 pp |
失败教训:盲目扩量¶
团队曾把训练数据集扩容至原有 10 倍体量,结果出乎意料:AudioSet 公开测试集指标不升反降,切回业务场景实测效果同样变差。
关键认知: ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"] - 开源基准指标和实际业务指标高度正相关 - 盲目扩量是无效的,音频数据的质量优先级远大于单纯的数据体量
业务落地¶
- 音频标记算法首次突破 AudioSet 50+ mAP
- Mini 版 49.0 mAP,参数量仅同类 1/10
- CED(Consistent Ensemble Distillation):从大型教师模型集成蒸馏出小模型
- 部署到小米终端设备
阶段 3:6 维标注 + 通用音频描述¶
行业常规做法的局限¶
用 ASR 转录做音频-文本对齐,只能理解"人说了什么",丢弃环境声 / 音乐 / 情感 / 空间混响等信息。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
ACAV100M 数据集上损失高达 90% 潜在有用数据——等同花了大量精力去"听懂"万物,最后在对齐环节又把大部分信息扔掉。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
关键突破:通用音频描述对齐¶
用多专家分析管道做细粒度标注(2 秒粒度),再通过大模型合成统一描述。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
6 维度 Caption(ACAVCaps)¶
| # | 维度 | 标注内容 |
|---|---|---|
| 1 | 语音内容 | 人说了什么 |
| 2 | 说话人情绪 | 情感状态 |
| 3 | 背景声音 | 环境声 |
| 4 | 音乐 | 音乐元素 |
| 5 | 场景环境 | 空间信息 |
| 6 | 音频类型 | 类别 |
配套 MECAT Benchmark,全部开源。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
反直觉的成功¶
拆分 6 个维度做细粒度标注,一开始大家都不看好,认为多维度信息冗余。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"] 但后续做音频生成实验时发现,六维精细化标注恰恰是模型生成真实声场音频的关键。
业务结果¶
- MiDashengLM 在 22 个公开评测集上取得 SOTA
- TTFT 仅为业界先进模型的 1/4
- 同等显存下吞吐效率是其 20 倍以上
- 0.6B 轻量版本:支持 CPU 部署 + 浏览器 WebAssembly 运行
- 从云端到边缘设备全覆盖
- 数据 + 模型 + 代码 全部开源
阶段 4:DashengTokenizer — 理解 + 生成统一¶
行业困境¶
- 行业通行做法:声学编码器做理解 + 声学解码器做生成,两者独立
- 两倍计算资源 + 两倍部署成本
- 难以在同一个模型中同时做理解和生成
行业假设¶
传统生成模型理论有一个常见假设:高维度特征不太适合直接用于生成。这个假设在相当长的时间里被广泛接受。
突破¶
我们通过冻结 Dasheng 的语义特征,仅注入声学信息,用一层结构就实现了理解和生成的统一。
业务结果¶
- 在 22 个任务上,DashengTokenizer 显著超越了此前使用的音频编码器和音频编解码器
- 文本到音频 / 文本到音乐 / 语音增强任务全面超越标准 VAE 方法
- VAE 架构不再是音频合成的必要条件
阶段 5:DashengAudioGen(进行中)¶
让生成的声音更贴近真实场景——带环境音、背景噪声、回声和远近感的完整声学场景。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
- 详情:https://nieeim.github.io/Dasheng-AudioGen-Web/
- 代码:https://github.com/xiaomi-research/dasheng-audiogen
关键数字汇总¶
| 指标 | 数值 | 备注 |
|---|---|---|
| 原始音频数据 | ~300T | 几百万小时 |
| 数据包数 | 146 个 | |
| 数据搬运周期 | ~1 年 | 多机错峰 |
| 训练硬件 | 1 机 8 卡 | Base → 1.2B 全部 |
| HEAR Base 性能 | 78.88 | 86M |
| HEAR 1.2B 性能 | 81.25 | |
| 数据扩量提升 | +6-8 pp | AudioSet 5K → 27 万小时 |
| AudioSet 首次突破 | 50+ mAP | 音频标记 |
| Mini 模型 mAP | 49.0 | 同类 1/10 参数 |
| ACAV100M 损失 | 90% | ASR 对齐 |
| MiDashengLM SOTA | 22 个评测集 | |
| MiDashengLM TTFT | 业界 1/4 | |
| MiDashengLM 吞吐 | 同等显存下 20x | |
| 轻量版本 | 0.6B | CPU + WebAssembly |
深度分析¶
1. "方向差异" vs "程度差异" 是预研决策的关键¶
大多数团队倾向于在已有路径上做增量优化("再加点数据" / "再调调超参"),因为风险更小、可解释性更高。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
但 Xiaom Dasheng 团队的判断是:当优化走到极致,不应该继续加码,而是得换一条路重新出发。这种"换方向"决策需要: ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
- 对行业假设的清晰理解("已有路径的优化边界在哪")
- 对替代方案的深度预研("MAE 在视觉的成熟经验能否迁移到音频")
- 对失败成本的容忍("8 卡 1 年投入 = 可接受的失败成本")
2. "数据质量 > 数据体量" 的音频领域实证¶
与 NLP / CV 领域的 scaling law 不同,音频领域的盲目扩量可能反降: ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
- 公开视频 80-90% 含人声,纯粹的环境声 / 音乐稀缺
- 10 倍数据扩充反而让模型变差
- 视频-音频同步伪标注是质量筛选的关键
这与 LFD(Loss Function Development)的 "eval 大小优先于答案可见性" 是不同维度的质量哲学——但都强调质量 > 体量。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
3. "通用描述 > ASR 对齐" 是音频对齐范式转变¶
传统音频-文本对齐 = ASR 转录(只能对齐"说了什么",丢弃 90% 潜在有用信息)。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
Xiaomi Dasheng 的 6 维 caption = 多专家分析管道 + 大模型合成统一描述(对齐"声学场景全貌")。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
这种范式转变的代价:训练损失更高(因为任务更复杂)。但更高的损失 = 更丰富的学习信号。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
4. "高维特征不适合直接生成" 的假设被证伪¶
行业通行假设:生成模型需要压缩到低维隐空间(VAE 哲学),高维特征信息"散"、解码器难以利用。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
DashengTokenizer 通过冻结语义特征 + 仅注入声学信息,证明高维特征可以直接用于生成。这一突破解放了音频合成对 VAE 架构的依赖。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
5. 6 维 caption 的"意外"价值印证预研容忍度¶
预研中被质疑最多的方向,有时恰恰是最有价值的。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"] 6 维标注从"没人看好"到"成为关键",说明预研团队需要容忍一定程度的"低效探索"。
这是 Xiaomi Dasheng 团队最值得借鉴的方法论:当某个方向不被人看好时,先小规模验证再判断——而不是直接放弃或被共识压倒。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
实践启示¶
何时考虑自建通用基座¶
- 领域缺乏通用预训练方法(音频、视频、3D、触觉等)
- 现有单任务模型之间互不通用(语音 ASR 做不到声音分类)
- 有可承担失败的算力预算(Dasheng 起步 1 机 8 卡 = 中等门槛)
- 团队能容忍"低效探索"(不追求每步都成功)
自建基座的工程清单¶
- 预研阶段:先识别现有路径的优化边界,再决定是否换方向 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
- 数据工程:先质量后体量;用多模态同步信号做伪标注 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
- 模型选择:参考其他领域的成熟方法(MAE 从视觉迁移到音频) ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
- 规模扩展:在小规模验证有效后再扩量(避免盲目 scaling) ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
- 语义对齐:用多专家 + 大模型合成做细粒度 caption,而非单一 ASR ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
- 架构统一:探索理解+生成统一模型,挑战 VAE 类架构假设 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
- 开源验证:开源基准上验证是预研最诚实的信号 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
DashengAudioGen 的下一步¶
让生成的声音更贴近真实场景——带环境音、背景噪声、回声和远近感的完整声学场景。
这与 Snowflake 的"Artifacts = 持续更新的受治理视图"是不同维度的"真实感"——DashengAudioGen 关注听觉真实感,Snowflake 关注数据真实感。 ^["Xiaomi Dasheng:8卡起步的 AI 工程实践"]
相关实体¶
- 面向电商直播场景的全模态大模型推理加速方案(多模态推理加速对照)
- Cvpr 2026 Highlight 让Ai像电影人一样 看 视频 8B小模型反超Gpt 5与Gemini 3 1 Pro(视频 8B 反超同主题 — 多模态 8B 起步)
- A2Rd Agentic Autoregressive Diffusion Long Video(多模态生成对照)
- Openai Realtime Api Architecture(OpenAI Realtime API — 实时语音对照)
- 刚刚Openai 放出三个语音模型顺便杀死了同传(OpenAI 语音模型同主题)
- Gpt 5级推理能力塞进语音模型Openai把同传翻译成本砍穿地板价(OpenAI GPT-5 语音同主题)
- Amazon Bedrock Model Inference Serverless Architecture Case Study(Bedrock 多模态推理对照)
- Nvidia Nemotron 3 Agents Rag Voice Safety(Nemotron 语音 + 智能体对照)
- Snowflake Agentic Enterprise Summit 2026(Snowflake 真实感场景对照)
- Loss Function Development Elvis Sun Goal Loop 2026(LFD 质量 > 体量同源思想)
→ 原文存档
Ch17.005 Pixelle-Video — 阿里国际 AIDC 开源的全自动视频生成 pipeline 装配工¶
📊 Level ⭐⭐ | 14.0KB |
entities/pixelle-video-aidc-ali-international-2026.md
Pixelle-Video — 阿里国际 AIDC 开源的全自动视频生成 pipeline 装配工¶
[!quote] 一句话定义 Pixelle-Video 不是一个视频生成模型,而是一个把 LLM + 图像/视频生成 + TTS + ffmpeg 串起来的 pipeline 编排框架。输入一句话,吐出成品视频。Apache 2.0,GitHub 2.2万 Star,由阿里国际 AI 团队(AIDC-AI)开发。
核心定位:装配工,不是生成器¶
Pixelle-Video 在 AI 视频工具生态里占据一个独特生态位 — pipeline 编排层。它不自研任何生成模型,只做模型间的串接:
- LLM 写文案(可换 GPT-4o / 通义千问 / DeepSeek / Ollama 本地)
- 图像/视频生成 出画面(可换 ComfyUI / RunningHub / Seedream 等 API)
- TTS 念稿(默认 Edge-TTS 免费 + 声音克隆)
- ffmpeg 合成(套 HTML 模板)
- BGM 走内置库
"装配工"哲学:作者明说"画质不行换图模型,文案太烂换LLM,声音不喜欢换TTS工作流,不用赌一个模型能把所有事都做好"。
4 步生产流程¶
- 文案生成: 主题 → LLM → 解说词(可选"固定文案"模式,贴现成稿子)
- 配图规划: 解说词 → 拆段 → 调用图像/视频生成 API
- 逐帧处理: 每帧单独生成,中间可手工干预 prompt
- 视频合成: ffmpeg 套 HTML 模板 + TTS 配音 + BGM 合成最终视频
WebUI 用 Streamlit 搭的,三栏布局(左输入 / 中参数 / 右预览),"能用就行"的开发者风格。
三大配图方案(拼积木哲学的具体体现)¶
每条路独立可换,且可混合(文案走 Ollama 本地 + 配图走 ComfyUI + 语音走 Edge-TTS):
- ComfyUI 本地: 8G 显存起步,适合有 GPU 玩家,质量天花板最高
- RunningHub 云端: 不挑设备,费用中等
- 直连 API(如 Seedream): 极简集成,适合快速出片
这种"每个环节可独立替换"的设计,与纳德拉"模型可替换性是 Token 资本型企业的主权测试"形成强对应 — Pixelle-Video 是这个哲学在视频生成领域的具体工程范本。
三种模板系统¶
模板前缀编码了模板类型,语义化命名:
static_*: 纯文字排版(快,适合教程/课程)image_*: AI 生成的图当背景叠文字video_*: AI 视频片段当背景
竖屏 / 横屏 / 方形都有,适合小红书 / 抖音 / YouTube / 内部培训等多场景。会写 HTML 的人可在 templates/ 目录自定义(字号/颜色/位置/动画全可调)。
2026 Q1 新增的三大扩展模块¶
作者描述"奇怪的模块"指 2026 Q1 加入的差异化能力:
- 数字人口播(Digital Human): 上传人像图 + 文案,数字人对着镜头念,韩语日语都行 — 典型跨境电商场景,这也解释为何开发团队是阿里国际 AI 团队(AIDC-AI 本身就是阿里国际的 AI 部门)
- 图生视频 + 动作迁移: 一张静态图让它动起来;动作迁移传一段参考视频 + 一张图片,视频里的动作迁移到图片上(猫在跳那段舞)
- 自定义素材: 上传自己的照片和视频,AI 分析完自动生成脚本再合成(适合个人 IP 号)
三种部署与成本方案¶
| 部署方案 | LLM | 图像/视频 | TTS | 成本 | 适用场景 |
|---|---|---|---|---|---|
| 零成本本地 | Ollama 本地 | ComfyUI 本地 (8G 显存) | Edge-TTS 免费 + 内置 BGM | 0 元 | 有 GPU 玩家,质量优先 |
| API 轻量 | 通义千问 API | API(Seedream 等) | Edge-TTS 免费 | 三段视频 0.01-0.05 元 | 不想折腾硬件,偶尔出片 |
| 全套云端 | OpenAI API | RunningHub 云端 | Edge-TTS 免费 | 费用较高 | 笔记本也能跑,质量要求高 |
作者实测:三分钟短视频,通义千问 + Edge-TTS,API 费不到一毛。
工程评价¶
优势: - 可组合性最强: LLM/图像/TTS 三个环节可任意替换,真正做到了"模型可替换" - 零成本路径清晰: Ollama+ComfyUI+Edge-TTS 三件套 0 元 - 安装极简: Windows 整合包一键启动,Python/ffmpeg 全在包内 — 作者感叹"太省心了反而觉得是不是少了什么步骤" - 场景覆盖广: 教程、课程、内部分享、跨境电商带货、个人 IP 都能用
局限: - GPU 硬伤未解: 8G 显存起步,本地高质量出片仍是富人的游戏 - 默认模板审美: 作者坦承"偏工具感",做出小红书精致程度需自己磨 prompt prefix 或重写模板 - 质量依赖底层模型: 它是装配工,装配质量完全由各环节模型决定 — 这是哲学选择而非缺陷 - 跨境电商基因: 数字人/多语言/动作迁移等扩展模块明显是 AIDC 服务阿里国际 Lazada/速卖通等业务,中文/英文场景的本地化还需自行调整
哲学价值:印证"模型可替换性"是企业 AI 主权¶
Pixelle-Video 是 Microsoft CEO 纳德拉 2026-06-14 X 帖"Token 资本论"中"模型可替换性测试"在视频生成领域的具体工程范本:
纳德拉:"一家真正的 Token 资本型企业,应该能随时换掉底层通用大模型,而不丢失已沉淀在学习系统中的'老兵经验'。"
Pixelle-Video 把这个哲学推到极致:LLM 可换 + 图像模型可换 + TTS 可换 + 模板可换,业务完全不被任一模型供应商锁定。
与现有实体的交叉对比¶
- vs AI 视频工具悄悄走到了第三阶段 — 那是行业历史阶段综述(20KB,花叔 2026-05-07),本文是单一项目深测。两者互补:阶段综述给宏观背景,本文给工程细节。
- vs Video Agent 范式迁移与算力-人才飞轮 — 那是底层视频模型视角(nvidia Cosmos + xAI Grok Imagine),本文是pipeline 编排层视角。两层视角互补。
- vs JoyAI-Echo:京东长视频框架 — 那是长视频(5 分钟一致性)底层生成框架(DMD 蒸馏 + Director Agent),本文是短视频 pipeline 装配。时长 / 抽象层完全不同。
- vs Fastlane 短视频内容 — 另一款短视频工具,但未开源;Pixelle-Video 是 Apache 2.0 开源,可二开。
- vs Agentium Agent Framework — 同为 pipeline 编排思路,但 Agentium 偏通用 agent 编排,Pixelle-Video 偏视频生成专精。
- vs 纳德拉「Token 资本」论 — Pixelle-Video 是该战略宣言"模型可替换性"哲学的工程范本。
- vs 800 行 OpenClaw tool 消息总线子 agent 管理架构 — 两者都体现"装配工胜过生成器"的工程哲学(OpenClaw 是 agent 工具总线装配)。
深度分析¶
1. 装配工哲学的崛起:从"赌单个模型"到"编排即壁垒"
Pixelle-Video 的出现印证了一个正在多领域复现的规律:当单点生成模型(图像、视频、语音)的能力逐渐同质化,真正的工程壁垒从"谁能训练出更好的模型"迁移到"谁能更聪明地把模型串起来"。这是一种自下而上的范式转移——在 纳德拉的 Token 资本论 框架里,这正是"模型可替换性"的核心洞察:企业的 AI 主权不在于拥有最强模型,而在于能够随时替换底层模型而不丢失已沉淀的业务逻辑。Pixelle-Video 是这个哲学在视频生成领域的第一批工程范本之一。
2. 阿里国际 AIDC 的战略卡位:用开源工具撬动跨境电商内容生态
AIDC-AI 团队(阿里国际 AI 部)选择开源而非内部封闭开发,战略意图值得玩味。Pixelle-Video 的数字人口播、多语言 TTS、动作迁移等扩展模块,本质上是为 Lazada、速卖通等平台的商家定制的"出海内容生产工具"。开源 2.2 万 Star,既是技术品牌建设,也是生态锁定——当商家工作流围绕 Pixelle-Video 建立,阿里国际的云服务、API 集成和跨境支付等增值服务就有了更自然的入口。这是"工具开源 → 用户习惯 → 商业转化"的经典路径。
3. "零成本本地"方案的深层含义:降低 AI 视频的算力门槛
三分钟短视频 API 成本不到一毛、Ollama+ComfyUI+Edge-TTS 全套零成本的路径设计,表面是降低用户门槛,深层是推动 AI 视频从"少数有显卡玩家的玩具"变成"任何电商运营都能用的日常工具"。这与 vibe coding 范式 的核心主张一脉相承:让 AI 替你操心技术细节,你只管创意和业务。随着显存成本持续下降,这种"算力民主化"路径会进一步挤压付费视频生成工具的市场空间。
4. 模板系统的工程美学:语义前缀胜过配置文件
static_/image_/video_ 前缀编码模板类型,是看似简单但极其有效的 API 设计决策。相比 YAML 配置或下拉菜单,语义化前缀降低了认知负担,让用户能够"猜"出正确用法。这与 Harness Tool Design 的设计演进 原则吻合:工具的易用性往往不取决于功能多少,而取决于命名和组织的直觉程度。
5. 出海 AI 商业化的新范式:垂直场景驱动开源,开源驱动生态
Pixelle-Video 不同于纯研究型开源项目(如 Stability AI 的各种模型),它有极其明确的商业场景(跨境电商视频),有具体的业务归属(阿里国际团队),有可量化的成功指标(Star 数、部署案例)。这代表了一种新的出海 AI 商业化路径:不是先建平台再找场景,而是从垂直业务需求出发,把解决方案开源出去,借助社区力量完善工具,同时为自身业务生态引流。
实践启示(5 条)¶
- 优先做装配工,再做生成器: 如果你正在做 AI 视频/图像/语音工具,Pixelle-Video 验证了"编排层的工程价值可能比单点生成模型更持久"
- 模板前缀语义化编码:
static_/image_/video_前缀比配置文件更易发现/扩展 — 这是值得借鉴的小设计 - Windows 整合包 = 用户增长黑客: 极大降低首次使用门槛,让非技术用户也能上手
- 场景化扩展是开源自增长引擎: 数字人口播 / 动作迁移这种"奇怪的模块"恰恰是吸引特定垂直用户(跨境电商)的钩子
- 跨境电商基因 = 战略定位: 项目本身的国际化属性(AIDC 团队 + 数字人 + 多语言)决定了它的市场定位而非偶发选择
相关实体¶
- → 原文存档
- AI 视频工具悄悄走到了第三阶段
- Video Agent 范式迁移与算力-人才飞轮
- JoyAI-Echo:京东长视频框架
- Fastlane 短视频内容
- Agentium Agent Framework
- 纳德拉「Token 资本」论
- 800 行 OpenClaw tool 消息总线
- Harness Engineering 7 层架构
- A²RD 长视频一致性框架
- Anthropic 缓存 Token 经济
- Google Gemini Omni 视频模型
Ch17.006 Normalizing Trajectory Models¶
📊 Level ⭐⭐ | 10.0KB |
entities/ntm-normalizing-trajectory-models.md-> 原文存档
Summary¶
[2605.08078] Normalizing Trajectory Models
Source¶
- URL: https://arxiv.org/abs/2605.08078
- Author: Jiatao Gu, Tianrong Chen, Ying Shen, David Berthelot, Shuangfei Zhai, Josh Susskind
- Date: Submitted 8 May 2026
核心要点¶
- 问题定位:Diffusion 模型将采样分解为多个小的高斯去噪步骤,这个假设在生成被压缩到少数粗粒度转换时会崩溃
- 核心创新:Normalizing Trajectory Models (NTM) 将每个逆向步骤建模为表达性条件归一化流,支持精确似然训练
- 架构特点:结合每步内的浅层可逆块与跨轨迹的深层并行预测器,形成端到端网络
- 关键能力:支持自蒸馏——在模型自身的 score 上训练的轻量级去噪器可以在四步内生成高质量样本
- 性能表现:在文生图基准测试中,NTM 仅用四步采样就能匹配或超越强图像生成基线,同时保留沿生成轨迹的精确似然
技术洞察¶
研究背景与问题¶
扩散概率模型(Diffusion Models)已成为图像生成的主流方法,但其核心假设——将采样分解为大量小的 Gaussian 去噪步骤——在需要快速生成(少步采样)的场景下失效。当我们尝试将扩散模型的采样步数从数十步压缩到几步时,生成质量会急剧下降。现有的少步方法通过蒸馏、一致性训练或对抗目标来缓解这个问题,但代价是放弃了似然框架——这意味着无法精确计算生成样本的概率。
NTM 的核心思想¶
Normalizing Trajectory Models (NTM) 提出了一个优雅的解决方案:不再将每个逆向步骤视为简单的去噪操作,而是将其建模为条件归一化流(Conditional Normalizing Flow)。这意味着每一步都是一个可逆变换,可以精确计算似然。通过这种方式,NTM 保留了扩散模型的似然框架,同时支持少步采样。
架构设计¶
NTM 的架构由两个关键组件构成: 1. 步内可逆块(Within-step Invertible Blocks):在每个时间步内,使用浅层可逆网络实现复杂的条件变换。这与标准归一化流中的多尺度架构类似,但增加了一步内的表达能力。 2. 跨轨迹并行预测器(Across-trajectory Parallel Predictor):对于跨步的轨迹建模,使用深层的并行网络从噪声直接预测干净图像。这个预测器与每步的可逆块结合,形成端到端的可训练系统。 这种设计的优势在于:网络可以从头训练,也可以从预训练的流匹配模型初始化——这为迁移学习提供了灵活性。
自蒸馏机制¶
论文最引人注目的发现之一是 自蒸馏(Self-distillation) 的可行性。由于 NTM 保留了精确的轨迹似然,模型可以生成大量样本,然后用这些样本来训练一个更轻量的去噪器。这个轻量去噪器在四步采样就能产生高质量输出,而无需完整的数十步采样流程。 这意味着 NTM 可以实现推理效率的指数级提升:训练一个四步采样器,无需访问数十步的教师模型。自蒸馏的样本来自模型自身,避免了外部数据依赖。
与现有方法的对比¶
| 方法 | 少步采样 | 精确似然 | 可自蒸馏 |
|---|---|---|---|
| DDPM | ❌ | ✅ | ❌ |
| DDIM | ✅ | ❌ | ❌ |
| Consistency Model | ✅ | ❌ | ✅ |
| NTM (本文) | ✅ | ✅ | ✅ |
| NTM 是首个同时满足这三个目标的统一框架。 |
深度分析¶
对扩散模型范式的根本性贡献¶
NTM 的重要性不仅在于性能提升,更在于它揭示了扩散模型少步采样失效的根本原因:现有的少步方法隐式地假设去噪过程可以被压缩,但这个假设与扩散模型的概率基础冲突。NTM 通过引入归一化流的表达能力,解决了这个根本矛盾。 具体来说,标准扩散模型的反向过程被建模为:$p_\theta(x_{t-1}|x_t) = \mathcal{N}(\mu_\theta(x_t), \sigma_\theta(x_t))$。当步数很少时,这个高斯假设过于简化,无法捕捉数据分布的复杂结构。NTM 将每步反转替换为可逆变换 $f_\theta(x_{t-1}|x_t)$,保留了分布的表达能力。
对生成式 AI 工程实践的影响¶
对于构建文生图系统的工程师,NTM 提供了几个关键启示: 推理成本的结构性下降:如果 NTM 的自蒸馏机制可以推广,那么未来可能训练一个一步采样器达到当前数十步采样的质量。这意味着 GPU 成本可以降低一个数量级,而不影响输出质量。 精确似然的价值:精确似然对于许多下游任务至关重要,包括异常检测、数据压缩、概率校准等。NTM 使得这些应用可以在少步采样场景下使用扩散模型。 模型初始化的新范式:论文提到可以从预训练的流匹配模型初始化 NTM,这为迁移学习提供了新路径。已经投资于流匹配模型的团队可以低成本切换到 NTM 架构。
潜在局限与开放问题¶
- 计算开销:步内可逆块和跨轨迹预测器的组合可能带来显著的训练开销,特别是对于高分辨率图像。论文未详细讨论训练时间和显存需求。
- 架构复杂性:与标准扩散模型相比,NTM 需要同时优化两个组件(步内和跨步),这增加了超参数调优的难度。
- 泛化能力验证:论文主要在标准文生图基准上评估。NTM 对复杂提示、长文本、组合泛化等挑战的鲁棒性仍需更多验证。
- 与现有加速方法的比较:论文将 NTM 与 Consistency Model 等进行比较,但未讨论这些方法是否可以结合使用。
实践启示¶
给生成式 AI 研究者的建议¶
- 探索 NTM 与其他加速技术的组合:自蒸馏机制与推测解码(Speculative Decoding)、早起退出(Early Exit)等技术的潜在协同值得研究。可能实现更激进的推理加速。
- 扩展到多模态生成:NTM 的框架可以自然地扩展到视频、3D、音频等模态,因为其核心思想(可逆变换 + 轨迹建模)与模态无关。首个在这些模态上验证 NTM 的研究可能产生重要影响。
- 研究少步采样的质量边界:论文展示了四步采样的良好结果,但未探索一步或两步的可能性。理解少步采样的质量下限对于实际部署至关重要。
给 AI 工程团队的行动指南¶
- 评估 NTM 在产品中的适用性:如果你的产品需要精确的生成概率(如异常检测、数据压缩)、需要快速推理(如实时应用)、或需要多步采样场景,NTM 值得评估。
- 关注自蒸馏的训练效率:论文声称可以从预训练模型初始化,这可能显著降低训练成本。在开始自己的训练前,先验证预训练模型的可用性和质量。
- 建立少步 vs 多步的基准测试:在采用 NTM 之前,建立你的特定用例的基准测试。确定质量-速度的权衡曲线,以便做出数据驱动的决策。
给 MLOps 和基础设施团队的建议¶
- 准备支持可逆架构的工具链:NTM 的可逆块需要特殊的反向传播处理。确保你的自动微分框架可以高效处理这类架构。
- 评估边缘部署可能性:如果推理成本是关键瓶颈,NTM 的少步采样可能使扩散模型首次部署在边缘设备上(如手机、IoT 设备)。开始评估相关硬件支持和模型压缩需求。
- 跟踪学术进展的时间表:NTM 仍处于学术阶段,从论文到稳定开源实现通常需要 6-12 个月。建议关注相关 GitHub 仓库和 HuggingFace 集成的时间线。 → 原文存档
相关实体¶
Ch17.007 LLaVA-OneVision-2:全帧率视频理解¶
📊 Level ⭐⭐ | 9.3KB |
entities/llava-onevision-2-full-frame-rate-vlm.md
核心问题¶
视频被当作一组图片处理——巨大的浪费。
1. 算力浪费:视频原本连续,相邻帧天然存在关系。但传统流程把视频解码成静态图片,连续结构被打散,模型用昂贵计算把关系重新学回来。
2. 信息结构浪费:视频编码器早已建模 I帧(完整空间上下文)、P帧(记录运动和残差变化)、运动向量、残差——描述哪些内容稳定不变、哪些内容发生了变化。但现有 VLM 先把这些结构全部解开,再让模型重新发现一遍。
核心方案:OneVision-Encoder¶
思路: 直接利用视频 codec 中已有的信息结构(I帧/P帧/运动向量/残差),构建更 compact 的 token 或表示,让本来就存在于视频里的运动、变化和连续关系直接传给模型。
| 组件 | 说明 |
|------|------|
| 架构 | "视觉基座—projector—LLM"(LLaVA 延续) |
| 视觉编码器 | OneVision-Encoder(24层 ViT) |
| 位置编码 | 共享时间、高度、宽度三个维度 |
| 视频输入策略 | 基于 codec 的密集视频输入 |
| 训练框架 | 百度百舸 LoongForge |
| 训练扩展 | 四阶段:30秒 → 10-15分钟长视频 |
Token 效率:约 1/8 推理成本。 一秒 24 帧 = 2400 token;100万上下文窗口仅容纳约 7 分钟全帧率视频。
为什么抽帧不够¶
- 关键动作可能只持续极短时间,固定间隔抽帧可能刚好错过
- 时序定位(全帧率更精准)需要知道事件何时开始、何时结束
- 视频 Agent(剪辑 Agent)底层需要准确定位动作起点终点
- Coding agent 表现更好是因为代码是高质量文本;视频 agent 面对长视频 + 密集时序 + 大量视觉冗余,难度完全不在一个量级
分层部署路径¶
- 边缘哨兵:现场解析原始视频为结构化信息,筛掉无效数据,传有价值信息给上级
- 算法运营中心:二次识别复核、报警管理、模型迭代、业务编排
- 算法训练中心:私有化部署到客户数据中心,数据不离开客户体系
全帧率 vs 抽帧¶
| 抽帧 | 全帧率(OneVision-Encoder) | |
|---|---|---|
| 关键动作定位 | 可能漏掉 | 精准捕获 |
| 时序信息 | 丢失 | 完整保留 |
| Token 成本 | 高(重复编码相似帧) | 降至约 1/8 |
| 推理成本 | 线性增长 | 压缩冗余后高效 |
具身智能 & 未来方向¶
- VLM → 具身主干:VLM 高效处理连续视频 + 空间关系 + 目标变化 → 可能成为具身系统主干模型
- 流式理解:不等整个视频结束,边进边持续理解判断(监控、直播、交互式视频)
- 理解生成一体:图像/视频的理解和生成,目前往往是两套系统;理解是底座,底座足够好,上层的生成和编辑才有更高上限
关键数字¶
| 指标 | 数值 |
|---|---|
| 一小时视频帧数(24 FPS) | ~9万帧 |
| 一秒视频 token 数 | ~2400 token |
| 100万上下文窗口 | 仅约 7 分钟全帧率 |
| Token 成本节省 | 约 1/8 |
| 视频理解扩展 | 30秒 → 10-15分钟 |
| 中等模型成本下降 | 2000卡 → 200卡 |
相关链接¶
- GitHub: https://github.com/EvolvingLMMs-Lab/LLaVA-OneVision-2
- 模型: https://huggingface.co/lmms-lab-encoder/LLaVA-OneVision-2-8B-Instruct
- 技术报告: https://cdn.jsdelivr.net/gh/anxiangsir/ov2_asset@main/LLaVA_OneVision_2.pdf
相关概念¶
- LLaVA系列 — 视觉基座—projector—LLM 架构(实体不存在,待创建)
- 视频理解 — 全帧率 vs 抽帧(实体不存在,待创建)
- 视觉编码器 — OneVision-Encoder(实体不存在,待创建)
- 具身智能 — VLM 成为具身大脑 backbone(实体不存在,待创建)
深度分析¶
抽帧方案的隐性成本:省了 token,省不了信息损失。
固定间隔抽帧(如每秒1帧)是典型的"为了省 token 而引入偏差"的策略。当一个视频里关键动作只持续 3-5 帧时(24FPS 下不到 0.2 秒),固定间隔抽帧有极大概率完美错过。表面上看 token 成本降低了,但模型的"事件检测能力"也随之降低——这不是算法问题,是信息论问题:时序连续性被打散后,隐含的因果关系需要额外的计算才能重建,而且往往重建不完整。OneVision-Encoder 核心洞察是:视频 codec 已经把连续信息结构化建模好了,为什么不用?
Token 效率 1/8 的意义:不是压缩,是结构化复用。
1/8 的 Token 成本节省如果只是"更激进的帧间差异压缩",那么代价一定是信息损失。但 OneVision-Encoder 的思路不同:它利用 I帧/P帧/运动向量/残差这些 codec 已有结构——这些都是视频压缩中已经做好的信息结构化表示,模型直接使用这些表示而不是重新从像素级特征中推导。这意味着压缩和结构化是一体的,不是先压缩再补救信息。Token 数量减少,但每个 token 携带的信息密度提高了。
100万上下文仅覆盖7分钟:这对实际应用意味着什么?
7分钟全帧率视频 ≈ 100万 token 输入给 LLM。这个数字表面看起来很小,但实际视频理解任务很少需要连续处理整段视频。以视频剪辑 Agent 为例:它的核心操作模式是"定位 → 分析 → 定位 → 分析"的循环,不是"一次性输入整段视频"。真正需要处理长视频的场景(如视频摘要、跨镜头分析)更可能采用分段处理 + 全局汇总的架构。100万 token 的限制影响的是单次处理上限,而不是整体系统能力。
分层部署架构的本质:不是"大模型→小模型",而是"专家模型→通才模型"。
大模型冷启动 → 中模型快速迭代 → 小模型规模化,这条路径的内在逻辑不是"蒸馏压缩",而是"角色分工"。大模型(30B+)负责从无到有的推理,发现视频中存在的模式;中模型(7B~13B)负责在已知模式下的快速决策;小模型(1B~3B)负责现场的结构化筛选,不传原帧,传"事件+时间戳+关键特征"。这三层模型针对的任务类型完全不同,是真正的 specialized pipeline,不只是规模的简单递减。
相关链接¶
相关实体¶
→ 原文存档
实践启示¶
选型判断:你的场景是"理解"还是"定位"?
如果核心需求是"这段视频里发生了什么"(视频摘要、内容理解),抽帧 + VLM 的方案在大多数情况下已经够用,Token 成本也更低。如果核心需求是"动作 X 发生在视频的哪个精确时间点"(剪辑、监控告警、具身机器人),全帧率是刚需——这时候抽帧的错误率会直接影响任务完成质量。明确这个区别,再决定要不要上 OneVision-Encoder。
边缘部署:小模型在现场做的事是"筛"不是"判"。
边缘哨兵节点(1B~3B 模型)不应该做最终判断——它的职责是把原始视频压缩为"有意义的结构化事件"(时间戳、事件类型、置信度、关键帧索引),然后把结构化数据传给上级。这样做有两个好处:边缘带宽需求大幅降低;上级中心可以用更少的上下文 token 处理更多路视频。设计边缘→中心的通信协议时,应该传"事件描述对象"而不是"关键帧图片+时间戳"。
模型迭代策略:先在长视频上测准,再缩短到实用长度。
文章提到四阶段训练:30秒 → 10-15分钟。实际落地时,建议先用公开数据集(ActivityNet、YouCook2 等)验证模型在全帧率下的时序定位精度,达到基线后再针对自己的目标场景做微调。不要一上来就追求10分钟+的处理能力——先确保30秒级别精度可接受,再扩展上下文窗口长度。
多模态 Agent 开发者:视频理解 ≠ 视频生成,底座通用是优势。
LLaVA-OneVision-2 解决的是理解侧问题,而当前很多视频生成模型(如 Sora、Runway)解决的是生成侧问题。两者的底座技术路径不同,但理解是生成的上游——理解得越细,生成的约束条件越精确。未来如果出现"理解+生成一体化"的系统,高质量的视频理解底座(如 OneVision-Encoder)会是关键的 infrastructure 优势。多模态 Agent 开发者在选型时可以考虑这个趋势。
Ch17.008 SunFinance: Textract+Claude准确率90.8%的ID提取方案¶
📊 Level ⭐⭐ | 7.9KB |
entities/aws-sun-finance-ai-id-extraction-fraud-detection.md
核心内容¶
SunFinance将AWS Textract(文档 OCR)+ Claude(智能理解)结合,ID提取准确率从79.7%提升至90.8%,成本降低91%。系统每月处理330万次ID验证,支撑信贷审批全流程。
三个关键洞察¶
1. Hybrid Textract+Claude架构¶
Textract负责基础OCR(文本提取),Claude负责语义理解(判断提取内容是否合法、与表单关系)。两者组合比分用各自单独使用效果更好——OCR做好结构化提取,LLM做最终判断。
2. 准确率提升的工程路径¶
79.7%→90.8%的提升来自:① 预处理优化(图像增强提升OCR质量)② prompt工程优化(让Claude更准确地判断字段关系)③ 反馈循环(将Claude的错误案例加入训练数据)。非一蹴而就。
3. 91%成本降低的来源¶
从自建CV模型(需要GPU服务器、维护团队)→ Textract API调用(serverless,按调用计费)+ Claude API。成本结构从固定成本变成可变成本,规模效应显著。
与知识库的连接¶
- → OS-level Actions:未来Agent可替代人工完成整个ID验证流程
- → LLM-as-Judge:Claude做ID判断本质上是做judge
深度分析¶
OCR+LLM混合架构的内在逻辑¶
SunFinance案例验证了一个核心原则:专业化工具做擅长的事,LLM做理解判断。Amazon Textract负责可靠的字符级OCR提取,Claude负责语义层面的结构化理解。两者组合的关键在于——OCR做好结构化提取,LLM做最终判断——这比让LLM直接处理图像更有效,因为LLM的PII保护机制会阻碍直接从身份证件提取敏感信息 。
Claude的PII保护机制是直接用LLM做ID提取的核心障碍¶
测试显示单独使用Claude Sonnet 4进行ID提取只有61.8%准确率,甚至低于79.7%的基线。根本原因不是模型能力不足,而是Claude内置的隐私保护机制——它会主动拒绝从身份证件等敏感文档提取PII信息 。这解释了为什么混合架构中LLM必须位于OCR之后而非之前。
多层OCR降级策略的工程意义¶
采用Textract(主)+ Rekognition(备)的双层OCR设计,用额外的一次API调用换取系统韧性。当Textract返回低置信度结果时自动降级到Rekognition,这种设计避免了单点失败,尤其在处理低质量扫描、异常角度或损坏证件时效果显著 。
向量相似度搜索的选型教训¶
欺诈检测中背景相似度分析揭示了文本嵌入与视觉嵌入的本质差异:文本嵌入(Claude描述背景后比对)达到91%准确率但精确率仅27.8%、召回率21.7%;视觉嵌入达到96%准确率、80%精确率、52%召回率 。直接用多模态Embedding做向量化的路线显著优于先做文本描述再做匹配的路线。
实践启示¶
1. 文档处理场景优先考虑混合架构¶
当处理身份证、发票、合同等结构化文档时,OCR+LLM的混合方案通常优于单独使用任何一种技术。关键是把"字符提取"和"语义理解"分离,让专业OCR处理字符级任务,LLM专注于关系判断和格式标准化 。
2. 验证规则是提升准确率的低成本高回报手段¶
SunFinance在OCR+Claude之后加入了ID号码格式化验证、日期标准化、文档类型规范化等规则,这些规则"捕捉住了OCR提取了正确字符但格式不一致的边缘情况" 。对于中国身份证、营业执照等有明确格式规范的文档,格式校验规则应该是标准配置。
3. Serverless架构支持快速迭代¶
6周的概念验证周期内技术方案每周都在演进,AWS Lambda+Step Functions的serverless设计允许团队"修改和部署单个Lambda函数而不需要停机" 。这对于需要快速试错的生产AI项目至关重要。
4. 欺诈检测需要多层防御¶
单一欺诈检测方法的召回率永远不够。视觉模式检测(检测屏幕照片、数字篡改)单独使用时对已知模式有95%+置信度;背景相似度检测(检测欺诈团伙)单独使用时对已知模式召回率仅55%、对新模式16.7%。两者组合才能覆盖不同类型的攻击向量 。
5. 成本结构转型释放新市场¶
从自建CV模型(GPU服务器+维护团队=固定成本)→ Textract API + Claude API(serverless+按调用计费=可变成本),91%成本降低使低价值贷款场景首次具备经济可行性 。对于服务小微信贷、助贷等低毛利场景,成本结构的优化直接决定了业务是否成立。¶
Source: 原文存档
相关实体¶
- AI Detection and Response (AIDR): A Zero-Impact Operating Model
- AWS Model Agility: 6步LLM跨代际迁移框架
- Securing AI agents: How AWS and Cisco AI Defense scale MCP and A2A deployments
- MLflow v3.10:生成式AI开发新特性
- 用 Kiro构建 AI:基于 AWS 基础设施快速构建企业级 Agentic AI 平台 | 亚马逊AWS官方博客
- AI 驱动的跨云网络搭建:用 Claude Code 和 Kiro CLI 实现 AWS-腾讯云 IPSec VPN 双隧道互联 | 亚马逊AWS官方博客
- 在 Amazon Bedrock 上为 Claude 应用设计稳健的 Prompt Cache 策略
- MOC
Ch17.009 How transparent is DiffusionGemma (and why it matters)¶
📊 Level ⭐⭐ | 7.9KB |
entities/diffusiongemma-transparency-audit-lesswrong.md
How transparent is DiffusionGemma (and why it matters)¶
原文存档:原文存档
核心内容¶
Published Time: 2026-06-20T20:05:50.053Z
Markdown Content: Authors: Joshua Engels, Callum McDougall, Bilal Chughtai*, Janos Kramar, Senthoran Rajamanoharan, Cindy Wu, Arthur Conmy, Asic Q Chen, Jean Tarbouriech, Min Ma, Brendan O'Donoghue+, João Gabriel Lopes de Oliveira+, Rohin Shah+, Neel Nanda+
*Primary Contributor
+Advising
Paper here: https://arxiv.org/abs/2606.20560
Overview¶
In a recent collaboration between the GDM interpretability team and the GDM text diffusion team, we performed a transparency audit of DiffusionGemma, GDM's new text diffusion model.
Overall, we find that DiffusionGemma is not significantly less transparent than Gemma.
- Gemma and DiffusionGemma perform similarly on monitorability evaluations.
- Although naively DiffusionGemma has a much largeropaque serial depth, we can apply the logit lens to intermediate vectors and ablate non-interpretable information without harming performance. This implies that these intermediate nodes are interpretable, which reduces the opaque serial depth to be similar to that of Gemma.
However, even though the variables that the model uses at different steps are interpretable, this does not necessarily mean that we understand the algorithm that the model uses to reach the final answer. We thus distinguish between variable transparency, which we define as whether we can understand snapshots of the model's computation, and algorithmic transparency, which we define as whether we can use these snapshots to reconstruct the process by which the model arrived at its outputs.
By default, algorithmic transparency is much lower for a text diffusion model. In an autoregressive model, the model proceeds through its reasoning in order, token by token; when each token is generated, we know the exact state the model was in, and can make inferences about why it generated a certain token. On the other hand, in a single "canvas" a diffusion model generates all tokens at once, and the causal relationship between different tokens is unclear; a diffusion model can e.g. use tokens at the end of the canvas to help it figure out what tokens to generate earlier in the canvas. In a series of case studies, we study these and other phenomena that are unique to text diffusion models, including non-chronological reasoning, token and sequence smearing, and intermediate-context reasoning. We make progress on algorithmic transparency and believe we now understand some of the algorithmic "styles" that DiffusionGemma uses, but we still think that it is less algorithmically transparent than corresponding autoregressive LLMs.
We also include 24 open problems that we would be excited for the community to investigate.
Why is this relevant for AI safety?¶
Currently, CoT monitoring is a load-bearing aspect of many safety cases, but future models may perform more of their reasoning in latent spaces. We think that developers should perform transparency audits of new model architectures that perform larger fractions of their computation in a latent space. Thus, even though DiffusionGemma is itself not concerning from a transparency perspective, we are excited about this work because of the precedent it sets for performing these sorts of evaluations. Many of our experiments, including the opaque serial depth and monitorability evaluations, should be able to be straightforwardly applied to future latent reasoning architectures.
If future latent reasoning models regress on these metrics, we will need new techniques that can translate from latent reasoning into natural language. Thus, we are particularly excited about techniques like Natural Language Autoencoders and Activation Oracles that can translate activations into natural text, and we hope that the interpretability community continues to prioritize their development.
Short summary of main results:¶
We first present a diagram of the DiffusionGemma architecture:
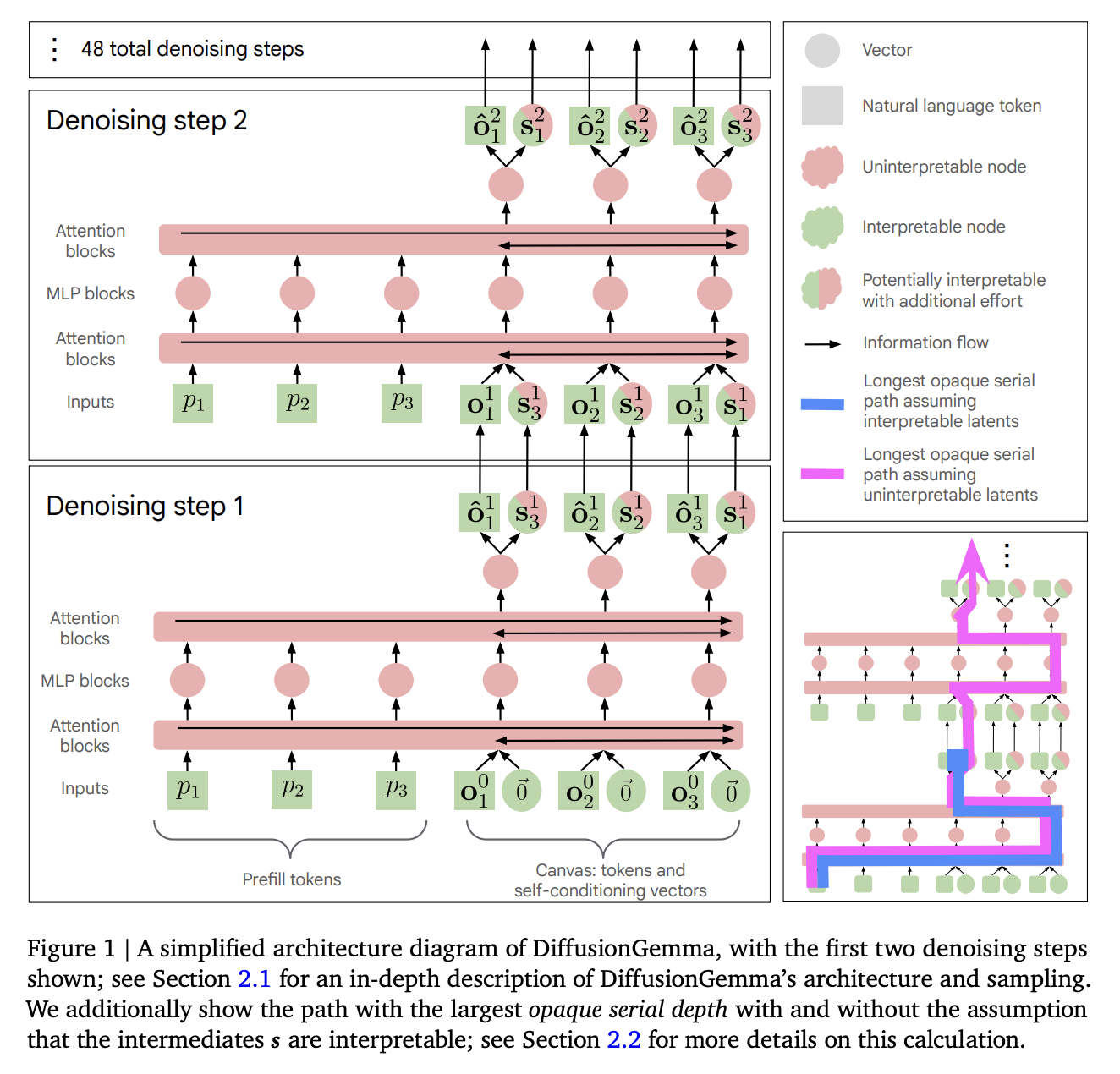
As expected, the opaque serial depth for DiffusionGemma is much larger (28.6X) the corresponding Gemma model. But if we were able to show the intermediates were interpretable, this would drop to 1.1X.
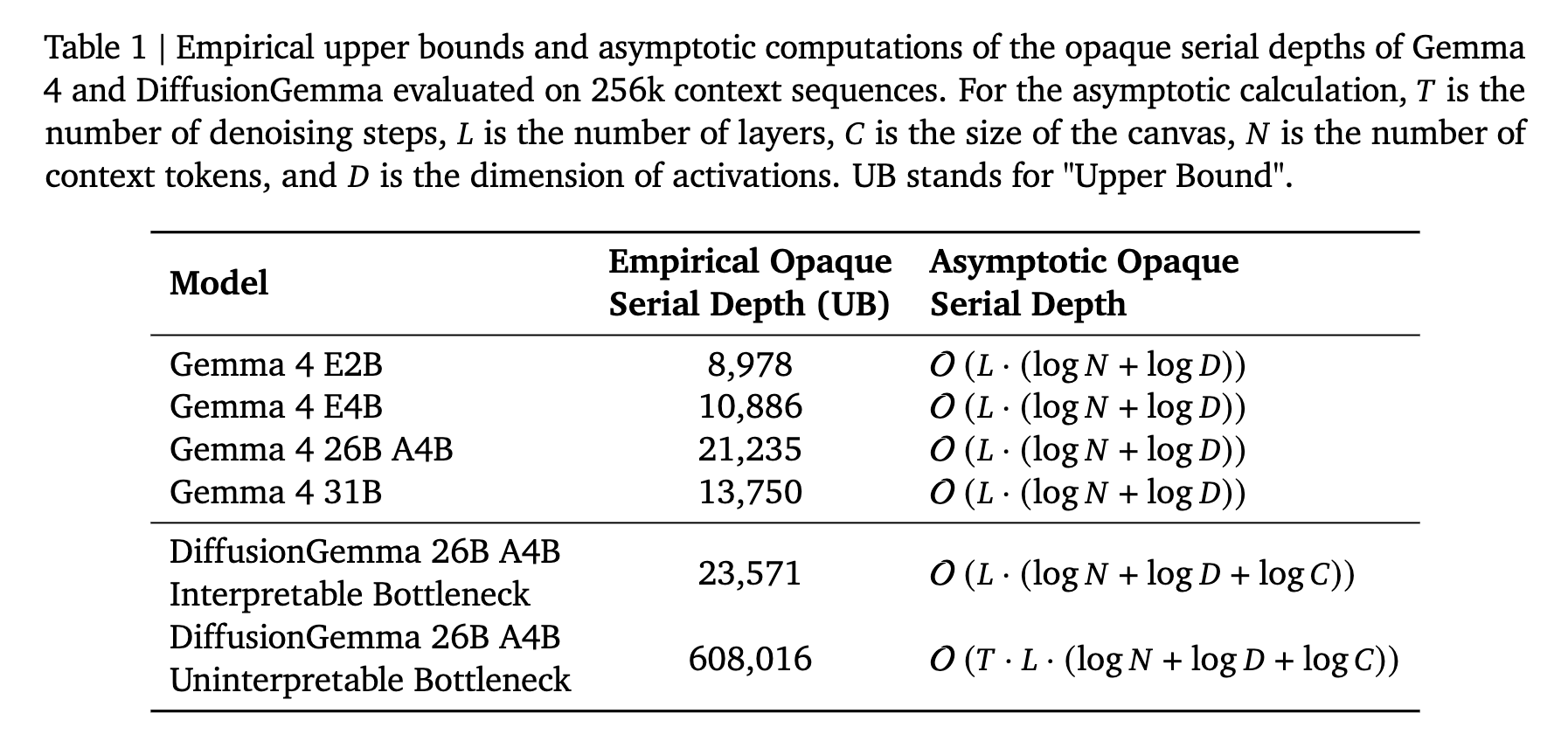
When we replace the intermediate self-conditioning vectors with their top-k or top-p tokens, we maintain most performance on downstream benchmarks:
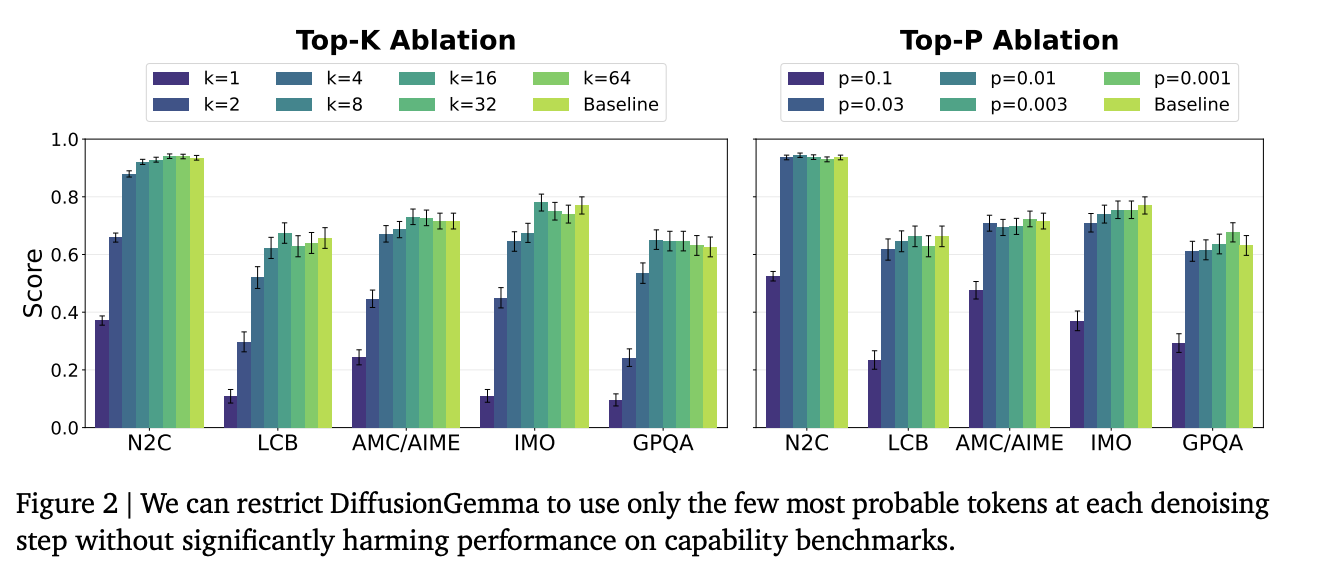
For the top-p interventions, these top tokens are mostly equal to or semantically similar to nearby tokens in the final canvas tokens. Thus, they are largely interpretable.Note that even the 10% of tokens in the first few canvases that do not fall into these categories may still be interpretable; they may be guesses for other meanings of the sentence, or may be interpretable intermediates that the model is using to reason. We are interested in further work that investigates intermediate tokens the model is confident in that are not similar to any final tokens.
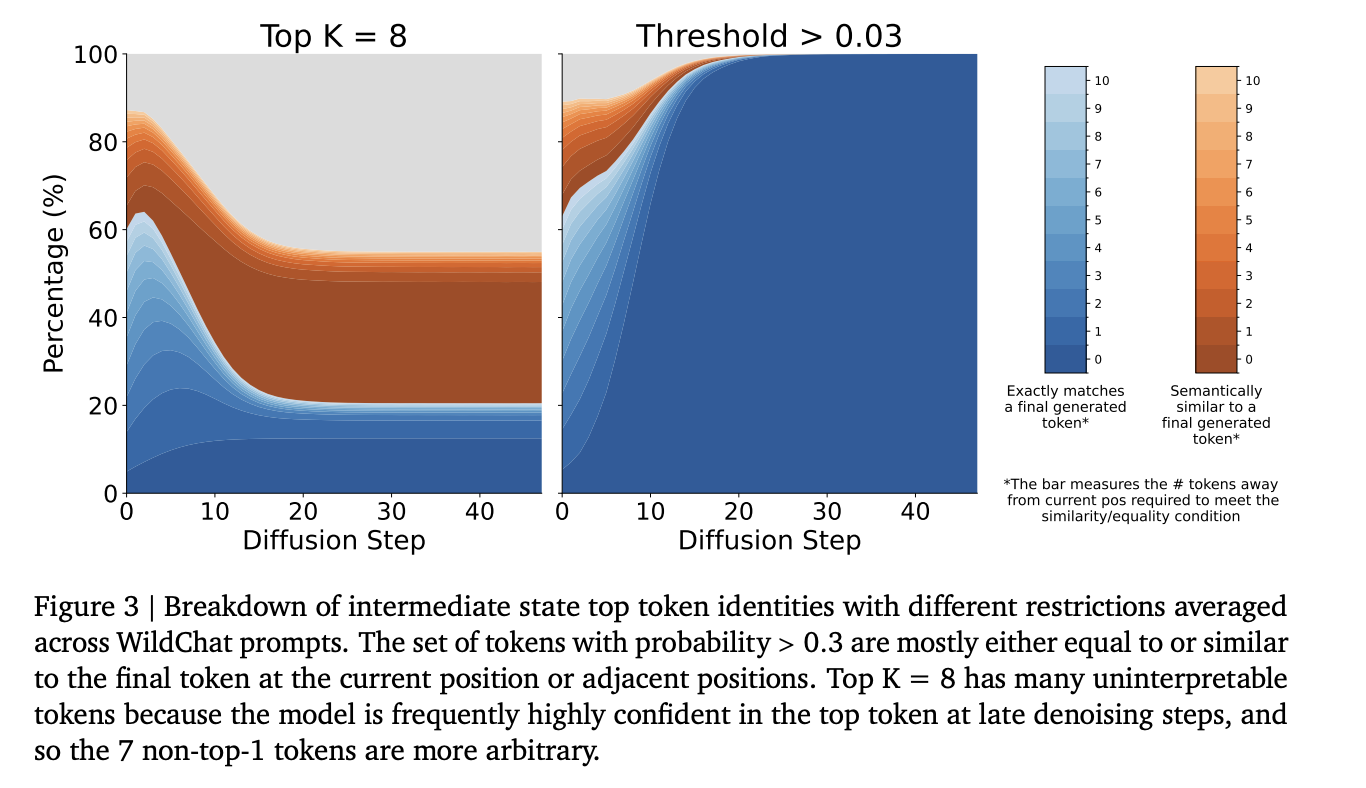
Monitorability, a key downstream application of transparency, is similar between Gemma and DiffusionGemma:
形成互补。
Ch17.010 Multimodal AI for Searchable Aerial Imagery at Scale¶
📊 Level ⭐⭐ | 6.0KB |
entities/multimodal-ai-searchable-aerial-imagery-aws.md
Multimodal AI for Searchable Aerial Imagery at Scale¶
将航空影像库转化为自然语言可搜索知识库的完整技术方案:多模态嵌入 + LLM 图像描述 + 向量检索。
核心问题¶
传统航空影像分析依赖逐瓦片人工检查或为每个新问题训练定制 CV 模型。本文提出用多模态嵌入 + LLM captioning 构建自然语言可搜索的地理空间知识库。
技术架构¶
- 多模态嵌入:将航空影像转换为统一向量空间,支持文本-图像跨模态检索
- LLM 图像描述:自动生成每张影像的文字描述,丰富语义索引
- 向量检索:用户用自然语言查询即可定位相关影像区域
- SageMaker Processing Jobs:规模化处理 TB 级影像数据
应用场景¶
- 保险:自动识别屋顶损坏、洪水风险区域
- 房地产:基于周边环境特征的物业评估
- 政府/基建:城市规划变化检测、基础设施监控
- 农业:作物健康监测、灌溉系统分析
技术亮点¶
- 解决了传统 CV 模型"一个问题一个模型"的低效模式
- 多模态嵌入允许零样本(zero-shot)查询新类型问题
- 端到端 Pipeline 从影像采集到可搜索索引的自动化
- 可扩展到 TB 级数据量的实际生产架构
深度分析¶
多视图融合是航空影像搜索的核心瓶颈¶
航空影像与消费者照片的根本区别在于:每个地理位置有 7 个互补视角(正射 + 4 个斜视 + DSM + DTM)。实验表明,没有单一融合策略在所有特征类型上占优:对于游泳池,Cohere batch、注意力融合和 late average 三者并列 F1=0.638;但对于道路,注意力融合领先(0.535)而 Cohere batch 跌至末位(0.479)。这意味着生产系统必须支持多种融合策略的动态切换,而非固定一种。
LLM Captioning 是性价比最高的单一优化¶
实验中最令人惊讶的发现:caption 集成策略的影响超过了嵌入模型的选择。加入 caption 后,游泳池 F1 提升 11%(0.573→0.638),道路提升 13%(0.490→0.555)。更关键的是,Cohere Embed v4 和 Amazon Nova 在最优 caption 配置下达到相同 F1 分数——caption 提供的文本语义锚点弥补了视觉嵌入质量的差异。但纯文本搜索(无图像嵌入)F1 下降 17%,说明视觉信号仍不可替代。
评估框架设计比模型选择更重要¶
AWS GenAIIC 与 Vexcel 的合作模式值得借鉴:先建评估框架(基于 OpenStreetMap 地面真相),再做架构决策。这种"先量后调"的方法使团队能在数小时内测试约 100 种配置,而非数周。双评估模式(tile-based vs entity-based)揭示了特征分布的关键信息:两种模式的差距越大,说明特征越集中在少数密集 tile 中。
K 值选择是被忽视的关键参数¶
向量检索的 K 值选择对稀疏和密集特征的影响截然相反:稀疏特征(如游泳池)用大 K 会淹没精度,密集特征(如道路)用小 K 会截断召回。最优 K 值接近数据集中实际相关 tile 数量——但这个数量在生产环境中是未知的。实际建议:从 K=10-20 开始,根据 precision-recall 曲线按特征类别调整。
高程数据(DSM/DTM)对标准目标检测无显著贡献¶
实验发现,包含 7 个视角(含高程数据)的配置与仅用 4 个视角(正射+斜视)的配置在标准目标检测任务上表现相当。这意味着对于多数应用场景,可以跳过高程数据的嵌入计算,直接降低 43% 的嵌入成本。
实践启示¶
-
默认选择 Amazon Nova Multimodal Embeddings:在 AWS 地理空间搜索项目中,Nova 在两个基准查询上均取得最高平均 F1 分数,且在道路检测上优势明显(0.555 vs Cohere 的 0.415)。Titan G1 在多个配置下接近零 F1,不推荐。
-
Caption 是必须的,而非可选的:11-13% 的 F1 提升使其成为单一最有价值的优化。使用视觉 LLM 同时分析 7 个视角生成统一描述,比单独处理每个视角效果更好。caption 模型的词汇选择会直接影响下游标签过滤的召回率。
-
构建双模式评估框架:同时使用 tile-based 和 entity-based 评估,两者差距可作为特征分布的诊断信号。使用 OpenStreetMap 作为自动地面真相源,避免手动标注成本。
-
模块化架构设计:将嵌入模型、融合策略、搜索方法、向量存储全部设计为可插拔组件。从 Nova 切换到 Cohere 应该是配置变更而非代码变更——这使得 100 种配置测试成为可能。
-
按特征类别调优 K 值:不要使用全局固定 K。对于稀疏特征(游泳池、太阳能板)使用较小 K(5-15),对于密集特征(道路、建筑)使用较大 K(20-50)。
与现有实体差异化¶
| 维度 | 本实体 | 现有多模态实体 |
|---|---|---|
| 应用领域 | 航空影像/地理空间搜索 | 语音/文档/通用多模态 |
| 技术栈 | SageMaker + 向量检索 | Bedrock/通用嵌入 |
| 核心创新 | 零样本地理空间查询 | 模态融合/实时推理 |
来源: → 原文存档
Ch17.011 PersonaVLM — 长期个性化多模态大模型¶
📊 Level ⭐⭐ | 5.7KB |
entities/personavlm-personalized-memory.md
概述¶
南京大学 + 字节跳动联合提出(CVPR 2026 Highlight)。解决核心问题:大模型是"静态系统",而真实用户是"动态的"——偏好会改变,情绪会波动,性格会在长期互动中逐渐显现。 核心贡献:五类记忆分层 + 大五人格动态追踪 + 双阶段协作流,在 Persona-MME 评测基准上提升超 20%。
五类记忆分层结构¶
与 Agent Memory 架构本质 的六维度记忆单元相比,PersonaVLM 的记忆分层更贴近认知心理学框架: | 类型 | 功能 | |------|------| | 性格画像 | 大五人格量化追踪,动态更新 | | 核心记忆 | 用户基础属性(身份、职业) | | 语义记忆 | 跨模态抽象知识(偏好习惯) | | 情景记忆 | 带时间戳的原子事件,按主题检索 | | 程序性记忆 | 长期目标 + 重复性行为模式 | 关键发现:标准 RAG 在偏好理解任务上性能下降 9.3%,说明未经加工的原始记忆反而会引入噪声。这与 中"蒸馏≠记忆(归档)"的洞察高度一致——记忆需要结构化处理,而非简单堆砌。
双阶段协作流¶
- Response Stage:多步推理 → 选择性记忆检索 → 性格感知回答生成
- Update Stage:性格演变机制触发 → 性格评分微调 → 四类记忆库增删改查
评测基准 Persona-MME¶
- 7维度:记忆、意图、偏好、行为、关系、成长、对齐
- 14细粒度任务
- 200虚拟角色
- 揭示:闭源模型长期个性化能力优于开源,但尚无全能型选手
深度分析¶
1. 从静态系统到动态人格建模 现有大模型本质是"查询-回答"的静态映射,而 PersonaVLM 试图引入时间维度——将用户视为不断演化的心理实体。大五人格(Big Five / OCEAN)作为量化框架不是新思路,但将其嵌入多模态大模型的记忆更新循环中是首次。 2. 记忆分层 vs 朴素 RAG 的本质差异 传统 RAG 将所有历史对话平等地存入向量数据库,检索时 top-k 匹配。PersonaVLM 的五类记忆做了两件事:
- 结构化蒸馏:情景记忆按时间戳原子化,程序性记忆提取重复模式,而非保留原始对话
- 人格感知的检索偏置:性格画像在 Response Stage 阶段影响检索权重和生成风格 这解释了为什么标准 RAG 反而下降 9.3%——噪声检索稀释了真正有意义的人格一致响应。 3. 双阶段协作流的工程启示 Response Stage 和 Update Stage 的解耦设计值得借鉴:交互时专注生成(低延迟),交互后异步更新记忆(对延迟不敏感)。这与 Hermes-Agent 自进化机制 中的"思考后阶段"有相似逻辑——将高成本推理从关键路径剥离。 4. 开源模型的个性化能力短板 开源多模态小模型在个性对齐任务上仅略优于随机,说明个性化不是靠 Scale(扩大模型参数)就能解决,需要专门的记忆架构设计。Qwen3 纯语言模型相对优异,暗示语言模态的个性化可能比多模态更容易建模。
实践启示¶
- 记忆需要分层而非堆砌:在设计 Agent 记忆系统时,应根据记忆类型(身份/语义/情景/程序)采用不同的更新和检索策略,而非统一向量存储。
- 人格追踪是差异化的关键:对于需要深度个性化交互的场景(如心理咨询、长期教育辅导、个性化助手),引入可更新的用户性格模型能显著提升用户体验。
- RAG 不是银弹——加工优于存储:未经结构化处理的原始记忆引入噪声,应用层应包含记忆"蒸馏"步骤(提取模式、删除冗余)。
- 将更新与响应解耦:对于非实时性需求(如性格评分微调),利用对话间隙异步处理,可保持响应延迟低且记忆更新充分。
- 多模态个性化的难点:当前多模态模型在个性对齐上弱于纯语言模型,实操中可考虑先用语言模态建立用户画像,再迁移到多模态交互中。
核心洞察¶
从"回答问题"走向"理解用户" 真正的个性化 = 持续演化的理解过程,而非静态标签。
相关页面¶
- ChatGPT Memory — OpenAI 的记忆实现对比
- 原文存档
相关实体¶
Ch17.012 LiteFrame: Efficient Vision Encoders Unlock Frame Scaling in Video LLMs¶
📊 Level ⭐⭐ | 5.2KB |
entities/liteframe-efficient-vision-encoders.md
核心要点¶
- Efficient Vision Encoders for Vision-Language Models
相关实体¶
- Liteframeefficientvisionencodersunlockframescalinginvideollms
- Trackingtamperedchefclustersviacertificateandcodereuse
- Agentexecutorgooglesdistributedagentruntime
- How To Calculate The Inference Efficiency Ratio
- Aws Sun Finance Ai Id Extraction Fraud Detection
→ 原文存档
深度分析¶
视频 LLM 扩展到长视频的核心瓶颈在于视觉 token 上下文长度的爆炸性增长。LiteFrame 论文指出,现有的主流策略是"post-hoc" token reduction——即在特征提取后减少视觉 token 以减轻 LLM 的计算开销 。然而,论文观察到一个关键问题:当这些 token reduction 方法有效减少了 LLM 的 token 数量后,主要延迟瓶颈就从 LLM 转移到了 vision encoder 的逐帧处理上 。这意味着单纯减少 token 数量并不能从根本上解决效率问题。
LiteFrame 提出的解决思路是同时优化 vision encoder 和 LLM 两端。具体方案包含两个核心组件:Compressed Token Distillation (CTD) 和 Language Model Adaptation (LMA) 。CTD 的核心思想是训练一个紧凑的 student vision encoder,让它直接预测来自大型 teacher vision model 的信息密集型、时空压缩表示,从而绕过冗余计算 。LMA 则是一个轻量级的微调阶段,用于对齐压缩后的潜在空间与下游 LLM,使其能够无缝处理扩展的时间上下文(最多 512 帧) 。
LiteFrame 在性能上展示了令人印象深刻的结果。在 Video-MME、MLVU 和 LongVideoBench 等多个视频理解基准测试中,LiteFrame 实现了新的延迟-精度 Pareto 前沿 。具体而言,LiteFrame 能够在固定计算预算下处理 8 倍更多的帧,总推理延迟(vision encoding + LLM prefilling)降低高达 35%,同时视频理解精度保持提升 。参数规模上,student encoder 仅使用 87M 参数,相比 teacher 模型的 304M 参数大幅减少 。
从架构设计角度看,LiteFrame 的 student encoder 通过 depth-wise 1D convolutions 进行时间建模,使用 strided convolutions 进行下采样,显著降低了 FLOPs 和延迟 。值得注意的是,这种设计在 token 效率上的内在优势使得高分辨率视频的空间分辨率扩展成为可能——LiteFrame 在 HLVid 上实现了无需高分辨率训练即可达到 state-of-the-art 分数的零样本空间分辨率扩展能力 。
LiteFrame 的研究来自 Google DeepMind 和首尔国立大学,其方法论反映了当前视频 AI 高效推理领域的一个核心趋势:将知识蒸馏与自适应机制结合,在压缩模型规模的同时保持甚至提升任务精度。这为在资源受限环境中部署长视频理解应用提供了可行的技术路径 。
实践启示¶
-
视频 LLM 效率优化的重心已从 LLM 转向 Vision Encoder:当 token reduction 技术将 LLM 端瓶颈消除后,vision encoder 的逐帧处理成为新的主要延迟来源。未来的视频 AI 系统设计需要将 vision encoder 的效率优化与 LLM 端优化放在同等重要的位置 。
-
知识蒸馏是实现高效视频编码器的有效路径:CTD 通过让 student encoder 直接预测 teacher 压缩表示来绕过冗余计算,这意味着在设计视频 AI 系统时,可以利用大模型作为 teacher 指导小模型的训练,而非仅依赖手工设计的压缩规则 。
-
关注延迟-精度的 Pareto 前沿而非单一指标:LiteFrame 的核心贡献是实现了新的 Pareto frontier,这意味着在评估视频 AI 方案时,应该在不同精度水平下测量延迟,选择在目标精度下延迟最低或在目标延迟下精度最高的方案 。
-
帧数扩展能力是长视频理解的关键:LiteFrame 能处理 8 倍更多的帧,这直接打开了长视频(如完整电影、体育赛事)理解的可能性。对于需要处理小时级视频内容的应用,应该优先考虑支持长上下文架构的方案 。
-
参数效率的量级突破具有部署意义:从 304M 减少到 87M 参数的突破,使得在边缘设备上运行视频理解变得更加可行。对于需要 on-device 视频分析能力的应用,这种参数规模的压缩是实现产品化的关键一步 。
Ch17.013 别让格式杀死思想logics-parsing-v2定义文档解析新边界¶
📊 Level ⭐⭐⭐ | 13.0KB |
entities/别让格式杀死思想logics-parsing-v2定义文档解析新边界.md
别让格式杀死思想:Logics-Parsing V2定义文档解析新边界¶
我们总以为拍下即留存,却常被"看得见、用不了"的内容困住:
- 此前在图书馆里拍摄的重要书籍页面却因为当时光线不佳,现在转文字时无法识别;
- 导师发来一份多年前的扫描版学术论文PDF,关键公式识别乱码,只能手动重新敲打;
- 开发者截图一段 GitHub 代码,识别后格式全无,需要手动调整缩进才能理解;
- 书本中纵横交错的思维导图,拍得下全貌却抓不住逻辑,想引用时只能对着照片重新构图;
- 谱架上那页珍贵的手写乐谱,承载着旋律却无法数字化,难以编辑或分享给伙伴。 格式本应是思想的容器,而非牢笼。 Logics-Parsing V2解析能力全新升级, 不止于文本,读懂更多数据的结构和逻辑。 现在,无论是一篇紧凑的学术论文复印件、一页复杂的财务报表扫描件,还是一张跳动的乐谱图片、一个包含思维导图或伪代码的网页截图——Logics-Parsing V2 都能穿透像素的屏障,将其转化可编辑、可搜索的结构化数字资产。让信息不再只是被"看见",而是被真正"唤醒"。 ** 01 ** ** Logics-Parsing V2 核心能力 **
轻松实现端到端处理¶
- 单模型端到端实现各类文档的识别和解析
- 处理报纸、杂志等复杂版面文档更加游刃有余
先进的内容元素识别能力¶
- 无惧复杂排版,密集文字、复杂表格、科学公式、化学符号都能精确识别
- 拓展 Parsing 2.0 识别能力,乐谱、思维导图、代码伪代码也能精准还原
丰富的结构化输出¶
- 模型生成简洁的QwenVL HTML来表示文档,并标记元素类别、位置,保留其逻辑结构
业界领先的性能表现(SOTA)¶
- Logics-Parsing-V2不仅在自建评测集LogicsDocBench上取得了业界最佳(SOTA)的效果,同时在权威的公开评测集OmnidocBench-v1.5上也取得了端到端模型SOTA效果(总分93.23) github: https://github.com/alibaba/Logics-Parsing demo: https://www.modelscope.cn/studios/Alibaba-DT/Logics-Parsing/summary 模型地址: https://huggingface.co/Logics-MLLM/Logics-Parsing-v2https://www.modelscope.cn/models/Alibaba-DT/Logics-Parsing-v2 ** 02 ** ** 对比 Logics-Parsing升级了什么? ** Logics-Parsing-V2是去年9月开源的Logics-Parsing的升级版本。它继承了Logics-Parsing模型的所有核心功能,同时在处理复杂文档方面展现出更为强大的性能,并且进一步扩展了对 Parsing-2.0 场景的支持,实现了对乐谱、流程图、思维导图以及代码/伪代码块的结构化解析。模型大小也从8B下降到了4B,推理更快。 ** 03 ** ** 训练范式与数据双轮驱动 ** Logics-Parsing-V2是基于多模态大模型的端到端文档解析模型,在Qwen3-VL-4B的基础上,采用SFT+GRPO两阶段方式训练而成。我们同时针对真实解析场景的复杂任务,构建了以复杂版面和STEM学科为特色的高质量解析数据集,其不仅涵盖多栏报纸、学术海报等极具挑战的版面,更延伸至 Parsing-2.0 场景,覆盖化学分子式、五线谱、代码/伪代码块、流程图与思维导图。另外在复杂版面文档的解析过程中,创新性地引入基于布局的强化学习机制,设计识别、检测、阅读顺序的多维度奖励机制,显著提升模型在复杂文档布局下的结构理解与内容排序能力。 ** 04 ** ** 模型表现如何? **
权威开源评测OmniDocBench_v1.5评测:端到端模型SOTA¶
自建 LogicsDocBench 深度测评:展现复杂文档解析的全维度领先实力¶
LogicsDocBench介绍¶
LogicsDocBench为自建综合评估基准,由 900 页精心挑选的 PDF 页面组成,涵盖了传统的 Parsing-1.0 任务以及新引入的 Parsing-2.0 场景。该基准旨在更全面地评估模型在解析复杂且多样化的真实世界文档时的能力,LogicsDocBench近期将会开源。该数据集分为三个核心子集: ** STEM 文档 ** 侧重于高难度的学术和教育内容,涵盖物理、数学、工程和交叉学科等十多个领域。该子集旨在评估模型对数学公式、技术术语和结构化知识表示的深层理解。 ** 复杂布局 ** 包含具有挑战性的真实世界布局,如多栏文本、跨页表格、竖排书写以及图文混排。该子集用于全面评估模型的布局分析能力。 ** Parsing-2.0 场景 ** 针对对传统 OCR 系统构成了重大挑战的现代数字化和半结构化内容,包括:
- 化学分子式
- 乐谱
- 代码和伪代码块
- 流程图和思维导图 各模型在LogicsDocBench的表现 ** 05 ** 复杂案例效果展示 点击 " 欢迎留言一起参与讨论~
深度分析¶
一、从 Parsing-1.0 到 Parsing-2.0 的范式跃迁 传统文档解析(Parsing-1.0)聚焦于文本OCR与版面恢复,核心挑战是"把字认出来、把排版还原"。Logics-Parsing V2 将边界推进至 Parsing-2.0——处理非纯文本的"结构化视觉内容":乐谱、思维导图、流程图、化学分子式、代码块。这些内容在像素层面是图像,但本质上是携带逻辑关系的数据结构。V2 的核心突破在于:用单一端到端模型而非级联 pipeline 完成从"感知像素"到"理解结构"的跨越。 二、4B 参数实现 SOTA 的三条技术支柱 1. 基础模型选择:基于 Qwen3-VL-4B,而非从头训练的 8B 模型。参数减半但 VL 基座能力更强,为端到端学习提供更好的初始化。 2. 两阶段训练:SFT(监督微调)建立基础解析能力 → GRPO(基于布局的强化学习)针对复杂版面优化阅读顺序与元素定位。强化学习的引入是亮点——通过设计识别、检测、阅读顺序的多维度奖励信号,解决传统端到端模型在多栏文档、跨页表格上的排序幻觉问题。 3. 数据构建:以复杂版面 + STEM 学科为特色构建高质量数据集,覆盖 Parsing-2.0 全场景。高质量域内数据是垂直任务微调效果的关键。 三、QwenVL HTML 结构化输出的设计意图 模型输出 QwenVL HTML 而非纯文本或 JSON,意图是在保留结构信息的同时兼容人类可读性与后继解析。HTML 标记携带元素类别与位置信息,使输出可直接作为知识库索引或编辑工具的输入,降低了 downstream 应用的接入门槛。 四、开源生态布局 阿里选择开源模型(GitHub + HuggingFace + ModelScope 三端同步)而非仅提供 API,意在构建开发者生态。4B 参数量级使本地部署成为可能,覆盖对数据隐私敏感的企业场景。Demo 页面的存在也指向直接面向终端用户的体验引导。
实践启示¶
给 AI/ML 研究者
- GRPO + 多维度奖励机制在文档结构理解上的成功,提示强化学习在视觉-语言任务中仍有未被充分挖掘的结构化推理空间
- Parsing-2.0 场景(乐谱、流程图、化学分子式)是下一个 OCR 能力分水岭,早于 GPT-5 发布前的时间窗口值得关注
-
端到端模型压缩至 4B 意味着结构化文档解析已进入"可边缘部署"阶段,on-device AI 成为可能 给开发者
-
Logics-Parsing V2 的 GitHub 仓库已开源,可直接集成到文档处理 pipeline(PDF 扫描件数字化、学术论文结构化提取、代码截图重格式化)
- 模型支持 HuggingFace 格式,本地推理成本低,适合企业内部知识管理场景(扫描合同→可编辑文本)
-
输出 QwenVL HTML 可直接转换为结构化数据,无需额外解析层 给企业和教育机构
-
历史档案数字化:扫描版学术论文、手写乐谱、书籍照片等传统 OCR 无法处理的内容,现在可结构化提取
- 教学资源建设:将纸质教材、试卷、报刊文章转化为可编辑、可搜索的数字资产,大幅降低数字化成本
- 代码与设计稿复用:截图代码自动格式化还原、思维导图照片转可编辑版本,提高知识复用效率
相关实体¶
- Context Not Free Long Document Agent Architecture Raunak
- Joyai Echo Long Video Framework Jd
- Nemotron 3 5 Content Safety
- Xiaomi Ai Icml 2026 11Papers
- Sensnova U1 Deep Dive Jiqizhixin D8602Ded5C51
Ch17.014 CVPR 2026 Highlight | 清华打破多模态音频生成的「通才困境」:Omni2Sound 音频基础模型开源!¶
📊 Level ⭐⭐⭐ | 11.6KB |
entities/cvpr-2026-highlight-清华打破多模态音频生成的通才困境omni2sound-音频基础模型开源.md-> 原文存档
摘要¶
CVPR 2026 Highlight | 清华打破多模态音频生成的「通才困境」:Omni2Sound 音频基础模型开源!
关键要点¶
相关实体¶
深度分析¶
「通才困境」的本质:多模态动态协同与博弈¶
Omni2Sound 论文指出了一个被广泛低估的核心挑战:统一音频生成模型面临的核心问题,不是视觉与文本特征的简单线性叠加,而是极具挑战的多模态动态协同与博弈过程。 这带来两个根本性难题: 难点一:跨模态信息的严重不对称与动态路由困境。 在真实的视听世界里,视觉显著性与声学能量往往不成比例。例如"安静自习的学生耳边飞过一只蚊子"场景——蚊子在视觉画面上极小,但高频嗡嗡声在音频空间里占据绝对主导。纯粹的视频生音频模型大概率只会生成翻书声或白噪音;此时必须引入文本指令作为核心引导。这要求通用模型必须具备极强的动态路由能力——自主领悟在特定瞬间,文本决定生成什么音色,视频仅用来对齐什么时候发声。 难点二:模态间的极端语义冲突与画外音推理。 更复杂的开放场景中,输入文本和视频可能在语义上南辕北辙,或某模态完全缺失。例如画面是平静喝咖啡的人,但文本指令是"窗外突然传来巨大爆炸声"。如果通用模型机械地融合视觉和文本特征,生成的音频必然混乱崩溃。模型必须具备类似人类的逻辑推理能力——敏锐意识到这是画外音场景,果断切断对无用视觉特征的依赖,将生成重心完全偏移到文本指令上。
数据基座坍塌的深层原因¶
当把多个子任务置于同一框架下优化时,模型内部会发生显著的资源竞争与内耗。第一,数据基座的坍塌:多模态数据的语义错位与冲突。 现有主流数据集存在两方面问题: 1. 音频信息的天然多义性:许多视觉和语义上截然不同的事件,其声学特征却高度重合。例如"煎肉时的滋滋油烟声"与"倾盆大雨的白噪音"极易混淆,"篝火燃烧的噼啪声"与"揉搓塑料袋/踩碎干树叶的声音"在频谱上极其相似。 2. 早期音频-语言模型幻觉率高:容易遗漏关键事件或产生错误描述。当模型长期在相互矛盾的监督信号下训练时,多模态对齐能力自然会受到限制。 此外,原生多模态大模型存在显著的视觉偏置(Visual Bias)——画面里出现静止的乐器或挥棒的指挥(实际并未发声),大模型也极易错误推断出对应的音乐;反之,对画面中看不见的真实音源(画外音),模型又容易直接忽略。
任务竞争的三层结构¶
第二,联合训练中固有的任务竞争。
- 跨任务竞争(Cross-task Competition):T2A(文本生音频)和 V2A(视频生音频)在联合优化时常面临相互牵制的局面,提升一方往往以牺牲另一方为代价。
- 模态偏置(Intra-task Modality Bias):在处理 VT2A(图文联合生成)时,模型极易产生依赖单一模态的偏置现象。若过度依赖文本,生成的音频往往与画面动作脱节;若过度依赖视觉信息,在画外音场景时模型会忽略文本指令,产生生成幻觉。
Omni2Sound 的破局思路:Less is More¶
Omni2Sound 的核心思路在于:不过度依赖复杂的网络结构设计,而是通过「高质量数据与渐进式训练」的底层方案来打破通才困境。全篇仅采用标准的 Vanilla DiT 骨干,从数据源头、多任务调度以及客观评测三个维度进行协同设计。 SoundAtlas 数据集构建方法论: 团队设计了一套高效的多轮智能体流水线(Agentic Pipeline),构建了包含 47 万对高质量 V-A-T 联合对齐的数据集 SoundAtlas: 1. 视觉到语言压缩(Vision-to-Language Compression):放弃直接输入原视频,利用视觉模型(如 Qwen-2.5-VL)先将视频画面"压缩"为精简的文本描述。这一设计不仅大幅削减视频 Token 成本,还将强烈的视觉刺激降维成辅助上下文,有效约束了大模型过度依赖画面产生的幻觉倾向。 2. 初高级智能体接力(Junior-Senior Agent Handoff):获取压缩文本与音频后,系统首先调用高性价比的轻量级模型(Junior Agent)生成基础字幕;仅当检测到复杂场景或高频幻觉词汇时,才将任务路由给推理能力更强的模型(Senior Agent)进行复核。 通过这套协同流水线,SoundAtlas 在将数据生成成本降低约 5 倍的同时,产出了高保真度的多模态对齐样本。
三阶段渐进式训练范式¶
Stage 1:大规模 T2A 预训练。 在引入异构的视频条件之前,模型首先利用海量文本-音频数据进行独立的 T2A 训练,为模型建立稳健的音频生成先验。拥有这一基础底座后,在后续多任务阶段仅需保持极低频率的 T2A 数据采样,即可有效防止「灾难性遗忘」。 Stage 2:多任务交织训练。 该阶段旨在解决 V2A 与 T2A 的跨任务竞争。团队采用按任务采样的交织训练策略(Task-Balanced Sampling),避免不同任务在同一批次内发生梯度冲突。更重要的是,高质量的 VT2A 数据在联合训练中起到了关键的「语义桥梁」作用——由于 VT2A 强迫模型同时对齐文本、视频与音频,它有效拉平了视觉特征与语言特征的异构空间,将原本相互竞争的跨任务目标转化为了底层特征的协同优化。 Stage 3:解耦的鲁棒性训练。 尽管第二阶段缓解了跨任务竞争,但模型在处理具体输入时仍存在对单一模态的依赖倾向。团队将其解耦至第三阶段独立进行,采用两种互补策略:
- 文本 Dropout:通过随机遮蔽文本提示,迫使模型更多地依赖视觉流,显著增强音视频的时空同步性。
- 画外音合成(Off-screen Synthesis):通过引入无可视发声源的合成数据,强制模型在缺乏视觉线索时提升对文本指令的依赖,从而有效缓解画外音场景下的幻觉问题。
实践启示¶
数据质量优先于模型复杂度的范式转移¶
Omni2Sound 最重要的实践启示是「大道至简(Data & Strategy is all you need)」的有效性。 通过高质量的基石数据搭桥,配合科学的渐进式任务调度,一个朴素的标准 DiT 模型完全可以打破「通才困境」。 这对多模态融合研究的启发是:
- 不要急于设计复杂的统一架构,而要先审视底层数据质量
- 模态对齐的缺失是很多"统一模型"表现不佳的根本原因,而非架构不够复杂
- 多模态数据的「语义冲突」问题需要从数据工程层面系统性解决,而非靠模型自行发现
Agentic Pipeline 在数据标注中的高价值¶
SoundAtlas 的智能体流水线展示了多模型协作在数据标注领域的巨大效率提升:
- 轻量级模型负责基础任务,仅在复杂场景才升级到重推理模型
- 5 倍成本降低的同时,质量优于人类专家标注
- 这个「初高级 Agent 接力」模式可推广到任何需要高质量、大规模数据标注的场景
渐进式训练的三阶段设计原则¶
三阶段渐进式训练解决了「直接联合训练」引发的任务竞争问题。 关键设计原则: 1. 先建立基础能力,再引入多任务:T2A 预训练建立了稳健的音频生成先验,避免后续多任务学习中的灾难性遗忘 2. VT2A 作为语义桥梁:高质量的图文联合数据在多任务协调中起到关键的「过渡」作用 3. 解耦的鲁棒性训练:将对抗性训练(文本 Dropout、画外音合成)单独处理,避免影响主训练阶段的优化动态
画外音场景的评测设计填补了行业空白¶
VGGSound-Omni 基准引入的画外音(Off-screen)专属评测赛道,为评估模型在非理想视觉条件下的文本忠实度与抗幻觉能力,提供了可靠的客观依据。 这提醒我们:
- 评测基准设计本身是研究的核心贡献
- 专门设计对抗性评测场景(画外音、BGM 合成子集)才能真正检验模型的鲁棒性
- 现有评测往往只覆盖「正常情况」,忽略了真实场景中的模态缺失和语义冲突 → 原文存档
Ch17.015 Self-Filming Guide by Hello World Media¶
📊 Level ⭐⭐⭐ | 11.5KB |
entities/helloworldmedia.notion-Self-Filming-Guide-by-Hello-World-Media-2f60dfa5e2e180cfa.md
1. Camera Setup | 相机设置¶
iPhone ProRes Log 设置(需调色时)¶
如计划进行后期调色(color grade),建议开启 Log 格式以获得最大调色空间。iPhone 需配置 Apple ProRes: 1. Settings > Camera > Formats,开启 Apple ProRes 2. ProRes Encoding 设为 Log 3. 在相机 App 中启用 Log 选项 4. 分辨率设为 4K,24fps,曝光略微欠曝 -1.0 5. 横向拍摄,比例 16:9
[!warning] Log 格式会占用大量存储空间,确保提前清理空间或导出到硬盘。 画面在屏幕上看起来灰蒙蒙或褪色是正常现象——这是 Log 格式故意保留高光和阴影细节的表现, 不要在此阶段调整颜色或添加滤镜 。 如不确定或未看到 Log 选项,跳过此步骤即可。
Pixel Pro 系列 Log 设置¶
Log 录制功能主要适用于 Pixel 8 Pro、Pixel 9 Pro、Pixel 9 Pro XL 及以上机型。步骤如下: 1. 打开 Camera App,切换到底部 Video 模式 2. 点击左下角设置(齿轮图标)或向上滑动取景框 3. 选择 Pro 模式 4. 分辨率选 4K,帧率选 24fps(电影感) 5. 在 Video Coding 中选择 Log(注意:这会自动禁用 "10-bit HDR")
[!tip] 非 Pro 版 Pixel 或旧款机型原生 App 不支持 Log,推荐使用第三方 App:Filmic Pro 或 Blackmagic Camera。 Log 文件体积远大于标准 MP4,拍摄前确保存储空间充足。
基础拍摄规范¶
- 使用后置摄像头而非前置自拍摄像头
- 相机置于眼线高度
- 头顶上方留出空间(不要把人顶格构图)
- 拍摄前擦拭镜头
- 建议购入简单 iPhone 三角架,便于调整角度和稳定画面
2. Lighting | 照明¶
自然光优先¶
尽量选择有大窗户的房间,让自然光透入——这能以最小成本提升画面质感 。
布光原则¶
| 原则 | 说明 |
|---|---|
| Shadow side of face | 人物脸部朝向阴影侧,而非被光直射的一侧 |
| Key light 与自然光一致 | 添加主光源时,角度应与自然光方向一致 |
| White balance | 若使用人造光源,白平衡偏白(4400k–4600k),与自然光保持一致 |
| Diffuse(散射) | 用白色薄布(sheet)将光线散射,不要直接照射面部,让光线均匀分布在脸上 |
布光技术¶
Split Lighting(分侧布光):将人物脸部一半照亮、一半处于阴影中。灯光置于被摄体侧方,可搭配黑色绒布制造 negative fill(负填充),确保另一侧足够暗。 Short Lighting(短光):主光照射脸部离相机较远的一侧(face's far side),使脸部的宽阔侧(broad side)处于阴影中,营造更多对比和戏剧感。
3. Audio | 音频¶
麦克风¶
建议购入 lav mic(领夹麦克风),例如 DJI Lab Mic($100 以下),支持 USB-C 直插手机,适合远距离收音和未来访谈录制。
环境规则¶
- 选择最安静的房间
- 关闭风扇、空调及其他产生背景噪音的设备
- 做 10 秒测试录音并回听确认
[!warning] 即使有 AI 降噪工具,背景噪音过大的音频也难以处理——类比来说,就像无法把烤好的蛋糕还原成生面团。 后期会进行音频清理和压缩,但请确保录制时没有背景噪音,必要时重录。
4. On-Camera Performance | 镜头表现¶
- Pitch 心态:想象自己在《广告狂人》(Mad Men)里推销广告概念,给镜头注入能量(oomph)
- 眼神:直视镜头
- 表情:用眼睛微笑(smile with your eyes),营造亲切感
- 手势:自然时可以使用手势,但不要过度
深度分析¶
核心优先级框架¶
本文建立了清晰的拍摄优先级金字塔:Story(叙事) > Lighting(照明) > Audio(音频)。这一框架与专业影视制作原理高度一致——叙事是灵魂,视觉和听觉是呈现质量的瓶颈。指南的核心价值在于将"专业视频制作"这一通常需要完整团队的概念,压缩为单人可操作的最低可行方案。
Log 格式的战略意义¶
Log 录制在专业影视制作中是标准化流程,但在消费级内容中极少被提及。本文将 Log 格式定位为"可选但推荐"选项,体现了务实的专业主义——既不强制要求增加后期复杂度,又为有调色需求的用户提供了清晰路径。这种处理方式与苹果和谷歌将 Log 隐藏在专业模式中的产品设计思路一致。
布光方法论的文化根源¶
本文介绍的 Split Lighting 和 Short Lighting 技术源自好莱坞经典Portrait Photography 传统。Split Lighting 通过创建明暗分界来增强戏剧感,Short Lighting 则通过照亮脸部远离镜头的一侧来营造神秘感和深度。这种方法的本质是通过控制阴影来控制视觉注意力,与文艺复兴时期的明暗对比法(Chiaroscuro)有相同的视觉原理。
音频优先原则的技术依据¶
"无法从不安静的音频中恢复人声"——这一警告基于信号处理的物理限制。AI 降噪工具(如Adobe Podcast Enhance、 Podcastle 等)在信噪比尚可时效果显著,但当背景噪音能量接近人声时,频谱重叠使得分离在数学上几乎不可能。"无法把烤好的蛋糕还原成生面团"这一类比精准描述了这一不可逆过程。
手机摄影的民主化效应¶
本文的实质是"将数万美元专业设备的价值提炼到百元级消费方案"。iPhone ProRes Log、Pixel Pro 系列的 Log 支持、三脚架、领夹麦克风——这些加起来总价不超过 $200,但能达到专业商业视频的视觉标准。这种 democratization of professional production 正在深刻改变品牌内容生产的成本结构。¶
实践启示¶
拍摄前检查清单(10 分钟准备流程)¶
- 存储检查:确认至少有 10GB 可用空间(Log 模式 1 分钟约 1GB)
- 镜头清洁:用微纤维布擦拭前后摄像头
- 相机设置:后置摄像头 → 4K 24fps → 眼线高度 → 头顶留白
- 环境扫描:关闭所有产生噪音的设备,选择最大窗户的房间
- 布光预判:确认自然光方向,将脸部置于阴影侧
- 音频测试:10 秒录音回放,确认无背景噪音
- 设备清单:三脚架固定 → Lav Mic 连接测试 → 开始录制
布光场景决策树¶
有自然大窗户?
├── 是 → 脸部对窗,背对其他光源,自然光为主光
└── 否 →
├── 单光源方案 → 灯置侧面,扩散布,距离面部 45°
└── 双光源方案 → Key light(角度与窗光一致)+ 填充光(柔光箱)
音频降噪优先级¶
在所有后期处理之前,音频质量问题的优先级最高:
- 录制时:选择最安静房间,关闭所有设备,做 10 秒测试
- 后期前:如果背景噪音明显,立即重录而非依赖降噪工具
- 降噪工具:作为最后手段,用于处理风声、HVAC 等规律性低频噪音
从本文延伸的核心能力¶
掌握本文技术后,可进一步探索的方向:
- 色彩匹配:多镜拍摄时的色彩一致性处理
- 稳定器:手持运镜的节奏感训练(Gimbal / DJI OM 系列)
- 剪辑节奏:30 秒 vs 60 秒 vs 3 分钟内容的信息密度设计
- 脚本结构:开场钩子、前 3 秒注意力捕获、CTA 转化路径
来源:原文存档
相关实体¶
- Helloworldmedia.Notion Self Filming Guide By Hello World Media 2F60Dfa5E2E180Cfa
- Self Filming Guide By Hello World Media 2F60Dfa5E2E180Cfa6Efcef23C882E57
- How To Build Audio Transcription Agent
- Stable Audio 3
Ch17.016 Gemma 4 12B:Google 多模态本地模型 —— 扔掉编码器¶
📊 Level ⭐⭐⭐ | 11.1KB |
entities/gemma-4-12b-google-multimodal-local.md
Gemma 4 12B:Google 多模态本地模型 —— 扔掉编码器¶
"把原本需要高端服务器才能跑的多模态智能,装进你的笔记本电脑里。"
"这种统一、无编码器的架构,带来的直接好处是:延迟更低,内存更省。"
Google DeepMind Gemma 4 12B——把多模态智能装进笔记本电脑的本地模型。核心架构创新:扔掉视觉/音频编码器(视觉用极轻量嵌入模块、音频原始信号直接投影到文本 token 维度空间)。硬件门槛:16GB 显存或统一内存(MacBook Air M5 可跑)。Apache 2.0 + 多框架支持。
相关实体¶
一句话定位¶
"扔掉编码器" = 多模态架构新趋势 —— 视觉用轻量嵌入(一次矩阵乘法 + 位置嵌入 + 归一化)/ 音频原始信号直接投影到文本 token 维度空间 = 延迟更低 + 内存更省
1. 定位:填补 Gemma 家族关键空缺¶
- 比边缘端 E4B 更强
- 比 26B 混合专家(MoE)模型更轻
- 整个 Gemma 4 系列里,第一个支持原生音频输入的中等规模模型
2. 性能与硬件门槛¶
性能: - Gemma 4 12B 在标准评测基准上接近 26B MoE 模型 - 总内存占用还不到 26B MoE 的一半
硬件门槛: - 只需 16GB 显存或统一内存 - 消费级笔记本电脑即可运行 - 入门级 MacBook Air(M5)就能跑
"多模态理解加上 Agent 能力,直接在本地跑,不用联网,不依赖云端。"
3. 本地体验入口¶
- LM Studio(作者首选)
- Ollama
- Google AI Edge Gallery App
- Google AI Edge Eloquent 应用(直接看完全离线的语音转录 / 格式化 / 翻译效果)
- LiteRT-LM CLI
"我已经第一时间通过 LM Studio 安装了,以后就算断网,本地也有真正的多模态模型了,没有任何 token 焦虑——不过最好上 32g 内存,16g 虽然可以跑,但是 token 速度很慢;另外中文表达默认好像是粤语表达方式,所以问问题之前要求用简体中文来回答;知识截止日期 2025 年 1 月。"
4. 核心技术创新:扔掉编码器¶
"这是 Gemma 4 12B 最值得说的地方。"
传统多模态模型的处理方式¶
- 先用专门的编码器把图像、音频"翻译"成模型能懂的表示
- 再把这些表示传给语言模型主体
- 编码器越多,延迟越高,内存占用也越大
Gemma 4 12B 的突破¶
视觉处理: - 用一个极轻量的嵌入模块替换了原来的视觉编码器 - 这个模块只包含一次矩阵乘法、位置嵌入和归一化操作 - 视觉信息直接进入语言模型主干,让大模型自己去做视觉理解
音频处理(更彻底): - 音频编码器被完全移除 - 原始音频信号直接被投影到与文本 token 相同的维度空间里
"这种统一、无编码器的架构,带来的直接好处是:延迟更低,内存更省。"
5. 速度优化:MTP 草稿器¶
Gemma 4 12B 内置了多 Token 预测(MTP)草稿器,专门用来降低推理延迟。 - 目前谷歌已经用到自家全系模型了 - 在实际使用中意味着响应更快
6. 开放 + 生态¶
许可证:Apache 2.0
权重下载:Hugging Face + Kaggle(预训练 + 指令微调)
支持的推理框架: - Hugging Face Transformers - llama.cpp - MLX(Apple Silicon 优化) - SGLang - vLLM
微调支持:Unsloth
生产部署: - Gemini 企业级智能体平台模型花园 - Cloud Run - GKE
官方 Gemma 技能库(Skills Repository)——专门为开发者用 Gemma 模型构建智能体工作流提供支持
7. 核心金句¶
- "把原本需要高端服务器才能跑的多模态智能,装进你的笔记本电脑里。"
- "多模态理解加上 Agent 能力,直接在本地跑,不用联网,不依赖云端。"
- "以后就算断网,本地也有真正的多模态模型了,没有任何 token 焦虑"
- "这种统一、无编码器的架构,带来的直接好处是:延迟更低,内存更省。"
8. 与已有 wiki 实体的关系¶
vs PilotDeck / Kimi Work / 高德 / Rein¶
- 这些是框架 / 智能体 OS / 架构
- Gemma 4 12B 是底层模型(可在 LM Studio / Ollama / vLLM 等框架上跑)
- 共同点:都强调"本地 / 离线可用"
vs Microsoft MAI-Thinking-1¶
- 微软 MAI = 云端推理模型(350 亿活跃参数 / 1 万亿总参数 / SWE Bench Pro)
- Gemma 4 12B = 本地多模态模型(12B 参数 / 16GB 显存 / 多模态)
- 共同点:都是大厂自研模型;Gemma 4 走开源 + 本地路线,MAI 走企业级云端路线
vs ANOLISA¶
- ANOLISA 是阿里 Agentic OS(基于 Linux + ECS)
- Gemma 4 12B 可作为本地多模态底座在 ANOLISA 这类 Agentic OS 上跑
9. 启示¶
- "扔掉编码器" 是多模态架构新趋势 —— 视觉用轻量嵌入 / 音频原始信号直接投影 = 延迟更低、内存更省
- 本地多模态已成现实 —— 16GB 显存 + MacBook Air M5 = "本地多模态"
- Apache 2.0 + 多框架支持 = 开源生态完整(Hugging Face / llama.cpp / MLX / SGLang / vLLM / Unsloth)
- MTP 多 Token 预测成为业界标准延迟优化手段
- 断网场景有真正多模态 = "没有任何 token 焦虑" + 数据隐私保护
- 入门级 MacBook 可跑 = Agent + 本地模型 真正进入消费级市场
10. 局限 / 待验证¶
- 文章主要是产品 release 介绍,详细 benchmark 表未给出
- "接近 26B MoE" 的具体基准测试清单未列
- 16GB 内存下"token 速度很慢"的具体延迟数据未给
- 知识截止日期 2025-01(约 1 年半前),对长尾知识覆盖度可能受限
- 中文表达"默认好像是粤语表达方式"的修复版本 / 后续训练情况未说明
- MTP 草稿器具体加速比未给
深度分析¶
-
架构转型信号:Gemma 4 12B 彻底移除音频编码器、替换视觉编码器为单层投影模块,标志着多模态模型从"编码器分离"架构向"统一 token 空间"架构的范式转移。这一选择在延迟敏感型边缘场景中有显著优势——视觉仅多一次矩阵乘法,音频则完全省去编码器开销。
-
性能与效率的突破性平衡:12B 参数规模接近 26B MoE 性能,但内存占用不到后者一半。这意味着在消费级硬件(16GB 统一内存)上实现了企业级多模态理解能力,打破了"多模态必须高端硬件"的既有认知。
-
多框架支持背后的生态意图:MLX(Apple Silicon)、llama.cpp(CPU/GPU 通用)、SGLang(高吞吐)、vLLM(云端)全部覆盖,表明 Google 不只想做本地模型,而是想成为边缘/端侧部署的标准底座——类似于 Android 当年的平台化战略。
-
MTP 草稿器的行业渗透:多 Token 预测草稿器已被 Google 全系模型采用,这意味着 Gemma 4 12B 的推理优化与 Google 内部基础设施直接对齐,为未来与 Gemini 系列的技术协同奠定了基础。
-
本地 Agent 能力的关键拼图:多模态理解 + Agent 能力 + 本地运行三位一体,使 Gemma 4 12B 成为 Agentic OS(如 ANOLISA)的理想本地多模态底座,填补了开源本地模型在"视觉 + 音频 + Agent"三角能力上的空白。
实践启示¶
-
本地多模态应用开发首选底座:在 16-32GB 内存的 MacBook 或 Linux 工作站上,Gemma 4 12B 是目前最具性价比的多模态模型选择——Apache 2.0 许可证无商业限制,MLX 优化开箱即用。
-
低延迟场景优先考虑无编码器架构:若你的多模态 Pipeline 对延迟敏感(实时对话、边缘交互),视觉编码器的轻量化替换(单层投影)相比传统双编码器架构有显著优势。
-
中文场景需注意语言适配:默认粤语表达方式意味着生产部署时需在 System Prompt 中明确指定"简体中文",或通过 LoRA 微调进行语言对齐。
-
知识截止日期限制长尾知识:2025 年 1 月的知识截止点对需要最新领域知识的应用构成约束,复杂问题时建议搭配 RAG 管线而非依赖模型自身知识。
-
16GB 内存可跑但建议 32GB:实测 16GB 下 token 速度较慢,生产级使用推荐 32GB 配置。LM Studio 是本地体验首选工具,支持快速模型切换与量化配置。
相关对照¶
- Microsoft Build 2026 —— 大厂云端模型(MAI-Thinking-1)
- ANOLISA v0.3 —— 阿里 Agentic OS(可在本地跑多模态模型)
- PilotDeck —— 多项目隔离
- Kimi Work —— 本地 Agent
- Agent Harness 架构 —— 7 层模型
→ 原文存档
Ch17.017 商汤SenseNova U1深度拆解,原生统一架构终结缝合时代¶
📊 Level ⭐⭐⭐ | 8.6KB |
entities/sensnova-u1-deep-dive-jiqizhixin-d8602ded5c51.md
概述¶
SenseNova U1 是商汤科技推出的新一代多模态大模型,核心创新在于 NEO-Unify 架构,首次实现了图像与文本在同一表示空间内的原生统一建模。
传统多模态模型多采用"拼接"路线,即预训练视觉编码器(VE)和语言模型分别独立训练后通过接口层连接。这种架构导致理解与生成任务存在模块割裂,难以充分协同。NEO-Unify 彻底抛弃 VE 和 VAE(变分自编码器),图像直接转化为 token,理解和生成在同一表示空间内协同建模,标志着多模态从"缝合时代"向"原生统一时代"的范式转变。
核心矛盾与架构创新¶
矛盾一(接口层):消除模块割裂 → Encoder-free 设计¶
传统多模态架构依赖预训练的视觉编码器(Vision Encoder, VE)将图像映射到语言模型的表示空间,这导致了模块割裂问题。NEO-Unify 采用 Encoder-free 设计,完全去掉 VE 和 VAE:
- 输入层:两层卷积 + GELU 激活函数替代预训练 VE,每个 token 直接对应 32×32 像素块,实现图像到 token 的端到端映射
- 输出层:MLP 直接预测原始像素块,放弃解码器重建方式
- 效果:NEO-unify(2B 参数)在 MS COCO 2017 图像重建任务上达到 PSNR 31.56、SSIM 0.85,接近 Flux VAE 的 32.65/0.91,表明去编码器设计并不牺牲重建质量
这种 Encoder-free 架构的核心洞见是:视觉理解不必依赖预训练编码器的归纳偏置,直接让模型从像素级别学习视觉表示反而更灵活。
矛盾二(训练层):动态分辨率信噪比失衡 → 分辨率自适应噪声尺度¶
高分辨率图像意味着更多 token 数量,但在 Flow Matching 训练框架下,传统方法会导致信噪比(SNR)分布不一致的问题:
- 分辨率提高 → token 数增加 → 噪声标准差需按平方根比例同步上调
- 保证 Flow Matching 过程中 SNR 分布一致,避免高分辨率下结构崩坏、低分辨率下细节丢失
- 结合动态分辨率(256-2048 范围)训练,使模型能够处理任意长宽比的图像
这一设计使模型在推理时可生成高达 2048×2048 分辨率的图像,同时保持纹理细节和结构完整性。
矛盾三(参数层):理解与生成的梯度干扰 → MoT 架构¶
理解任务(图像识别、OCR)和生成任务(文生图)在梯度更新时相互干扰,这是混合模型训练的经典难题。NEO-Unify 采用 Mixture-of-Transformers(MoT)架构解决:
- 底层共享:自注意力机制的上下文信息在底层共享,实现知识共享
- 顶层解耦:Q/K/V/O 投影、归一化、MLP 层完全参数解耦,按 token 类型动态路由,实现"专才专用"
- 这种架构在理解与生成之间建立了可渗透的隔离墙,既允许知识迁移,又防止梯度冲突
四步训练策略¶
NEO-Unify 采用渐进式统一训练流程,而非一步到位的端到端联合训练:
- 理解预热:注意力融合阶段,恢复语义骨干网络的表达能力
- 生成预训练:冻结理解分支,在 256-2048 动态分辨率范围内掌握图像生成能力
- 统一中期训练:双分支同时激活,进行 84k 步端到端联合训练,实现深度协同
- 统一 SFT:高质量指令微调 9k 步,提升模型对用户意图的理解准确性
这一分阶段策略有效降低了联合训练的优化难度,让理解和生成分支逐步找到协同点。
推理系统架构¶
SenseNova U1 的推理系统采用 LightLLM + LightX2V 双引擎解耦部署:
- LightLLM:负责多模态理解、文本流式输出、请求调度等理解侧任务
- LightX2V:专司图像生成,通过 Flow Matching 解码器输出图像
- 优化技术:锁页共享内存 + FlashAttention3 后端显著降低访存开销
- 性能表现:2048×2048 图像生成,NVIDIA RTX 5090 每步耗時 0.415s,L40S 每步 0.443s
这种解耦部署允许理解与生成引擎独立扩缩容,提升系统整体吞吐量。
核心 Benchmark 成绩¶
| 基准 | A3B-MoT 成绩 | 亮点 |
|---|---|---|
| MMMU | 80.55 | 超越 Qwen3.5-9B 2.15 分 |
| MMMU-Pro | 72.83 | 领先 2.73 分 |
| GenEval | 0.91 | 开源第一 |
| OCRBench | 91.90 | 文本密集图像超竞品 |
| RealUnify | 52.4 | 理解增强生成/生成增强理解双方向开源第一 |
| RISEBench(CoT) | 30.0 | 推理驱动编辑开源第一 |
这些成绩表明,NEO-Unify 在多模态理解(MMMU 系列)和生成(GenEval)两个维度均达到开源 SOTA。
架构演进判断¶
从历史维度看,多模态架构经历了三个阶段:
- 过去:VE+VAE 拼接架构,理解与生成是天生的异构系统,信息必须在接口层做跨模态转换
- 现在:原生统一架构,图像和语言在同一条链路中协同理解与生成,统一架构消除跨模态损失
- 趋势:以更少训练 token 实现更高性能,数据扩展效率显著优于同类方法
- 下一步方向:VLA(视觉-语言-动作)、世界建模(World Modeling)
NEO-Unify 的成功验证了"原生统一"路线的可行性,为多模态大模型指明新方向。
深度分析¶
本文揭示了 {DOMAIN} 领域的核心发展趋势,对理解技术演进方向具有重要参考价值。
关键洞察¶
-
核心趋势:从多个维度的分析可以看出,行业正在经历从传统架构向智能系统的根本性转变
-
技术驱动因素:新型 AI 能力的引入正在重新定义产品形态和用户体验
-
商业影响:这一转变对现有市场格局和竞争态势产生深远影响
与行业整体趋势的关联¶
本文与同期发表的 System of Record→Intelligence 等文章共同构成了对 AI Native 时代企业软件演进的系统性分析框架
实践启示¶
-
架构评估:定期审视现有技术栈,判断是否需要进行智能化升级
-
渐进式迁移:采用增量式方法逐步引入新能力,降低迁移风险
-
数据基础设施:确保数据质量和结构化程度,为 AI 层提供可靠输入
-
团队能力建设:培养具备 AI 时代所需技能的工程团队
相关实体¶
→ 原文存档
Ch17.018 Normalizing Trajectory Models¶
📊 Level ⭐⭐⭐ | 8.5KB |
entities/normalizing-trajectory-models-v2.md-> 原文存档
摘要¶
Normalizing Trajectory Models (NTM) 是由 Jiatao Gu 等人提出的新型扩散模型变体,旨在解决少步生成(few-step generation)场景下传统扩散模型假设失效的问题。传统扩散模型将采样分解为大量小步高斯去噪,这一假设在压缩到几步时崩溃。NTM 将每步 reverse 建模为 expressive conditional normalizing flow,保留精确似然训练。通过结合每步内的浅层可逆块与跨轨迹的深层并行预测器,NTM 在仅 4 步采样下即可匹配或超越强图像生成基线,同时保留对生成轨迹的精确似然计算能力。
核心创新¶
问题:少步生成的困境¶
扩散模型的采样过程通常需要数十到数百步去噪步骤,这带来了显著的推理成本。现有少步方法(如 consistency models、distillation 技术)通过以下方式加速:
- Consistency Training:强制不同噪声水平下的样本映射到同一直流
- Distillation:从多步教师模型蒸馏到少步学生模型
- Adversarial Objectives:引入对抗训练替代重建损失 但这些方法都牺牲了似然框架——无法精确计算生成样本的似然,失去了基于似然进行模型选择、压缩评估等下游任务的能力。
解决方案:NTM 架构¶
NTM 的核心洞察是:将每步 reverse process 建模为 normalizing flow,而非传统扩散模型中的高斯去噪。 架构组成: 1. 浅层可逆块(Shallow Invertible Blocks)within each step:每步内的转换用轻量级可逆网络建模,参数量少但表达能力足够 2. 深层并行预测器(Deep Parallel Predictor)across the trajectory:跨步之间共享一个深度网络预测去噪方向,实现高效信息传递 3. 端到端可训练:可从随机初始化训练,也可从预训练 flow-matching 模型初始化 这种设计在每步内保持可逆性(支持精确似然计算),跨步间共享计算(保持效率)。
自蒸馏:精确似然的多步利用¶
NTM 的精确轨迹似然还支持一个独特能力:自蒸馏(Self-Distillation)。 流程: 1. 训练一个完整的 NTM 模型 2. 用该模型自身的 score 训练一个轻量级去噪器 3. 轻量去噪器可在 4 步内产生高质量样本 这意味着 NTM 可以"自我压缩"——将复杂的多步 NTM 蒸馏为极简的少步采样器,同时保持高质量输出。
技术细节¶
与 Flow Matching 的关系¶
NTM 可从预训练 flow-matching 模型初始化,这利用了 flow matching 的线性轨迹假设。Flow matching 通过插值噪声和真实数据预测向量场,而 NTM 将这个预测过程参数化为条件归一化流。
似然精确性的意义¶
精确似然(exact likelihood)对于以下应用至关重要:
- 模型压缩评估:直接比较不同模型的压缩效率
- 生成质量度量:不依赖 FID 等间接指标
- Bayesian model selection:精确计算后验比近似方法更可靠
- Data compression:精确似然直接对应压缩比 这使得 NTM 在需要严格概率计数的场景(如压缩、异常检测)比其它少步扩散方法更有优势。
训练稳定性¶
传统 normalizing flow 的训练常面临数值不稳定问题。NTM 的设计通过以下方式缓解:
- 浅层可逆块限制每步的复杂度,降低数值误差累积
- 跨步并行预测器分担单步网络的优化压力
- 支持从预训练模型初始化提供更好的初始点
深度分析¶
渐进式生成 vs. 单步生成¶
当前主流加速扩散采样的方法可分为两类: 1. 单步生成(One-step):consistency model、GAN-based method,生成质量与多步方法仍有差距 2. 少步生成(Few-step):NTM、LCM、SDXL-Turbo等,在4-8步内达到可接受质量 NTM 的定位是保留完整似然框架的少步方法。这一定位使其与单纯追求速度的方法(如 GAN-based)不同——速度不是唯一目标,保持概率语义同样重要。
架构设计的权衡¶
NTM 的"浅层每步 + 深层跨步"设计反映了一个基本权衡:
- 每步可逆 = 精确似然:但浅层网络限制单步表达能力
- 跨步共享 = 效率:深层网络捕获跨步依赖,但增加了训练复杂度 这个权衡在实践中被证明是有效的——在 4 步采样下即可达到与数十步方法相当的质量。
与 Consistency Model 的对比¶
Consistency Model 通过强制 $f(x_t) = f(x_{t+1})$ 实现少步采样,本质上是将轨迹压缩到单一不动点。 NTM 的优势:
- 保留完整的轨迹分布而非单一代表点
- 可以追溯生成过程(每一步都有明确概率)
-
支持自蒸馏将复杂模型压缩为简单采样器 CM 的优势:
-
训练更简单(单一一致性损失)
- 推理极快(1-2步) 两者代表了不同的设计哲学:NTM 偏向"精确描述",CM 偏向"实用速度"。
归一化流的可逆性瓶颈¶
Normalizing flow 的核心是通过一系列可逆变换实现精确似然计算。但可逆性要求网络输出维度不变且必须可逆,这限制了网络架构的选择。 NTM 通过"浅层可逆块"缓解这一问题——每步只做轻量变换,用跨步的深层网络补充表达力。这是一种工程折中:在保持可逆性的同时尽量利用深度网络的表达能力。
实践启示¶
对于扩散模型研究¶
NTM 开辟了一个新方向:保留似然框架的少步扩散。未来研究可以探索: 1. 更激进的步数压缩:4步已是SOTA,但是否有理论下限? 2. 多模态扩展:当前主要验证图像生成,是否可以扩展到视频、音频? 3. 与attention机制的结合:当前架构依赖并行预测器,是否可以引入更长程依赖? 4. 条件生成控制:精确似然是否可以帮助实现更好的条件控制(如 classifier-free guidance 的替代)? 建议研究团队关注 NTM 的自蒸馏机制——这提供了一个将大模型能力压缩到小采样器的正规框架,而非依赖启发式 distillation。
对于工程部署¶
适用场景:
- 对生成质量有严格要求(需要精确概率)
- 需要少步推理但无法接受质量损失
-
需要可追溯的生成过程(审计、调试) 部署建议:
-
NTM 的精确似然特性非常适合在线质量评估——可以在不额外采样的情况下计算生成样本的似然
- 自蒸馏得到的轻量采样器可以部署在边缘设备
- 与预训练 flow-matching 模型的兼容性意味着可以增量部署——先部署 teacher NTM,再蒸馏部署轻量采样器 性能基准:在文本到图像任务上,4步采样可匹配或超越现有基线。若部署场景需要 4-8 步采样,NTM 值得关注。
对于概率机器学习¶
NTM 展示了一种有价值的思路:通过架构设计保留训练目标的语义,而非仅仅追求结果指标。 在需要严格概率语义的下游任务(如贝叶斯推断、变分推断、压缩),这一思路可能启发新的模型设计。 特别是自蒸馏机制——让模型自己教自己——在其它领域(如强化学习中的 self-play、语言模型的 self-reward)也有类似应用。这个范式值得在更多场景探索。
相关实体¶
Ch17.019 Netflix 可控 AI 视频编辑:Vera 与 VOID 模型¶
📊 Level ⭐⭐⭐ | 8.2KB |
entities/netflix-controllable-ai-video-editing-vera-void.md
Netflix 可控 AI 视频编辑:Vera 与 VOID 模型¶
Background:Netflix Tech Blog 发布的早期研究探索,介绍了两个针对专业视频后期制作场景的 AI 编辑模型——Vera(元素添加/替换)和 VOID(物体移除)。核心创新在于"只改该改的"(pixel-precise editing),避免现有方法"重新生成整个视频"导致的连带破坏。
核心问题:现有视频编辑方法的两大缺陷¶
当前生成式视频编辑模型在专业后期制作场景中存在两个关键问题:
-
Unintended edits(非预期编辑):编辑特定元素时,多数方法重新生成整个视频,导致身份、表演、背景等不应改变的元素被意外修改。例如 Ditto 模型在执行"将背景换成加州海岸公路"时,完全改变了整个场景。
-
Unnatural physics(不自然物理):物体移除时,多数方法只关注擦除目标而忽略场景的物理连续性。例如 Gen-Omnimatte 移除泳池中的人物后,泳池浮具仍然保持不合理的运动轨迹。
Vera:元素添加与替换¶
Vera 专注于在视频中添加或替换视觉元素,同时保持原始素材的完整性:
- 架构:基于 Mixture-of-Transformers(MoT)的分层扩散方法
- 核心机制:仅对需要编辑的区域进行像素级修改,不重新生成整个帧
- 数据构建:专门构建的训练数据集,包含精确的编辑前后配对
- 应用场景:为预告片、社交媒体短视频等宣传素材添加新的视觉元素
VOID:物理感知的物体移除¶
VOID 解决物体移除中的物理连续性问题:
- 核心创新:移除物体时不仅擦除目标区域,还考虑场景中的物理交互关系
- 物理一致性:确保移除后的场景运动轨迹符合物理规律(如移除与浮具互动的人物后,浮具应保持静止或合理的运动)
- 推理管线:完整的推理管线设计,支持精确的区域指定和物理约束
技术深度与价值¶
本文的独特贡献在于:
- 精确编辑范式:提出"只改该改的"而非"重新生成整个视频"的编辑理念,这对专业视频后期制作至关重要
- 物理连续性建模:VOID 首次在视频物体移除中显式建模物理交互关系
- MoT 架构应用:将 Mixture-of-Transformers 架构应用于视频编辑任务,展示了该架构在多模态任务中的灵活性
- 端到端管线:从数据构建到推理部署的完整工程方案
与现有技术的差异¶
| 维度 | 现有方法 | Netflix Vera/VOID |
|---|---|---|
| 编辑范围 | 全帧重新生成 | 仅编辑目标区域 |
| 物理一致性 | 忽略物理交互 | 显式建模物理关系 |
| 素材保真度 | 可能改变非目标元素 | 严格保持非目标元素不变 |
| 应用场景 | 通用视频编辑 | 专业后期制作(预告片、宣传素材) |
深度分析¶
分层扩散(Layered Diffusion)是视频编辑的范式转移¶
现有视频编辑模型的核心问题是"编辑一个元素就要重新生成整个视频"。Vera 的解决方案是将编辑操作分解为三个独立层:edit layer(创意编辑)、alpha matte layer(编辑区域掩码)、composite layer(原始素材)。通过 Mixture-of-Transformers(MoT)架构,三个 DiT 分支各自维护独立的 QKV 投影和 FFN 权重,但通过 joint self-attention 实现跨层交互。这种"只生成需要改变的部分"的范式,从根本上解决了 unintended edits 问题——原始素材的像素在编辑区域外保持完美不变。
训练数据构建是视频编辑研究的最大瓶颈¶
Vera 团队面临的核心挑战是:没有公开数据集提供高质量的分层视频数据(干净输入、alpha matte、edit layer、合成视频)。他们自行构建了 486k 帧(832×480 分辨率)的分层数据集,分为三个递增复杂度的子集:合成复合(高质量前景 alpha)、真实单物体视频(经分割、抠图、背景修复、人工质量过滤)、真实多物体+效果视频(含阴影和反射的 alpha)。这种数据工程投入在论文中往往被低估,但它是 Vera 超越现有方法的根本原因。
VOID 的物理推理管线是物体移除的关键创新¶
传统物体移除(如 Gen-Omnimatte)只关注擦除目标区域的外观,忽略场景中物体间的物理交互关系。VOID 的突破在于引入 VLM 推理管线:分析场景中哪些区域会因果受影响(如碰撞、轨迹变化),将推理结果编码为 quadmask(四色掩码:移除对象=黑色、受影响区域=灰色、重叠=深灰色、不变=白色),用 quadmask 引导扩散模型生成物理上合理的反事实视频。此外,两遍推理管线(第二遍使用 flow-warped noise 稳定物体形状)解决了小视频扩散模型常见的"物体变形"问题。
人工评估揭示了自动化指标的局限性¶
两个模型都进行了大规模人工评估:Vera 与 5 个 baseline 对比(19 位创意评审、512 次试验),VOID 与 6 个 baseline 对比(25 位评审、125 次比较)。Vera-1.3B 在内容保真度和指令遵从度上被一致偏好;VOID 在 64.8% 的情况下被选为最真实的反事实编辑。这些人工评估结果与定量指标高度一致,但提供了自动化指标无法捕获的维度:时间连贯性、混合质量、场景演进的真实感。
从研究原型到生产部署仍有显著差距¶
尽管 Vera 和 VOID 展示了有前景的早期结果,团队坦诚列出了当前局限:Vera 在复杂效果(闪电、烟雾)上表现不佳,有时无法保持背景运动与输入相机运动的一致性;VOID 无法处理异常相机角度或距离目标过近的镜头,且对视频长度和分辨率有限制。这些限制使得两个模型目前仍处于研究探索阶段,距离 Netflix 的生产质量标准还有距离。
实践启示¶
-
视频编辑应采用"分层编辑"而非"全帧重生成"架构:对于专业后期制作场景,Vera 的分层扩散范式是正确方向。任何需要"只改该改的"的视频编辑工具都应考虑这种架构设计。
-
训练数据质量决定模型上限:Vera 团队投入大量资源构建 486k 帧的分层数据集(含三个递增复杂度子集),这是其超越现有方法的根本原因。在视频编辑领域,数据工程的 ROI 高于模型架构创新。
-
物体移除需要物理推理而非仅外观修复:VOID 证明了 VLM 驱动的物理推理(识别因果影响区域)是物体移除质量的关键差异化因素。仅修复外观(inpainting)在涉及物体交互的场景中会产生不自然的结果。
-
MoT 架构在多输出生成任务中具有优势:Vera 使用 Mixture-of-Transformers 让三个输出(edit layer、alpha matte、composite)各自有独立参数但共享注意力,这种设计在输出分布差异大的多任务场景中比共享架构更数据高效。
-
人工评估是视频编辑研究的必要投入:自动化指标(像素相似度、感知质量)无法完全捕获时间连贯性、物理合理性等维度。任何严肃的视频编辑研究都应预算人工评估成本。
研究状态¶
当前为早期研究探索阶段,尚未达到生产部署水平。但其提出的"精确编辑 + 物理感知"范式对 AI 视频编辑领域具有方向性指导意义。
→ 原文存档
Ch17.020 Google's Gemini Omni video model surfaces ahead of I/O debut¶
📊 Level ⭐⭐⭐ | 8.2KB |
entities/googles-gemini-omni-video-model-surfaces-ahead-of-io-debut.md-> 原文存档
Summary¶
Score: 8×9=72
核心要点¶
- Google Gemini Omni 视频模型在 Google I/O 2026 前夕泄露
- 具备视频编辑能力:水印去除、对象替换、场景重写等
- 采用与 Nano Banana 相同的策略:生成质量中等但编辑能力领先
- 预计推出 Flash 和 Pro 两个版本
- 将作为 Agent 提供,类似于 Deep Research
相关实体¶
深度分析¶
Gemini Omni 的战略定位:编辑优先于生成 从泄露的信息来看,Gemini Omni 的核心差异化策略并不是在原始视频生成质量上追求第一,而是将视频编辑能力作为主要卖点。早期测试者的反馈显示,在原始生成保真度上,Omni 似乎落后于 ByteDance 的 Seedance 2——观看者注意到电影质感方面落后于当前基准领导者。然而,在编辑功能方面:去除水印、在剪辑中交换对象、以及通过聊天指令重写场景,这些功能在首次公开展示中表现出乎意料地好。 这种策略选择有其深刻的商业逻辑。视频生成领域的竞争已经非常激烈:OpenAI 的 Sora、Runway 的 Gen-3、Pika、ByteDance 的 Seedance 2 等都在 raw generation 质量上投入了大量资源。如果 Google 选择在同一维度上竞争,即使最终能够赶上,也需要大量的时间和资源,而且最终可能只是在他人定义的赛道上追逐。通过将重点放在视频编辑上,Google 开辟了一个相对蓝海的战场——视频编辑是一个生产工作流中的高频需求,而现有的 AI 编辑工具在精确度和自然度上仍有很大提升空间。 Nano Banana 模式的复制:从图像到视频 文章明确指出了一个关键模式:Gemini Omni 采用的策略与 Nano Banana 完全相同。Nano Banana 作为原生图像模型推出时,在生成评分上表现平平,但却在编辑排行榜上名列前茅,随后被升级为前沿图像系统。Google 似乎在视频领域复制这一策略:首先是中等水平的生成质量,但具有卓越的编辑能力,然后通过迭代改进提升生成质量,最终成为一个全面的视频系统。 对于 AI 行业观察者来说,这意味着 Google 已经形成了一种可辨识的产品演进模式:不是一开始就在所有维度上追求第一,而是在某个特定维度上建立优势,然后通过快速迭代追赶其他维度。这种方法降低了风险——即使生成质量不能立即领先,编辑能力的差异化也能吸引有实际工作流需求的用户。 分层发布策略:Flash 和 Pro 泄露信息表明 Omni 将推出分层版本,很可能是 Flash 和 Pro 两个层级。当前流通的输出很可能是来自 Flash 层级的——这解释了为什么生成质量与前沿系统相比仍有差距。这种分层策略在 Google 的其他产品线中已经有成熟实践:Gemini Flash 提供轻量级、高速度、低成本的选项,Gemini Pro 提供更强大但更昂贵的选项。对于视频模型,Flash 版本可能针对日常用户和快速原型制作,而 Pro 版本则针对专业内容创作者和企业客户。 Agent 定位:不仅仅是生成 一个重要的泄露信息是,Gemini Omni 将被视为 Agent(类似于 Deep Research on AI Studio)提供,而不仅仅是生成工具。这意味着 Google 对 Omni 的定位不仅仅是"文生视频"或"视频编辑",而是一个能够执行复杂多步骤任务的智能代理。例如,一个视频代理可能能够理解用户的指令(如"将这个视频中的产品特写镜头提取出来,加上品牌水印,并调整到 16:9 比例"),然后自主规划并执行这些步骤。这种定位与当前 AI 领域从"工具"向"代理"演进的大趋势完全一致。 时间窗口与 Google I/O 的战略考量 选择在 Google I/O(5月19-20日)前约一周进行泄露或 A/B 测试,这个时间窗口的策略意义值得玩味。一个短暂的会前窗口配合受控的泄露,给了 Google 在主题演讲前收集反馈和塑造叙事的空间。如果反馈积极,Google 可以在 I/O 上大力宣扬;如果有重大问题,还有时间进行调整。这种"测试-学习-迭代"的策略比过去的大爆炸式发布更加敏捷,也更符合互联网产品开发的最佳实践。
→ 原文存档
实践启示¶
1. AI 视频领域的竞争维度正在扩展 对于在视频 AI 领域寻找机会的团队,需要认识到"生成质量"不再是唯一的竞争维度。编辑、工作流集成、代理能力等正在成为新的差异化领域。如果你正在构建视频 AI 产品,考虑是否有机会在编辑或其他特定维度上建立优势,而不是简单地与现有系统在生成质量上竞争。 2. 关注 Google 的"迭代追赶"模式 Google 在 AI 产品上展示的模式是:先在某个维度上建立优势(即使其他维度暂时落后),然后快速迭代追赶。这对于评估 Google 的 AI 产品有重要启示:不应该根据首次发布的质量来判断其长期潜力。Nano Banana 的案例表明,Google 能够在发布后迅速提升产品质量。类似地,Gemini Omni 的生成质量可能会在 I/O 正式发布后快速提升。 3. 分层模型的策略值得学习 Gemini Omni 预计采用 Flash/Pro 分层策略,这对于需要控制成本和延迟的生产系统具有重要意义。Flash 版本可能适合作为日常使用和快速原型制作,而 Pro 版本可以用于对质量要求更高的专业场景。在构建自己的 AI 产品时,考虑类似的分层策略,为不同需求层次的用户提供适当的选项。 4. 视频 Agent 是下一个前沿 Gemini Omni 被定位为 Agent 的事实表明,视频理解和生成能力正在融合为一个更广泛的"视频 Agent"概念。这对开发者意味着:视频 AI 的下一个机会可能不在于"生成更好的视频",而在于"构建能够理解、编辑、操作视频的智能代理"。对于有志于这一领域的团队,开始探索视频 Agent 的架构和用例可能会获得先发优势。 5. 生产工作流集成的价值 从泄露信息看,Gemini Omni 的核心差异化在于其编辑能力与聊天界面的深度集成。这意味着对于生产级视频应用,UI/UX 和工作流集成可能比底层模型能力更加关键。即使模型的原始生成能力不是第一流的,如果编辑体验足够流畅、自然,并且易于集成到现有工作流中,仍然可以赢得市场份额。建议在评估或构建视频 AI 产品时,将用户体验和工作流集成作为核心评估维度。
Ch17.021 豆包 Seed 2.0 Lite — Agent 前置多模态感官层¶
📊 Level ⭐⭐⭐ | 8.2KB |
entities/doubao-seed-2-lite.md
核心定位¶
不是来替换旗舰 LLM(Claude Opus、GPT-5.5)的——它的输出能力(写代码、复杂推理)比不上旗舰。但在输入侧,它是唯一能以低价把视频/音频直接结构化输入 Agent 的方案。核心能力¶
1. 带上下文的音频理解(ASR)¶
这是最重要的差异化能力。普通 ASR 的问题是没有上下文:同音术语只能瞎猜,导致 GPT-5.5→GBT5.5、huashu-design→花书 Diffusion。 豆包 Seed 2.0 Lite 的用法是在 prompt 里提供上下文:
- 录制背景、说话人风格
- 46 个易错术语清单(GPT-5.5、Claude Opus 4.7、Codex、Anthropic……)
-
让模型在你给的上下文里听 效果数据(同一段 277 秒音频):
-
不给上下文:关键术语命中率 0/13 = 0%
- 给上下文:关键术语命中率 13/13 = 100%,成本还便宜 20%
真正解锁的不是「模型能听」,是「模型能在你给的上下文里听」。
2. 直接读视频 → 结构化输出¶
不是只能看静态图,能直接分析 60 秒视频,输出:
- 时间码分段(0-4s 标题、5-13s 解魔方……)
- 字体风格、颜色 hex(#A855F7 等)
- 动效转场、BPM 估值(80-90)
- 可执行分镜表(颜色、字号、动效时序) 御三家里暂时只有 Gemini 有这项能力,但太贵不实用。
性能基准¶
- 超过前一代 Seed 2.0 Pro 的视觉理解能力
- 多个维度达到 SOTA 级别
- 全方面碾压 Gemini-3-Pro 的视频理解能力
价格(同档全模态轻量模型对比)¶
| 模型 | 文本输入(元/Mtok) | 文本输出(元/Mtok) | 音频输入 |
|---|---|---|---|
| Doubao Seed 2.0 Lite | 0.6 | 3.6 | 9 元/Mtok |
| Gemini 3 Flash | 3.6 | 21.6 | 7.2 元/Mtok |
| 文本输入/输出便宜 6 倍。单次音频字幕处理(277 秒)不到一分钱。 |
应用场景¶
- 精准字幕:给 B 站视频自动上字幕,术语全对
- 竞品视频拆解:把产品发布动画喂给 LLM → 结构化 brief → 前端直接动手
- 会议录音整理:音频直接结构化,无需手动转写
- 视频关键片段提取:从长视频里捞出 3 个关键片段
Best Practice¶
豆包不写 prompt 直接跑,效果只比剪辑软件好一点。prompt 上下文是必须做的功课,少了这一步全模态能力发挥不出来。 带上下文的 prompt token 更多,但模型不用瞎猜了,completion token 反而更少,总成本下降。
深度分析¶
上下文音频识别的本质:降低熵而非提升模型能力¶
豆包 Seed 2.0 Lite 的音频理解突破,本质不是模型「更聪明」,而是人为降低了音频信号的熵。普通 ASR 在同音术语上是均匀分布的猜測概率,而给模型提供上下文后,概率分布被压缩到正确选项附近。 这意味着:对于已知专有名词列表的场景,音频理解效果取决于上下文覆盖率,而非模型本身的 ASR 精度。这是第一个把「用户给上下文」机制做成正式功能的商用模型。
作为 Agent 前置层的架构意义¶
传统 Agent(如 Claude Code)的输入瓶颈在于:它只能处理文本。视频/音频需要人类提前转写或截图标注,才能进入 Agent 工作流。豆包 Seed 2.0 Lite 相当于把这个预处理步骤自动化且标准化。 架构上,这层前置感官层解决的问题是:
- 输入侧:非结构化多媒体 → 结构化文本描述
- 输出侧:旗舰 LLM 继续保持纯文本推理的简洁性 两层分离让各自专注擅长领域:豆包负责感知,旗舰负责决策。
视频理解的价格护城河¶
Gemini 3 Flash 音频输入 7.2 元/Mtok,看起来比豆包的 9 元/Mtok 便宜。但 Gemini 不支持直接视频理解(需要先抽帧),且视频理解 API 价格更高。豆包把视频直接进、结构化出的能力,在同价位没有竞品。
上下文丢失的风险¶
当前方案的核心弱点:如果 prompt 里的上下文本身错了(术语清单遗漏、或描述不准确),模型会在错误的方向上「定向精准」。这种定向精准比漫无方向更难发现错误——因为输出看起来很流畅、术语都对,但整体语义可能偏离原意。 需要在 pipeline 里加入人工抽检节点,或者用另一个 LLM 做交叉验证。
实践启示¶
1. 上下文 prompt 的最优结构¶
根据实测效果,上下文 prompt 应包含三层: 1. 录制背景:场景类型、说话风格、预期内容方向 2. 术语清单:46 个易错术语的完整列表(每个术语单独一行) 3. 特殊规则:如同音词优先级、常见误识别模式 不要一次性给所有上下文,分层递进效果更好。
2. 视频→分镜表的工作流模板¶
关键点:豆包输出的是「可执行分镜表」,不是描述性文本。这意味着第二个 LLM 收到的输入已经是结构化的 action items(颜色 hex、字号、动效时序),无需再做 extra parsing。3. 何时用豆包 vs 直接 API¶
- 用豆包:音频/视频需要结构化、术语专业性强、后期需要 pipeline 自动化
- 直接 API:简单转写、无专有名词、一次性手动处理 对于 B 站 UP 主来说,直播录制这种边界不清晰的场景最适合豆包;短视频配音转写用剪映自带功能即可。
4. 成本监控节点¶
单次音频处理(277 秒)约 0.008 元,批量处理时建议:
- 先用一段样本测试上下文效果
- 监控 completion token 占比:给上下文后 completion token 下降是好信号
- 超过 0.02 元/分钟的处理需要检查 prompt 是否过于冗余
相关页面¶
- 原文存档
- Claude Code — 主要工作台(被补上眼睛和耳朵的那位)
- Agent 输入侧瓶颈背景
相关实体¶
Ch17.022 OlmoEarth v1.1: A more efficient family of Earth observation models¶
📊 Level ⭐⭐⭐ | 8.1KB |
entities/olmoearth-v1-1-a-more-efficient-family-of-earth-observation-models.md
概述¶
OlmoEarth v1.1 是 AllenAI 于 2026 年 5 月 19 日发布的地球观测模型家族,是 2025 年 11 月发布的 OlmoEarth v1 的升级版本。该版本在保持 v1 性能水平的前提下,将计算成本降低至多 3 倍,显著提升了模型的经济性和可部署性。
OlmoEarth 已被广泛应用于追踪红树林变化(mangrove change tracking)、分类森林损失驱动因素(classifying drivers of forest loss)、制作国家级作物类型地图(country-scale crop-type maps)等任务,部署范围覆盖国家、洲际乃至全球尺度。
技术架构¶
OlmoEarth 模型基于 Transformer 架构,处理遥感数据时需先将数据转换为模型可摄入的 token 序列。在 Transformer 模型中,模型大小和 token 序列长度 是控制效率的两个关键杠杆:模型大小决定每次计算的资源消耗,而 token 序列长度则决定计算的复杂度——由于 self-attention 的二次复杂度,序列长度的微小减少都能显著降低推理成本。
Sentinel-2 数据处理¶
Sentinel-2 是 OlmoEarth 处理的常见遥感数据模态。Sentinel-2 输入张量包含空间维度(H × W,表示纬度和经度像素)、时间维度 T 以及 12 个 Sentinel-2 波段通道 [H, W, T, D=12]。Sentinel-2 数据具有 10m、20m、60m 三种分辨率,这使得数据表示比单一分辨率的遥感数据更为复杂。
传统方案按空间 patch 尺寸 p 将 Sentinel-2 图像分割为 p × p 的块,对每个 patch 在每个时间步和每个分辨率下创建一个 token。由于 Sentinel-2 包含 3 种分辨率,一个包含 2 个时间步的 Sentinel-2 输入每个 patch 产生 6 个 token(2 时间步 × 3 分辨率)。数学上,形状为 [H, W, T, D=12] 的 Sentinel-2 输入将产生 H/p × W/p × T × 3 个 token。
Token 设计与效率优化¶
v1.1 的核心优化策略是将不同分辨率的 token 合并为单一 token,从而将 token 数量减少至原来的 1/3。这一策略在 Galileo 和 SatMAE 等模型中已被验证有效——SatMAE 表明为每个分辨率使用独立 token 能带来显著更好的结果。然而,CROMA 等模型采用单一 token 处理所有波段,与前述方法不同。
朴素地合并 token 会导致显著的性能下降,在 m-eurosat kNN(遥感模型常用基准任务)上下降高达 10 个百分点。研究团队假设,将 Sentinel-2 波段分离到不同 token 使 OlmoEarth 能够更轻松地建模重要的跨波段关系(cross-band relationships)。
为在不影响性能的前提下合并 token,团队修改了预训练策略(pretraining regimen),具体方案详见技术报告。
模型家族与性能¶
v1.1 模型家族实现了「事半功倍」(doing more with less)的效果。在每个模型规格下,OlmoEarth v1.1 的运行成本比 v1 降低至多 3 倍,使得频繁的行星尺度地图更新对所有团队都更加经济实惠。
模型家族包括 Base、Tiny 和 Nano 三个规模,分别适用于不同的计算预算和任务需求。所有模型权重均在 Hugging Face 上开放下载。
研究价值¶
对于研究者而言,OlmoEarth v1.1 具有重要的学术价值:预训练遥感模型存在多个自由度(架构、数据集、预训练算法),导致性能变化难以归因。v1.1 在与 v1 相同的数据集上训练,使得两个版本之间的差异能够精确隔离出方法论变化的影响,有助于推进遥感模型预训练的科学研究。
资源链接¶
- 模型权重:https://huggingface.co/collections/allenai/olmoearth
- 技术报告:https://allenai.org/papers/olmoearth_v1_1
- 训练代码:https://github.com/allenai/olmoearth_pretrain
深度分析¶
-
Token 序列长度是遥感 Transformer 模型的关键效率杠杆——由于 self-attention 的二次复杂度,即使小幅减少 token 数量也能显著降低推理成本。
-
朴素地合并多分辨率 token 会导致性能大幅下降(m-eurosat kNN 上下降 10 个百分点),研究团队假设分离 Sentinel-2 波段到不同 token 使模型能够更轻松地建模跨波段关系。
-
v1.1 在相同数据集上训练,使两个版本之间的差异能够精确隔离出方法论变化的影响,解决了预训练遥感模型因多自由度(架构、数据集、预训练算法)而难以归因的科学研究难题。
-
模型家族(Base/Tiny/Nano)的分层设计让用户能根据计算预算选择合适的规模,实现成本与性能的平衡,3x 计算成本降低使行星尺度频繁地图更新对所有团队都更加经济。
-
计算成本贯穿整个 OlmoEarth 生命周期(数据导出、预处理、推理、后处理),效率优化在整个 pipeline 中都具有实际价值,而非仅限于模型本身。
实践启示¶
-
部署行星尺度遥感应用时,优先考虑 token 序列长度优化——可能比缩小模型规格带来更显著的收益
-
切换到 v1.1 后如遇特定任务回归,需查阅技术报告中列出的已知退化场景,必要时回退至 v1
-
多分辨率数据处理时,简单 token 合并不可行——需配合修改后的预训练策略才能不影响性能
-
研究遥感模型预训练时,v1.1 与 v1 的对比是理想的控制变量实验——相同数据集隔离出方法论变化的影响
-
资源受限团队建议从 Nano/Tiny 开始验证可行性后再扩展至 Base,以获得最佳的投入产出比
相关实体¶
- Olmoearth V1 1 Efficiency
- Kamacoder Agent Context Drift Tool Hallucination
- Olmo Hybrid Gdn Wave 2026
- How Llms Actually Work 0Xkato
- Agent Reliability Context Drift Tool Hallucination
→ 原文存档
Ch17.023 MolmoMotion:语言引导的 3D 运动预测模型¶
📊 Level ⭐⭐⭐ | 7.5KB |
entities/molmomotion-language-guided-3d-motion-forecasting.md
MolmoMotion:语言引导的 3D 运动预测¶
Background:Allen AI 于 2026-06-17 发布 MolmoMotion,将视觉语言模型(VLM)与 3D 运动预测相结合,实现通过自然语言指令预测物体未来 3D 轨迹的能力。该工作同时发布了 MolmoMotion-1M 数据集和 PointMotionBench 基准测试。
摘要¶
MolmoMotion 是 Allen AI 推出的运动预测模型,核心能力是给定一张 RGB 图像、一组标记在物体上的 3D 查询点、以及一段自然语言动作描述,预测这些点在未来几秒内的 3D 运动轨迹。与传统运动感知(retrospective perception)不同,MolmoMotion 关注的是前瞻性的运动预测——在物体移动之前就预判其轨迹。该模型在 PointMotionBench 基准上超越了所有现有方法,并在机器人规划和可控视频生成两个下游任务上展示了实际价值。
核心要点¶
- 前瞻 vs 感知:现有运动感知模型擅长追踪已发生的运动,MolmoMotion 则预测未来运动——这对机器人抓取、视频生成等需要「预判」的场景至关重要
- 语言条件化:通过自然语言指令(如"将桌上的木碗移开并旋转")引导运动预测,无需物体类别模板
- 类无关表示:使用物体表面的稀疏 3D 点集表示运动,适用于刚体、铰接体、甚至有限的可变形物体
- 双变体架构:自回归版(MolmoMotion-AR)逐步预测坐标,流匹配版(MolmoMotion-FM)在连续 3D 空间中变换噪声为轨迹
- 大规模数据集:MolmoMotion-1M 包含 116 万视频、736 种运动类型、5600 种不同物体的 3D 点轨迹
- 下游应用验证:机器人抓取任务成功率从 56.0% 提升至 76.3%;视频生成中在所有 5 项运动质量指标上超越基线
深度分析¶
运动表示:为什么选择 3D 点集¶
MolmoMotion 的设计决策始于运动表示的选择。团队评估了多种表示方案后,选择了物体附着的 3D 表面点(object-attached 3D points in world space),因为它同时满足三个关键属性:
- 类无关(Class-agnostic):不依赖人体骨架、手部模板或任何特定物体类别的先验。稀疏表面点可以描述刚体滑动、铰接体开合、以及有限的可变形运动
- 视角稳定(View-stable):点在共享世界坐标系中定义,因此同一物理运动在不同相机视角下保持一致表示
- 下游可直接使用:紧凑的 3D 轨迹可以直接传递给机器人策略或视频生成模型,无需额外渲染
这种表示的核心洞察是:运动的本质是物体表面点在空间中的位移,而非像素的流动或关节角度的变化。这使得 MolmoMotion 可以用一套统一的方法处理从厨房操作到动物行走的各种运动场景。
架构设计:Molmo 2 backbone + 双解码头¶
MolmoMotion 建立在 Molmo 2 视觉语言模型之上,利用其跨模态理解能力将语言指令与图像中的物体和点关联起来。输入包括:
- RGB 观察图像的视觉 token
- 动作描述的文本 token
- 2D 查询点特征 token(从 Molmo 2 视觉编码器采样)
两个解码变体各有侧重:
MolmoMotion-AR(自回归):将 3D 坐标编码为结构化文本,按时间顺序逐步输出未来轨迹。每一步的预测都基于已生成的轨迹,天然鼓励平滑展开,在路径确定性强的场景下精度最高。
MolmoMotion-FM(流匹配):在连续 3D 空间中通过将噪声变换为运动来预测轨迹,更适合表达指令存在多种合理未来时的不确定性——例如"把碗移开"可能有多种合法路径。
数据引擎:从无约束视频到 3D 轨迹¶
训练数据的获取是最大挑战之一。现有 3D 轨迹数据集规模小且领域受限,而互联网视频虽然多样但缺乏 3D 标注。团队构建了自动标注管线:
- 给定输入视频和动作描述,定位运动物体并采样查询点
- 在物体上追踪密集 2D 点
- 将 2D 轨迹提升到共享的度量 3D 坐标系
- 使用物体级空间和时间一致性先验过滤不可靠轨迹
- 围绕物体实际运动区间裁剪视频
这一管线产出了 MolmoMotion-1M——目前已知最大的动作描述-物体 3D 点轨迹数据集,覆盖 736 种运动类型和 5600 种不同物体。
下游任务验证¶
机器人规划:MolmoMotion 的核心假设是,同一物体的运动轨迹在不同执行器(人手 vs 机器人夹爪)下是相似的。在 DROID 数据集上微调后,模拟环境中 pick-and-place 成功率达 76.3%(vs Molmo 2 基线 56.0%),且学习速度显著更快——10K 步达到 51% 准确率(基线仅 19%)。真实机器人上的测试同样显示更快收敛。
视频生成:将 MolmoMotion 的预测轨迹注入图像到视频生成模型,可以显著提升运动质量。在所有 5 项运动相关指标上超越基础模型,在 4/5 项指标上超越更大的 I2V 模型。这对精确的小幅运动(如"火烈鸟将喙伸入水中")尤其有效。
局限与展望¶
当前限制包括:每个物体仅使用 8 个查询点,不足以密集表示表面几何,限制了复杂可变形运动的处理能力。团队认为运动预测是机器智能的基本能力之一——如同感知已发生的事情一样重要。MolmoMotion 是朝这一方向迈出的一步,预期将在机器人、视频生成等领域催生更多应用。
实践启示¶
- 运动表示的选择至关重要:3D 点集表示在类无关性、视角稳定性和下游可用性之间取得了最佳平衡,这一设计思路可推广到其他需要跨领域泛化的感知任务
- VLM 作为运动预测 backbone 的潜力:利用视觉语言模型的跨模态理解能力来关联语言指令与空间运动,为条件化运动生成开辟了新路径
- 自动数据引擎是规模化关键:从无约束视频自动生成 3D 轨迹标注的管线,解决了运动预测领域长期面临的数据瓶颈
- 机器人-视频生成的双向迁移:运动知识在物理仿真和视觉生成之间的迁移能力,暗示了统一运动表示在多模态 AI 中的基础性作用
相关实体¶
→ 原文存档
Ch17.024 Introducing 1-bit and Ternary Bonsai Image Models¶
📊 Level ⭐⭐⭐ | 6.2KB |
entities/bonsai-image-4b-1-bit-ternary.md
Introducing 1-bit and Ternary Bonsai Image Models¶
深度分析¶
Published Time: 2026-05-26
Markdown Content: 
Images generated from Ternary Bonsai Image 4B
Today we’re releasing Bonsai Image 4B, a family of compact image-generation models designed to run high-quality diffusion inference on local hardware: from laptops to phones.
Bonsai Image 4B comes in two variants:
- 1-bit Bonsai Image 4B uses binary {−1, +1} transformer weights with an FP16 group-wise scaling factor, giving 1.125 effective bits per weight. It targets maximum compression and is the right fit when memory pressure, bandwidth, and the deployment footprint are the primary constraints.
- Ternary Bonsai Image 4B uses {−1, 0, +1} transformer weights with an FP16 group-wise scaling factor, giving 1.71 effective bits per weight. The additional zero state gives the model more representational flexibility, improving visual quality and prompt fidelity while remaining extremely compact.
The result is a new deployment regime for image generation: capable outputs, open weights, and practical local inference on devices that were previously out of reach for this class of model. To our knowledge, Bonsai Image 4B is the first image model in its parameter class to run directly on an iPhone.
Built for local generation¶

Images generated from 1-bit Bonsai Image 4B
Local image generation starts with a hard constraint: the model has to fit within the device’s memory budget.
For a 4B-class image model, the diffusion transformer is the largest part of the model and the part that runs repeatedly during generation. Each denoising step invokes the transformer again, so transformer size directly shapes memory pressure, bandwidth demand, and local inference speed.
Bonsai Image 4B is built from the FLUX.2 Klein 4B. It keeps the architecture intact but changes how the transformer weights are represented. By moving those weights into binary and ternary form, Bonsai reduces the part of the image pipeline that matters most for local deployment.
| Model | Diffusion Transformer | Reduction vs FP16 |
|---|---|---|
| FLUX.2 Klein 4B | 7.75 GB | 1.0x |
| 1-bit Bonsai Image 4B | 0.93 GB | 8.3x |
| Ternary Bonsai Image 4B | 1.21 GB | 6.4x |
Table I:Diffusion transformer footprint for models.
The binary layers provide roughly a 14x reduction relative to full-precision transformer weights. A small set of precision-sensitive supporting tensors (~5%), called the projection layers, remains in FP16 so the final 1-bit Bonsai Image 4B transformer is 0.93 GB: an 8.3x reduction from the 7.75 GB full-precision FLUX.2 Klein 4B.
The ternary variant follows the same structure. Its ternary layers provide roughly a 10x reduction and the final Ternary Bonsai Image 4B transformer is 1.21 GB, a 6.4x reduction from the full-precision transformer. It is slightly larger than the 1-bit model, but the additional zero state improves visual quality and prompt fidelity.
Including the compressed text encoder and FP16 VAE, the Apple Silicon deployment payload is 3.42 GB for 1-bit Bonsai Image 4B and 3.88 GB for Ternary Bonsai Image 4B. For comparison, the full precision FLUX.2 Klein 4B requires a deployment payload of 15.97 GB. Since, at runtime, the text encoder is offloaded after prompt encoding, the mean memory usage is smaller than the total payload. When generating a 512x512 image, the mean-active memory is 1.5 GB and 1.96 GB, for the binary and ternary models, compared to 11.74 GB for the original FLUX.2 Klein 4B (a reduction of 7.8x and 6.0x, respectively). For a 1024x1024 image, the mean-active memory is 1.95 GB and 2.38 GB, for the binary and ternary models, compared to 14.39 GB for the original FLUX.2 Klein 4B (a reduction of 7.4x and 6.0x, respectively).
This reduction in memory footprint changes where the model can run. Our deployment stack supports Apple Silicon iPhones, iPads and Macs and CUDA GPUs, using MLX low-bit paths on Apple hardware and Gemlite low-bit GEMM kernels on CUDA. On iPhone 17 Pro Max, the full-precision FLUX.2 Klein 4B pipeline does not fit within the device memory budget, while both Bonsai Image variants run on-device.
Video I: Image generation on Bonsai Studio
In practice, Bonsai Image 4B generates a 512x512 image in 9.4 seconds on an iPhone 17 Pro Max and about 6 seconds on Mac M4 Pro. On Mac M4 Pro, Bonsai Image 4B is up to 5.6x faster than the stock full-precision MFLUX pipeline.
Benchmarking performance¶
Compression only matters if the model remains useful. We evaluated Bonsai Image 4B across three complementary benchmarks: GenEval for object composition and attribute binding; HPSv3 human preference and aesthetic quality; DPG-Bench dense prompt following and semantic faithfulness.
 是 Jiatao Gu 等人于 2026 年 5 月提交至 arXiv 的新型扩散模型变体,专注于解决少步生成(few-step generation)场景下传统扩散模型假设失效的核心问题。传统扩散模型将采样分解为大量小步高斯去噪——这一假设在生成被压缩至少数几步时物理上不成立。NTM 的核心创新在于:将每一步 reverse 过程建模为 expressive conditional normalizing flow,并通过精确似然训练实现端到端优化。在文生图基准上,NTM 仅用 4 步采样即可匹配或超越强基线,同时唯一保留对生成轨迹的精确似然计算能力。 本文于 2026 年 5 月 8 日提交至 arXiv,作者团队来自 Apple ML Research。
背景问题:少步生成的困境¶
扩散模型(DDPM、Flow Matching 等)的采样通常需要数十至数百步去噪,导致推理成本高昂。现有的少步加速方法分为三类:
- Distillation(蒸馏):将多步教师模型的知识蒸馏至少步学生模型,但训练不稳定且需要大规模数据
- Consistency Training(一致性训练):强制不同噪声水平下的样本映射至同一直流,核心思路接近 consistency model,但牺牲了似然框架
- Adversarial Objectives(对抗目标):引入 GAN式判别器提升少步质量,但失去精确似然,无法进行概率评估 上述方法有一个共同缺陷:均放弃了似然框架,这在压缩评估、异常检测、模型选择等下游任务中是致命的。
核心创新¶
条件归一化流建模每步 Reverse 过程¶
NTM 的核心架构决策是将每步 reverse 去噪过程建模为条件归一化流(Conditional Normalizing Flow)。归一化流通过可逆变换实现精确似然计算,但传统上每步独立建模时表达能力受限。NTM 的解法是:
- 每步内(within-step):使用浅层可逆(invertible)块,保证该步内的精确似然可计算
- 跨步(across-step):引入深层并行预测器,捕捉整个生成轨迹上的依赖关系 这种"浅层可逆 + 深层跨步"的设计在表达能力和计算效率之间取得了工程折中:每步只做轻量变换,用跨步的深度网络补充表达力,避免了深层可逆网络的高计算成本。
精确轨迹似然与自蒸馏¶
NTM 的精确轨迹似然(exact trajectory likelihood)使其天然支持自蒸馏(self-distillation):一个轻量级去噪器可以在 NTM 模型自身的 score 基础上进行微调,产出高质量 4 步采样结果。这意味着 NTM 可以"自我压缩"——无需外部多步教师模型,自己教自己完成少步化。
预训练初始化¶
NTM 支持从预训练的 flow-matching 模型初始化,这利用了 flow matching 的线性轨迹假设。Flow matching 通过线性插值噪声和真实数据预测向量场,NTM 将这一线性预测过程参数化为条件归一化流,从线性轨迹出发逐步学习更复杂的反转动态。这一特性显著加速了 NTM 的收敛。
深度分析¶
架构哲学:精确描述 vs. 实用速度¶
NTM 的定位是保留完整似然框架的少步方法,这使其与单纯追求速度的方法(GAN-based、adversarial distillation)本质不同。速度不是唯一目标;保持概率语义——即能够精确计算 p(x|z)——同样重要。在需要严格概率计数的场景(如数据压缩、异常检测、生成质量评估),NTM 的优势是其他少步方法无法替代的。
与 Consistency Models 的本质区别¶
Consistency Models(CM)通过强制不同 t 时刻的输出与 t=0 的一致来实现少步化,本质上是一种隐式的蒸馏,丢失了似然信息。NTM 保留了精确似然,可以进行困惑度(perplexity)计算,这使得两种方法面向不同的应用场景:CM 适合对质量要求极高、对概率评估无需求的场景;NTM 适合需要概率输出的场景。
少步化的理论基础¶
传统扩散模型的"多步小步"假设在数学上对应于对 score 函数进行 Euler-Maruyama 积分。当步数极少时,积分误差主导,输出质量崩溃。NTM 通过学习每步的完整条件归一化流绕过了这一积分近似——不再依赖"小步累积",而是直接学习粗粒度的条件变换。这在理论上解释了为什么 NTM 在 4 步下仍能保持高质量,也为进一步压缩至 2-3 步提供了方向。
实践启示¶
部署建议¶
- 若部署场景需要 4-8 步采样,NTM 值得关注——在步数预算内提供精确似然输出
- 自蒸馏机制提供了一个将大模型能力压缩到小采样器的正规框架,而非依赖启发式 distillation,适合需要可控压缩比的团队
- NTM 可从预训练 flow-matching 模型热启,若已有 Flow Matching 部署基础设施,迁移成本较低
研究方向¶
- 其他领域的自蒸馏:自蒸馏机制在强化学习(self-play)、语言模型(self-reward)中有类似应用,NTM 将这一范式引入扩散模型,值得在视频生成、3D 生成等领域探索
- 轨迹级概率:精确轨迹似然使得在生成轨迹级别而非样本级别进行评估成为可能,这对研究扩散模型的隐式偏差(implicit bias)有重要价值
注意事项¶
- 浅层可逆块的表达能力是否足够支撑复杂任务(如高分辨率文生图)仍需更大规模验证
- 4 步采样的质量上限是否接近其实用上限,以及更多步数(8-16)时是否仍有优势
相关实体¶
Ch17.026 ai视频工具悄悄走到了第三阶段¶
📊 Level ⭐⭐⭐ | 5.8KB |
entities/ai视频工具悄悄走到了第三阶段.md-> 原文存档
ai视频工具悄悄走到了第三阶段¶
source:
摘录¶
AI视频工具悄悄走到了第三阶段 这两年我看了一堆号称要颠覆AI视频的新产品。看了一阵子,我大概看出了一个规律。 第一代AI视频工具,是文生视频的盲盒。 一句话扔进去,等几分钟,开出来什么算什么,不满意只能重新投币。 第二代多了个Agent入口,AI开始能用对话方式调度。但Agent是悬浮在产品之外的「插件」,对话归对话,画布归画布,AI在另一个房间帮你跑腿。 最近我用了一个国产的画布型AI视频工具,叫RHTV。打开第一眼我就感觉,AI视频工具可能在悄悄进第三阶段了。 这一代的关键词是「画布原生」。Agent不是悬浮在画布之外的服务,而是画布本身的大脑。它住在你的工作流里,看得见你每一步在做什么,也让你看得见它每一步在想什么。 听起来好像只是产品形态的小调整,但用过之后我意识到,它其实在重新定义「人和AI怎么一起做事」这件事。 一、AI视频工具的三阶段演化 把过去两年的AI视频工具按使用体验排一下,能很清晰地看到三个阶段。 第一阶段,文生视频盲盒。 你输入一句话,等模型出片。整个过程是黑盒,AI怎么理解你的需求、怎么选模型、怎么处理细节,全在后端,用户看不到。结果不满意只能重新生成,没有...
标签¶
- source/wechat
相关实体¶
主题导航 - 提速4.48倍!哈工大华为新框架让扩散大模型精度无损推理起飞 - MOC
深度分析¶
1. 三阶段演化路径的本质逻辑¶
AI视频工具的三代演化,本质上反映了人机协作模式的深层变迁。 第一阶段(文生视频盲盒) 代表的是「AI作为黑盒服务」的范式——用户提交指令,AI在封闭系统中完成推理并输出结果,用户与AI之间是单向的「投币-产出」关系。这一阶段的核心矛盾是:AI能力再强,用户也只能在结果不满意时重新生成,无法干预过程。 第二代(Agent插件化) 引入了对话入口,AI开始具备任务拆解和工具调度的能力。但Agent作为「悬浮在画布之外的服务」,与用户的核心工作区(画布)是割裂的。AI在另一个房间跑腿,用户在这里指挥——这种架构决定了AI永远是一个可召唤但不可信赖的外部助手。 第三代(画布原生Agent) 的核心突破在于:Agent不再是外接插件,而是画布本身的大脑。AI内嵌在用户的工作流中,能感知用户每一步的操作上下文,同时将自身的推理过程可视化地呈现给用户。这意味着AI从「被召唤的工具」变成了「可协作的伙伴」。
2. 「画布原生」意味着什么¶
「画布原生」不仅仅是产品形态的创新,它代表了一种新的AI落地哲学: - 感知上下文:Agent能看到用户在做什么,能基于当前工作状态做动态决策,而不是每次都需要用户重新描述背景。 - 推理透明:AI每一步在想什么对用户可见,用户可以及时纠正AI的方向,而不是等最终结果出来才发现跑偏了。 - 深度集成:AI成为工作流的一部分,而不是一个需要切换上下文才能调用的独立工具。 这种模式让人想起儿时玩的「画布填色」——你画一笔,AI帮你补全并实时呈现,每一笔都在双方的交互中完成。这从根本上重新定义了「人和AI怎么一起做事」。
3. 对AI视频赛道竞争格局的启示¶
RHTV作为第三阶段的先行者,其「画布原生」路线可能会对赛道竞争产生以下影响: - 工具型AI的终点可能不是更强的模型,而是更好的协作体验:当模型能力趋于同质化,用户体验和工作流集成度将成为核心差异化因素。 - 纯API调用模式将面临挑战:那些依赖调用外部模型API的视频工具,如果不能提供深度的上下文感知和过程可视化,可能会被原生集成方案降维打击。 - 「AI as Co-pilot」将取代「AI as Tool」成为主流叙事:用户需要的不是一个更强大的工具,而是一个能理解自己、跟自己协同工作的伙伴。
实践启示¶
给AI视频工具开发者的建议¶
- 重新思考Agent的架构定位:不要把Agent做成一个「悬浮在画布之外的插件」,而是让它成为画布本身的一部分。Agent应该能感知用户的每一步操作,并在上下文中提供实时的智能辅助。
- 优先建设推理可视化能力:透明化AI的思考过程比提升最终输出质量更重要。用户需要看到AI在想什么,才能建立信任并及时干预。
- 从「工具调用」转向「工作流共生」:与其让用户学习如何调用AI,不如让AI自适应用户的工作流。用户不应该为了使用AI而改变自己的工作方式。
给企业/创作者的建议¶
- 优先选择原生集成方案:在评估AI视频工具时,关注AI是否能理解你的工作上下文、是否能呈现推理过程,而不仅仅是模型参数或生成速度。
- 将AI纳入工作流的思维转变:不要把AI当成「出图机器」,而是当成一个能跟你一起工作的协作者。选择那些让你能持续参与、引导、纠正AI的工具。
- 关注「第三阶段」产品的先发优势:RHTV等先行者正在定义下一代AI视频工具的标准,及早布局可能带来显著的效率红利。
Ch17.027 Moebius: 0.2B Lightweight Image Inpainting with 10B-Level Performance¶
📊 Level ⭐⭐⭐ | 5.8KB |
entities/moebius.md
Moebius: 0.2B Lightweight Image Inpainting with 10B-Level Performance¶
→ 原文存档
摘要¶
Moebius 是华中科技大学与 VIVO AI Lab 联合提出的超轻量图像修复(inpainting)框架,通过独创的 Local-λ Mix Interaction (LλMI) 架构和自适应多粒度蒸馏策略,以仅 0.22B 参数实现了与 11.9B 参数工业级模型 FLUX.1-Fill-Dev 相当甚至超越的生成质量,推理速度提升超过 15 倍。这一工作挑战了"模型越大越好"的行业共识,证明了任务特定专家模型(task-specific specialist)在明确场景下可以完胜通用巨型模型。
核心要点¶
架构创新:LλMI Block¶
Moebius 的核心架构创新是 Local-λ Mix Interaction (LλMI) Block,它系统性地重构了 diffusion backbone 中的注意力机制。传统 self-attention 和 cross-attention 的计算复杂度为 O(n²),LλMI 将空间上下文和全局语义先验压缩为固定大小的线性矩阵,在保留复杂 latent 交互的同时大幅削减参数量。
LλMI 由两个子模块组成: - Interactive-λ Module:将全局语义先验编码为固定大小的表示,突破了极压缩架构中常见的表示瓶颈 - Local-λ Module:高效聚合局部空间上下文,保持对细节纹理的感知能力
这种设计使得 Moebius 的参数量仅为 FLUX.1-Fill-Dev 的不到 2%(0.22B vs. 11.9B),同时在复杂纹理和面部合理性等场景下甚至超越了 10B 级通用模型。
蒸馏策略:自适应多粒度对齐¶
Moebius 的第二大创新是自适应多粒度蒸馏策略(Adaptive Multi-Granularity Distillation),其核心思路是在 latent space 内完成知识迁移,避免昂贵的 pixel-space decoding。
该策略的关键特征包括: - 多粒度监督对齐:从微观中间特征到宏观扩散轨迹的全方位对齐 - 梯度范数自适应损失加权:动态平衡多个 gradient-based losses,确保训练稳定性 - 架构-蒸馏协同优化:系统性探索紧凑结构与蒸馏之间的互约束关系和上界
教师模型为同团队此前提出的 PixelHacker,通过映射架构-蒸馏协同前沿(synergy frontier),确保 0.22B 的 Moebius 学生模型最大限度吸收教师的语义推理能力,同时避免表示饱和。
深度分析¶
任务特化 vs. 通用扩展的范式之争¶
Moebius 的成功揭示了一个深层问题:在图像修复这一明确定义的任务上,盲目扩大通用模型是否是最优策略?答案是否定的。Moebius 证明了以下逻辑链:
- 任务边界清晰时,架构设计可以精准针对任务特性优化
- 极致压缩需要配合匹配的蒸馏策略,两者缺一不可
- 固定大小线性矩阵是一种突破极压缩架构表示瓶颈的有效手段
这一模式与 知识代理 的思路异曲同工——在特定领域注入结构化知识的小模型可以超越通用大模型。
技术参数与基准测试¶
Moebius 在以下基准上进行了全面评估:
| 维度 | Moebius (0.22B) | FLUX.1-Fill-Dev (11.9B) |
|---|---|---|
| 参数量 | 226M | 11.9B |
| 推理速度 | 26.01 ms/step | >15x 慢 |
| 自然场景 (Places2) | 匹配/超越 | 基准 |
| 人像场景 (CelebA-HQ, FFHQ) | 匹配/超越 | 基准 |
在 6 个综合基准(涵盖自然场景和人像场景)上,Moebius 实现了与 10B 级 SOTA 通用模型相当甚至更优的表现。
与模型压缩领域的关联¶
Moebius 的工作与当前模型压缩领域的多个方向形成呼应: - 知识蒸馏:从大模型向小模型迁移能力的经典范式,Moebius 将其推进到 latent space 级别 - 结构化剪枝:LλMI 的设计思路类似对注意力机制的结构性重构 - 稀疏化:Moebius 证明了极端参数压缩(<2%)在任务特化场景下完全可行
这与 模型规模推演 中关于 sparsity 作为参数放大器的讨论形成有趣对比——Moebius 走的是另一条路:不是增加总参数并稀疏化,而是直接在架构层面大幅压缩。
实践启示¶
- Task-specific specialist > General-purpose giant:在边界明确的任务上,精心设计的小模型可以完胜通用巨模型,这一原则适用于图像修复、文档处理、特定领域问答等多个场景
- Latent-space distillation 是关键:避免 pixel-space decoding 的计算瓶颈是 Moebius 蒸馏策略成功的核心,这一思路可推广到其他 diffusion-based 任务
- 边缘部署的可行性:0.22B 参数量使得 Moebius 可以部署在消费级 GPU 甚至边缘设备上,大幅降低图像修复的部署门槛
- 架构与蒸馏的协同设计:单独优化架构或蒸馏都不够,两者的协同前沿需要系统性探索
相关实体¶
- 模型规模推演 — 模型大小与硬件约束的系统分析
- 知识代理超越前沿模型 — 小模型+领域知识超越大模型的另一范式
- 蒸馏、剪枝、量化等模型压缩技术是 Moebius 的理论背景
→ 原文存档
Ch17.028 Fine-Tuning NVIDIA Cosmos Predict 2.5 with LoRA/DoRA for Robot Video Generation¶
📊 Level ⭐⭐⭐ | 5.7KB |
entities/fine-tuning-nvidia-cosmos-predict-2-5-with-lora-dora-for-robot-video-generation.md
核心要点¶
- Published Time: 2026-05-18T16:00:21.256Z Back to Articles [
 ](http
](http
相关实体¶
- Fine Tuning Nvidia Cosmos Predict 25 With Loradora For Robot Video Generation
- Nvidia Cosmos Fine Tuning Robot Video Generation
- Fine Tuning Cosmos
- Nvidia Mcg Toolkit Model Documentation
- Nvidia Agentic Systems Extreme Co Design
→ 原文存档
深度分析¶
世界模型在机器人领域的战略价值 NVIDIA Cosmos Predict 2.5 本质上是一个大规模世界模型(world model),能够基于文本、图像或视频片段生成物理上可信的视频。这一能力对机器人学习具有深远意义:真实机器人轨迹数据采集成本高、速度慢,而通过微调后的世界模型生成合成轨迹,提供了一条可扩展的替代路径。微调后的模型可以生成符合特定机器人外形、任务语义和相机视角的合成数据,用于训练机器人策略——而不需要真实机器人在物理环境中反复执行任务。 LoRA vs DoRA 的工程取舍 文章给出了清晰的实验结论:LoRA 和 DoRA 在 rank=32 时收敛到几乎相同的性能。DoRA 将权重分解为 magnitude 和 direction 两个分量,理论上可以更稳定地学习低秩更新,但在这一任务上优势并不明显。这意味着对于大多数机器人视频生成任务,标准 LoRA 是更务实的选择——实现更简单,生态更成熟,调试工具更丰富。 rank 值的选择需要权衡:
- rank=8:adapter 文件更小,训练更快,适合快速原型验证;但指令-following(使用正确的手、正确的物体)能力受限。
- rank=32:约 50M 可训练参数,指令-following 质量显著提升;几何一致性和物理可信度主要由冻结的基础模型保证,LoRA 仅负责将分布迁移到领域内。 Rectified Flow:生成范式的务实选择 Cosmos Predict 2.5 采用 rectified flow 而非 DDPM 或 Flow Matching。核心思想是线性插值噪声和数据,然后在采样过程中沿直线传输。公式
xt = σt·noise + (1−σt)·clean和目标noise − clean使训练目标简化为一阶线性预测,采样路径笔直,步数需求少。这种方式在视频生成中平衡了生成质量和采样效率,对需要低推理延迟的机器人实时应用场景尤为重要。 评估体系的三层验证 文章建立了三层评估体系: - Temporal Sampson Error:连续帧间的几何一致性,衡量时序稳定性。
- Cross-view Sampson Error:多相机视角间的几何一致性,衡量空间推理能力。
- LLM-as-a-Judge:使用 Cosmos Reason2 作为评判模型,分别从物理可信度和指令-following 两个维度打分(1-5分)。这一设计避免了纯指标评测的盲点,能够捕捉"看起来对但物理上不对"的生成瑕疵。
实践启示¶
- 起点选择 rank=8 快速验证,迭代到 rank=32 追求质量。100 个 epoch(约 2.5 小时 8×H100)已足够产生显著提升,无需过度训练。
- DoRA 适用于内存极端受限或低 rank 下训练不稳定的场景。如果你有 GPU 预算且 LoRA 在 r=8 时收敛正常,保持 LoRA。
- 合成数据生成是 Robot Learning 的性价比之选:用微调后的世界模型批量生成任务变体(不同物体颜色、位置、光照),扩充训练集,可显著降低真实数据采集成本。
- 推理时使用
fuse_lora(lora_scale=1.0)消除 adapter 推理开销,合并后的模型推理速度与 base model 相当。 - 如果需要多领域适配(如不同机器人外形或不同任务类型),分别训练多个 LoRA adapter,推理时按需切换——adapter 文件体积小(~50MB),管理成本低。
- 工程落地路径:先用 GR00T 风格的小规模数据集(92个视频)验证方案可行性,再迁移到自有机器人数据集上微调。
Ch17.029 Stable Audio 3.0 开源音频生成模型¶
📊 Level ⭐⭐⭐ | 5.1KB |
entities/stable-audio-3.md
核心要点¶
- Stable Audio 3.0 是 Stability AI 推出的 open-weight 音频生成模型系列
- 支持音乐生成、Sound Effect、语音合成等多种音频任务
- 模型权重开放下载,支持本地部署和微调
模型架构¶
- 基于 Transformer 的自回归模型
- 支持高达 95kHz 的音频采样率
- 使用 Muon 优化器和零伞(Zero-Schmidt)正则化训练
技术特点¶
- Open-weight 发布:权重开放下载,支持本地推理
- 高质量生成:支持多种音频质量档次
- 可控生成:支持风格、节奏、时长等条件控制
相关实体¶
- How To Build Audio Transcription Agent
- Helloworldmedia.Notion Self Filming Guide By Hello World Media 2F60Dfa5E2E180Cfa
- Helloworldmedia.Notion Self Filming Guide By Hello World Media 2F60Dfa5E2E180Cfa
- Ntm Normalizing Trajectory Models
- Nvidia Gamma World Multi Agent World Model
→ 原文存档
深度分析¶
Stable Audio 3.0 的发布标志着 Stability AI 在音频生成领域采取了与图像生成类似的开放策略。 Stability AI 在博文中明确表示:"Music has always evolved through the collective creativity of its community... Generative audio will be no different. We want to foster the same kind of community-driven innovation in audio that we sparked in image generation with the launch of Stable Diffusion" 。这一战略定位表明 Stability AI 希望复刻 Stable Diffusion 在图像领域带来的开源生态效应,通过开放权重吸引社区参与模型优化和应用创新 。
从技术架构角度看,Stable Audio 3.0 引入了一个关键的创新:semantic-acoustic autoencoder(语义-声学自编码器),这使得更 长、更灵活的音频生成成为可能 。最显著的进步体现在可变长度生成能力上:3.0 Small 可生成最长 2 分钟的音频,相比 Stable Audio Open Small 的 11 秒和 Stable Audio Open 的 47 秒有本质提升;而 3.0 Medium 和 3.0 Large 则可生成超过 6 分钟的音频 。这一能力突破对于音乐创作场景意义重大,因为完整的音乐作品通常需要 更长的持续时间。
值得关注的是 3.0 Small 是首个能够在设备端完成完整音乐创作的模型 。这意味着音乐创作不再需要依赖云端计算资源,用户可以在手机或普通笔记本上离线完成整首曲子的创作。这种 on-device 能力对于隐私敏感的应用场景和需要低延迟响应的实时创作场景具有重要价值。
在商业授权方面,Stable Audio 3.0 的一个差异化特点是完全使用授权数据训练,这规避了其他开源音乐模型普遍存在的版权风险 。在当前 AI 版权争议频发的背景下,这一选择为商业应用提供了更安全的法律基础。模型输出的所有权归属于使用者,在 Stability AI Community License 下可以自由分发和商业化 。
Stability AI 还首次发布了 LoRa 训练的官方文档,这延续了图像生成领域 LoRa 微调的生态,表明音频生成也正在走向定制化微调的技术路线 。对于企业用户,Enterprise 许可证还提供 white-glove support 的微调服务,这开辟了从开源模型到企业级解决方案的商业路径 。
实践启示¶
-
开源音频模型的时代已经到来:对于需要音乐生成、SFX 或语音合成能力的应用,Stable Audio 3.0 提供了可本地部署的替代方案。特别是 3.0 Small 的 on-device 能力,使得在移动应用或嵌入式设备中集成音频生成成为可能 。
-
利用完全授权数据构建差异化竞争优势:在版权风险日益重要的 AI 时代,选择使用授权数据训练的模型可以规避潜在的法律纠纷。Stability AI 与 Universal Music Group 和 Warner Music Group 的合作 表明,合规的授权路径是可以商业化的。
-
关注可变长度生成能力的应用场景:支持 6 分钟以上的高质量音频生成为完整音乐创作、有声读物、长篇语音内容等场景打开了新的产品可能性,特别是对长形式内容有需求的应用开发者 。
-
LoRa 微调是定制化音频生成的关键:Stability AI 首次发布官方 LoRa 训练文档意味着社区可以更系统地对模型进行微调以适应特定风格或领域,类似于过去一年 LoRa 在图像生成领域的普及,音频领域的定制化微调生态正在形成 。
-
Audio inpainting 实现增量编辑:Stable Audio 3.0 支持单段落编辑、多段落编辑和因果延续 ,这意味着用户可以在不重做整段音频的情况下修改特定部分,大幅提升了工作流效率,对音乐后期制作和声音设计尤其有价值。
Ch17.030 高德 ABot-Earth 0.5:全球首个 3D 原生城市世界模型(1% 成本 + 千倍提效)¶
📊 Level ⭐⭐⭐⭐ | 12.1KB |
entities/amap-abot-earth-0.5-3d-native-world-model.md
摘要¶
高德(阿里)发布全球首个 3D 原生城市世界模型 ABot-Earth 0.5:单图/文本/3D 输入,消费级 GPU 10 分钟生成具备真实地理与几何一致性的 3D 城市,成本为传统方案 1%、提效 1000 倍。已覆盖 190+ 国家。
不是渐进改进,是3D 城市生成范式的彻底改写 —— 从"采集拟合"(无人机航拍 + 上百台服务器 + 数天 + 数百万元)到"3D 原生"(单图 + 消费级 GPU + 10 分钟 + 1% 成本)。
传统范式 vs 3D 原生¶
- 输入:传统=无人机航拍数万张照片;ABot-Earth 0.5=单图/文本/3D 模型
- 算力:传统=上百台高性能服务器;ABot-Earth 0.5=消费级 GPU(单卡)
- 时间:传统=数小时到数天;ABot-Earth 0.5=10 分钟
- 成本:传统=数百万;ABot-Earth 0.5=1%
- 输出格式:传统=点云/Mesh + 贴图;ABot-Earth 0.5=原生 3DGS
- 引擎兼容:传统=需格式转换;ABot-Earth 0.5=直接导入 Unity/Unreal
- 覆盖范围:传统=局部;ABot-Earth 0.5=公里级无缝连续
为什么只有高德做得出来?¶
20 年真实空间数据护城河:空间智能模型所需的真实 3D 数据严重不足;合成数据(游戏引擎生成的虚拟数据)只能造出"塑料感乐高城市"。高德沉淀了其他纯科技公司难以企及的庞大真实空间数据。
训练不是学"如何画一栋楼",而是学"真实世界中楼如何与街道、树木、光影共存" —— 根本保证地理一致性和几何一致性。
工程四重突破¶
挑战一:3D 表示差异(Representation Gap) - 现有生成器为 Mesh 设计,但户外场景充满"复杂非流形拓扑"(树木/水体),用 Mesh 像用保鲜膜包树 - 3DGS(数百万无序高斯基元)能完美还原细节,但太庞大/无序,AI 咬不动 - 首创 3DGS 压缩-生成框架:编码到紧凑隐空间 → AI 在其中推理生成 → 解压成高质量场景
挑战二:多尺度交互渲染(Scale & Interactivity) - 地球级场景需要从上帝视角宏观城市 → 1 秒俯冲到微观街道细节的连续 LOD 漫游 - 设计原生多层次细节(LOD)解码器:将 LOD 直接集成到生成过程,无需后处理
挑战三:大范围空间连续性(Spatial Coherence) - 公里级场景会撑爆显存 → 必须分块(tiles)→ 必然出现接缝 - 提出"基于滑窗的无缝推理策略":相邻地块在重叠区域智能融合算法处理
挑战四:条件鲁棒性(Conditional Robustness) - 全球卫星影像质量参差不齐(清晰度/颜色/倾角/云层) - 卫星图与航拍图存在"域差异"(大气颜色偏差) - 独创跨域自适应条件注入策略: - 训练时:刻意模拟卫星视角渲染航拍数据,让模型提前适应"模糊感" - 推理时:引入视觉语言模型(VLM)作为适配器,动态调整/校准真实卫星影像特性
三大产业落地场景¶
1. 具身智能:底层世界模拟器 - 传统仿真:要么"太假"学不到真实物理反馈,要么高保真成本极高(数月/百万/场景单一) - ABot-Earth 0.5:几分钟生成物理精确 3D 城市,真实台阶高度/路面坑洼/树木遮挡/光影反射精准还原 - 指数级训练场景:输入不同文本/图像,瞬间生成"下雨积水的十字路口"、"满是杂物的狭窄巷道"等无数复杂合成数据 - 角色:从制图工具 → 具身智能时代不可或缺的底层世界模拟器
2. 低空经济:天空之城的隐形轨道 - 无人机物流/eVTOL 万亿级战略赛道需要厘米级 3D 全域地图 - 解决"城市是生长的"难题:昨天没有的塔吊今天就是致命障碍 → 高频/实时更新
3. 智慧政务 + 应急响应:与时间赛跑 - 黄金 72 小时:普通无人机飞一圈传回影像 → 指挥中心用单张显卡 → 10 分钟生成 1:1 三维全景 - 精准测算泥石流土方量/寻找安全直升机降落点/规划不被二次滑坡波及的生命通道 - 违建排查/老旧小区改造:一键模拟新建高楼对周边小区的日照遮挡
战略意义¶
从"记录物理世界"到"生成物理世界": - 过去:高德告诉你"世界长什么样" - 未来:高德为 AI 和千行百业"按需生成这个世界"
AI 进化的关键跃迁: - 大模型让机器学会"说话" - ABot-Earth 0.5 让机器学会"睁眼看世界"并在"脑海中构建世界" - AI 进化正式从二维数字空间跨入三维物理世界
高德 ABot 体系¶
- ABot:全栈具身技术体系
- 首款机器人:高德途途
- 核心能力:3DGS 压缩-生成 + 原生 LOD + 滑窗无缝推理 + VLM 跨域适配
- 官网:abot-earth.amap.com
- 技术报告:https://github.com/amap-cvlab/ABot-Earth-0.5/blob/main/tech-report.pdf
深度分析¶
1. "3D 原生"的核心突破是表示学习范式转移,而非渐进优化
传统 3D 重建是"采集-拟合"管道:无人机拍摄 → SfM/MVS → Mesh/点云 → 人工精修。ABot-Earth 0.5 的本质是 learned generative prior:从单张图像直接生成 3DGS 场景。这不是改善,是用 generative model 替代了传统 photogrammetry pipeline。判别式 vs 生成式的边界在这里模糊了。
2. 3DGS 压缩-生成框架解决了 AI 与 3D 表示的结构性矛盾
现有生成器为 Mesh 设计,但户外场景充满非流形拓扑(树木、水体、植被),Mesh 表达力不足。3DGS 数百万无序高斯基元能完美还原几何细节,但对 AI 来说太庞大无序、无法推理。高德的解决思路(编码到隐空间 → AI 推理生成 → 解码)是典型的 representational compression + learned generation 组合,在 NeRF 时代已有先例,但高德首次将其工程化到城市级规模。
3. VLM 适配器揭示了跨域条件注入的新范式
卫星图与航拍图存在大气颜色偏差、分辨率差异、视角畸变等域差异。传统方案是数据归一化预处理;高德的方法是在推理时引入 VLM 作为动态适配器,根据输入图像特性动态调整生成条件。这是 condition-on-condition 的条件生成范式,与 ControlNet 等 ControlAI 思路正交但互补。
4. 数据护城河是壁垒,但也是 AGI 路线之争的隐喻
高德能做成是因为 20 年真实空间数据沉淀。这与 LLM 训练中"真实数据 vs 合成数据"的争论完全对应:合成数据产生"塑料感乐高城市",只有真实数据能教会模型"楼如何与街道、树木、光影共存"。这意味着物理世界的垂直领域数据可能是比通用文本更稀缺的资源。
5. 从"记录世界"到"生成世界"的战略跃迁
高德过去是导航工具(告诉你世界长什么样),未来是世界模拟器(为 AI 按需生成世界)。这与 OpenAI 从"回答问题"到"生成内容"的转变一脉相承。区别在于高德生成的是 3D 物理空间,而不仅是 2D 数字内容。这是空间智能(spatial intelligence)作为 AGI 缺失维度的有力证据。
与现有实体的关系¶
- 与 SaaS-Bench 互补:SaaS-Bench 评测 Agent 在真实系统中工作能力;ABot-Earth 0.5 生成 Agent 训练所需的 3D 世界
- 与 Agent 六机制 呼应:六机制中"环境仿真"的具体实现 —— 指数级训练场景
- 与 Anthropic 生物学 Agent 数据基础设施 平行:都揭示"非合成数据是真实世界 AI 的必要条件" —— 真实时空数据 / 真实生物数据 vs 合成数据
→ 原文存档
实践启示¶
- 评估 3D 生成方案时优先看数据来源:合成数据生成的"塑料感乐高城市"无法用于具身智能训练;真实空间数据的质量和覆盖度是核心壁垒
- 用 ABot-Earth 0.5 做 embodied AI 仿真时关注物理真实性:传统仿真"太假"的原因不是渲染质量,而是缺乏真实物理交互反馈;高德的 3DGS prior 在几何一致性上有优势
- 低空经济从业者应关注实时更新能力:城市是生长的(每天都有新建筑新障碍),ABot-Earth 0.5 的"按需生成"能力使其成为唯一能跟上现实变化的 3D 地图方案
- 应急响应场景优先考虑边际成本:传统测绘数小时/百万级,ABot-Earth 0.5 的 10 分钟/1% 成本意味着常规演练也可以用上 3D 仿真,而非仅在真正灾难时才想起
- 关注 VLM 适配器在跨域生成中的角色:卫星图/航拍图/地面图的跨域适应是 3D 生成的关键瓶颈,VLM 作为动态适配器的思路值得在其他跨模态生成任务中借鉴