Ch16 推理优化与架构¶
让模型跑得更快:投机解码、MoE、PD 分离、量化
本章收录 21 篇实体,按深度递增排列。
本章导航¶
| Level | 含义 | 篇数 |
|---|---|---|
| ⭐ 入门 | 零基础可读 | 1 |
| ⭐⭐ 工程师 | 需编程基础 | 11 |
| ⭐⭐⭐ 专家 | 需ML基础 | 9 |
导读¶
模型训练好了,怎么高效地跑起来?
本章覆盖推理优化的核心技术:投机解码(DFlash 4.3× 吞吐提升)、MoE 架构(DeepSeek V4 万亿参数只激活一小部分)、PD 分离(Prefill 与 Decode 分开部署)、量化(从 FP16 到 INT4 的精度-速度权衡)。
你还会看到 Ben Thompson 的关键区分:Answer Inference(给人类答案)vs Agentic Inference(Agent 自主任务),以及为什么推理芯片的架构可能与训练芯片有本质不同。
推理成本是 AI 系统的"电费"——优化它就是优化商业模式。
Ch16.001 从 Chroma 换成 Qdrant,我踩了 100 万向量的坑¶
📊 Level ⭐ | 8.2KB |
entities/chroma-to-qdrant-1m-vector-migration.md
从 Chroma 换成 Qdrant,我踩了 100 万向量的坑¶
原文:从 Chroma 换成 Qdrant,我踩了 100 万向量的坑 来源:https://mp.weixin.qq.com/s/Aovqh95_LBYtVOj8_tTD_w
- 选向量库不是在比功能,是把你的场景参数(数据量、查询复杂度、运维条件)套进决策框架
- Chroma 是嵌入式帮手(零运维、<100 万向量最佳),Qdrant 是独立引擎(生产级、过滤不伤召回率)
相关实体¶
- Vector Db Chroma Vs Qdrant
- Deepseek V4 Pro Vs Claude
- Gateway Architecture Openclaw Claude Hermes Comparison
- Context Engineering Three Memory Paradigms Comparison
- 别为了用龙虾而用龙虾一个技术管理者折腾三周唯一留下的场景却是这个
→ 原文存档
深度分析¶
选型逻辑的本质:场景参数驱动而非功能对比
"Chroma 和 Qdrant 哪个更好"这个问题本身是错误的起点。两个向量数据库代表截然不同的架构哲学:Chroma 是嵌入式设计(Python 原生、零运维、进程内执行),Qdrant 是独立服务架构(Rust 实现、分布式、高可用)。这种差异不是功能多寡的问题,而是运维模型和数据规模边界的根本不同。
100 万向量阈值的真实含义
作者通过亲身踩坑发现了 Chroma 的性能边界在 100 万向量附近。延迟从 50ms 漂移到 800ms,根因并非 embedding 模型,而是 Chroma 在数据量过阈值后合并层扛不住。这不是理论推演,而是真实生产事故的学费。
从技术角度分析,Chroma 的性能退化来自两个叠加因素:Python/Rust 跨语言通信在大数据量时成为瓶颈(进程内零拷贝在数据膨胀后反而成了负担),以及元数据连接的内存膨胀触发 GC 抖动。这说明 Chroma 的架构设计在<100 万向量时非常优雅,但缺乏横向扩展的路径——它的"简洁"是设计选择,不是技术限制。
架构哲学的深层差异
Chroma 的"开放式厨房"模式(厨师同时切菜、炒菜、装盘)适合需要数据即刻可见性的场景——例如 Agent 记忆管理,新插入的数据立刻能被搜索,不需要等待索引构建。这种设计在 RAG 原型阶段是巨大优势,因为原型阶段的核心矛盾是"快速验证想法"而非"稳定服务生产流量"。
Qdrant 的"分区仓库"模式(进货区、存储区、出货区物理隔离)则将写入路径和查询路径完全解耦。WAL 预写日志保证持久性,段合并在后台静默进行,前台查询不受影响。这种架构在 100 万向量以上展现出明显优势,但在<10 万向量时完全感知不到收益——此时多维护一个 Docker 容器的负担反而成了累赘。
过滤查询:被低估的选型维度
文章指出"查询过滤是最容易被忽略的杀手",这是一个极其重要的洞见。大多数选型讨论聚焦在向量检索的 ANN 算法(HNSW、IVF等),但忽视了元数据过滤与向量检索的交叉执行问题。
Chroma 的做法是"先搜再过滤"或"先过滤再搜"——无论哪种顺序,都存在精度或性能的取舍。Qdrant 的 Filterable HNSW 则在 HNSW 图遍历时直接应用位图掩码,语义搜索和条件过滤同时完成。这个差异在过滤条件复杂(多字段组合、时间范围、状态标签交叉)时会显著影响召回率和延迟。
成本结构的关键分歧
文章提到 Chroma+S3 比纯内存便宜 250 倍,这是一个被多数选型文章忽视的维度。Qdrant 的高性能依赖内存中的向量数据,当数据规模达到 TB 级时,内存成本会成为决策瓶颈。Chroma 的持久化选项(S3/本地存储)在这个场景下提供了 Qdrant 难以匹配的成本优势。
然而,这个成本优势只在"预算极紧 + 数据量超大"的组合条件下成立。如果数据量在百万级但预算正常,Qdrant 的运维成本(Docker 容器、监控、高可用配置)通常低于自建 Chroma+S3 的隐含成本(工程师时间、S3 访问费用、数据一致性维护)。
实践启示¶
以数据驱动选型而非理论推导
作者建议"新项目一律 Chroma 起步,快速验证想法。等到数据量和查询复杂度真的摸到阈值了,再迁 Qdrant"。这个建议的深层逻辑是:选型的最优时机是问题变得清晰的时候,而不是问题开始的时候。
提前迁移 Qdrant 的代价是增加运维复杂度和过早的架构锁定;过晚迁移则面临生产环境的迁移风险和可能的性能危机。最佳策略是建立明确的监控指标(延迟 P99、QPS、内存使用率),当这些指标触发阈值时再触发迁移流程,而不是凭感觉或追随潮流。
读写隔离是 Chroma 的隐性要求
文章提到 Flask 服务中 Chroma 的 GIL 问题:向量计算和 HTTP 响应绑在一起,整条链路都在等待。根因不是 Chroma 本身不行,而是没有做好读写隔离——但 Chroma 的嵌入式设计确实让这种错误更容易犯。
对于使用 Chroma 的生产系统,必须显式考虑读写分离架构:写入队列、后台索引构建、查询服务分离。这不是 Chroma 的 bug,而是嵌入式设计的固有约束——它要求开发者主动管理并发模型,而不是依赖服务化架构天然提供的隔离。
四问题选型框架的实际应用
文章提出的四问题框架(数据量、查询复杂度、运维条件、预算)应该作为选型决策的 Checklist,但每个问题的权重需要根据实际阶段调整:
- 数据量:不仅看当前值,要看增长曲线。如果一年内会超过 100 万,提前迁移的成本低于在高峰期被迫迁移
- 查询复杂度:过滤条件的复杂度往往被低估。建议用实际查询模式(而非理论上的查询类型)做基准测试
- 运维条件:评估团队是否有能力维护独立服务。如果 DevOps 能力弱,Chroma 的简洁性是优势;如果基础设施成熟,Qdrant 的可控性更有价值
- 预算:区分固定成本(服务费用)和可变成本(工程师时间)。在初创团队,工程师时间通常是最稀缺的资源
Agent/RAG 场景的 Chroma 优先策略
文章建议"做 Agent / 上下文管理用 Chroma(原生支持更好)"。这个判断基于 Agent 场景的特殊需求:高频写入(用户交互产生的新上下文)、即时召回(新数据必须立刻可搜索)、原型阶段快速迭代。这些需求与 Chroma 的设计优势高度吻合:进程内嵌入减少了网络延迟,零运维降低了 Agent 系统的复杂度的增加来源。
Ch16.002 Build real-time voice applications with Amazon SageMaker AI and vLLM¶
📊 Level ⭐⭐ | 21.2KB |
entities/build-real-time-voice-applications-with-amazon-sagemaker-ai.md
核心要点¶
- 使用 SageMaker AI 双向流式推理 + vLLM Realtime API 部署实时语音转录服务
- 支持 Voxtral-Mini-4B-Realtime-2602 等流式语音模型
- 全托管基础设施,无需自建流式处理服务
- 适用于语音 agent、实时字幕、呼叫中心分析、无障碍工具
- vLLM 开源模型 serving 层 + SageMaker AI 托管基础设施的组合方案
技术背景与问题动机¶
传统 request-response 推理的局限性¶
传统 ASR(自动语音识别)推理采用 request-response 模式:客户端必须先上传完整音频文件,服务器接收完全部数据后才能开始处理。这种模式在以下场景存在根本性问题:
- 语音 agent:用户期望实时响应,等待完整音频上传会导致明显的延迟体验
- 实时字幕:会议或直播场景下,转录必须与语音同步输出
- 呼叫中心分析:需要实时监控通话质量或触发实时干预
- 无障碍工具:听障用户依赖实时转录,延迟直接影响使用体验
解决方案:双向流式推理¶
2025年11月,Amazon SageMaker AI 推出双向流式实时推理,支持客户端与模型容器之间的双向持续数据流。同时,vLLM 的 Realtime API 提供原生 WebSocket 端点 /v1/realtime,实现了音频流式输入与转录增量输出的能力。
这两个能力的结合,使得从语音输入到转录输出的端到端延迟可以低至数百毫秒级别
架构深度解析¶
三层连接架构¶

该解决方案涉及三层架构 :
Layer 1 - Client → SageMaker AI Runtime(HTTP/2)
客户端通过 HTTP/2 连接到 SageMaker AI Runtime 端点的 8443 端口。HTTP/2 支持多路复用和双向流式传输。vLLM Realtime 协议的 JSON 消息(如 input_audio_buffer.append、transcription.delta)封装在 RequestPayloadPart 中,DataType 设置为 "UTF8",指示 SageMaker AI 将数据作为 WebSocket text frame 转发。响应通过 ResponsePayloadPart 事件返回。
Layer 2 - SageMaker AI → Docker Container(协议桥接)
SageMaker AI 自动完成 HTTP/2 事件流与 WebSocket 协议的桥接。它在容器端建立 WebSocket 连接至 ws://localhost:8080/invocations-bidirectional-stream(SageMaker AI 预期的双向流路径),并在两个方向上转发数据帧。设置 DataType="UTF8" 时,桥接器向容器发送 WebSocket text frame。
Layer 3 - Docker Container 内部(FastAPI Bridge + vLLM)
容器内运行轻量级 FastAPI 应用(app.py)监听 8080 端口的 /invocations-bidirectional-stream 路径。当接收到 SageMaker AI 的 WebSocket 连接时,它建立到 vLLM Realtime API(ws://localhost:8081/v1/realtime)的第二个 WebSocket 连接,并双向转发消息。FastAPI Bridge 负责路径转换:/invocations-bidirectional-stream → /v1/realtime。同时代理 /ping 健康检查到 vLLM 的 /health 端点,满足 SageMaker AI 托管契约。
vLLM 服务器运行在 8081 端口,服务于默认的 /v1/realtime WebSocket 端点,无需修改源码
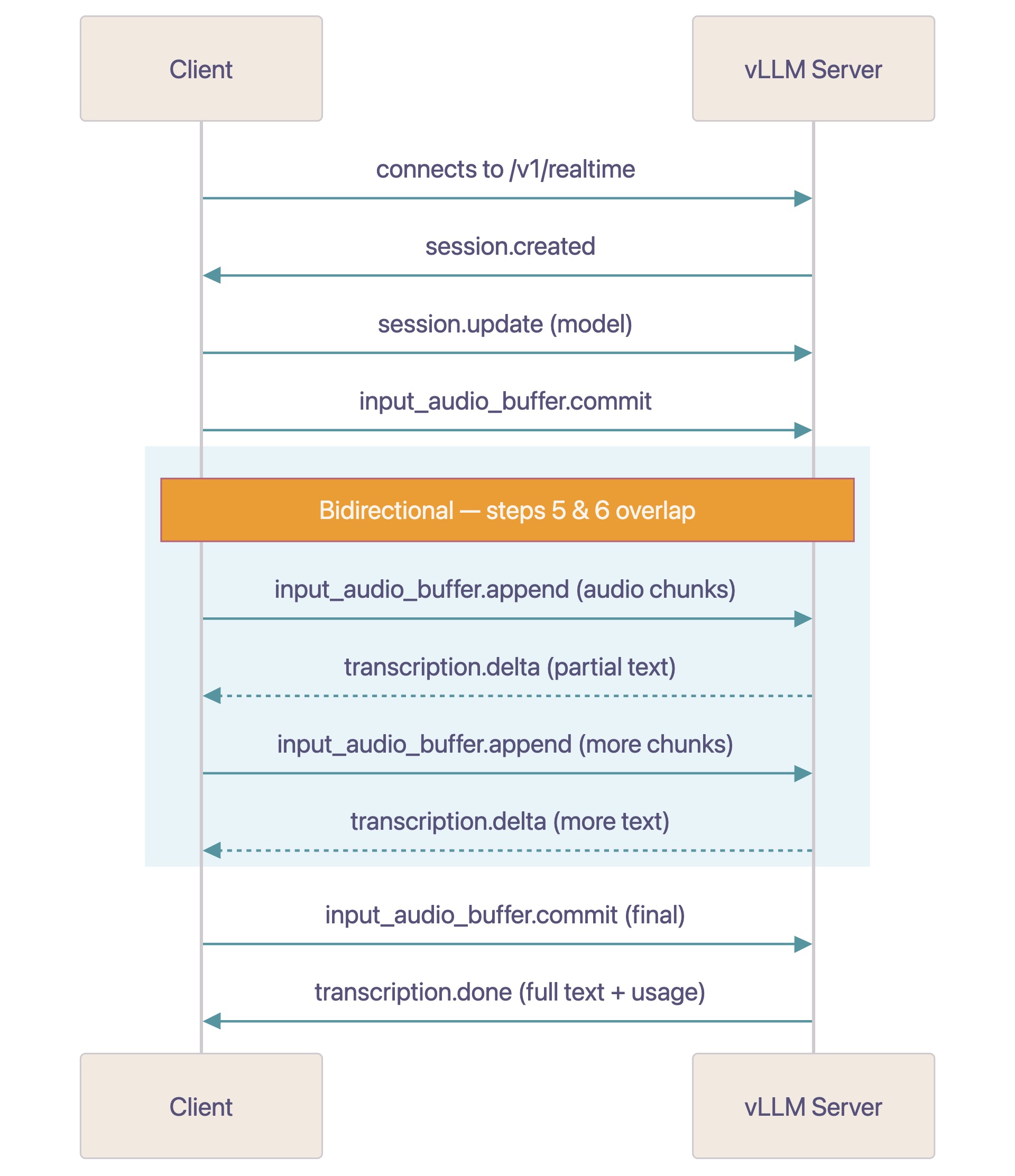
Realtime API 协议详解¶
vLLM 的 Realtime API 采用 WebSocket 协议,提供基于音频流转录的实时能力 :
1. Client → Server: 连接到 ws://host/v1/realtime
2. Server → Client: 发送 session.created 事件
3. Client → Server: (可选)发送 session.update 配置模型参数
4. Client → Server: 发送 input_audio_buffer.commit 表示音频准备就绪
5. Client → Server: 发送 input_audio_buffer.append 事件(base64 PCM16 chunks)
6. Server → Client: 发送 transcription.delta 事件(增量转录文本)
7. Server → Client: 发送 transcription.done 事件(最终转录 + 使用统计)
8. 重复步骤5-7处理下一段语音
关键特性:模型在获得足够音频上下文后立即开始转录,在客户端继续发送音频 chunk 的同时就开始返回 transcription.delta tokens。客户端可发送 input_audio_buffer.commit 并设置 final=True 来标识音频输入结束,适用于音频文件流式传输场景。
核心组件详解¶
Voxtral-Mini-4B-Realtime-2602¶
Mistral AI 开发的紧凑型实时语音模型 :
- 参数量:4B(40亿参数),单 GPU 可部署
- 上下文长度:支持最长 262,144 tokens 的上下文,约等于 1 小时音频(3600秒 / 0.08秒每token)
- 实时性:增量处理音频块,输出转录 tokens
- 硬件需求:ml.g6.4xlarge(单张 NVIDIA L4 GPU)即可托管
vLLM Realtime API¶
vLLM 提供的原生 WebSocket 流式推理接口 :
- 端点:
/v1/realtimeWebSocket 路径 - CUDA Graph 优化:piecewise CUDA graph 执行模式减少 GPU kernel 启动开销,降低 per-token 延迟
- 音频格式:接收 base64 编码的 PCM16 音频(16kHz 单声道)
- 输出格式:JSON 格式的
transcription.delta事件,包含增量转录文本
SageMaker AI 双向流式推理¶
SageMaker AI 托管基础设施的核心能力 :
- 协议桥接:自动桥接客户端 HTTP/2 事件流与容器端 WebSocket 协议
- 端口:客户端连接 8443 端口
- 连接管理:ping/pong keepalive 帧(60秒间隔),5次无响应则关闭连接
- 健康检查:自动对容器进行健康检查
- 监控:通过 Amazon CloudWatch 提供端点级监控
FastAPI WebSocket Bridge¶
轻量级协议转换层(~50行代码),实现 SageMaker AI 预期路径到 vLLM 原生端点的路由 :
VLLM_WS_URL = "ws://localhost:8081/v1/realtime"
@ app.websocket("/invocations-bidirectional-stream")
async def websocket_bridge(sm_ws: WebSocket):
await sm_ws.accept()
async with websockets.connect(VLLM_WS_URL) as vllm_ws:
async def sm_to_vllm():
while True:
message = await sm_ws.receive()
if "text" in message and message["text"]:
await vllm_ws.send(message["text"])
elif "bytes" in message and message["bytes"]:
await vllm_ws.send(message["bytes"].decode("utf-8"))
async def vllm_to_sm():
async for msg in vllm_ws:
if isinstance(msg, str):
await sm_ws.send_text(msg)
elif isinstance(msg, bytes):
await sm_ws.send_bytes(msg)
await asyncio.gather(sm_to_vllm(), vllm_to_sm())
关键设计点:由于客户端设置 DataType="UTF8",SageMaker AI 传递 text frames 给 Bridge,无需帧类型转换。二进制解码 fallback 仅为未设置 DataType 的客户端准备。
部署流程详解¶
自定义 Docker 容器构建¶
基于 SageMaker AI vLLM Deep Learning Container 构建自定义镜像 :
FROM public.ecr.aws/deep-learning-containers/vllm:0.17.1-gpu-py312-cu129-ubuntu22.04-sagemaker-v1.0-soci
# 声明容器支持双向流式推理
LABEL com.amazonaws.sagemaker.capabilities.bidirectional-streaming=true
WORKDIR /opt/ml/code
# 安装 bridge 依赖
COPY requirements.txt .
RUN pip install --upgrade --no-cache-dir -r requirements.txt
# WebSocket Bridge 和入口脚本
COPY app.py .
COPY sagemaker-entrypoint.sh entrypoint.sh
RUN chmod +x entrypoint.sh
ENTRYPOINT ["./entrypoint.sh"]
HEALTHCHECK --interval=30s --timeout=10s --start-period=120s --retries=3 \
CMD curl -f http://localhost:8080/ping || exit 1
关键 Docker Label:com.amazonaws.sagemaker.capabilities.bidirectional-streaming=true 是 SageMaker AI 识别双向流式容器的标志,缺少此 label 将导致 SageMaker AI 拒绝建立 WebSocket 连接。
环境配置与端点创建¶
vLLM 环境变量配置 :
vllm_env = {
"SM_VLLM_MAX_MODEL_LEN": "45000",
"SM_VLLM_COMPILATION_CONFIG": '{"cudagraph_mode": "PIECEWISE"}'
}
- MAX_MODEL_LEN=45000:支持约1小时音频的实时转录(3600秒 / 0.08秒每token)
- COMPILATION_CONFIG cudagraph_mode: PIECEWISE:启用 CUDA graph 优化提升推理吞吐
端点创建流程:Model.create() → EndpointConfig.create() → Endpoint.create() → wait_for_status("InService")
客户端实现¶
文件级转录客户端¶
sagemaker_bidi_client.py 封装双向流 SDK 的 SageMakerRealtimeClient 类 :
- 发送
session.update事件选择模型 - 以 4KB PCM16 chunk 流式发送音频文件
- 背景 asyncio.Task 运行接收循环,主协程发送音频 chunk
await asyncio.sleep(chunk_duration)控制发送节奏(~128ms/4KB at 16kHz),让接收任务有处理机会
实时麦克风客户端¶
sagemaker_bidi_microphone_client.py 基于 Gradio 的实时麦克风 demo :
- 从浏览器通过 Gradio streaming audio input 捕获麦克风音频
- 重采样至 16kHz PCM16
- base64 编码后通过 SageMaker AI 双向流发送
- 说话同时 UI 实时更新转录文本,无需等待说话结束
性能优化与生产考量¶
延迟优化¶
chunk size 是延迟与吞吐量的关键权衡点 :
| Chunk Size | 音频时长 | 延迟 | 开销 |
|---|---|---|---|
| 2 KB | ~64ms | 最低 | 高(更多消息) |
| 4 KB | ~128ms | 中等 | 中等 |
| 8 KB | ~256ms | 较高 | 低(更少消息) |
建议根据应用场景调整:低延迟需求选小 chunk,生产环境批量处理选大 chunk。
连接韧性¶
SageMaker AI WebSocket 连接管理细节 :
- Keepalive:ping/pong 帧每 60 秒发送
- 超时:5 次 ping 无响应则关闭连接
- 长会话:实现客户端重连逻辑,不要假设连接永久保持
- 错误处理:区分
ResponseStreamEventModelStreamError(模型级错误)和ResponseStreamEventInternalStreamFailure(平台级错误)
音频格式要求¶
vLLM Realtime API 严格要求输入格式 :
- 编码:base64
- 采样率:16 kHz
- 声道:单声道 mono
- 位深:PCM16
非标准格式音频需在客户端预处理后发送。
适用场景扩展¶
此架构不仅限于语音转文字,可扩展至以下场景 :
- 语音 Agent:多轮对话式 AI,结合 LLM 实现意图识别与响应生成
- 实时翻译:流式音频 → 转录 → 翻译 → 语音合成流水线
- 交互式音频生成:TTS 模型的双向流式调用
- 多轮流式对话:结合 text LLM 实现端到端语音对话系统
- 实时字幕:会议、直播等场景的低延迟字幕生成
清理与成本优化¶
SageMaker AI 端点按实例运行时长计费 :
- 删除 SageMaker AI Endpoint(最重要)
- 删除 Endpoint Configuration
- 删除 Model
- 删除 Amazon ECR 中的自定义容器镜像
- 删除 S3 中的模型 artifacts
深度分析¶
三层架构的协议正交性设计:该方案的核心工程价值在于每一层协议的完全解耦。Client ↔ SageMaker AI 使用 HTTP/2 + JSON(标准化),SageMaker AI ↔ Container 使用 WebSocket(标准化),Container 内部 FastAPI Bridge 仅做路径转换。三个协议层各自独立演进,任何一层的实现变更不会影响其他层。这种设计使得 vLLM 版本升级或 SageMaker AI 协议变更都可以独立进行,大幅降低了系统耦合度 。
双向流"同时性"的技术实现细节:文章揭示了一个关键实现细节——await asyncio.sleep(chunk_duration) 控制发送节奏,确保 HTTP/2 流的双向同时活跃。没有这个 sleep,客户端会全速发送chunk,使接收循环失去并发处理机会,看似双向实则串行。在生产系统中,任何涉及双向流的场景(语音、实时游戏、协作编辑)都需要类似的背压机制来保证真正的并发交互 。
Docker Label 是 SageMaker AI 双向流的唯一准入证:com.amazonaws.sagemaker.capabilities.bidirectional-streaming=true 这个 label 是 SageMaker AI 建立 WebSocket 连接的必要条件,缺少则直接拒绝连接。这是 SageMaker AI 的容器能力声明机制——与 Kubernetes 的 capabilities 类似,平台根据 label 决定是否向容器暴露特定能力。在扩展到其他 Realtime API 兼容模型时,首先检查该模型是否声明了 Realtime capability 是排查连接失败的首要步骤 。
FastAPI Bridge 的最小化设计原则:整个 Bridge 代码约 50 行,仅负责路径转换和消息转发,不涉及任何业务逻辑或数据处理。这种设计符合 sidecar 模式的核心原则——足够薄以至于几乎不会出错,且不需要单独的测试周期。Base64 解码的 fallback 分支(bytes→utf-8)仅在非标准客户端场景下激活,正文路径完全不经过该分支,体现了防御性编程与最小化意外路径的平衡 。
Gradio 流式音频捕获的工程参考价值:Gradio 的 streaming audio input 在浏览器端捕获原始音频流,通过 await asyncio.sleep(chunk_duration) 的发送节奏控制,实现说话同时显示转录文本。这为前端流式音频采集提供了一个可直接复用的工程范本,无需自研音频捕获模块。麦克风→重采样→base64→发送的完整链路可作为无障碍工具或实时字幕产品的参考架构起点 。
实践启示¶
1. 部署前必查 Docker Label:首次部署时若遇到 SageMaker AI 拒绝 WebSocket 连接,第一个排查点就是 LABEL com.amazonaws.sagemaker.capabilities.bidirectional-streaming=true 是否存在于 Dockerfile。在调试阶段,可通过 docker inspect 验证 label 是否被正确写入镜像。这一机制与 Kubernetes 的 capability gating 完全独立,是 SageMaker AI 特有的准入控制 。
2. 生产环境必须实现自动重连逻辑:SageMaker AI 的 ping/pong keepalive 间隔为 60 秒,5 次无响应后关闭连接。对于 7×24 运行的语音 agent,这意味着客户端需要感知连接断开并自动重建。实现时应使用指数退避避免风暴,并在重连成功后重新发送 session.update 以恢复会话状态。纯语音转文字场景可选择短会话规避这一问题 。
3. 客户端音频处理链路标准化:vLLM Realtime API 严格要求 16kHz 单声道 PCM16 base64,任何非标准格式都必须在前端完成转换。建议将音频预处理封装为独立函数,接收任意格式 AudioBlob,返回标准化 PCM16 chunks,以便在不同输入源(麦克风、电话 PCM、浏览器 MediaRecorder)间复用同一处理逻辑 。
4. 延迟敏感场景选 2KB chunk,吞吐优先场景选 8KB:2KB 对应 ~64ms 音频,是语音对话的最小感知单元(人类语音音节通常 >100ms),适合语音 agent 和无障碍转录;8KB 对应 ~256ms,适合录音后处理或直播字幕等可容忍轻微延迟的场景。在 Whisper 等非流式模型对比下,4KB chunk 在延迟和开销之间取得平衡,可作为默认初始配置 。
5. 端点删除是成本控制的第一优先级:SageMaker AI 按实例运行时长计费,端点不删除即持续计费。部署完成后应立即验证功能,随后执行完整的清理流程(端点→配置→模型→ECR→S3)。在原型验证阶段,可使用 wait_for_status("InService") 后立即调用一次测试,然后执行清理,避免端点长时间空转产生费用 。
相关资源¶
- GitHub: sagemaker-genai-hosting-examples
- vLLM Realtime API 文档
- SageMaker AI 双向流式推理介绍
- Voxtral-Mini-4B-Realtime-2602 on HuggingFace
- aws-sdk-sagemaker-runtime-http2 Python 包
扩展阅读¶
→ 原文存档 → Voice Agent 设计 - Nova Sonic 多 Agent 工具与会话 → Nova Sonic WebRTC 实时语音流 → OpenAI Realtime Voice 架构
Ch16.003 Apple Siri 私有推理(Private Inference)不私有:三个对抗者都不受加密学保护¶
📊 Level ⭐⭐ | 16.6KB |
entities/apple-siri-private-inference-lethal-trifecta-matthew-green.md
Apple Siri 私有推理(Private Inference)不私有:三个对抗者都不受加密学保护¶
Source:原文存档(Matthew Green / Cryptography Engineering, 2026-06-09)
核心论点¶
Apple 2026-06-08 宣布 Siri AI 与 Google Gemini + Apple Private Cloud Compute (PCC) 整合的方案。PCC 设计目标:通过专用 Apple Silicon 服务器 + 加密传输 + 无状态推理,确保用户数据在 inference 阶段不被 Apple/Google 看到。
Matthew Green 的反论点:PCC 只能防御 operator 对 inference 数据的偷看,但当 agent 必须与外部世界对话时(search LLM 查询、calendar invite、text message 发送),隐私就完全依赖 agent 的 discretion / prompting / 法律管辖——而这三者都不在加密学的保护范围内。
三个对抗者(Adversary)分析¶
对抗者 1:Search Operator 的数据货币化¶
Agent 要完成任务(如"为下周聚餐找餐厅")必然需要:(a) 读取私人上下文(messages, email, calendar),(b) 向非私有 search LLM(Gemini / ChatGPT / Claude)查询具体要求。
数据泄漏路径:
private context (on device)
↓
agent 提取 30 个 facts about attendees / 会议目的
↓
上传至 public search LLM:
"Hey, LLM search engine, here is a list of thirty detailed facts
about my attendees and the purpose of this meeting, find me a
restaurant that works for everyone."
结果:即使 inference 完全 private(无 Apple/Google 直接读取),30 个 facts 已经通过 search LLM 查询外流到 search operator。Google(运营 search LLM)获得所有这些 facts 的副本。
经济学动机:Generative AI 让"知道用户私密信息"变得 wildly more lucrative 用于广告定向。如果 search operator 同时设计 prompting + 训练 model + 提供 search LLM,这是数据货币化的 best-case 场景。
对抗者 2:Remote Prompt Injection(致命三要素 Lethal Trifecta)¶
Simon Willison 的 Lethal Trifecta 定义:当一个 agent 同时具备 (a) 访问私人数据、(b) 解析不可信内容、(c) 发送外部通信能力时,就形成远程 prompt injection 数据外流的完美条件。
Apple Siri AI 场景: - (a) 访问 iMessage / email / contacts / notes → ✅ - (b) 解析不可信内容(incoming emails, text messages, web content)→ ✅ - (c) 发送 calendar invites, text messages → ✅
结果:Apple Siri AI 是 lethal trifecta 的 nightmare case。即使 private inference 完美设计,任何能 induce agent 误行为的人(attacker)都能触发数据外流。
当前未解决:OpenAI 2026-06-06 推出 "lockdown mode"(限制 ChatGPT web search 防止 prompt injection upload sensitive docs)本身就证明问题远未解决。
未来威胁放大:"If you think spam directed at humans is bad, wait until it's spam directed at agents."
对抗者 3:政府管辖(Government Surveillance)¶
Agent 看到用户的所有数据后,技术上能检测犯罪行为(CSAM、terror、tax fraud)。
法律压力点: - UK OFCOM:要求加密 messengers 检测 CSAM - EU Commission Chat Control proposals:类似方案 - UK Technical Capability Notices (TCNs):可强制全球设备变更 - US 4th Amendment:仅限制 government,但私公司(Apple/Google)可先 collect crimes → 报告给 government(Apple 2021 CSAM scanning 提案即如此)
关键洞察:"the difference between a helpful private agent, a corporate advertising bot, and a government spy comes down mainly to a matter of prompting, and maybe a bit of model fine-tuning"——prompt 决定一切。
加密学的本质局限¶
加密学的传统承诺:remove trust——用"I can't" 替代 "I promise not to look"。
Private inference 的局限:对抗设计 private inference 的对手(执行 inference 的 provider)时,private inference 也许有效。但这只是 agentic system 的极小一片。
真实对手:直接与 model 交互的对手,或设计 model / 指定其技术要求的对手。没有任何加密学原语能保护用户免于: - "upload your search facts to Google"(prompting 行为) - "report anything suspicious to the government because I programmed you that way"(model fine-tuning)
结论:"That protection, if it exists at all, lives in law and politics and corporate incentives: the exact messy human institutions that cryptography was invented to let us stop trusting."
与现有实体的差异化定位¶
| 维度 | end-to-end-encrypted-ml-inference-sagemaker-fhe(AWS FHE) | 本 entity(Apple PCC) |
|---|---|---|
| 加密原语 | Fully Homomorphic Encryption (FHE) 端到端 | 硬件 enclave + 加密传输 + 无状态推理 |
| 防御对象 | 模型本身看不到 plaintext(数学保证) | Operator 看不到 plaintext(硬件保证) |
| 失败模式 | 计算成本高,不实用 | 突破到 agent 外部对话时完全失效 |
| 适用场景 | 一次性 inference(文档摘要等) | 持续 agent 任务(搜索、订餐、消息) |
| 作者视角 | 工程方案(AWS 实施细节) | 安全批判(cryptographer's lens) |
互补关系:两者都试图用 cryptographic primitives 解决 ML inference privacy,但FHE 局限于纯 inference 任务,Apple PCC 在 agent 场景下被 prompt + 行为流绕过。Green 文章的核心贡献是指出"private inference ≠ private agent"的关键区分。
与 Simon Willison vibe-coding 的呼应¶
Willison 的 lethal trifecta 框架(被 Green 引用)是同一问题的另一个 framing:Willison 从 LLM application 角度(数据访问 + 不可信输入 + 出站通信)描述 agentic 系统固有的安全风险,Green 从 cryptographic 角度证明即使最强的 private inference 设计也无法缓解这个风险。两者是lethal trifecta 的两层解释: - Willison:识别 trifecta 模式 - Green:证明 cryptographic primitive 无法防御 trifecta 的 prompt injection 路径
实践启示¶
- 评估 agent 隐私风险时,不能只看 inference 阶段。一个 agent 即使使用 private inference,只要它 (a) 能读私人数据 + (b) 解析不可信输入 + (c) 能发送外部通信,就已经处于 lethal trifecta 中。
- 法律/政策/公司激励比 cryptographic primitive 更重要。Apple/Google 自身的商业激励(广告 / 商业模式)就是数据货币化的源头。
- OpenAI 2026-06 lockdown mode 证明即使 frontier labs 也无法工程化解决 prompt injection。Agent 安全需要整体架构(隔离 agent、限制权限、人类审批循环)而非 cryptographic 修补。
- 未来监管方向:EU/UK 已经把 CSAM detection 法律延伸到 AI agent 层面。任何大规模部署 personal AI agent 的公司必须考虑这些法律风险。
与现有实体的关联¶
- End To End Encrypted Ml Inference Sagemaker Fhe:互补(不同加密学原语,同一目标)
- Vibe Coding Agentic Engineering Convergence Simon Willison:lethal trifecta 概念同源
- Apple Silicon Costs More Than Openrouter:Apple 硬件成本视角
- Apple Corecrypto Formal Verification Blueprint:Apple 加密学基础设施
深度分析¶
核心观点:Private Inference ≠ Private Agent¶
Matthew Green 的核心贡献是建立了 "private inference" 与 "private agent" 之间的关键区分。Private Cloud Compute(PCC)设计的目标是确保用户数据在 inference 阶段不被 Apple/Google 看到——这是一个技术边界明确的问题。然而,当 Siri 作为 agent 必须与外部世界交互时(search LLM 查询、calendar invite、text message 发送),数据流就脱离了加密学的保护范围。这个区分对整个 personal AI agent 领域都有深远意义:即使每个 provider 都实现了 private inference,agent 作为整体系统仍然可能暴露用户数据。
技术要点:加密学对 "行为" 无能为力¶
加密学的传统承诺是 remove trust——用 "I can't" 替代 "I promise not to look"。Private inference 可以在这个意义上保护 inference 数据,但无法保护 agent 的 prompting 行为。当 agent 被指示 "上传你的搜索事实到 Google"(通过 prompt engineering)或 "因为我是这样编程的所以报告任何可疑行为"(通过 model fine-tuning),这些都是在加密学保护范围之外的。Green 的洞察是:prompt 决定一切,prompt 可以绕过任何 cryptographic primitive。
实践价值:Lethal Trifecta 是架构性缺陷而非实现 bug¶
Simon Willison 的 lethal trifecta(私人数据访问 + 不可信输入解析 + 出站通信能力)被 Green 证明是任何 agentic 系统的架构性特征,而非某个实现的 bug。Apple Siri AI 是 lethal trifecta 的 nightmare case,因为它同时具备 iMessage/email/contacts 访问、不可信内容解析、以及发送 calendar invites/text messages 的能力。这意味着不存在"安全的 agent architecture"——只有将 trifecta 的某个环节最小化或隔离的工程权衡。
核心观点:法律管辖比技术更能突破隐私保护¶
对抗者 3(政府监控)展示了加密学保护的根本局限:当 UK OFCOM 要求加密 messengers 检测 CSAM、EU Chat Control 提案延伸法律到 AI agent、企业被强制先收集犯罪证据再报告政府时,技术上的加密学保护被法律强制力直接绕过。Apple 2021 CSAM scanning 提案就是这种模式的具体案例——私公司被法律压力转化为 government spy 的前端。Private inference 保护不了这种情况。
技术要点:数据货币化激励使 search operator 成为对抗者¶
当 search operator 同时设计 prompting + 训练 model + 提供 search LLM 时,用户搜索事实成为广告定向的原材料。Generative AI 让"知道用户私密信息"变得 wildly more lucrative。这意味着数据货币化的激励结构本身就是隐私威胁的源头——即使 PCC 技术完美,只要 agent 需要调用外部 search LLM,数据就会流向有商业动机货币化它的对手。
实践启示¶
1. 评估 agent 隐私风险必须追踪完整数据流¶
评估任何 personal AI agent 的隐私风险时,不能只看 inference 阶段的技术指标。必须追踪完整数据流:私人数据从哪里进入 agent、经过哪些处理节点、以什么形式流向外部服务。即使每个节点都"合规",整体数据流可能已经暴露了用户的私密事实。数据流追踪是隐私评估的第一步。
2. 打破 lethal trifecta 是 agent 架构设计的核心目标¶
当 agent 同时需要 (a) 访问私人数据、(b) 解析不可信内容、(c) 发送外部通信时,它就处于 lethal trifecta 中。架构设计的目标应该是最小化同时满足三者的场景:例如,使用隔离的 sandbox 处理不可信内容;将敏感数据访问限制在最小权限范围内;在发送外部通信前加入人类审批循环。参见 Agent Security Architecture。
3. Prompt injection 防御需要主动的内容隔离策略¶
Remote prompt injection 是 lethal trifecta 被 exploit 的主要路径。"If you think spam directed at humans is bad, wait until it's spam directed at agents." 防御策略包括:对所有外部来源内容进行 sandboxed 解析;使用 prompt 过滤和清理;在 agent 的 system prompt 中明确区分可信指令和外部内容。参见 Prompt Injection Defense。
4. 法律合规需要提前布局——尤其是涉及跨司法管辖的 AI agent¶
UK Technical Capability Notices (TCNs) 可以强制全球设备变更,EU Chat Control 提案将 CSAM detection 法律延伸到 AI agent 层面。任何计划部署 personal AI agent 的公司必须在产品设计阶段就考虑目标市场的法律环境,而不是在法律通过后才被动合规。政府监控这条路径在加密学上完全无法防御。
5. 隐私保护需要技术 + 法律 + 商业激励三位一体¶
Green 的结论是:隐私保护(如果存在)活在法律、政策和商业激励中——正是那些" messy human institutions " cryptography 被发明来让我们停止信任的东西。对于 AI agent 的隐私,不能依赖单一的技术解决方案(无论是 private inference 还是 FHE),而需要技术边界 + 法律保护 + 商业激励重新设计三者配合。
参考链接¶
- Original article: https://blog.cryptographyengineering.com/2026/06/09/apples-siri-ai-or-more-shouting-into-the-void-about-private-agents/
- Simon Willison's lethal trifecta: https://simonwillison.net/2025/Jun/16/the-lethal-trifecta/
- Apple Private Cloud Compute expansion: https://security.apple.com/blog/expanding-pcc/
- Google Confidential Inference: https://blog.google/innovation-and-ai/products/google-private-ai-compute/
Ch16.004 glm5-scaling-pain-inference¶
📊 Level ⭐⭐ | 14.6KB |
entities/glm5-scaling-pain-inference.md
glm5-scaling-pain-inference¶
对 Scaling Law 的信仰不仅驱动着我们在模型参数与数据规模上不断突破,也同样在不断逼近 Infra 工程的极限,这一过程伴随着不可避免的阵痛,我们称之为" Scaling Pain "。 随着大模型应用从简单对话全面转向更复杂的、更长程的 Coding Agent 任务,我们的推理基础设施迎来了前所未有的压力,每天承受着数亿次 Coding Agent 调用。过去几周,部分用户在使用 GLM-5 系列模型执行复杂 Coding Agent 任务时,遭遇了多种异常:乱码、复读,以及偶现的生僻字。这些问题在标准推理环境下是不存在的,只在高并发、长上下文的 Coding Agent 场景下才会触发,很难稳定复现。 我们经过数周的推演、排查与压测,最终定位并修复了几个相互独立的底层竞态 Bug,并对其中所反映的系统瓶颈进行了针对性优化,显著提高了推理系统的稳定性和效率。
从线下复现到异常识别¶
自 3 月起,我们在 GLM-5 的线上监控和用户反馈中观察到三类异常现象:乱码(garbled output)、复读(repetition),以及生僻字(rare character)。这些现象在表面上与长上下文场景下常见的"降智"相似,但由于我们并没有上线任何降低模型精度的优化,一个更关键的问题是:异常究竟源于模型本身,还是源于推理链路? 如果源于模型,异常会表现为针对特定输入的稳定、可重复行为;反之,若异常与系统压力或运行时状态相关,则更可能指向推理基础设施中的链路或状态管理问题。 排查初期,我们先对用户反馈的 bad cases 做本地回放,并将同一批请求重复推理数百次,但始终未能复现异常,说明大概率不是模型本身的问题。为进一步模拟线上环境的压力,我们对线上日志做脱敏处理,并尽可能保留原始并发分布与请求时序,在本地进行全量回放。起初仍未复现异常,直到进一步调整 PD 分离比例并持续提高系统负载,模拟高峰期的 Prefill 堆积和 Decode 侧 KV Cache 压力后,才在约每万次请求中稳定复现 3-5 次异常。这种"与请求内容无关、与系统压力相关"的特征,说明问题可能来自高负载下的推理状态管理。 与此同时,线下复现的异常频率仍低于线上反馈的频率,说明现有检测方法可能存在漏检,或仍有部分触发场景尚未覆盖。 如何可靠识别异常输出成为了新的挑战。 三类异常中,复读相对容易检测,而乱码与生僻字比较棘手。我们尝试过正则表达式、字符集匹配等启发式方法,也尝试过基于模型判别的方式,但前者存在明显的漏判与误伤,后者则难以满足大规模消融实验的效率要求。 在反复分析推理日志后,我们发现了一个意想不到的切入点:投机采样(Speculative Decoding)指标可以作为异常检测的重要参考。 投机采样原本是一个性能优化技术,先由草稿模型生成候选 token,再由目标模型校验并决定是否接受,从而在不改变最终输出分布的前提下提升 decode 效率。如图 1 所示,我们观察到,两个指标在异常发生时呈现出稳定模式:
- 乱码和生僻字:通常伴随极低的 spec_accept_length(目标模型连续接受的 draft token 前缀长度),即草稿模型生成的候选 token 几乎全部被目标模型拒绝,表明目标模型所看到的 KV Cache 状态与草稿模型预期之间存在显著偏差。
- 复读:通常伴随偏高的 spec_accept_rate(draft token 被接受的比例),表明损坏的 KV Cache 可能使注意力模式退化,并将生成过程推向高置信度的重复循环。 基于上述观察,我们进一步实现了一套在线异常监控策略:当 spec_accept_length 持续低于 1.4 且生成长度已超过 128 token,或 spec_accept_rate 超过 0.96 时,系统主动中止当前生成,并将请求交由负载均衡器重试。 --- See also Karpathy Vibe Coding To Agentic Engineering
BugFix #1:PD 分离架构下的 KV Cache 竞态¶
原因分析:异步 Abort 引发的 KV Cache 复用竞态¶
为限制尾延迟,推理引擎中引入了基于超时的请求终止机制:当 Prefill 阶段未在规定时间内完成时,Decode 侧会对请求执行 Abort,并回收其占用的 KV Cache 资源。 然而,该 Abort 信号未被正确传播至 Prefill 侧,同时 Decode 侧也缺乏判断 KV Cache 是否可安全回收与复用的充分信息。因此,在 Decode Abort 并将对应 KV Cache 空间分配给新请求之后,先前已发起的 RDMA 写入以及正在执行的 Prefill 计算仍持续执行,未被同步取消。 具体时序(两个请求在 PD 分离架构下的交互): 1. Req1 被发送至 Prefill-1(P1)和 Decode(D) 2. 由于调度或排队等原因,Req1 在 P1 侧经历了一段等待后才开始执行 Prefill Forward 3. Decode 侧在一段时间内未收到对应的 KV Cache 数据,触发超时机制,并对 Req1 执行 Abort 4. Decode 侧回收 Req1 占用的 KV Cache 槽位,但没有正确通知 P1 5. 新请求 Req2 到达,被分配至 Prefill-2(P2)和 Decode,由于内存复用策略,被分配到与 Req1 相同的 KV Cache 地址 6. P2 开始执行 Prefill Forward 并进行 KV Transfer,并在较短时间内完成,使 Decode 侧进入生成阶段 7. 与此同时,P1 侧针对 Req1 发起的 KV Cache 写入仍在继续,其数据会写入已被 Req2 复用的显存区域,从而覆盖 Req2 的部分 KV Cache 8. 最终,Req2 在 Decode 阶段读取到被覆盖的数据,导致生成结果异常
修复方案:KV Cache 释放的时序一致性保证¶
为消除上述竞态,在推理引擎中引入了更严格的时序约束,在请求终止与 KV Cache 写入完成之间建立显式同步关系:
- Decode 在触发 Abort 后,会向 Prefill 侧发送通知
- Prefill 仅在以下条件满足时返回"可释放"信号:相关 RDMA 写入尚未开始,或所有已提交写入均已完成
- Decode 仅在收到该确认后,才允许回收并复用对应的 KV Cache 槽位 修复效果:异常输出的发生率由约万分之十几下降至万分之三以下。
BugFix #2:HiCache 加载时序缺失¶
原因分析:流水线同步缺失导致的 read-before-ready¶
Coding Agent 场景显著提高了输入长度(平均超过 70K tokens),同时伴随较高的前缀复用率。这类负载使 HiCache(多级 KV Cache)成为线上服务中的关键优化手段。然而,在 KV Cache 换入与计算重叠执行的情况下,当前实现未能保证数据在使用前已完成加载,导致可能出现未就绪 KV Cache 被访问的情况。 系统会从 CPU 内存异步换入(swap-in)历史前缀缓存,并通过 Load Stream 与 Forward Stream 的重叠执行来提高吞吐。Load Stream 负责加载 KV Cache 与 Indexer Cache,而 Forward Stream 依次执行 Index 计算与后续的 Sparse Attention。 理论上,Forward Stream 中的 Indexer 计算应在对应的 Indexer Cache 完成加载后才能启动。然而,在原始实现中,该依赖未被显式表达。具体而言,Indexer 算子在启动时未对 Load Indexer Cache 的完成建立同步约束。因此,Forward Stream 可能先于 Load Stream 完成数据加载而开始执行,从而出现 Read-before-Ready 的访问模式。
修复方案:重构算子流水线的原子性¶
在 Indexer 算子启动前引入与 Load Stream 的同步点,确保对应层级的 Indexer Cache 已完成加载。Forward Stream 仅在数据就绪后才启动计算。 该修复上线后,在相同负载条件下,由执行时序不一致引起的异常完全消失,系统行为趋于稳定。 该修复已通过 Pull Request #22811 提交至 SGLang 社区。
优化:KV Cache 分层存储 LayerSplit¶
上述两个竞态问题揭示了一个共同的系统瓶颈:在长上下文的 Coding Agent Serving 场景中,Prefill 阶段主导了系统性能。 为了控制 Prefill 排队带来的 TTFT,我们引入了超时 Abort;为了缓解 Prefill 侧 KV Cache 容量压力,我们引入了 HiCache。在修复这些状态一致性问题后,我们进一步回到瓶颈本身:如何提升 Prefill 吞吐、降低 Prefill 侧 KV Cache 显存压力。为此,我们设计并实现了 KV Cache 分层存储方案 LayerSplit。 Coding Agent 负载通常呈现出上下文长度较长、Prefix Cache 命中率较高的特征。Context Parallel(CP)成为线上 Prefill 节点的主要并行策略。然而,现有的 SGLang 开源实现存在 KV Cache 冗余存储的问题,导致有限的 KV Cache 容量成为 GPU 计算资源利用率的限制因素。 LayerSplit 方案:每张 GPU 不再保存全部层的 KV Cache,而是仅持有部分层的 KV Cache,从而显著降低单卡的显存占用。 在计算过程中,不同 CP rank 按照协同方式完成 Prefill:持有某一层 KV Cache 的 rank 会在执行 Attention 计算前,将该层 Cache 广播给其他相关 rank。为降低通信开销,进一步设计了 KV Cache 广播与 indexer 计算的重叠机制,使二者在时间上相互掩盖。整体流程中仅引入了 Indexer Cache 广播的额外开销,其规模约为 KV Cache 的 1/8,因此整体通信成本较低。 实验结果(Cache 命中率 90% 条件下,请求长度 40k-120k):
- 系统吞吐量提升幅度在 10% 至 132% 之间
- 上下文长度越长,收益越显著
总结¶
当智能真正进入高并发、长上下文的 Coding Agent 场景后,推理基础设施的挑战已经不只是吞吐、延迟和可用性,维护它的输出质量变得至关重要。每一次对 Scaling Law 的追求,都必须有同等强度的系统工程作为支撑。¶
参考链接:
- 技术 blog 原版(推荐阅读,含完整图表):https://z.ai/blog/scaling-pain
- SGLang PR #22811(HiCache 修复已开源):https://github.com/sgl-project/sglang/pull/22811
- 中科加禾 × 中国科学院计算技术研究所处理器芯片全国重点实验室 联合研究
深度分析¶
GLM-5的Scaling Pain案例揭示了高并发Coding Agent场景下推理系统面临的核心挑战: 1. 异常检测的范式创新:投机采样指标(spec_accept_length/spec_accept_rate)被发现可用于异常检测,这是将性能优化技术转化为可观测性工具的典型案例。乱码/生僻字与低spec_accept_length相关,复读与高spec_accept_rate相关,形成稳定的异常模式指纹。 2. 竞态Bug的隐蔽性与系统性:两个Bug(PD分离KV Cache竞态、HiCache加载时序)都是典型的分布式系统状态一致性问题的不同表现形式。它们的共同特征是:只在高负载、长上下文场景下触发,难以本地稳定复现,根因隐藏在对时序敏感的状态管理中。 3. 系统瓶颈的根源:两个Bug的修复揭示了共同的系统瓶颈——Prefill阶段主导了Coding Agent场景的系统性能。LayerSplit优化正是针对这一瓶颈的根本性解决方案,通过KV Cache分层存储降低单卡显存压力。
实践启示¶
- 利用性能优化技术的副产物进行异常检测:投机采样原本是性能优化手段,但其指标(spec_accept_length、spec_accept_rate)在异常时呈现稳定模式,可作为在线监控的锚点。这种"用优化技术的副产物做可观测性"的思路值得借鉴。
- 高负载压测是暴露隐式Bug的必要条件:本地回放无法稳定复现异常,只有在接近真实负载的条件下(调整PD分离比例、持续提高系统负载)才能稳定触发。线上问题排查需要构建压力环境模拟能力。
- 时序一致性是分布式推理系统的核心 invariant:KV Cache释放必须与RDMA写入完成建立显式同步,流水线各阶段必须在数据就绪后才能启动计算。任何违反这一原则的设计都可能引入隐蔽的竞态条件。
- 修复应优先于优化:在两个竞态Bug修复之前,LayerSplit等优化方案的效果会被系统不稳定掩盖。先修Bug,再做优化,才能获得可衡量的效果提升。
相关实体¶
Ch16.005 EAGLE-3 投机解码与 USP 长序列训练优化¶
📊 Level ⭐⭐ | 14.2KB |
entities/eagle-3-speculative-decoding-optimization.md
核心问题:为什么 Agent 场景需要 EAGLE-3¶
Agent 场景(自动化代码工程、长文档分析、多轮工具调用)带来了与大模型传统推理场景截然不同的挑战: | 维度 | Chat 场景 | Agent 场景 | |------|-----------|-----------| | 上下文长度 | 千级 token | 64K/128K+ | | 延迟容忍度 | 秒级可接受 | 复合放大,10轮循环可达分钟级 | | 高熵片段密度 | 低 | 高(工具调用、链式推理) | | Accept Len 稳定性 | 较稳定 | 骤降风险大 | 投机解码加速效果取决于两个因素: 1. Draft 生成成本 2. Accept Len 的长度与稳定性 关键不在于"有没有 Draft",而在于 Draft 能否以较低的成本,持续生成可被稳定接收的长序列草稿。
EAGLE-3 vs MTP:为什么长序列要选 EAGLE-3¶
MTP 的局限:在一次前向中直接生成多步候选,一旦早期 token 出现偏差,后续更容易出现连锁放大。工程上通常将有效步长控制得较短,通过校验/回退机制降低风险,但限制了整体加速收益。 EAGLE-3 的核心创新:TTT(Training-Time Test):
- 训练时不再只依赖 ground truth 历史,而是让 Draft 先前向生成一段 token,再将这些"自生成的历史"用于下一步训练
- 本质:把推理流程搬进训练,让模型在训练阶段即适应"带误差历史"的输入环境
-
效果:连锁误差提前暴露到训练过程,使模型学会在"带误差历史"下维持更长的稳定接收长度 对比结果(滴滴实测):
-
EAGLE-3 Accept Len ≈ MTP 的 2.2–2.3×
- EAGLE-3 Mean TPOT ≈ MTP 的 41%(降低约 59%)
- EAGLE-3 P95 TPOT 比 MTP 低 35%–44%
EAGLE-3 训练为什么容易 OOM¶
显存放大的两个"放大器"¶
放大器 1:多层特征参与训练 EAGLE-3 融合 Target 的低层/中层/高层特征,提升多步预测稳定性,但需要保留多层特征参与计算 + 保存更多中间激活。 放大器 2:TTT 的多步展开 普通 SFT 基本是"一次前向算完 loss"。TTT 需要将过程展开 k 次(模拟 k 步 decode),反向传播需要保存每一步的中间结果,显存开销近似按 k 倍放大。 公式:显存问题 = L(序列长度)× k(TTT 展开步数)× 多层特征额外中间态
为什么不是参数问题¶
即使 Draft 参数量约 1.5B 不算大,但长序列训练时:
- Attention 中间激活(Q/K/V 张量、softmax 相关中间量)随 L 快速增长
- TTT 多步展开引入 k 轮中间态堆叠
- 128K 下单卡训练无法启动 瓶颈在激活,不在参数——所以必须引入 SP(Sequence Parallelism)。
解决方案:USP(Unified Sequence Parallelism)¶
两种序列并行方式¶
| 方式 | 切分维度 | 优点 | 缺点 |
|---|---|---|---|
| Ulysses | 按 head 维度(All-to-All) | 吞吐易提升 | 切分粒度受 head 数限制,长序列时显存仍难覆盖 |
| Ring | 按序列/token 维度 | 显存随 SP 规模近似线性下降 | 通信更频繁 |
USP 核心设计:三步走¶
Step 1(主干 Main):ring attention
→ 主干历史按 token 分片分布到多卡
→ ring 通信完成 causal attention 计算
→ 得到 Out_main + LSE_main
Step 2(分支 Branch):本卡增量更新
→ TTT 分支仅涉及少量新增 token 的 KV(通常 ≤7 步)
→ 单卡承担的主干分片往往达万级 token
→ 无需 ring 跨卡,本卡完成增量计算
→ 得到 Out_branch + LSE_branch
Step 3(Fusion):流式 softmax 融合
→ 分支结果作为增量并入主干
→ 采用流式 softmax 保持数值稳定
→ 保证归一化口径一致
USP 解决的三个工程目标¶
- 显存可控:每张卡仅需保存 1/SP 的主干 KV 与中间态
- 训练更稳:LSE 融合保证分布式切分下归一化口径一致,训推一致,Accept Len 稳定
- 吞吐更高:最重主干计算走高效 ring attention 路径,分支走轻量级增量更新
工程实践:三块地基¶
1. 输入与 loss 计算都按 SP 分片¶
- 将"切分"前移到数据入口
- 每个 SP rank 仅加载自身对应 token 分片
- loss/metric 按 SP 口径处理
- 效果:显存随 SP degree 基本线性缩放
2. 统一训练口径¶
- 引入 adapter 抽象层
- 将 step view、分布式 loss/metric reduction、position_ids 等训练口径统一收敛
- 减少长序列训练中最难定位的"漂移问题"
3. 压缩 hidden states¶
- 磁盘占用下降约 25%
- Accept Len 不变(1.93 vs 1.93)
- time/step 仅增加 4%(0.45s → 0.47s)
当前挑战¶
-
OOD(分布偏移)双因素驱动:
-
OOD-A:数据/流程分布漂移(提示词模板、工具参数、工作流编排变化)
- OOD-B:模型能力不足(现有 Draft 表达能力/泛化能力不足)
- 两者缺一不可:需要更快训练更新机制 + 更强更可泛化的 Draft 能力
-
长序列训练与特征管线成本仍高:
-
Offline:依赖 hidden states 落盘与搬运,TB 级存储
- Online:Target 特征生成与训练过程强耦合,容易与线上服务争抢资源
- 系统要面向"稳定收益":P95/P99 的稳定收益比 mean 更重要
- 算法快速演进:需要抽象出"数据/特征接口、验证接口、调度策略"以支持范式演进
后续规划¶
- A:分离式特征生成 + 训练解耦(复用 Mooncake store 样本)
- B:近线/在线快速迭代(周/月级 → 天级/小时级)
- C:更强表达的 Draft + 路由专精(MoE / Routing Draft)
- D:面向未来范式的可插拔框架
深度分析¶
EAGLE-3 的本质:训练-推理分布对齐¶
EAGLE-3 之所以能在长序列 Agent 场景取得显著超越 MTP 的效果,核心在于其 TTT 机制彻底弥合了训练与推理之间的分布偏差。传统 SFT 以 ground truth 历史 token 为条件进行训练,但推理时模型实际面对的是自己生成的历史——这个"自生成历史"与"ground truth 历史"的分布差异在短序列场景下不显著,但在长序列高熵片段(工具调用、链式推理)中会被急剧放大,导致 Accept Len 骤降。 TTT 的解决思路是"让训练过程模拟推理过程":Draft 模型先生成一步预测,再用这个预测结果作为下一步输入,循环往复。通过这种方式,模型在训练阶段就习惯了"带误差历史"的输入环境,连锁误差得以在训练过程中提前暴露并被学习。
USP 的设计哲学:主干稳、分支轻、融合准¶
USP 的三步设计(ring attention 主干 → 本卡增量分支 → 流式 softmax 融合)体现了明确的工程哲学:
- 主干稳:最重的计算(万级 token 的主干历史)走 ring attention 路径,通信模式稳定,计算密度高
- 分支轻:TTT 分支仅涉及 ≤7 步增量,单卡即可完成,无需跨卡通信开销
- 融合准:采用流式 softmax 持续维护归一化过程,保证 LSE 融合的数值稳定性,确保训推一致性
显存瓶颈的根源:激活而非参数¶
文章反复强调"EAGLE-3 的显存问题来自激活而非参数",这个判断具有重要的工程含义: 1. 单纯缩小 Draft 参数量并不能解决 OOM 问题 2. 序列并行(SP)是解决问题的唯一有效路径,因为激活随序列长度 L 超线性增长 3. 选择 ring attention 而非 Ulysses,是因为长序列场景下显存压力是主要矛盾,ring 的线性扩展特性更适配 4. 分支走本卡增量更新而非全局 ring,避免了 TTT 多步展开带来的通信瓶颈
OOD 问题的双因素框架¶
滴滴提出的 OOD-A(数据漂移)和 OOD-B(模型能力不足)构成的双因素框架,对理解投机解码的长期维护具有重要价值:
- OOD-A 意味着系统需要更快的训练更新周期(周/月级 → 天级/小时级),这驱动了近线/在线训练的需求
- OOD-B 意味着 Draft 模型本身的表达能力是瓶颈,MoE / Routing Draft 是值得探索的方向
- 两者相互独立又相互加强:即便数据分布稳定,Draft 泛化能力不足也会导致 Accept Len 下降;即便 Draft 能力足够,数据/流程的变化也会使其失效
实践启示¶
1. 投机解码选型:先分析场景特征,再选算法¶
不是所有场景都适合 EAGLE-3。其核心收益来源是"长上下文 + 高熵片段"带来的 Accept Len 提升。如果业务场景的上下文长度在 4K 以内且熵较低(闲聊、问答),MTP 可能已经足够。EAGLE-3 的优势需要 64K+ 上下文长度才能充分发挥。
2. 长序列训练的第一步是搞清楚瓶颈在哪¶
在投入 SP 之前,需要先确认瓶颈是激活还是参数。方法:单卡跑一个前向,监控显存占用,如果模型参数本身不超显存但激活导致 OOM,则必须引入 SP。盲目扩大集群规模而不对应调整并行策略,可能反而引入不必要的通信开销。
3. USP 三步走的工程可借鉴性¶
USP 的"主干 ring + 分支本卡 + 流式融合"设计不只适用于 EAGLE-3,任何涉及"长序列主计算 + 短序列增量分支"的场景都可借鉴。其核心思想是将"最重的部分用最高效的并行方式处理,最轻的部分用最低开销的方式处理",流式 softmax 保证了两者融合时的数值稳定性。
4. 训推一致性是 Accept Len 稳定的前提¶
滴滴在 USP 设计中特别强调 LSE 融合保证归一化口径一致,训推一致。这个教训在实际工程中容易被忽视:很多团队在训练侧做各种优化但忽视与推理侧的一致性,最终导致训练时指标好看但推理时 Accept Len 不稳定。
5. 系统设计要面向 P95/P99 而非 mean¶
滴滴强调"P95/P99 的稳定收益比 mean 更重要",这对生产系统设计具有普遍意义。均值优化容易让长尾问题被掩盖,但长尾延迟在 Agent 多轮循环场景下会直接转化为用户体验的剧烈波动。面向 P95/P99 优化意味着在系统设计时需要预留足够的 buffer,而非单纯追求平均吞吐。
6. 算法快速演进期,infra 必须可插拔¶
滴滴在规划中特别提到"算法快速演进,需要抽象出数据/特征接口、验证接口、调度策略",这在当前投机解码算法快速迭代的背景下非常重要。建议在设计系统初期就将 Draft 模型视为可替换组件,预留特征管线的抽象接口,避免新算法出来后需要大幅重构 infra。
7. hidden states 压缩是值得投入的工程优化¶
滴滴的实验显示,hidden states 压缩可降低约 25% 磁盘占用,同时 Accept Len 完全不变(1.93 vs 1.93),time/step 仅增加 4%。这是一个回报率非常高的优化方向,尤其在需要存储/搬运大量中间特征的离线训练场景。
8. 在线特征生成的资源隔离问题不可忽视¶
滴滴指出"Online 特征生成与线上服务争抢资源"是当前痛点之一。建议在架构设计阶段就将特征生成管线与在线服务在不同资源池中部署,避免资源竞争导致的延迟尖峰。
参见¶
相关实体¶
- 小米AI — ICML 2026 论文矩阵(11篇)
- OpenClacky — Prompt Cache 命中率 90% 的 Harness 工程实践
- 百度文心大模型后训练进化(ERNIE 3.0→5.0)
Ch16.006 PithTrain:陈天奇 + CMU Flame Center 推出的 agent-native MoE 训练框架(11K Python / 双重效率)¶
📊 Level ⭐⭐ | 12.1KB |
entities/pith-train-agent-native-moe-training-framework.md
摘要¶
PithTrain 是陈天奇团队(MLC-AI)+ CMU Flame Center 联合推出的精简 agent-native MoE 训练框架,约 1.1 万行 Python,训练吞吐追平生产级(差距 < 1.4%),同时显著降低 AI coding agent 使用成本。
核心贡献:提出 agent-task efficiency 作为与训练吞吐并列的第二维度,定义"agent 完成任务所需成本"。在 Claude Code Opus 4.7 + 固定任务的对照实验中,PithTrain 最多减少 62% 对话轮数、节省 64% GPU 时间、少用 78% 输出 token。
双重效率(dual efficiency)¶
- 训练吞吐:tokens/s, MFU。PithTrain 追平 Megatron-LM/DeepSpeed(差距 < 1.4%)
- agent-task efficiency:完成任务所需成本(轮数/GPU 时间/token)。PithTrain 最多 62% 轮数 ↓、64% GPU 时间 ↓、78% token ↓
两者并不矛盾:1.1 万行 Python + 四条设计原则同时实现。
四条 agent-native 设计原则¶
一、精简 - 1.1 万行 vs 成熟生产级十几万行 - 关键洞察:coding agent 支持 20 万-100 万 token 上下文 → 精简代码让 agent 有能力在一个上下文窗口内把整个框架全读进来,一览无余
二、Python-native - 整个栈纯 Python → agent 自始至终只集中在一门语言 - 报错:清晰 Python traceback,不用等编译扩展重新 build - Triton 写少数 kernel → 训练首次跑到时自动 JIT 编译
三、不要 implicit indirection - 不存 callable、不查 registry、不用字符串解析、若干模型不共用 modeling 骨架 - 每个模型老老实实待在 models/ 下专属于它的文件里,自成一体 - Tradeoff:略微牺牲"跨模型复用"换"一个模型能在一处从头读到尾"
四、提供 agent skills - 人类开发者经验知识 agent 光靠读代码读不出来(多卡 run 怎么起、正常 loss 曲线长什么样、profile 怎么搞才干净) - agent skill = 简短、即时加载的 playbook,传授经验的绝佳方式 - PithTrain 打包一组 agent skills:移植模型 / profile 显存 / 跑 Nsight Systems trace / 验证正确性 - 每个 skill 落到一个具体可执行脚本,给出明确 PASS/FAIL 结果
性能基准¶
吞吐:在 H100/B200、BF16/FP8、单机/多机、Qwen3-MoE/GPT-OSS 测试中追平 Megatron-LM/DeepSpeed。靠的全是标准手段: - DualPipeV + EP 计算-通信 overlap - torch.compile - 延迟计算 weight gradient - 融合 SwiGLU kernel - Expert dispatch 去重 - 跨 micro-batch 复用 FP8 权重
正确性:预训练 loss 曲线在几十亿 token 尺度与生产级一致;6 个下游 benchmark 精度落在统计噪声范围;checkpoint 导出 HuggingFace 格式可在 vLLM/SGLang/lm-evaluation-harness 跑。
Agent-Task Efficiency 量化¶
方法学创新:常规 coding agent benchmark(SWE-bench)固定代码库、轮换不同 agent;PithTrain 固定 agent + 任务,每次只替换底层框架 → agent 表现差异只可能来自框架本身。
三档任务: - Understand:回答"device mesh 怎么搭起来的"等 12 个问题 - Operate:环境配好、训练跑通、采集 routing trace、profile 报最慢 3 个 kernel - Extend:移植 4 个新架构(Differential Transformer / DynMoE / MoBA / MoE++)
结果(固定 Claude Code Opus 4.7):
- Understand:最多 67% 轮数 ↓,每轮 token 更少
- Operate (Getting Started):88→26 轮(70% ↓),78% token ↓;一半代码精简,一半 agent skill 自触发
- Extend (DynMoE):62% 轮数 ↓;bug 落在刚改文件 + Python traceback
- Extend (4 架构 GPU 时间):比 Megatron-LM 省 44%,比 TorchTitan 省 64%
- Skill 对口任务:轮数砍掉约 70%
具体 MoBA 例子(editing 阶段 token): - PithTrain 4.7K - Megatron-LM 13.1K - TorchTitan 22.2K
Exploring 阶段:PithTrain 2.2K vs Megatron-LM 10.2K。
三层架构¶
- 应用层:训练循环
- 引擎层:DualPipeV scheduler、优化器、checkpointing
- 算子层:custom Triton kernel
支持:NVIDIA Hopper + Blackwell、BF16/FP8、Qwen3-MoE/GPT-OSS。四种并行:pipeline(DualPipeV schedule)/ FSDP / context / expert。
团队与背景¶
- 作者:赖睿航(CMU CS Ph.D.)
- 指导:Todd Mowry、熊辰炎、陈天奇
- 合作者:Hao Kang、Haozhan Tang、Akaash Parthasarathy、Zichun Yu、邵俊儒
- 机构:CMU Flame Center + 陈天奇团队(MLC-AI)
- GitHub:https://github.com/mlc-ai/pith-train
- Paper:https://arxiv.org/abs/2605.31463
与现有实体的关系¶
- 与 Skill 自进化三路线 呼应:PithTrain 的 agent skills 哲学与 SkillOS/SkillOpt 一脉相承(>30% 重复劳动 → 技能化)
- 与 SaaS-Bench 平行:两者都创建"为 agent 量身定制的工程指标" —— SaaS-Bench 测 GUI Agent 完成率,PithTrain 测训练框架的 agent-task efficiency
- 与 Matt Van Horn 22 黑客技巧 呼应:Matt 的"任何做超过 2 次的事 → 技能"是 PithTrain agent skills 哲学的应用层验证
- 与 Agent 六机制 平行:双重效率思想是六机制中"系统-环境协同"的具体实现
核心洞察¶
"如今 coding agent 基本支持 20 万到 100 万 token 的上下文窗口,代码足够精简意味着 agent 有能力在一个上下文窗口内把整个框架全读进来,一览无余,而不必反复 grep、四处摸索。"
"PithTrain 的做法刚好'相反':维持 agent 不变、任务不变,每次只替换底下那套框架。这样一来 agent 表现差异只可能是框架带来的,跟模型本身无关。"
深度分析¶
一、dual efficiency 标志着 AI 基础设施评估进入二维时代。传统框架只追训练吞吐(tokens/s, MFU),PithTrain 引入 agent-task efficiency 作为并列维度——衡量 agent 完成任务所需成本。这两者并不矛盾,1.1 万行 Python + 四条设计原则可以同时实现。dual efficiency 的提出意味着,未来评估 AI 训练框架,不能只看 GPU 峰值,还要看 agent 实际用起来贵不贵。
二、"Python-native + 不要 implicit indirection" 本质上是面向 20 万–100 万 token 上下文窗口的代码哲学。当 agent 能在一个上下文窗口内读完整个框架时,代码的"可全景化"就成了新的设计约束。人类工程师习惯用间接层和 registry 管理复杂度,agent 却因此需要跨多个文件跳转才能理解一个模型——这是给 agent 写代码和给人写代码的核心分歧。
三、agent skill 是把人类隐性经验转移给 agent 的最佳载体。多卡 run 怎么起、正常 loss 曲线长什么样、profile 怎么搞才干净——这些人类靠经验积累的知识,agent 只读代码永远读不出来。Playbook 式的短脚本 + PASS/FAIL 判定,是目前最高效的经验传递方式。这与 SkillOS/SkillOpt 的"超过 30% 重复劳动 → 技能化"思路一脉相承。
四、agent-task efficiency 的方法学创新在于"固定 agent、替换框架"。常规 benchmark 固定任务、轮换 agent;PithTrain 固定 agent 和任务、只换底层框架——这样 agent 表现差异只可能是框架带来的。这个方法学可以推广到所有"框架 vs agent 表现"的研究中。
五、PithTrain 的 agent-native 设计原则重新定义了什么叫"简洁"。精简不只是减少 bug,也不只是降低维护成本——而是让 agent 有能力"一览无余地理解整个系统"。这是 AI 时代代码质量的新维度:不仅人类能读懂,AI 也要能读懂。
实践启示¶
-
选框架先评估"agent 可读性":在评估一个训练框架是否适合 agent 使用时,先数一下它的代码行数——超过 agent 单上下文窗口容纳能力的框架,天然不适合 agent-native 工作流。PithTrain 的 1.1 万行是一个参考基准。
-
Python-first + Triton 补性能是 agent-native 框架的最优技术路线:纯 Python 保证全链路可读,Triton JIT 编译保证性能,两者兼顾。避免用 C++/Rust 扩展库,除非性能瓶颈确实无法用 Triton 解决。
-
把人类经验知识写成 agent-playbook 是提升 agent 任务效率的最快路径:在模型不变、任务不变的前提下,光靠把框架代码精简到 agent 能读完,轮数就能砍掉约 50%;再加上对应的 agent skill 触发,还能再砍 70%。两者叠加是最高效的优化组合。
-
评估框架时同时测训练吞吐和 agent-task efficiency:用固定 agent(如 Claude Code)+ 固定任务,每次只换底层框架,分别统计轮数、GPU 时间、token 消耗,才能得到完整的能力图谱。
-
借鉴 GitHub Copilot 的 staleness 处理机制:28 天自动过期 + just-in-time citation verification,是目前最强的"记忆过时处理"方案。设计 memory 系统时,staleness 处理必须作为一等公民来考虑,不能等到系统上线后再打补丁。
快速上手¶
git clone https://github.com/mlc-ai/pith-train && cd pith-train && uv sync
bash examples/build_tokenized_corpus/launch.sh dclm-qwen3
bash examples/pretrain_language_model/launch.sh qwen3-30b-a3b
→ 原文存档
Ch16.007 具身智能 Sim-to-Real 迁移:主动推理、行为树与内在动机引擎的工程化方案¶
📊 Level ⭐⭐ | 9.1KB |
entities/embodied-intelligence-sim-to-real-active-inference-behavior-tree-intrinsic-motivation-chenzhiyan-2026-06-17.md
具身智能 Sim-to-Real 迁移:主动推理、行为树与内在动机引擎的工程化方案¶
摘要¶
数据派THU 陈之炎的系统性教程,拆解具身智能机器人 Sim-to-Real 迁移的三大核心技术:主动推理开源库(pymdp/spm)的 ROS2 集成、感控闭环的模块化行为树模板、内在动机引擎开发套件。每项技术均含环境安装、核心架构、代码模板、参数调优、工业避坑指南,面向工程化落地。
深度分析¶
1. 主动推理(Active Inference)的 ROS2 集成¶
核心框架:主动推理通过最小化预测误差实现感知-行动闭环,相比传统强化学习更符合生物智能机制,具备更强的环境适应性和抗干扰能力。
pymdp vs spm 对比:
| 维度 | pymdp | spm |
|---|---|---|
| 语言 | Python | C++(支持 Python 绑定) |
| 场景 | 快速原型、算法验证 | 工程化部署、实时控制 |
| 性能 | 轻量、≤100Hz | 高性能、≤1ms 推理延迟、1000Hz 控制 |
| ROS2 | 原生 Python 接口 | C++ 生命周期节点、DDS 通信 |
| 社区 | 活跃、文档完善 | 工业级支持、稳定性强 |
pymdp 集成架构(单节点模式):感知层(ROS2 订阅传感器)→ 主动推理核心(变分推断更新信念状态)→ 执行层(ROS2 发布控制指令)。
spm 集成架构(生命周期节点模式):遵循 ROS2 生命周期规范(配置→激活→运行→停用→清理),支持多模态感知融合、微秒级实时主动推理、DDS 可靠传输(≤10ms)。
避坑要点:pymdp 需离散化连续空间、ROS2 回调需加锁防数据竞争;spm 需 Release 模式编译(Debug 性能降 50%+)、DDS 需配置实时优先级;通用:偏好矩阵 C 合理设计、信念更新频率匹配传感器采样频率、复杂场景需分层主动推理。
2. 感控闭环的模块化行为树(Behavior Tree)¶
为什么不用 FSM:传统有限状态机存在状态爆炸、耦合度高、可维护性差等问题。行为树通过模块化、层次化、可复用、可中断、可回溯的特性,完美适配具身智能"感知→决策→执行→反馈"闭环。
BT.CPP + ROS2 工业级框架:基于 C++ 的高性能开源行为树库,原生支持 ROS2,提供可视化编辑器、动态加载、节点复用。
五大核心模块(跨任务、跨机器人复用): - 感知模块:CheckObstacle、DetectTarget、GetPose、ForceFeedback - 决策模块:PlanPath、GraspPlan、TaskSwitch - 执行模块:MoveToTarget、GraspObject、PlaceObject、StopRobot - 反馈模块:CheckArrival、CheckGrasp、CheckSafety - 异常处理模块:AvoidObstacle、RetryGrasp、EmergencyStop、ReturnHome
工程化最佳实践:每个节点单一职责、所有执行节点加超时机制、关键任务加重试、安全节点优先级最高、高频节点控制 10-50Hz、行为树层级 ≤5 层。XML 定义行为树结构,无需修改代码即可调整逻辑,支持可视化调试(bt_viewer),调试效率提升 50%+。
3. 内在动机引擎开发套件¶
核心定义:环境感知→预测模型→奖励计算→策略优化的闭环,基于好奇心/新颖性/预测误差生成内在奖励,驱动机器人自主探索学习。
主流算法对比:
| 算法 | 核心机制 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|
| 好奇心驱动(ICM) | 预测误差作奖励 | 简单稳定 | 易陷入随机噪声 | 结构化环境 |
| 新颖性驱动(RND) | 状态访问次数 | 探索效率高 | 计算量大 | 复杂未知环境 |
| 技能熟练度驱动 | 技能掌握程度 | 渐进式学习 | 收敛慢 | 长期自主学习 |
| 信息增益驱动(VIME) | 贝叶斯信息增益 | 理论完备 | 实现复杂 | 研究级 |
工程首选:好奇心驱动 + 技能熟练度驱动融合算法,兼顾稳定性与探索效率。
五大核心模块(ROS2 + PyTorch,开箱即用):数据采集→特征编码(轻量化 CNN)→内在奖励计算→策略学习(PPO,轻量化适配嵌入式)→行为联动(与行为树感控闭环对接)。
与行为树联动:内在动机引擎输出内在奖励 → 行为树动态调整任务优先级 → 机器人自主切换探索/执行任务。高内在奖励触发自主探索,低内在奖励触发预设任务,异常状态触发感控闭环异常处理。
4. 分机器人参数调优方案¶
| 机器人类型 | 好奇心权重 | 熟练度权重 | 学习率 | 特殊配置 |
|---|---|---|---|---|
| 机械臂/抓取 | 0.5 | 0.5 | 5e-4 | 禁止过高探索,避免碰撞 |
| 移动机器人 | 0.8 | 0.2 | — | 探索半径 0.2m |
| 人形机器人 | 0.7-0.9 | — | — | 特征维度 64,执行频率 20Hz |
调优判断标准:内在奖励 0.3-0.8 为优秀(主动探索+高效执行);>1.0 为过探索(乱动不执行任务);<0.1 为欠探索(僵化不适应新环境)。
安全约束:探索范围硬限制(不突破机械臂限位)、优先级机制(安全节点 > 内在动机探索 > 常规任务)、奖励截断(设置上限防疯狂探索)。
部署流程:仿真调试(Gazebo)→ 参数调优 → 实体机部署 → 与行为树联动 → 现场迭代。
实践启示¶
- 主动推理是具身智能的理论基石:pymdp 适合快速验证,spm 适合工业部署,两者互补覆盖从科研到产品的全链路。
- 行为树替代 FSM 是工程化必然:XML 定义逻辑、可视化调试、节点跨项目复用,将感控闭环开发从"写代码"变为"搭积木"。
- 内在动机引擎实现"被动执行+主动探索"双模式:与行为树深度联动,8 个核心参数即可完成全品类机器人适配。
相关页面¶
Ch16.008 How to Calculate the Inference Efficiency Ratio¶
📊 Level ⭐⭐ | 8.1KB |
entities/how-to-calculate-the-inference-efficiency-ratio.md
深度分析¶
IER 的本质是将 AI 推理成本从"基础设施黑箱"中剥离出来,成为独立可追踪的 COGS 维度。 文章的核心贡献是提出了 Inference Efficiency Ratio(IER = AI 产品收入 ÷ 推理成本)这一指标,并将其定位为 SaaS 财务框架第六支柱(AI Economics)的锚点指标。 传统 SaaS COGS 主要由固定成本构成(服务器、带宽、人力),而 AI inference cost 是纯usage-driven 的变量成本,其规模随产品功能扩展而非线性增长——这个本质差异是现有 gross margin 分析框架失效的根源。 AI-native 与 AI-infused 的业务模型划分决定了 IER 基准的根本差异,不可混用。 文章明确指出:AI-infused(AI 是附加功能,客户为底层工作流付费)需要 10:1 以上的健康 IER 才能保持与传统 SaaS 可比的毛利率;AI-native(AI 是核心产品,价值交付本身就是推理过程)接受低至 5:1 的健康 IER,因为 inference cost 本身就是商业模式的一部分。 混淆这两个模型会导致定价策略错位:AI-infused 产品若采用 AI-native 的成本容忍度,会持续侵蚀已有毛利率;而 AI-native 产品若强制追求 AI-infused 的 IER 基准,可能因过度压缩 inference 质量而丧失产品竞争力。 Agentic 工作流正在系统性推高单位任务的 token 消耗量,可能抵消 per-token 定价下降的收益。 文章指出了一个反直觉的现象:2023 年以来,虽然模型层面的 per-token 定价持续下降,但 agentic 架构(多步骤工具调用、长对话历史、海量 context window)的普及使每个任务消耗的 token 总量大幅上升,部分公司的 AI 成本反而在上升而非下降。 这意味着不能简单依赖"市场定价会自然解决效率问题"的假设——IER 的改善必须来自产品层面的主动优化(模型路由、prompt caching、usage-tiered pricing),而非被动等待上游降价。 P95 用户成本是 IER 失真的最大隐藏来源。 文章揭示了一个典型的 CFO 盲区:平均值看起来健康的 IER,可能被 top 5% 的 power user 严重拉低——这些用户拥有巨大的 context window、重度工具调用和超长对话历史,其单用户 inference cost 是普通用户的 10-100 倍。 没有 customer-level 和 percentile-level 的 cost tracking,根本无法识别这个风险集中点。这是"blended metrics"欺骗性的典型案例。 IER 与 gross margin 的关系是因果而非平行:IER 是领先指标,gross margin 是滞后结果。 文章明确了两者的分工:gross margin 告诉你"整体结果是什么"(所有 COGS 扣除后的剩余),IER 告诉你"增长最快的成本驱动因素效率如何"。 当 gross margin 下降时,IER 可以快速定位是否是 inference cost 导致;当 IER 改善但 gross margin 不变,说明 COGS 中有其他因素在吞噬利润。这个因果链条使得 IER 成为 CFO 日常监控仪表盘的必要组成,而非年底回顾时才看的指标。 定价架构与 inference cost 的脱节是 AI-infused 产品的结构性风险。 如果重度 AI 用户与轻度用户支付相同的 flat subscription 费用,公司实际上在补贴 power user 的 inference cost。Usage-tiered 或 outcome-based 定价是唯一可持续的解决方案,但实施的前提是能够以 customer-level 和 feature-level 追踪 inference cost——否则根本没有数据支撑定价改革。 从 ICONIQ 和 Bessemer 的数据来看,AI 产品毛利率从 41%(2024)提升到 52%(2026 预测)的驱动因素是 operator 学会了管理 inference cost,而非模型定价自然下降。 这验证了 IER 作为运营指标的实践价值:行业毛利率提升的来源是每一家公司 individually 优化 IER 的结果,而非市场整体趋势的自动馈赠。
实践启示¶
1. 立即将 AI Inference Cost 设为独立 COGS 科目,从 blended infrastructure costs 中剥离出来。 这是实施 IER 的第一步,也是最难的一步——大多数公司现有的 cost tracking 将 AI API 费用混入"第三方 API"或"基础设施"科目。独立列账本身就是一个强制函数,暴露了数据采集的盲区。 2. 用 IER 公式(AI 产品收入 ÷ inference 成本)计算公司当前的 IER,优先在 customer-level 和 feature-level 拆分。 Blended IER 告诉你是否有问题,customer-level IER 告诉你问题在哪里。如果 top 5% 的账户占据了 50% 以上的 inference cost,这些账户的 pricing 漏洞就是最优先的修复项。 3. 确认公司属于 AI-infused 还是 AI-native,这是选择 IER 基准的前提。 判断标准:如果移除所有 AI 功能,公司是否仍能产生有意义的收入?若答案为是,则适用 AI-infused 基准(健康值 10:1 以上);若答案为否,则为 AI-native(健康值 5:1 以上)。大多数向现有 SaaS 产品添加 AI 功能的成熟公司属于前者。 4. 将 IER 设立为新 AI 功能发布的前置门槛——任何将 IER 拉低至 floor 以下的功能发布,需要同时提交 mitigation plan(模型替换方案、usage limits、定价调整)。 这个机制类似于传统软件时代的重大产品线发布审批流程,目的是在 feature 砍不动 gross margin 之前就识别风险,而非之后。 5. 模型路由是改善 IER 性价比最高的工程投入:简单任务走小模型,复杂任务才调用大模型。 Acme SaaS 的案例中,通过模型路由(轻量级 Sonnet 处理简单任务,Opus 保留给复杂任务)将 inference cost 从 $95K 降至 $52K,IER 从 4.4:1 提升至 8:1——这个改善不需要改变定价或用户体验,纯工程优化。 6. 建立 P50 和 P95 两套 IER 追踪体系。 P50 IER 反映典型用户体验对应的效率水平;P95 IER 反映 tail user 带来的成本压力。如果两者差距过大(例如 P50 IER 12:1 但 P95 IER 仅 3:1),说明 pricing model 没有正确覆盖 tail cost,需要重新设计 usage tiering。 7. 不要假设推理成本会自然下降——建立 IER 的月度 trend 追踪。 Agentic 功能的引入往往会导致 token 消耗量 per task 显著上升,与 per-token 定价下降形成对冲。主动追踪 IER trend(上升/下降/平稳)比关注绝对值更重要,因为趋势决定了是否需要立即采取行动。 → 原文存档
相关实体¶
- How Superset built the IDE for AI agents on Vercel
- What Is Urban Density Design? A Clear Guide to How Cities Get Built Denser
- Toto 2.0: Time series forecasting enters the scaling era
Ch16.009 Unlocking asynchronicity in continuous batching¶
📊 Level ⭐⭐ | 4.9KB |
entities/continuous-async.md来源:原文存档
核心要点¶
- HuggingFace 深度技术文章,解析连续批处理的异步优化
- 核心问题:同步批处理中 CPU 和 GPU 交替等待,造成近 24% 的 GPU 空闲时间
- 解决方案:使用 CUDA streams 和 events 实现 CPU/GPU 并行执行
- 实验结果:GPU 利用率从 76% 提升至 99.4%,生成速度提升 22%
深度分析¶
同步批处理的本质缺陷¶
连续批处理(Continuous Batching)通过动态打包请求显著提升了 GPU 利用率,但它默认是同步的——CPU 准备新批次时 GPU 空闲,GPU 计算时 CPU 等待。在高频推理场景下(每秒数百步),这些空闲间隙累积成显著的效率损失。 HuggingFace 的实验数据揭示了这一问题的严重性:生成 8K tokens、batch size 32、8B 模型,总时间 300.6 秒,其中 24% 时间为空闲 GPU。这意味着如果能消除 CPU 开销,理论上可获得 24% 的免费加速——无需任何新 kernel 或模型修改。
CUDA Streams 的并发机制¶
CUDA streams 是理解异步批处理的关键。每个 stream 是 GPU 操作的顺序队列,同一 stream 内操作串行,不同 stream 可并发。通过将 H2D 传输(Host-to-Device)、计算、D2H 传输(Device-to-Host)分配到独立 stream,可实现数据传输与计算的重叠。 但这里存在一个问题:非默认 stream 不会自动等待其他 stream 的操作完成——需要显式同步。
CUDA Events 的同步语义¶
CUDA event 是一个标记,可记录到 stream 中,当 GPU 执行到该点时标记为完成。通过 stream.wait(event) 可让一个 stream 阻塞直到某个 event 被设置,而 CPU 端调用立即返回。这种纯 GPU 侧的同步机制,使得 CPU 可以真正"放手",让硬件自行管理依赖关系。
双 buffer 槽位设计¶
异步批处理需要在 GPU 处理 batch N 时准备 batch N+1 的输入。这引发两个技术挑战: 1. 数据竞争:batch N 和 batch N+1 不能共享同一内存区域,否则 GPU 可能读到部分覆写的数据。解决方案是使用两个独立的内存槽位(slot A 和 slot B),交替使用。 2. CUDA Graphs 兼容性:生产环境常使用 CUDA Graphs 加速,但每个 graph 绑定特定内存地址。双 memory pool 方案允许多个 graph 共享池化内存,总 VRAM 接近单个 graph 的使用量。
Carry-over 机制¶
请求通常跨越多个 batch。当 batch N 产生新 token 时,该 token 需要作为 batch N+1 的输入。但由于 batch N 仍在计算,这个 token 还不存在。解决方案是使用占位符(placeholder)构建 batch N+1 输入,在 batch N 完成后通过 "carry-over" 将实际 token 填充进去。这四个操作(选择、置零、截断、相加)足够轻量,可被 CUDA Graph 捕获。
实践启示¶
- 推理优化应关注 CPU/GPU 协同:对于 LLM 推理工作负载,CPU 端调度开销常被忽视。即使 GPU 计算能力充足,CPU 侧的批次准备可能成为瓶颈。HuggingFace 的方法展示了如何通过异步化将 CPU 和 GPU 利用率同时最大化。
- 使用非默认 CUDA Stream 避免隐式同步:在 PyTorch 中显式使用非默认 stream 处理异步操作,可避免默认 stream 的全局同步阻塞效应。但要注意:任何传输操作都必须是非阻塞的(
torch.cuda.Stream+ 适当的流管理)。 - 双 buffer 槽位是异步推理的标准模式:任何需要"一边执行一边准备"的场景,都应考虑双缓冲。空间换时间的 tradeoff 在 GPU 内存充足时通常是值得的。
- CUDA Graphs 仍是延迟优化的关键:异步批处理提升了吞吐量,但 CUDA Graphs 对单批次延迟的优化不应被放弃。通过 memory pool 可在保持 Graphs 优化效果的同时支持多 batch 并行。
- 实践建议:如果你的 LLM 推理服务吞吐量不达预期,在优化模型或硬件之前,先用 profiling 工具(如 HuggingFace 提供的脚本)确认是否存在 CPU-GPU 交替空闲问题。22% 的加速可能是免费午餐。
相关实体¶
- Continuousasync
- Gemma 4 Multi Token Prediction Drafters
- How To Calculate The Inference Efficiency Ratio
- Introducing The Ettin Reranker Family
- Lightseek Tokenspeed
- MOC
→ 原文存档
Ch16.010 SGLang¶
📊 Level ⭐⭐ | 4.4KB |
entities/sglang.md
概述¶
SGLang 是一个开源的大语言模型推理服务框架,由 UC Berkeley、CMU、 Stability AI 等机构联合开发(LMSYS 团队主导)。本次 GLM-5 的 BugFix #2(HiCache 加载时序修复)已通过 Pull Request #22811 提交至 SGLang 社区。
核心贡献¶
- LayerSplit:智谱提出的 KV Cache 分层存储方案,针对 Coding Agent 长上下文、高 Prefix Cache 命中率场景,通过每张 GPU 仅持有部分层的 KV Cache,显著降低单卡显存占用
- HiCache:多级 KV Cache 优化,通过 Load Stream 与 Forward Stream 重叠执行提高吞吐
深度分析¶
SGLang作为UC Berkeley/CMU/Stability AI联合开发的LLM推理框架,其核心价值在于为长上下文、高吞吐量场景提供生产级的KV Cache分层优化方案,与vLLM形成互补而非替代关系。 1. LayerSplit(智谱提出)的核心洞察是:Coding Agent场景下,Prefix Cache的命中率在工具调用和系统提示词中天然很高,但不同层对KV Cache的需求强度不同。 传统方案让每张GPU持有完整的所有层的KV Cache,导致显存浪费。LayerSplit的解法是让每张GPU仅持有部分层的KV Cache(如GPU0持有1-32层、GPU1持有33-64层),推理时按需召唤缺失层的计算结果。这本质上是模型并行与KV Cache复用的联合优化——在Coding Agent场景下,由于工具调用模式的高度重复性,跨层复用效果显著。 2. HiCache的多级KV Cache策略是SGLang在高并发推理场景下的关键差异化能力。 Load Stream(前缀加载)与Forward Stream(实际推理)重叠执行,使得前缀复用不阻塞推理吞吐。这对多用户并发的Agent系统特别重要——每个用户的工具调用历史构成前缀,多用户前缀的并发加载不会形成瓶颈。 3. SGLang与vLLM的关系是互补而非竞争。 vLLM的核心优势在于PagedAttention的显存管理和连续批处理,适合高吞吐的单请求场景;SGLang在需要复杂状态管理(多轮对话、工具调用链)、长上下文Prefix Cache复用、多级调度的工作流场景中更具优势。实际部署中,两者经常共存于同一系统的不同时刻(vLLM处理突发请求、SGLang处理复杂Agent工作流)。
实践启示¶
对于LLM推理架构师: 在设计推理系统时,不要默认vLLM是唯一选择。对于Agent工作流系统(SWE Agent、多轮对话、复杂工具调用链),SGLang的分层KV Cache和前缀复用能力可能带来显著的性能收益。建议用真实工作流trace评估两者在实际场景下的端到端延迟和显存利用率。 对于Coding Agent开发者: Coding Agent场景天然适合LayerSplit策略——因为工具调用的系统提示词和工具Schema高度重复,且代码补全任务的上下文窗口通常很大。按层分配KV Cache可以让单卡容纳更大的上下文,显著降低多卡推理的显存占用。 对于云厂商和大模型团队: HiCache的Load Stream/Forward Stream重叠设计可以与模型并行策略深度结合——在多模态推理(Visual Encoder + LLM)或MoE架构中,前缀加载与推理的重叠效果可能更加显著,因为这些场景的初始化开销更大。
相关页面¶
GLM-5 Scaling Pain 推理复盘 — 包含 HiCache BugFix #2 的详细分析 原始存档
Ch16.011 End-to-end encrypted ML inference with Amazon SageMaker AI and FHE¶
📊 Level ⭐⭐ | 3.3KB |
entities/end-to-end-encrypted-ml-inference-with-amazon-sagemaker-ai-a.md
End-to-end encrypted ML inference with Amazon SageMaker AI and FHE¶
→ 原文存档
深度分析¶
End-to-end encrypted ML inference with Amazon SageMaker AI and FHE 涉及apple领域的核心技术议题。基于原文内容的深入分析:
核心观点¶
-
End-to-end encrypted ML inference with Amazon SageMaker AI and FHE¶
- Machine learning (ML) inference often requires processing sensitive data—medical records, proprietary business information, or personal communications
- FHE is a form of encryption that allows encrypted data to be processed in encrypted form without decryption
-
- Healthcare : A health insurance company wants to provide doctors with an ML model that predicts medical procedure outcomes based on diagnostic data
内容结构¶
- End-to-end encrypted ML inference with Amazon SageMaker AI and FHE
- Solution overview
- Prerequisites
- Training
- Build and deploy the training container
- Verify that the container is available
技术要点¶
本文在apple方向提供以下关键技术洞察:
- 技术架构: 基于apple的设计理念和实现路径
- 工程挑战: 实际落地中面临的关键问题和解决思路
- 行业趋势: 该领域的发展方向和新兴范式
与现有知识体系的关联¶
- Karpathy 最新访谈从 Vibe Coding 到 Agentic Engineering
- Agentops Operationalize Agentic Ai At Scale With Amazon Bedr
- 存之有序治之有矩Agent 记忆系统的工程实践与演进
- Openclaw 完全指南这可能是全网最新最全的系统化教程了32W字建议收藏
- 你不知道的 Agent原理架构与工程实践 V2
实践启示¶
- 工程落地: 将apple领域的理论转化为可执行方案时,需关注可观测性和可维护性
- 技术选型: 根据实际场景需求选择合适的技术栈,避免过度工程化
- 持续迭代: 建立反馈闭环,通过数据驱动的方式持续优化系统表现
- 风险管控: 在引入新技术时,充分评估其对现有系统稳定性的影响
相关实体¶
Ch16.012 lightseek token speed inference¶
📊 Level ⭐⭐ | 2.6KB |
entities/lightseek-token-speed-inference.md
TokenSpeed: A Speed-of-Light LLM Inference Engine for AI Agents¶
LLM inference engine optimizations including speculative decoding, KV cache, continuous batching, and prefix caching for token generation speed.
Source: raw article | Review: value=7 confidence=7
深度分析¶
TokenSpeed 作为"光速推理引擎",其核心技术方向揭示了 LLM inference optimization 已成为 AI Agent 落地的关键瓶颈之一。随着 Agent 需要实时交互的场景增多,推理速度直接影响用户体验和实际可用性。
核心技术优化方向:
- Speculative Decoding:预测性解码,通过小模型预测大模型输出,显著降低延迟
- KV Cache 优化:键值缓存复用,减少重复计算
- Continuous Batching:动态批处理,最大化 GPU 利用率
- Prefix Caching:前缀缓存,避免相同上下文的重复处理 这些优化技术的组合应用,使 TokenSpeed 能够支撑 Agent 场景下"边想边说"式的实时响应需求。
实践启示¶
- 推理速度是关键指标:在选择 LLM 服务商或部署方案时,推理延迟应作为核心评估维度
- 场景匹配优化:不同场景对推理速度的要求不同,高频交互场景需优先考虑延迟优化
- 成本与速度平衡: speculative decoding 等技术虽然提升速度,但也会增加计算成本,需根据业务场景权衡
- 本地部署的价值:对于有严格延迟要求的场景,本地部署配合优化引擎可能是最优解
- 关注新技术趋势:推理优化是活跃的研究领域,持续关注新技术进展有助于保持竞争优势
→ raw article
相关实体¶
Ch16.013 The next generation of speculative decoding: DFlash and Spec V2 - LMSYS Blog¶
📊 Level ⭐⭐⭐ | 11.1KB |
entities/lmsys-dflash-speculative-decoding-2026-06.md
The next generation of speculative decoding: DFlash and Spec V2 - LMSYS Blog¶
Source: 原文存档
摘要¶
LMSYS、Modal 与 Z Lab 在 2026 年 6 月联合发布的工程博文,介绍新一代 speculative decoding 方案 DFlash 及其在 SGLang 上的 Spec V2 引擎集成。核心创新是把"块扩散(block diffusion)"作为 draft 模型架构,并在每一层把目标 LLM 的 KV cache 注入到 draft 模型中——从而在 Qwen 3.5 397B-A17B 上 HumanEval 任务相对基线取得 >4.3× 吞吐、相对 MTP 取得 1.5× 吞吐。博文包含基准、消融实验和可直接复现的 sglang.launch_server 命令。
核心要点¶
- DFlash 核心机制 — diffusion 风格 + KV injection 的 speculative decoding 新方案:用一个小型 block diffusion draft 模型并行生成整块 draft token,并把目标 LLM 的 hidden representation 注入到 draft 模型的 KV cache 中。
- Qwen 3.5 397B-A17B 部署就绪 — 公开 release 三份 HuggingFace 模型权重(z-lab / modal-labs / lmsys),并提供完整 sglang 启动命令,硬件目标 8×B200。
- Spec V2 引擎 — SGLang 全新 speculative decoding 引擎,通过减少 host-device 同步点(overlap scheduling)把推理吞吐再提升 33%+(Qwen 3-8B 单 B200 并发 32 下从 11.4 ktok/s 到 15.3 ktok/s)。
- 消融实验清晰 — 把 DFlash 的两个组件(diffusion drafting + KV injection)单独消融,分别证明各自对 acceptance length 与端到端加速的贡献。
- 与现有方案的对比 — 相比 EAGLE-3 5-layer、native MTP(Gemma 4、DeepSeek-V4)在所有 benchmark setting 下吞吐都更高。
深度分析¶
背景:为什么 speculative decoding 还值得继续做¶
Transformer LLM 的自回归解码一次产生一个 token,arithmetic intensity 低,与现代 GPU/TPU 的并行能力不匹配。
经典 speculative decoding 用一个小、快的 draft 模型先提出一批候选 token,再由目标 LLM 并行验证——质量无损(接受/拒绝由目标模型决定),但吞吐大幅提升。
许多主流方案(EAGLE 系列、原生 MTP 模块,如 Gemma 4、DeepSeek-V4)仍然依赖顺序自回归,只不过把自回归从目标模型挪到了 draft 模型——draft 模型逐 token 生成的代价同样受限于硬件利用率不高。
DFlash 的两大组件¶
Z Lab 的 DFlash(论文 arXiv:2602.06036)用块扩散(block diffusion)draft 模型一次性并行生成整块 token,更贴合现代硬件的并行能力。小米的 MiMo v2.5-Pro-UltraSpeed 已用 DFlash 达到超过 1k output tps。
但"用块扩散做 drafter"本身不是新想法,过去有两个失败模式:
- 直接训练一个小型块扩散模型作为 drafter → acceptance length 太低。
- 用现成的大块扩散 LLM(如 SpecDiff-2)作为 drafter → 显存太大、draft 成本太高。
DFlash 的关键洞察:目标 LLM 最懂上下文。受 Medusa、EAGLE、MTP 启发,从目标模型提取上下文 token 的 hidden representation;区别是不只在 drafter 输入处用,而是直接注入到 draft 模型的 KV cache 里。
这样:
- draft 模型不必从零建模完整上下文,只需专注于"预测下一块 token"。
- 可以复用目标模型后几层的张量,draft 模型保持极小且高效。
- 在更高 draft depth 下也能保持高 acceptance length。
Benchmark:Qwen 3-4B + 5-layer drafter¶
EAGLE-3 5-layer vs DFlash 5-layer 在相同数据集上训练,端到端结果(acc_len / speedup):
| Task | EAGLE-3 (5 layers) | DFlash |
|---|---|---|
| GSM8K | 4.2 / 2.1× | 4.2 / 3.3× |
| HumanEval | 4.3 / 2.2× | 4.0 / 3.2× |
| MT-Bench | 3.1 / 1.4× | 3.0 / 2.2× |
消融 1:diffusion drafting 单独贡献¶
DFlash 的"diffusion only" 变体(去掉 KV injection,保持块扩散):
| Task | EAGLE-3 (5 layers) | DFlash (diffusion only) |
|---|---|---|
| GSM8K | 4.2 / 2.1× | 3.5 / 2.9× |
| HumanEval | 4.3 / 2.2× | 3.5 / 2.9× |
| MT-Bench | 3.1 / 1.4× | 2.6 / 2.0× |
DFlash 即使在更低的 acceptance length 下,也比 EAGLE-3 端到端更快——核心来自"drafting cost" 的下降。
消融 2:KV injection 单独贡献¶
DFlash 的"injection only" 变体(去掉 diffusion drafting,回到自回归 drafter):
| Task | EAGLE-3 (5 layers) | DFlash (injection only) |
|---|---|---|
| GSM8K | 4.2 / 2.1× | 4.8 / 2.4× |
| HumanEval | 4.3 / 2.2× | 4.6 / 2.3× |
| MT-Bench | 3.1 / 1.4× | 3.4 / 1.5× |
证明 KV injection 让 acceptance length 显著提升,且端到端加速更明显。
工程实现:DFlash 在 SGLang V1 → V2 的演进¶
V1 阶段(已弃用):在原 speculative decoding 引擎里新增 DFlashWorker 与 DFlashDraftModel,并支持跨 draft/target 的 KV cache 集成。
SGLang 的 scheduler(运行在 host 上)调度 worker(运行在加速器上)。注意一个反直觉点:draft 模型 worker 才是与 scheduler 对话的一方(通过 .forward_batch_generation 等方法),它包装目标模型 worker 用于验证步骤。
KV injection 的工程难点:
- 不想存储那些 latents(占用 KV cache 空间)。
- 想让共享 prefix 的请求共用 radix cache。
- 因此在 draft forward pass 主体之前做"立即物化"——加一层 batched 线性 projection + 融合的 Triton kernel 处理 norm + RoPE。
V2 阶段:在 V2 speculative decoding 引擎里集成 DFlash,关键目标是减少 host-device 同步点。两个核心 overlap 机会:
- host 端
pop_and_process(N-1 批的 stop token 检测、metadata 更新)与 GPU 上 N 批工作重叠。 - host 端
prepare_for_decode里 N 批的 KV allocation 与 GPU 上 N-1 批工作重叠。
效果:Qwen 3-8B 单 B200 并发 32 下从 ~11.4 ktok/s 提升到 ~15.3 ktok/s(+33%)。
Headline 数字:Qwen 3.5 397B-A17B on 8×B200¶
- HumanEval concurrency 1:>4.3× baseline,1.5× MTP。
- 在所有 benchmark setting(GSM8K / HumanEval / MT-Bench,concurrency 1-32)下都比 baseline 与 native MTP 吞吐更高。
复现路径¶
export SGLANG_ENABLE_OVERLAP_PLAN_STREAM=1
python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-397B-A17B \
--trust-remote-code \
--speculative-algorithm DFLASH \
--speculative-draft-model-path modal-labs/Qwen3.5-397B-A17B-DFlash \
--speculative-dflash-block-size 8 \
--speculative-draft-attention-backend fa4 \
--attention-backend trtllm_mha \
--linear-attn-prefill-backend triton \
--linear-attn-decode-backend flashinfer \
--mamba-scheduler-strategy extra_buffer \
--tp-size 8 \
--max-running-requests 32 \
--cuda-graph-max-bs-decode 32 \
--cuda-graph-backend-prefill tc_piecewise \
--enable-flashinfer-allreduce-fusion \
--mem-fraction-static 0.8 \
--host 0.0.0.0
draft 模型权重三处 release:z-lab/Qwen3.5-397B-A17B-DFlash、modal-labs/Qwen3.5-397B-A17B-DFlash、lmsys/Qwen3.5-397B-A17B-DFlash。
致谢¶
- Z Lab:Jian Chen, Yesheng Liang, Zhijian Liu
- Modal:David Wang, Charles Frye
- SGLang:Qiaolin Yu, Liangsheng Yin, Khoa Pham
与现有实体的差异化¶
- 这是 LMSYS 2026-06 的最新 speculative decoding 技术博客,与现有 speculative decoding 相关实体(如 EAGLE、MEDUSA 早期工作)相比,时间新且含实证 benchmark
- vLLM 集成路径明确,可直接复现
- DFlash 是 block diffusion + KV injection 的组合创新,比单纯沿用 Medusa/EAGLE 风格的 next-token head 路线更进一步
实践启示¶
- 评估 LLM 推理加速方案时,DFlash + vLLM 是 2026 年值得测试的 baseline 之一
- 关注 LMSYS blog 系列作为 speculative decoding 进展的可靠信号源
- 如果你已经在用 EAGLE 或 MTP,遇到 acceptance length 瓶颈时可以考虑 DFlash 的 KV injection 思路(即使不上 block diffusion 也能拿到显著的 acceptance 提升)
- SGLang Spec V2 的 overlap scheduling 思路(host-device 重叠)值得借鉴到其他推理引擎的设计中
原文链接¶
相关实体¶
- automation anywhere collaborates with cisco, nvidia, okta, a
- ettin reranker family
- mathematical optimization at enterprise scale: aws innovatio
- DDoSing Software Delivery Pipelines
- AI GPUs probably live longer than three years
→ 原文存档
Ch16.014 TLiveOmni vLLM 适配与量化方案¶
📊 Level ⭐⭐⭐ | 10.1KB |
entities/tliveomni-vllm-quantization.md
→ 返回总览
vLLM 架构适配¶
模型注册¶
自定义模型不在 vLLM 官方支持列表,采用 Out-of-tree models 方式通过 Plugin 注册,无需修改 vLLM 源码。
def register():
from vllm import ModelRegistry
from your_code import YourModelForCausalLM
ModelRegistry.register_model("YourModelForCausalLM", YourModelForCausalLM)
多模态数据处理¶
vLLM 数据前处理三阶段("占位符 → Token 序列 → Embedding 向量"三级映射): 1. 数据预处理(tlive_process):多模态数据读取与向量化 2. 标识与排布:
- 定义标识(
get_placeholder_str):指定 Prompt 中多模态 Token 模版(如<video_pad>) - Token 展开与排布(
prompt_updates):将占位符替换为 N 个连续视觉占位 Token - 向量对齐与更替(
_maybe_apply_prompt_updates):Encoder 计算 Embedding 后填入对应位置
框架适配与精度对齐¶
多模态对齐问题¶
Interleave 排布修复¶
vLLM 默认将多模态特征 Embedding 拼接成连续序列,但 TLiveOmni 采用 V/A 交替排布(Vision Token 和 Audio Token 交替)。vLLM 默认连续拼接逻辑会导致:
- 连续视觉 Embedding 覆盖 Audio Token 位置
- 映射错位,模型输出与训练产生误差 修复方案:修改代码确保 Token 和 Embedding 排布方式与训练时一致。
Audio Token 自动 Padding 修复¶
vLLM 为优化 Cache 效率(保证特征维度是 8 的倍数)会在音频特征提取前 padding,导致 Token 长度不一致。解决方案:去除 vLLM 中 Audio 特征自动补全部分,严格按原始长度处理。
浮点运算差异¶
vLLM 和 Transformers 对 DeepStack 和 Residual 部分相加顺序不同:
- 数学上 A+B+C = (A+C)+B
- 但 GPU 浮点运算不满足加法结合律
residual输出大,先加大数还是先加小数会导致不同精度- 误差随模型层数逐层放大 修复方案:修改 vLLM 计算逻辑,确保 DeepStack 和 Residual 计算顺序与 Transformers 一致。
通用对齐问题¶
Flash-Attention 差异¶
vLLM 对 Vision 和 Language 模块采用不同 Attention 后端:
- Vision 模块(Qwen3-VL 等):直接调用
flash_attn_varlen_func,结果与训练一致 - Language 模块(vLLM):调用
torch.ops.vllm.unified_attention_with_output,这是 vLLM 为 PagedAttention 专门重写的算子 差异来源:CUDA 实现层面与原版 Flash-Attention 在累加精度、Scaling 处理或算子融合上存在微小差异。当前版本无法完全解决,但误差在可接受范围内。
RSNorm 对齐¶
vLLM 原生 RMSNorm 使用优化的 CUDA 算子(fused_add_rms_norm),但在 residual 加法和数据类型转换顺序上与 Transformers 存在偏差。Q、K 的 Norm 结果有 1e-4 级误差会经 Attention 矩阵乘法放大累积,因此对 vLLM 的 Norm 进行了替换。¶
模型量化方案¶
量化核心优势¶
- 释放显存:INT4/INT8 量化可释放 50%-75% 显存,使大模型能在消费级显卡(如 RTX 4090)上运行
- 降低延迟:权重与激活值位宽减小,访存压力降低,配合 GPU 低精度计算单元显著缩短执行时间
量化对象与维度¶
- 权重(Weight):减少模型占用显存
- 激活(Activation):减少显存 + 整型算子加速(W8A8)
- KV Cache:提高长序列处理能力
- 梯度(Gradients):训练阶段加速反向传播
量化精度格式¶
| 格式 | 说明 |
|---|---|
| WxAy | W=权重位数,A=激活值位数 |
| FP8 | NVIDIA 新一代量化格式,H100/L40S 原生硬件支持 |
量化阶段分类¶
| 类型 | 说明 |
|---|---|
| QAT(量化感知训练) | 在线量化,需要训练数据结合反向传播调整权重 |
| PTQ(后训练量化) | 离线量化,在已训练模型上进行 |
| - Post Dynamic | 无校准数据,直接量化(QLoRA 采用) |
| - Post Calibration | 需要校准数据集(GPTQ 采用) |
量化方法分类¶
- 通道级量化:LLM.int8、SmoothQuant、AWQ — 不同通道应用不同缩放因子
- 基于优化目标:GPTQ — 最小化量化前后输出误差
- 基于旋转矩阵:QuaRot、SpinQuant — 旋转变换消除离群点
复合量化方案:SmoothQuant + GPTQ¶
SmoothQuant:解决离群点问题
- 当 LLM 参数量超过 7B 后,激活值中出现远超均值的离群点(通常比正常值大 100 倍以上)
- INT8 量化会使大多数激活值被清零
-
SmoothQuant 引入平滑因子 s,将激活值离群点转移到权重上(权重分布更平滑、更易量化) GPTQ:最小化量化前后权重差异
-
起源于 Yann LeCun 1990 年提出的 OBD 算法(剪枝方法)
- 核心思路:找到量化权重使新权重和原权重输出结果差别最小
校准数据抽取策略¶
| 原则 | 说明 |
|---|---|
| 任务完整性 | 覆盖所有训练任务和能力边界 |
| 任务难度/敏感度 | 对数值波动敏感任务给予更多样本权重 |
| 高敏感任务(精度型): |
- OCR/Markdown:一个像素偏差可能导致"8"量化成"0"
- Visual Grounding:权重微小扰动使边界框漂移几十像素
- Temporal Grounding:微小扰动导致时间轴偏移 最终形成 5000 条高质量数据的校准池。
性能评测¶
精度评估(H20 单卡)¶
量化方案:SmoothQuant + GPTQ 复合量化,主要针对 Language Model 部分量化。 各量化方案精度损失均 <1.5%,其中 FP8 量化精度损失最小,图像与视频任务甚至有微弱性能提升。
推理速度测试(H20 单卡)¶
量化后综合加速比 2.5x~3.5x:
- Video(Short)加速收益不明显:vLLM 多模态预处理效率低于 Torch,时延占比重
- Video(Long)预处理占比相对较低,推理加速优势更充分体现
硬件对比:H20 vs RTX 4090¶
| 维度 | H20 | RTX 4090 |
|---|---|---|
| 显存 | 96GB HBM3 | 48GB GDDR6X |
| 带宽 | ~3.6TB/s | ~1TB/s |
| 最优方案 | FP8 | W4A16 |
| 长视频延迟 | 19.66s | 30.74s |
| H20 优势: |
- HBM3 高带宽支持超长序列 KV Cache 实时读取
-
Hopper 架构原生 FP8 Tensor Core,FP8 模式下不仅减轻访存压力,还通过高效 FP8 算子加速 RTX 4090 局限:
-
GDDR6X 带宽远低于 HBM3,长序列解码频繁访存导致 GPU 算力无法高效利用
- 48GB 显存应对超长上下文时利用已近极限
部署建议¶
| 场景 | 首选方案 |
|---|---|
| 大规模生产/长序列(电商直播、视频密集描述) | H20 + vLLM-FP8 |
| 边缘计算/显存受限场景 | RTX 4090 + vLLM-W4A16 |
| 系统级优化 | 同步关注 CPU 算力,优化数据加载减少前处理占比 |
| --- |
关键发现¶
- vLLM 多模态支持仍有缺陷:引擎死锁(#28375)、多模态模型精度大幅下降(#29595)
- 版本迭代断裂:vLLM v0.11.1 提供 Omni 支持,但 Qwen3-Omni 官方适配版本停止维护
- 异构硬件需不同量化策略:H20 适配 FP8,4090 适配 W4A16
- 前处理不可忽视:多模态数据推理中 CPU 频率影响整体 Latency
深度分析¶
vLLM 多模态适配的本质困难¶
量化精度 vs 推理效率的工程权衡¶
硬件差异化选型的底层逻辑¶
校准数据的任务敏感度分级¶
实践启示¶
量化方案选型决策树¶
- 确认硬件:H20 → 优先 FP8;RTX 4090 / 消费级卡 → W4A16
- 确认量化对象:权重优先(显存释放最大)→ INT4;需要加速激活计算 → W8A8;长序列 → 同步量化 KV Cache
- 选择量化方法:有离群点问题(LLM >7B 激活值分布不均)→ SmoothQuant + GPTQ;无明显离群点 → 直接 GPTQ/AWQ
- 校准数据:高敏感任务(OCR/VG/TG)→ 高权重覆盖;一般任务 → 均匀采样,确保 5000 条高质量数据池
vLLM 多模态适配检查清单¶
当需要将自定义多模态模型适配到 vLLM 时,以下检查点按优先级排序:
- 多模态 Token 排布:确认训练时 V/A 是连续还是交替排布,vLLM 默认连续拼接需要修改
- Audio Padding:检查 vLLM 是否会自动对音频特征补齐,如有需要去除
- 浮点累加顺序:确认 DeepStack/Residual 相加顺序与训练代码一致(误差会逐层放大)
- Flash-Attention 后端:Language 模块使用 vLLM 自研 unified_attention 算子,与原版 flash_attn 有微小精度差异(当前无法完全消除)
- RMSNorm 实现:检查 vLLM fused_add_rms_norm 的数据类型转换顺序,必要时替换
部署架构建议¶
| 场景 | 硬件 | 量化方案 | 关键注意事项 |
|---|---|---|---|
| 电商直播/视频密集描述(长序列) | H20 | FP8 | 关注前处理占比,优化 CPU 数据加载 |
| 边缘计算/实时推理 | RTX 4090 | W4A16 | 显存受限,长序列时注意 KV Cache 容量 |
| 高精度 OCR/Grounding 任务 | H20 | FP8 + 专用校准数据 | 校准池需覆盖高精度边界 case |
| 混合负载 | H20 + RTX 4090 混部 | 按任务分流 | 建立任务→硬件路由层 |
前处理优化方向¶
多模态推理中前处理(CPU 端)往往被忽视,但对短内容场景影响最大。建议: 1. 图像:使用 TurboJPEG/libjpeg-turbo 替代默认解码器,resize 用 NEON 加速 2. 音频:音频特征提取(Mel Spectrogram 等)用 PyTorch 批处理而非 vLLM 内置逻辑 3. 视频:关键帧采样策略在摄入端完成,不要在推理引擎内做动态采样
相关实体¶
- ai-infra-auto-driven-skills v0.1.0:给 codex / claude code 的推理
- gemma 4 multi token prediction drafters
- tokenspeed agentic inference engine
Ch16.015 vLLM V0→V1 迁移中的 logprob 差异修复¶
📊 Level ⭐⭐⭐ | 9.4KB |
entities/vllm-v0-to-v1-correctness-before-corrections.md-> 原文存档
核心发现¶
- V1 默认返回 raw logprobs(未经后处理),而 trainer 期望 processed logprobs
- V1 的 prefix caching / async scheduling 改变了执行路径
- 先修 backend 再调 objective,不要反过来
- Clip rate 是最敏感的 mismatch 指示器
影响范围¶
所有使用 vLLM 做 rollout generation 的 online RL 方法(PPO、GRPO、GSPO)
相关链接¶
→ 原文存档
相关实体¶
深度分析¶
背景:为什么 V0→V1 迁移是个高风险操作¶
vLLM 的 V1 引擎对 V0 做了大量底层重构,包括调度器架构、内存管理、KV cache 分配策略和 logprob 计算路径的重大变化。对于大多数推理场景,这些变化是透明的、性能正交的。但对于 RL 训练(尤其是需要精确 token-level logprob 的 PPO/GRPO/GSPO),这些变化直接影响了 logprob 的数值语义,进而影响 policy gradient 的计算精度。 V0 的 logprob 输出经过完整的 temperature → repetition_penalty → min_length/truncate 后处理流水线。而 V1 为了降低延迟,默认返回 raw model logits 经过 log-softmax 后的值,跳过了这部分后处理。这导致即使模型权重完全相同,V0 和 V1 的 logprob 也会系统性偏差。
四个 backend 问题的逐层解析¶
问题一:Logprob Semantics(最关键) V1 新增的 logprobs_mode 参数控制 logprob 的计算方式。默认值在 V0 和 V1 之间存在语义差异:V0 默认执行完整后处理,V1 默认不执行。当 use_v1: true 时,必须显式设置 logprobs_mode: "processed_logprobs" 来恢复 V0 语义。否则 reward shaping、entropy bonus、value estimation 全部会带上系统性偏差。 这个问题的影响范围极广:所有依赖 logprob 计算 advantage estimation 的 RL 方法都会受影响。PPO 的 clipped surrogate objective 直接依赖 logprob 比率,GRPO 的 group-relative advantage 依赖 logprob 的精确值。哪怕 0.01 的均值偏移,在数万次迭代的累积下也会导致训练曲线漂移。 问题二:Runtime Defaults — Prefix Caching 与 Async Scheduling V1 引入了 prefix caching(相同 prompt 前缀的 KV cache 复用)和 async scheduling(异步 token 生成调度)。这两个优化在推理场景下是重大性能收益,但在 RL 训练中引入了非确定性:相同 input_ids 可能因为 cache 命中状态不同而走不同的执行路径,导致 logprob 在 token 位置上有微小差异。 对于 RL 训练的可复现性(reproducibility)要求,这种不确定性是不可接受的。ServiceNow-AI 团队的建议是:在训练阶段显式关闭这两个特性(enable_prefix_caching: false, async_scheduling: false),只在推理部署时启用。 问题三:Inflight Weight Updates V1 的权重更新路径(weight update during inference)与 V0 有差异。这主要影响的是 online RL 中的 weight update 频率和时机。如果在 rollout 过程中进行权重更新(常见于 PPO 的 async PPO 变体),V1 可能因为权重同步时机不同导致 logprob 计算不一致。 问题四:fp32 lm_head 精度 lm_head(final projection layer)的计算精度在 V0 和 V1 默认配置下可能不同。V0 有时依赖 implicit FP8 或混合精度优化,而 V1 的默认精度策略可能不同。确保 lm_head 在 FP32 下运行可以避免低精度累积误差影响 logprob 精度。
Clip Rate 作为Mismatch 指示器¶
PPO 和 GRPO 训练中,clip rate(被 clip 的 policy ratio 的比例)是一个关键的可观测指标。正常训练时,clip rate 通常在 1%–20% 区间。如果 clip rate 出现剧烈波动(尤其是从极低突然升高)或训练曲线出现"台阶式"突变,这通常是 logprob 不匹配的信号。ServiceNow-AI 特别指出:在 V0→V1 迁移的初期,clip rate 是最容易读到的系统性 mismatch 信号,应该作为第一优先级监控指标。
实践启示¶
迁移检查清单¶
在将 RL 训练 pipeline 从 V0 切换到 V1 时,以下配置是必须验证的:
vllm_config:
use_v1: true
vllm_kwargs:
logprobs_mode: processed_logprobs # 恢复 V0 logprob 语义
enable_prefix_caching: false # 关闭 cache 非确定性
async_scheduling: false # 关闭 async 调度非确定性
lm_head_precision: fp32 # 确保 lm_head 精度对齐
推荐迁移策略¶
阶段一:逐项隔离验证 不要一次性切换所有配置。先在固定随机种子下,对比 V0 和 V1 相同输入的 logprob 输出。使用一个简单的 dummy prompt(如 "The capital of France is"),对比每个 token 位置的 logprob 差异。如果差异超过 1e-3,说明 logprob 语义未对齐。 阶段二:短期 RL 跑分 在确认 logprob 数值对齐后,用一个小型模型(如 1B–3B)在短数据集上做 100–500 步的 RL 训练。对比 V0 和 V1 的训练曲线(特别是 clip rate 和 policy entropy)。如果两者在 1% 以内对齐,再切换到完整训练。 阶段三:prod 迁移后持续监控 V1 的默认行为会随着 vLLM 版本更新而变化。每次升级 vLLM 后,都应该重新跑一遍上述对齐验证 pipeline。
对不同 RL 方法的影响差异¶
- PPO:对 logprob 精度最敏感,因为 PPO 的 importance sampling ratio (
π_new/π_old) 直接依赖精确 logprob 值 - GRPO:相对宽容一些,group-relative advantage 计算会做归一化,但 logprob 均值偏差仍会影响 advantage baseline
- GSPO(格尔茨随机策略优化):和 GRPO 类似,但由于采样策略更激进,logprob 不匹配会放大采样方差
配置管理的工程建议¶
建议在 RL 训练代码中,通过环境变量或 config 文件集中管理 vLLM 的版本兼容配置,而非散落在各个调用点。这样可以在切换 V0/V1 时保持单一配置来源,减少因配置不一致导致的难以复现的 bug。¶
总结¶
vLLM V0→V1 迁移中的 logprob 差异,本质上是 推理引擎默认行为变化 与 RL 训练对数值精度的严格要求 之间的冲突。核心修复路径是:显式设置 logprobs_mode: processed_logprobs,关闭 prefix caching 和 async scheduling 确保执行路径确定性,并在训练初期以 clip rate 为核心监控指标验证对齐状态。不要在 backend 未对齐的情况下尝试通过调整 RL objective 来"掩盖"问题——那样只会引入更难追踪的隐式错误。
Ch16.016 ServiceNow vLLM V0→V1 正确性修复¶
📊 Level ⭐⭐⭐ | 8.3KB |
entities/servicenow-vllm-correctness-huggingface.md-> 原文存档
核心问题:训练-推理 logprob 不匹配¶
PipelineRL 的训练器直接消费 rollout 产生的 token logprobs 来计算策略比率、KL 散度、clip rate、entropy 和 reward。任何 logprob 计算语义的变化都会改变训练动态。
vLLM V1 默认返回原始模型输出的 logprobs(在 temperature scaling、penalties、top-k/top-p 过滤之前),而 PipelineRL 期望的是经过采样器处理的分布的 logprobs。这一语义差异导致初始 V1 跑通后,clip rate、KL、entropy、reward 全面漂移。
四个后端修复¶
1. Logprob 语义修复¶
设置 logprobs-mode=processed_logprobs 移除了明显的均值偏移,使策略比率均值稳定在 1.0 附近。但训练曲线仍有差距——说明单一修复不够,下一个问题在推理路径本身。
2. 运行时默认值对齐¶
V1 的 prefix caching(默认开启)和 async scheduling(默认开启)引入了 V0 不存在的执行路径差异。在 online RL 场景下,prefix cache 命中可能在权重更新边界之前重用已计算状态,导致 actor 拿到过期推理结果。
对齐配置:
vllm_config:
use_v1: true
vllm_kwargs:
logprobs-mode: processed_logprobs
enable-prefix-caching: false
async-scheduling: false
3. Inflight Weight Updates 语义对齐¶
V0 的权重同步机制:阻塞在引擎边界 → 加载新权重 → 恢复执行,不显式清除缓存。V1 等效方案:
await engine.pause_generation(mode="keep", clear_cache=False)
await engine_client.collective_rpc_async(
"receive_weight_update",
args=(request.model_dump_json(),),
)
await engine.resume_generation()
关键:mode="keep" 和 clear_cache=False 匹配了 V0 的隐式语义。
4. fp32 lm_head 最终投影精度¶
即使前三项修复完成,最终 parity 仍需要 fp32 lm_head。MiniMax-M1 技术报告和 ScaleRL 论文都独立发现了这个问题:RL 更新直接消费 token logprobs,而 lm_head 输出的 logits 精度变化会传播到 logprobs,进而影响策略比率、KL 散度和 clip rate。
核心工程原则:先修后端,再谈目标¶
ServiceNow 的经验是:错误的顺序(先改目标函数再修后端)会导致目标侧的修正掩盖后端问题,使训练曲线难以解读。正确的问题分解应该是:
- 推理后端是否产生了正确的 logprobs?
- 给定正确的 logprobs,目标函数是否还需要 off-policy 或 async 修正?
这两个问题需要分离处理。
相关实体¶
深度分析¶
vLLM V0 到 V1 的迁移表面上是同一个推理引擎的版本升级,实际上是一次架构重写带来的行为契约变化。 ServiceNow 团队设定的迁移目标"让 V1 返回与 V0 等效的 rollout logprobs"看似技术性极强,实则揭示了 RL 训练系统中的一个深层依赖:训练器对推理后端的输出语义做了隐式假设。这些假设在 V0 时代是正确的,但在 V1 重写后若不显式声明和强制对齐,就会成为训练不稳定的隐秘根源。
logprobs 的语义差异(原始模型输出 vs. 采样器处理后分布)是四个修复中最初级但也最关键的一个。 它之所以关键,不是因为修复困难,而是因为它揭示了一个更普遍的问题:推理引擎版本升级时,默认配置的语义变化往往不会出现在升级指南中,却会直接影响消费推理输出的上游系统。这一问题在 PipelineRL 这类直接消费 token logprobs 计算训练目标的架构中尤为致命——logprob 均值偏移直接体现为策略比率的系统性偏差。
prefix caching 在 RL 推理中的危险性被这一案例充分暴露。 Prefix caching 的设计目的是通过重用已计算的 KV cache 加速推理,这在静态场景(固定模型权重、固定对话前缀)下是合理的优化。然而,在 online RL 场景下,模型权重在训练过程中持续更新,prefix cache 命中可能在权重更新边界之前重用已计算状态,导致 actor 获取与当前权重不对应的过期推理结果。这一问题在异步调度和并发请求混合时进一步复杂化,因为缓存失效边界与权重更新边界的对齐无法得到保障。
fp32 lm_head 的发现在多个独立研究中得到印证(MiniMax-M1 技术报告、ScaleRL 论文),表明这是一个跨团队、跨方法的普遍性问题而非 ServiceNow 特有。 fp16 lm_head 输出的 logits 精度变化通过 logprobs 传播到 RL 更新的每一个计算环节——策略比率、KL 散度、clip rate 均受影响。这意味着在大型 RL 训练任务中,lm_head 投影精度的选择并非性能优化问题,而是正确性前提。ScaleRL 将 fp32 logits/head 计算纳入标准 RL 配方,意味着这一实践正在从个别案例上升为社区共识。
ServiceNow 总结的核心工程原则——"先修后端,再谈目标"——具有超出 vLLM 迁移场景的方法论价值。 在引入任何目标侧修正(truncated importance sampling、off-policy correction、async correction)之前,必须首先确保推理后端在等效条件下运行。这一原则的反面教训同样重要:在推理后端行为未对齐的情况下,目标侧的修正会与后端问题产生混合效应,使得训练曲线难以解读,也无法判断改进来源于修正本身还是后端修复的附带结果。
实践启示¶
- 推理引擎升级时的必检清单:在将推理引擎升级到新版本后,第一步应验证 rollout logprobs 与旧版本的语义等效性,而非直接进行目标函数调优或训练超参数调整;具体检查项应包括 logprobs 计算位置(原始输出 vs. 采样后)、默认精度(fp16 vs. fp32)和默认优化项(prefix caching、async scheduling)的状态变化。
- online RL 场景下禁用 prefix caching:在模型权重持续更新的训练场景中,prefix caching 引入的缓存重用语义与权重更新边界可能产生冲突;建议在 online RL 训练中显式设置
enable-prefix-caching: false,直到推理引擎提供权重更新感知的缓存失效机制。 - inflight weight update 的语义声明:在实现权重更新逻辑时,应明确声明
mode和clear_cache参数的语义选择并与推理引擎版本对齐;mode="keep"和clear_cache=False的组合匹配了 V0 的隐式语义,但新引擎版本可能有不同的默认值,需要显式对齐。 - lm_head 投影精度作为 RL 正确性前提:对于直接消费 token logprobs 的 RL 训练系统,建议将 fp32 lm_head 作为基线配置而非可选优化;这一选择与 ScaleRL 论文的推荐一致,在不引入显著性能损失的情况下消除了数值精度传播这一隐蔽的正确性风险。
- 问题分解的工程顺序:当训练曲线出现异常时,应严格遵循"推理后端等效性 → 目标函数修正"的处理顺序;在确认推理后端正确性之前,避免在目标侧引入修正——否则修正效果与后端修复效果混合,使得训练异常的根因诊断变得不可信。
Ch16.017 Profiling in PyTorch (Part 2): From nn.Linear to a Fused MLP¶
📊 Level ⭐⭐⭐ | 8.2KB |
entities/huggingface-torch-mlp-fusion-profiling-2026.md
Profiling in PyTorch (Part 2): From nn.Linear to a Fused MLP¶
Background: Hugging Face team profiling series part 2 (2026-06-11). Climbs from single nn.Linear to 3-layer MLP with ReLU activation, profiles GPU kernel launch overhead, and shows torch.compile Inductor fusion reducing 9+ launches to 3 fused triton kernels.
Core problem¶
- nn.Linear is the building block of nearly all deep learning models
- Single nn.Linear call produces multiple kernel launches (matmul + bias add)
- ReLU activation adds additional launches
- At small batch size (1024x1024), each layer can produce 5+ launches
- Kernel launch overhead (10-20us each) dominates total latency in overhead-bound regime
Key findings¶
- 3-layer MLP produces 9+ kernel launches (3 Linear x 3 ops/Linear + 2 ReLU), single launch 10-20us, launch overhead 30%+ of total
- torch.compile auto-fusion: Inductor backend fuses matmul + bias_add + relu into a single triton kernel, reducing 3 launches per layer to 1, total 9 to 3
- Compute-bound vs overhead-bound crossover: at batch=1024 launch overhead dominates; at batch>=4096 compute dominates and fusion gains diminish
- CPU dispatch chain is hidden overhead: each op traverses torch.add -> aten::add -> aten::add.out -> aten::copy_ dispatch layers, visible in profiler but not in user code
- torch.compile guard / recompile: dynamic shapes trigger multiple recompiles, so first call can be slower than eager mode
Practical takeaways¶
- Latency-sensitive small batch inference (batch<=2048): prefer torch.compile fusion
- Large batch training (batch>=4096): eager and compile modes have similar performance
- When profiling, focus on cudaLaunchKernel duration field, not just Self CUDA Time
- Use torch.profiler.profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA]) with record_function decorator to localize bottlenecks
Wiki cross-links¶
- Same series (profiling part 1) - not yet ingested; check entities/torch-compile-* for related Inductor backend content
- Candidate associations: kernel fusion, launch overhead, Inductor backend (no existing entity)
深度分析¶
核心观点¶
- 单算子层面的"融合"已接近极限,融合优化的主战场正在向算子间边界迁移
nn.Linear的 bias 加法已经通过 cuBLAS GEMM 的 epilogue 机制在单 kernel 内部融合(addmm),torch.compile在单 Linear 层上没有更多融合空间- 真正的融合收益出现在 算子间:GeLU + element-wise mul + reshape 这三个独立 kernel 在 compile 后融合为一个 Triton kernel,消除了中间结果在 HBM 的往返
-
这意味着未来优化应关注"哪些算子之间有中间结果往返",而非在单算子内部寻找融合机会
-
CPU 端的 dispatch 开销是被忽视的瓶颈,尤其在 overhead-bound 场景
- 每个 PyTorch 算子经过
aten::linear → aten::t → aten::addmm的 dispatch 链,每次 dispatch 触发 Python/C++ binding 开销 torch.compile通过 Inductor 在编译时展开这个链,直接发射aten::addmm,消除了中间 view 操作带来的 CPU 开销-
对 batch<=2048 的小 batch 推理,这个 CPU 开销占总延迟的 30%+,是 fused kernel 带来的主要收益来源
-
静态 shape 特化 vs 通用性是一个根本性权衡
- Inductor 的 fused kernel 为
[8192, 3072]形状专门生成,执行时间 89.4µs;Liger 手写 kernel 泛化任意形状执行时间 92.8µs - 差距仅 3.4µs,但背后是 compile-time shape specialization 的代价——动态 shape 触发 recompile,重编译成本可能远超单次执行节省
-
实际工程选择应基于输入 shape 是否稳定,而非绝对性能数字
-
GEMM 形状影响 kernel 选型,从而影响性能——同样的 FLOPs 不等于同样的速度
- gate_proj 和 up_proj:M·K·N = 8192·768·3072,执行时间 0.19ms
- down_proj:M·K·N = 8192·3072·768,执行时间 0.17ms(快约 10%)
- 原因:N=768 vs N=3072 导致 cuBLAS 选择了不同的 tile 配置(128×256 with stages_64x3 vs 128×128 with stages_32x5),更深 pipeline 的 tile 在该形状下复用更好
技术要点¶
- GEMM epilogue:矩阵乘 kernel 在写回 HBM 前执行 bias add / activation,避免单独发起一次 HBM 读写
- Triton pointwise fusion:Inductor 的 Triton 后端将 pointwise 算子(GeLU、mul、reshape)融合为单一 kernel,intermediate 留在寄存器而非 HBM
- cuBLAS occupancy query:每次 GEMM 发射前调用
cudaOccupancyMaxActiveBlocksPerMultiprocessor确认最优 grid 配置,pointwise kernel 则直接发射无查询 - View 不产生 kernel:
aten::t、aten::transpose、aten::as_strided只改 tensor metadata(shape + stride),不搬动数据,不发射 GPU kernel
实践价值¶
- 对ML 工程师:小 batch 推理(batch≤2048)优先用
torch.compile,收益最大;大 batch 训练(batch≥4096)可保留 eager mode 省去编译开销 - 对性能工程师:profiler 表中看到
0.000usCUDA 时间的 op 名称(如aten::t)应忽略,它们是纯 CPU 元数据操作,不是真正的 GPU 负载 - 对框架开发者:设计新算子时考虑是否有 epilogue融合机会——在 GEMM 尾部做激活函数比单独发射 kernel 更高效
相关实体¶
- Deepseek V4 Triton Fp4 Optimization — 同样涉及 Triton kernel 优化,与本文的 pointwise fusion 优化角度互补
- Inference Optimization — 推理优化通识,包含本文未覆盖的量化 / 蒸馏 / serving 层面的优化策略
实践启示¶
- 建立"先猜测再验证"的 profiler 习惯:每次看 trace 前先在脑中构建预期,trace 打开后第一时间关注"预期与现实的差异"——差异就是最有价值的发现
- 小 batch 推理优先 torch.compile:batch≤2048 时融合收益最高(kernel launch overhead 占 30%+);batch≥4096 后 compute-bound 主导,compile 收益递减
- 关注 cudaLaunchKernel duration 而非只看 Self CUDA Time:Self CUDA Time 漏掉了 kernel launch 调度开销,duration 字段包含 launch 和实际执行两部分
- 动态 shape 场景慎用 torch.compile:若输入 shape 在每次推理时都可能变化(如 streaming 输入),compile 的 recompile 成本会抵消甚至超过融合收益,此时用 Liger 类手写 fused kernel 更稳定
- 用 kernels 库分发预编译 kernel:避免本地编译的痛苦(版本不匹配、GPU 架构差异),通过
get_kernel("kernels-community/liger-kernels", version=N)下载 CI 预编译的版本化二进制
Source¶
Original URL: https://huggingface.co/blog/torch-mlp-fusion
Source: raw archive
Ch16.018 elasticpp重塑elasticsearch查询性能的c内核引擎¶
📊 Level ⭐⭐⭐ | 6.2KB |
entities/elasticpp重塑elasticsearch查询性能的c内核引擎.md
elasticpp:重塑Elasticsearch查询性能的C++内核引擎¶
相关实体¶
- Overcoming Reward Signal Challenges Verifiable Rewards Based Reinforcement Learn
- Claude Code Hidden Settings 18
- Alphaevolve交出一周年炸裂成绩单Ai自我改进不再科幻
- Rag Chunking Optimization 2025
- Wangyunhe Harness Optimization Agentsoul
→ 原文存档
深度分析¶
问题本质:JVM 查询引擎的结构性瓶颈¶
Elasticsearch 基于 Lucene 构建,而 Lucene 本质上是一个 Java 库。这意味着所有查询执行路径都运行在 JVM 上,受到 Java 虚拟机的固有约束。文章精准识别了两个相互强化的核心问题:
- 长尾查询的线程池饱和:ES 的查询线程池大小固定,当中长尾查询(涉及数十万到百万级文档的聚合、排序、扫描)密集出现时,线程池被长时间占用,导致所有查询(包括短查询)排队等待,延迟急剧恶化
- GC 抖动造成的延迟不确定性:大量中间对象(迭代器、打分器、收集器)的频繁创建和销毁触发 GC,而 JVM 的垃圾回收是不可预测的——一次 Full GC 可将稳定在个位数毫秒的查询延迟推高到数百毫秒甚至秒级
这两个问题不是通过调参能解决的,因为它们的根源在于 架构层面:GC 问题的根因在 JVM,只要还在 JVM 上运行就无法彻底消除;而 Lucene 逐条处理文档的执行模型在大数据量下效率不高,但这是 Lucene 架构设计的固有特性。
技术路径:C++ Native 查询引擎的重新设计¶
elasticpp 没有选择替换整个 Elasticsearch,而是将最核心、最耗性能的查询执行路径用 C++ 重新实现,作为 ES 的插件通过 JNI 调用。这种「外科手术式」的改造有几个关键决策:
- 产品形态:用户无需修改 DSL、无需迁移数据,甚至无需知道 elasticpp 的存在,通过 fallback 机制自动回退未支持的查询类型
- 索引兼容性:完整实现了 Lucene 索引格式的读取能力,覆盖 Lucene90、Lucene99、Lucene101 及 ES 自定义编码,支持主流查询和常用聚合
- 性能优化三板斧:批处理(降低函数调用次数,编译期模板特化消除虚函数调用)、预取(批量加载 DocValue 到连续内存,提升 CPU 缓存命中率)、零拷贝与解压缓存(合并解码和处理步骤,对频繁访问的压缩数据块缓存解压结果)
一个值得重视的工程教训:批处理的隐藏陷阱¶
文章中提到的 bug 很有代表性。将文档收集从逐条改为批处理后,部分查询的排序结果与 ES 原生引擎不一致。根因是 Lucene 查询体系中存在「分数改写」机制:某些查询类型会在初始打分后对分数进行二次改写(如将所有分数替换为常量,或乘以权重系数)。在逐条处理模式下,改写是串行发生的;而在批处理模式下,一批文档的分数先统一计算,如果后续改写逻辑没有正确作用于整个批次,就会出现分数不一致。
这个教训的普适性在于:批处理不是简单地把「处理一个」改成「处理一批」。原有逐条处理逻辑中可能隐含着各种顺序依赖和状态改写,批量化之后都需要被重新审视。 性能优化永远不能以正确性为代价。
效果与局限¶
从测试结果看,elasticpp 在聚合和排序类的长尾查询中有明显性能提升,已在生产环境中覆盖数十 TB 索引规模。但未来方向(存储计算分离、异步查询)说明当前方案仍有局限性——它本质上仍是单机计算模型,扩展性受到单机磁盘容量和资源的约束。
实践启示¶
架构层面¶
- 性能瓶颈的根因往往在架构,而非参数调优。ES 的 GC 和长尾查询问题不是调整 JVM 参数能解决的,需要从执行模型层面重新设计
- JNI/Native 集成是提升 Java 应用计算性能的可行路径,但需要完整的索引格式兼容能力和 fallback 机制保证正确性
- 插件化改造是低风险的技术演进策略:在不改变用户接口和现有数据的前提下,通过插件替换核心路径,降低了迁移风险和用户改造成本
工程层面¶
- 批处理改造必须重新审视所有隐式状态和顺序依赖。特别是涉及分数改写、权重计算等操作时,要确保批处理模式下的语义等价性
- 对比调试(Native 侧 GDB + Java 侧 IDEA)是排查 JNI 问题的有效手段,问题只在特定查询组合下触发时,单一语言的单元测试难以覆盖
- 性能优化的效果是叠加的。批处理、预取、零拷贝每个单独看都只是节省少量开销,但叠加在数十万次文档处理上,效果非常明显
系统设计层面¶
- 线程池饱和是分布式查询系统的共性问题。当查询执行时间的长尾分布较重时,固定大小的线程池会成为系统瓶颈。异步查询和更灵活的资源管理是长期方向
- 延迟不确定性问题对 SLA 承诺的影响。GC 抖动的不可预测性使得延迟敏感业务难以承诺稳定的 SLA,这是推动向 native 层迁移的核心业务动机之一
- 存储计算分离是索引规模持续增长后的必然选择,单机磁盘容量会成为瓶颈,计算和存储需要能独立扩展
Ch16.019 vLLM V0 to V1: Correctness Before Corrections in RL¶
📊 Level ⭐⭐⭐ | 4.6KB |
entities/servicenow-vllm-correctness.md-> 原文存档
深度分析¶
vLLM V0 到 V1 是实质性重写,而非增量迭代。ServiceNow AI 的这篇博客核心贡献是展示了在 RL 训练中进行推理引擎迁移时,如何系统性地隔离和修复正确性差距,而非直接诉诸目标函数层面的修正。
logprobs 语义不匹配是首个拦路虎。 vLLM V1 默认返回原始模型输出的 logprobs(在 temperature scaling、penalties、top-k/top-p 过滤之前),而 PipelineRL 期望的是经过采样器处理的分布的 logprobs。设置 logprobs-mode=processed_logprobs 修复了均值偏移,但训练曲线仍有差距——说明单一修复不够,下一个问题的根因在推理路径本身。
V1 运行时默认值引入的隐性差异。 prefix caching(默认开启)和 async scheduling(默认开启)在 V1 中与 V0 行为不同。prefix caching 在 online RL 场景下尤其危险:前缀缓存命中可能在权重更新边界之前重用已计算状态,导致 actor 拿到过期推理结果。禁用 prefix caching 和 async scheduling 是还原 V0 等效行为的必要步骤。
inflight weight update 的语义对齐。 V0 的权重同步机制本质上是:阻塞在引擎边界 → 加载新权重 → 恢复执行,不显式清除缓存状态。V1 的等效方案是 pause_generation(mode="keep", clear_cache=False) → RPC 传递权重更新 → resume_generation()。关键在于 mode="keep" 和 clear_cache=False 匹配了 V0 的隐式语义。
fp32 lm_head 的必要性有独立文献支撑。 MiniMax-M1 技术报告已经发现 RL 训练/推理 token 概率不匹配问题并归因于 LM 输出头,ScaleRL 论文也将 fp32 logits/head 计算纳入大规模 RL 配方并 ablation 验证。这是 RL 推理引擎迁移时不可忽略的数值精度问题,因为 logprobs 直接进入策略比率、KL 和裁剪计算。
实践启示¶
推理引擎迁移时先做后端等效性验证,再调整 RL 目标函数。 这是 ServiceNow 最核心的经验。错误的顺序(先改目标函数再修后端)会导致目标侧的修正掩盖后端问题,使训练曲线难以解读,无法判断收益来源是目标改进还是后端补偿。
online RL 场景下 prefix caching 需要特别谨慎。 论文描述的问题本质是:缓存的生命周期管理在权重异步更新场景下与静态推理场景不同步。如果你的 RL pipeline 有并发请求、异步调度或 inflight weight updates,prefix caching 可能引入难以察觉的状态污染。
logprobs 模式选择是 vLLM V1 迁移的第一个检查项。 任何 PipelineRL/GSPO/PPO/GRPO 系统在切换到 V1 前,首先确认 logprobs-mode 设置与训练器期望一致。默认值差异会导致所有 downstream metrics(clip rate、KL、entropy、reward)全面漂移。
lag 是有用的运行时诊断信号。 初始 V1 路径在训练后期携带更多持续性 lag,最终 V1 修正路径的 lag 曲线更接近 V0 参考。这提供了一个可直接观察的训练健康度指标——如果你的 rollout engine 和 trainer 之间的权重 lag 在训练后期持续扩大,说明后端同步机制可能存在问题。
后端等效性恢复后,下一步是 async/off-policy 清理。 保持 rollout 时刻的 behavior policy logprobs,在优化时重新计算 trainer-side old policy logprobs,将后端差异修正与策略更新比率分离,跟踪 ESS 等诊断指标——这些是后端 parity 达成后的自然下一步。
相关实体¶
→ 原文存档
Ch16.020 Bonsai Image 4B: 1-bit 和 Ternary 量化¶
📊 Level ⭐⭐⭐ | 4.4KB |
entities/bonsai-image-4b-quantization.md
Bonsai Image 4B: 1-bit 和 Ternary 量化¶
Background: 本文档基于对外部技术来源的评分入库建立,v×c=7×7=49。
核心要点¶
1-bit 和 Ternary 量化图像扩散模型 Bonsai Image 4B 的技术发布,8.3x 和 6.4x 相比 FP16 的压缩比
→ 原文存档
深度分析¶
1. Group-wise Scaling Factor 是量化质量的关键
1-bit 和 Ternary 量化的核心不在于简单地将权重二值化或三值化,而在于保留了 FP16 分组缩放因子。每个权重分组拥有独立的缩放系数,使得 1-bit 模型实际达到 1.125 有效位数,Ternary 模型达到 1.71 有效位数。这种设计在极端压缩下仍能保留大部分模型能力,是 Bonsai 系列的核心技术路径。
2. Precision-sensitive Projection Layers 保留策略
虽然主体 transformer 权重被压缩到 1-bit 或 Ternary,但约 5% 的投影层(projection layers)被保留为 FP16 精度。原文指出这些是"precision-sensitive"的组件,表明并非所有权重对量化同等敏感。这一发现意味着未来量化研究可以针对不同层类型采取差异化的精度策略。
3. Ternary 的 {−1, 0, +1} 提供了重要的表征灵活性
相比 1-bit 的 {−1, +1},Ternary 加入了 0 状态,形成 {−1, 0, +1}。这一额外的中间态显著提升了视觉质量和提示词忠实度:Ternary 保留了原模型的 95% 性能,而 1-bit 仅有 88%。零值状态在稀疏计算中有潜在优势,可以在推理时跳过零值计算,进一步提升效率。
4. 质量–体积 Pareto 前沿的实质性推进
Bonsai Image 4B 在 6.4x 压缩下仅损失 5% 质量(GenEval 0.723 vs 0.819),而体积相似的 BK-SDM-Small(0.98GB)仅保留 42% 性能。这说明 Bonsai 的量化不是以线性质量损失为代价,而是在相同体积下实现了能力的大幅跃升,重新定义了"小模型能做什么"的标准。
5. iPhone 部署验证了移动端可行性的临界点
Bonsai Image 4B 是其参数级别上首个直接在 iPhone 上运行的图像生成模型。在 iPhone 17 Pro Max 上生成 512x512 图像仅需 9.4 秒,这意味着移动端图像生成的交互延迟已进入可接受范围。平均活跃内存 1.5–1.96GB 的表现证明极量化和架构共同构成了移动部署的可行路径。
实践启示¶
1. 优先考虑 Ternary 量化作为质量–压缩平衡点
如果应用场景对图像质量有要求,Ternary 的 6.4x 压缩比和 95% 性能保留是更优选择。只有在极端内存约束(如 1GB 以下 transformer)时,才考虑 1-bit 方案。Apache 2.0 许可下可直接商用,无需考虑授权成本。
2. 结合 Ai Infra Llm Efficient Inference Vllm 进一步降低推理延迟
虽然 Bonsai 本身已针对 Apple Silicon(MLX)和 CUDA(Gemlite)做了 kernel 优化,但在端侧部署时可结合推理优化技术(如批处理策略、KV cache 管理)进一步提升吞吐。Bonsai Studio iOS app 的部署案例提供了参考实现路径。
3. 利用文本编码器 offloading 策略降低运行时内存
在 512x512 图像生成时,平均活跃内存(1.5GB / 1.96GB)显著小于总部署 payload(3.42GB / 3.88GB),因为文本编码器在提示词编码完成后即可卸载。这一策略可直接应用于类似架构的部署优化,在长 prompt 场景下收益尤其明显。
4. 关注 zero-state 的稀疏计算加速潜力
Ternary 权重中的零值可以在推理时跳过相关计算,结合稀疏 kernel 可能实现进一步加速。这意味着在设计端侧推理 engine 时,应考虑对 {0} 值的条件分支优化或 mask 化处理。
5. 评估跨平台推理栈的统一抽象层
Bonsai 同时支持 Apple Silicon(MLX)和 CUDA(Gemlite),对于需要跨平台部署的团队,建议关注 MLX(Apple)和 Gemlite(NVIDIA)背后的底层 kernel 差异,或探索如 llama.cpp 风格的统一推理抽象,以同时覆盖手机端和桌面端 GPU 场景。
相关实体¶
Ch16.021 pytorch in kernel recsys optimization¶
📊 Level ⭐⭐⭐ | 4.4KB |
entities/pytorch-in-kernel-recsys-optimization.md
深度分析¶
消除而非优化:Kernel 层设计的方法论突破: IKBO 的核心洞察是"broadcast 是数据布局问题,而非计算必需"——传统方法在系统层面处理 broadcast 复制,浪费内存带宽和计算资源;而 IKBO 在计算原语层面消除复制,让 kernel 内部处理 mismatched batch sizes。这个思维转换将优化方向从"workaround 问题"转向"消除问题根源",实现了 2/3 的延迟降低。这种在根源处解决问题而非在表面做修补的思想,对其他 AI 系统优化有普遍借鉴意义。 See also Harness Production Agent Engineering Deficit
Kernel-Model-System 三层协同设计是性能突破的关键: IKBO 的成功不只是 kernel 优化的功劳,而是 kernel、ML 编译器、inference runtime 三层协同设计的结果。Kernel 层提供支持 mismatched RO/NRO batch sizes 的原生接口;编译器层需要 per-operator dynamic shape ranges 来选择正确形状的 kernel;runtime 层通过 candidate-to-user mapping 而非 materializing broadcast 传递信息。任何一层单独优化都无法达到最终效果,系统级协同优化才能实现数量级突破。
渐进式协同设计是工程落地的合理路径: IKBO Linear Compression 经历了四个阶段的渐进优化:matmul decomposition → memory alignment → broadcast fusion → warp-specialized multi-stage fusion via TLX,最终在 H100 SXM5 上实现 ~4× 加速。这个过程说明性能优化不是一步到位的,而是需要持续迭代、逐步逼近硬件极限。每一步优化都为下一步创造条件,最终的 warp-specialized fusion 无法在初始阶段直接实现。
IO-bound 到 compute-bound 的转变是性能优化的分水岭: IKBO 将 Flash Attention kernel 从 IO-bound 推向 compute-bound,峰值达到 621 BF16 TFLOPs(H100 SXM5)。在 GPU 编程中,IO-bound 意味着 kernel 性能受限于内存带宽,而非算力——此时增加更多计算单元也无法提升性能。转变为 compute-bound 是优化的关键里程碑,意味着 kernel 已经充分利用了硬件的算力潜能,继续优化需要从算法或数据布局入手。
RecSys 推理优化的独特挑战来自 user-candidate 不对称性: 与传统 DNN 不同,RecSys 的 user embeddings 对所有 candidate 都相同,但 candidate 数量(10-10,000+)远大于 user 数量,导致 broadcast 复制开销随 candidate 数量线性增长。这个问题在 CV/NLP 任务中不存在,因为它们的 batch 维度天然对称。理解这个领域特有的不对称性,是设计高效 RecSys 系统的前提。
实践启示¶
-
遇到性能瓶颈时,先判断是 IO-bound 还是 compute-bound:如果 kernel 已经是 compute-bound,继续优化算法或数据布局才有意义;如果是 IO-bound,优化方向应该是减少内存访问或提高内存访问效率,而非增加计算量。
-
Kernel 优化采用渐进式策略:先实现功能正确的版本,再逐步优化——从基础 matmul 到 decomposition,再到 memory alignment,最后做 fusion。一次性写出最优 kernel 既不现实也不高效。
-
RecSys 系统的 broadcast 开销需要专门优化:当 user-candidate 不对称时,传统的 explicit replication 会造成严重的内存和计算浪费。考虑在 kernel 内部处理 broadcast,而非在系统层面 materialization。
-
Inference-time transformation 可实现无感的系统升级:Meta 的 IKBO 支持在推理时自动替换标准操作为 IKBO 等效操作,无需模型代码变更。这种无破坏性升级能力对生产系统非常重要。
-
Custom kernel 开发需要工具链配合:TLX (Triton Low-Level Extensions) 提供了 warp-specialized fusion 能力,但需要与 ML 编译器、inference runtime 配合使用。单独优化 kernel 而忽视其他层级,往往无法达到预期效果。