Ch15 训练与微调¶
打造专属模型:PPO → DPO → GRPO,合成数据,课程学习
本章收录 34 篇实体,按深度递增排列。
本章导航¶
| Level | 含义 | 篇数 |
|---|---|---|
| ⭐⭐ 工程师 | 需编程基础 | 10 |
| ⭐⭐⭐ 专家 | 需ML基础 | 20 |
| ⭐⭐⭐⭐ 科学家 | 需研究背景 | 4 |
导读¶
通用模型很强,但你的场景需要专属模型。
本章从 RLHF 的经典 PPO 开始,经过 DPO(直接偏好优化)、GRPO(群组相对策略优化),到 Self-Taught RLVR(自我教学的强化学习与验证奖励)。你会看到在线蒸馏 vs 离线蒸馏的数学原理与实战对比,以及 PRISM(ICML 2026 的并行残差迭代序列模型)如何用线性注意力突破 Transformer 瓶颈。
不是每个场景都需要微调——但理解微调能让你选对策略。有时候,一个好的提示词比一个微调模型更有效。
Ch15.001 What I’ve been building: ATOM Report, post-training course, finishing my book, and ongoing research¶
📊 Level ⭐⭐ | 15.2KB |
entities/interconnects-what-ive-been-building-atom-report-post-training-course-finishing-my-book-and-on.md
type: entity - raw/articles/what-ive-been-building-atom-report-post-training-course-fini tags: [interconnects] - article title: 'What I’ve been building: ATOM Report, post-training course, finishing my book, and ongoing research' type: entity updated: '2026-06-08'
type: entity
What I’ve been building: ATOM Report, post-training course, finishing my book, and ongoing research¶
相关实体¶
- Building Blocks For Foundation Model Training And Inference On Aws
- Llm Post Training Full Guide
- Yann Dubois Openai Post Training Interview
- How Harnesses And Post Training Close The Open Weight Bug Finding Gap 20260606
→ 原文存档
What I’ve been building: ATOM Report, post-training course, finishing my book, and ongoing research¶
This post is a roundup of my recent efforts that did not warrant a standalone Interconnects post, why I’m spending time on them, and what they accomplished.
1. The ATOM Report: Measuring the Open Language Model Ecosystem¶
https://arxiv.org/abs/2604.07190
To accompany The ATOM Project memo, arguably a manifesto, making the case for investment in open models in the U.S. – originally launched in August 2025 – we’ve released an updated technical report with our latest data, analysis, and storytelling within the open language model ecosystem. The ATOM Report is dense with the methods Florian and I use to keep track of the open ecosystem. It covers GPT-OSS’s rise, inference market share, the influence of China’s mid-tier players like Moonshot, Z.ai, & MiniMax, signs of the U.S.’s progress on open models, and much more.
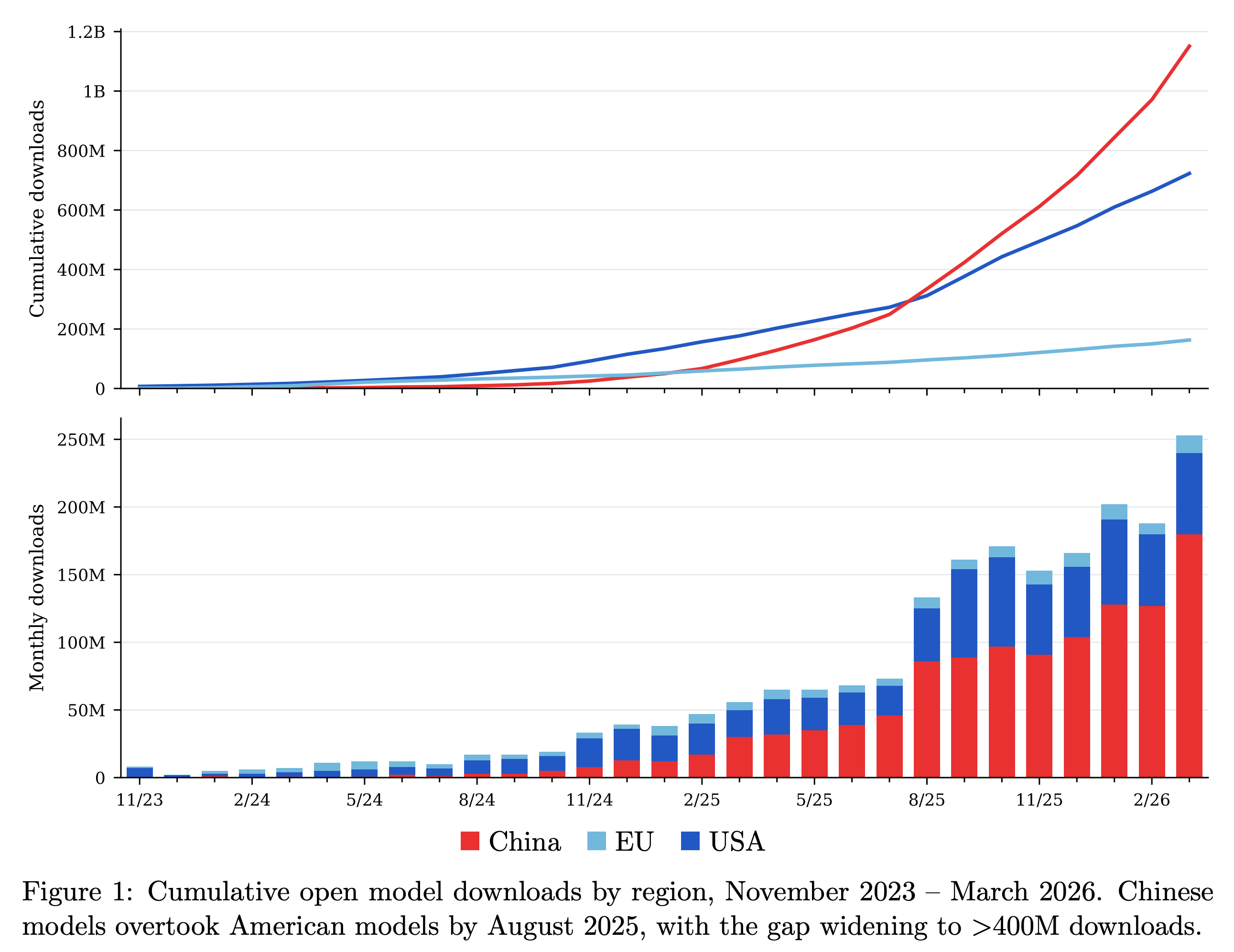{kind=link}
In particular, the paper details our updates to the Relative Adoption Metric (RAM), which we use to evaluate the adoption of recent models in a time-varying and size-normalized manner. Here’s a sampling of recent, primarily Chinese, models on the RAM score. The RAM score is designed so that a score >1 indicates a model is, at that point in time, on track to be a top 10 most downloaded model of its size category, ever. It reduces a messy landscape to one, easily interpretable number!
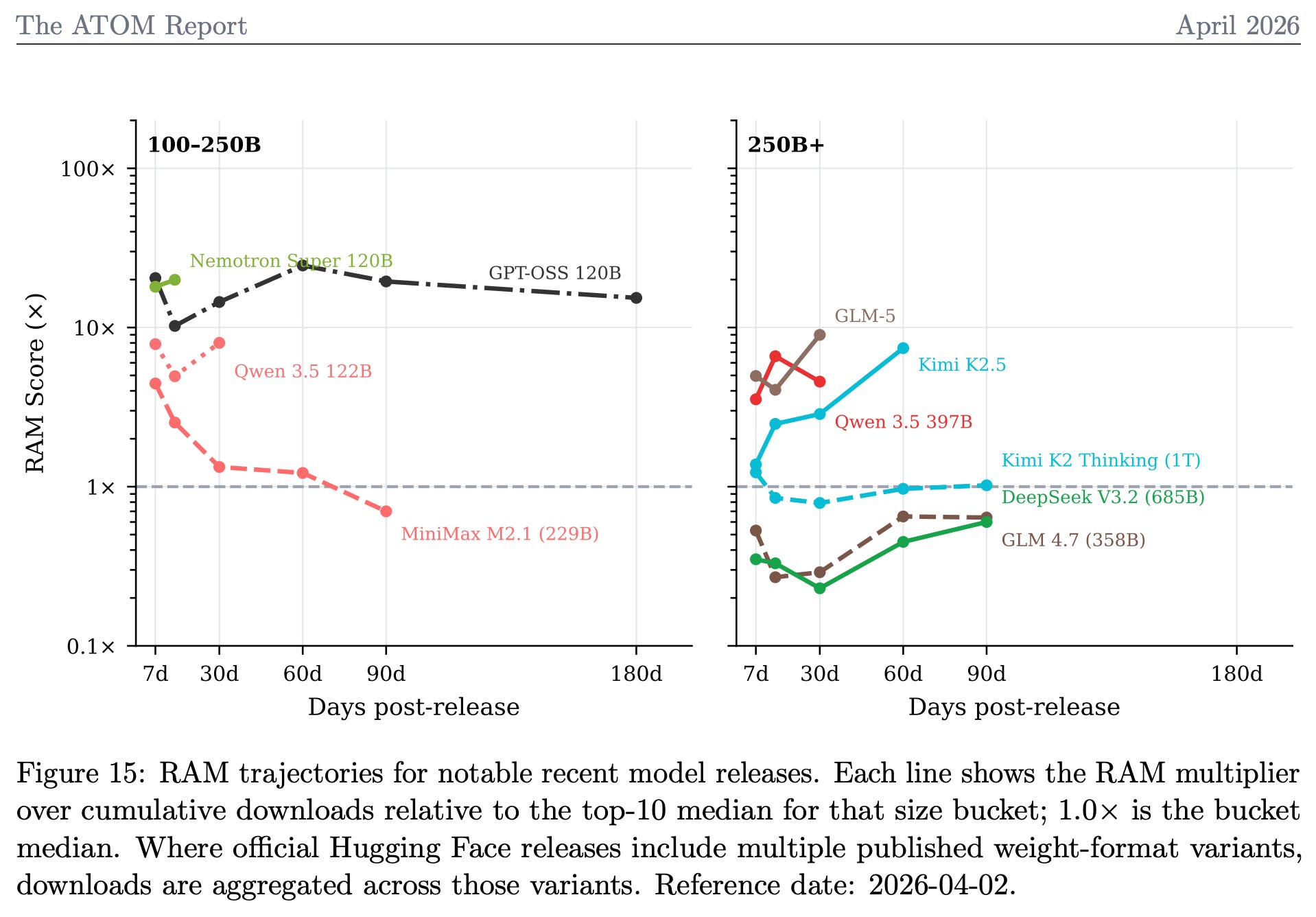{kind=link}
We used the data to also analyze the recent Gemma 4 release, which is showing incredible early adoption numbers. We’ll stay tuned on it!
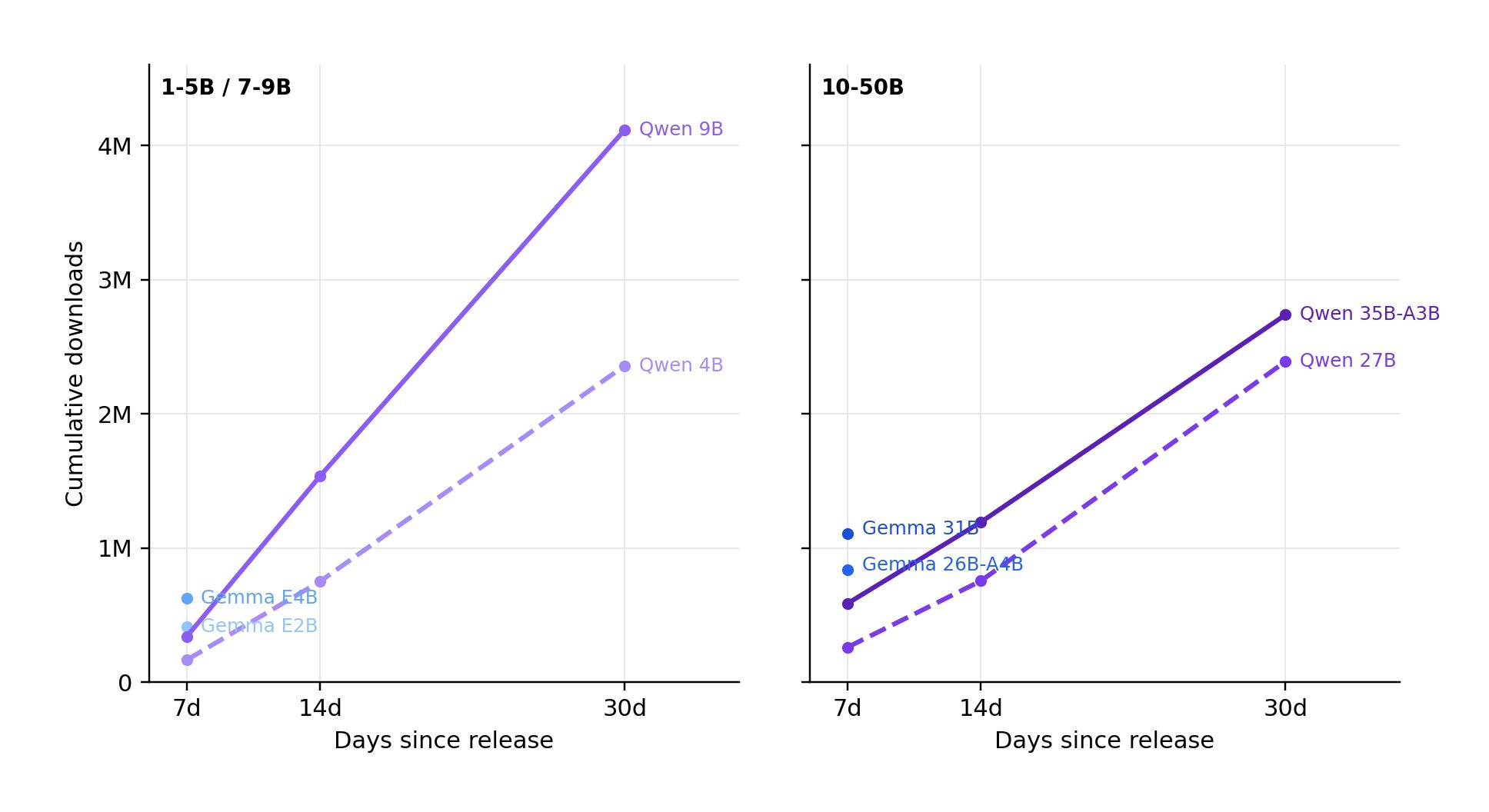{kind=link}
Subscribe to the (infrequent) ATOM Project Substack for more updates like this!
2. RLHF Book is done & ready for pre-order!¶
The goal of this book was to write the book I wished I had when I was getting started in post-training language models. This project has been on my mind for a long time. I bought the domain rlhfbook.com and started to take it more seriously on May 20th, 2024. Here we are!
Last week, it was sent to production with the Manning team. This means content edits are done, and it’ll be sent to print in ~2 months. In the meantime, I’m spending my time developing the accompanying code and course (more on that below).
You can preorder on Amazon or Manning (currently cheaper).
{kind=link}
3. A post-training course I’m making¶
The goal of my book is for it to be the central resource for people looking to transition from beginner to expert in post-training. It’s not necessarily an entry-level book, but as AI models become stronger, it needs to be a community -building effort as well. The first step I’ve made to expand the scope from just a book to a complete learning experience is building a lecture series. The lectures will be freely available on YouTube and incorporate community questions & answers (as standalone videos in between lectures).
You can watch the first batch of videos below, and subscribe on YouTube for future ones. I’m going to build on the book platform more this summer, as I develop the book codebases and host in-person events.
-
RLHF and Post-training Overview | RLHF Book Course, Lecture 1
-
RLHF Foundations, IFT, Reward Modeling, Rejection Sampling | RLHF Course Lecture 2
-
Understanding Policy Gradient Algorithms for RL on LLMs | RLHF Course Lecture 3
{kind=link}
4. Recent technical research¶
Long-time followers of Interconnects know that this blog has its roots in explaining fundamental research in the field. This has immense value in two ways. First, as AI moves incredibly fast, far more people need to be able to parse research to make the right bets on the technology. Research is the only early warning of some big changes coming. Second, it helps uplift the careers of my collaborators – the people I spend my life with! On that note, check out two papers I had the privilege of being part of below.
https://arxiv.org/abs/2603.16759 -TurnWise: The Gap between Single- and Multi-turn Language Model Capabilities ,__ Graf et al. 2026
This work explores the strengths of various models in multi-turn dialogue settings, how to create training data to improve it, and other quirks in post-training. My interests here have fully shifted to agents, where I see multi-turn interactions as a very important user interface problem — what information do I show to the user to solve the task as soon as possible without cutting corners?
https://arxiv.org/abs/2603.11327 - Meta-Reinforcement Learning with Self-Reflection for Agentic Search , Xiao et al. 2026
This paper frames solving hard problems with RLVR as a meta-learning problem, where context from previous attempts should be used to inform future rollouts. It’s a very obvious idea in some ways, where most of RL for LLMs is still very on-policy, but naive. The models learn from recent trials in parameters, but not in context. This research feeds into a ton of other recent work on ways that RL can be formulated to solve different forms of continual learning. Another great related paper is Learning to Discover at Test Time.
I'm off to China (and then hopefully DC) in the next couple of months to learn even more about how the world sees progress in AI. I'm excited to talk to a broader range of people than I tend to in my focused technical job. Thanks for reading, as always!
深度分析¶
开放模型生态的度量框架:RAM 的设计哲学¶
ATOM Report 中提出的 Relative Adoption Metric(RAM)代表了一种关键的方法论转向——将复杂的开源模型生态压缩为单一可解读的数字。Nathan Lambert 在此处透露的设计意图尤为值得关注:RAM > 1 意味着该模型在特定时间点有望成为其尺寸类别中下载量前十的模型。这种设计哲学体现了"时间归一化 + 尺寸归一化"的双重Normalization思路 。
RAM 的核心价值在于它解决了开放模型评测中的一个根本性问题:传统的基准测试分数无法反映模型在真实生态系统中的采用程度,而简单的下载量又会被新模型的时间优势所扭曲。RAM 通过 score > 1 这个单一阈值,将模型的早期采用信号转化为对长期影响力的预测,这对于政策制定者和投资者而言是关键的决策支持工具 。
RLHF 图书作为社区基础设施的战略定位¶
Lambert 将这本书定位为"我刚开始接触 post-training 语言模型时希望能有的书",这一表述揭示了当前 post-training 知识传播的结构性缺口。与传统学术教材不同,这本书从一开始就被设计为社区建设的核心——而非仅仅是一本技术手册 。
这个战略选择反映了更广泛的趋势:当 AI 模型能力足够强时,单个技术的学习曲线开始变得平缓,而围绕技术的社区网络成为新的差异化因素。Manning 的出版模式(纸质书 + 电子书 + 视频课程 + 代码仓库)本质上是在构建一个多模态的学习生态,而非单纯的内容产品。rlhfbook.com 这个域名本身就是一个战略资产——它将品牌与领域核心概念直接绑定,形成了搜索可见性的垄断 。
Post-training 课程的开源与商业混合模式¶
从免费 YouTube 讲座到付费代码库和线下活动,Lambert 的课程设计呈现了一种精心策划的漏斗结构。前端 YouTube 内容承担的是认知触达和社区招募功能,而真正的商业价值在后端的代码库、活动和书籍配套服务中实现。这种模式与 Andrej Karpathy 的 full-stack course 分享了相似的分发逻辑,但更早地嵌入了商业闭环 。
值得关注的是,Lectures 1-4 的内容覆盖了从 RLHF Overview 到 Policy Gradient 实现的全链路,这在免费内容中构成了一套完整的 Mini 课程体系。这种策略的精明之处在于:它将 post-training 的复杂技术栈切割为可独立消费的模块,降低了入门门槛,同时通过社区 Q&A 视频建立了与付费用户的情感连接 。
Agentic AI 研究的 Meta-Learning 转向¶
TurnWise 和 Meta-RL with Self-Reflection 这两篇论文的并列出现,揭示了 2026 年 post-training 研究的一个核心主题:从单轮优化到多轮/持续学习的范式转移。TurnWise 将多轮对话视为一个用户界面问题——如何在保持任务一致性的同时最大化信息效率——这与传统的单轮基准测试形成了鲜明对比 。
Meta-Reflection 论文的核心洞察更具根本性:当前大多数 RL for LLMs 仍然是 on-policy 的,但模型只能从参数层面的最近试验中学习,而无法从上下文层面的历史经验中获益。这篇论文将 RLVR 框架重构为 meta-learning 问题,使得模型能够在推理时利用先前尝试的上下文信息,这对 agentic search 等hard problem 具有特殊的意义 。
中国开源模型的地缘政治维度¶
ATOM Report 对中国中间层玩家(Moonshot、Z.ai、MiniMax)的关注,以及 Lambert 即将访问中国了解 AI 进展的计划,揭示了当前开放模型生态的地缘政治复杂性。开放权重模型的跨境流动正在重塑 AI 供应链,而 ATOM Project 本身(作为支持美国对开放模型投资的备忘录)在这个背景下具有政策倡导的意义 。
实践启示¶
1. 为开放模型项目设计度量标准时,优先考虑时间归一化和尺寸归一化¶
RAM 的设计提供了一个关键参考:不要用原始下载量或原始基准分数来比较跨时间发布的模型。如果你要为自己的模型或项目建立跟踪机制,应该设计一个能在时间维度和尺寸维度上进行标准化比较的指标。score > 1 这个阈值的设计使得跨类别比较成为可能,值得在企业内部评测体系中借鉴 。
2. 将技术图书项目作为社区建设的前期投资¶
Lambert 对 rlhfbook.com 的战略使用——将其作为社区连接的中心节点——表明,一本技术书的商业价值不仅来自内容销售,更来自它所创建的认知入口和信任通道。如果你在考虑撰写一本专业技术图书,应该从第一天就将其视为一个社区基础设施项目,而不仅仅是内容产品。购买域名和建立邮件列表应该在开始写作之前完成 。
3. 用免费内容建立漏斗,用付费服务实现商业闭环¶
Lambert 的课程策略提供了一个可复制的模式:YouTube 讲座承担认知触达,代码仓库和线下活动实现商业价值。对于任何希望建立技术课程的人而言,前 1-2 个 lecture 应该设计为完全独立可消费的内容,作为进入更深层服务的入口。社区 Q&A 视频在 lecture 之间插入,是一个低成本的社区参与机制,值得在在线课程中广泛采用 。
4. 在 Agentic AI 项目中,关注上下文级记忆而非仅参数级学习¶
Meta-RL with Self-Reflection 的核心洞察对 agent 系统设计具有直接指导意义:你的 agent 系统应该能够在上下文中利用历史任务经验,而不仅仅是依赖模型参数中的最新训练信号。在实现 agentic search 或自主研究系统时,考虑在 context window 中引入"失败历史摘要"机制,使模型能够在当前任务中借鉴先前尝试的上下文信息 。
5. 建立开放模型跟踪系统,关注早期采用信号¶
Gemma 4 显示出的"令人难以置信的早期采用数字"提醒我们,对于开放模型而言,发布后头几周的采用数据往往比基准测试更能预测长期影响。如果你负责评估或选择开放模型,应该建立一个系统来跟踪发布后 2-4 周内的下载量、社区讨论度和集成项目数量,而非仅依赖静态基准分数 。
Ch15.002 NVIDIA Blackwell MLPerf Training 6.0 基准测试结果(2026-06)¶
📊 Level ⭐⭐ | 11.2KB |
entities/nvidia-blackwell-mlperf-training-6-0-benchmark-results-2026-06.md
NVIDIA Blackwell MLPerf Training 6.0 基准测试结果(2026-06)¶
摘要¶
NVIDIA 在 2026-06-18 的官方博客中公布 MLPerf Training 6.0 基准测试结果:Blackwell 平台在全部七个基准上都跑出了最快的训练时间,最大规模达到 8,192 GPU(使用 Blackwell NVL72 系统),并且是唯一提交了全套基准结果的厂商。本轮 MLPerf 首次引入 MoE(mixture-of-experts)预训练负载(DeepSeek-V3 671B 与 GPT-OSS-20B),反映了行业向 MoE 架构的全面迁移;NVIDIA 的 NVLink Switch fabric 与 NVFP4 低精度训练方法在 MoE 训练上展现出明显的扩展性优势。
核心要点¶
- MLPerf Training 6.0 引入 MoE 训练基准:新增 DeepSeek-V3 671B 与 GPT-OSS-20B 两个 MoE 预训练负载,反映 MoE 架构在行业中的中心化趋势;NVIDIA 是唯一提交全部七个基准的厂商。
- Blackwell NVL72 架构:单机柜系统由 72 颗 B200/B300 GPU 组成,第五代 NVLink Switch 将全部 72 颗 GPU 通过高带宽互连组成统一计算与内存池,对上层呈现为"一颗巨型 GPU"。
- GB300 NVL72 性能领先 GB200 NVL72 1.6×:相同规模下,Blackwell Ultra 系统在训练时间上相比 Blackwell 快达 1.6 倍,关键能力包括 NVFP4 下的更高算力密度、更大内存容量、以及支持 GPU 维持峰值性能的更高功耗上限。
- 8,192 GPU 的最大训练规模:在 DeepSeek-V3 671B 上,NVIDIA 使用 GB200 NVL72 系统扩展到 8,192 GPU,是本轮 MLPerf Training 最大的 Blackwell 提交;同时在 Llama 3.1 405B 上以 5,120 GPU 提交。
- NVFP4 低精度训练:NVIDIA 在 5,500 亿参数的 Nemotron 3 Ultra 模型上使用 NVFP4 完成预训练,证明 NVFP4 在不同规模预训练与微调上都能满足精度要求。
- 可靠性机制:NVRx(NVIDIA Resiliency Extension)提供故障检测、恢复与健康监控,节点故障时从最近 checkpoint 续训而非重启整个作业;Spectrum-X Ethernet 在毫秒级绕过故障链路。
- 生态合作伙伴广泛参与:本轮提交共 19 家组织,包括 Microsoft Azure、CoreWeave、ASUSTeK、Cisco、Dell、Fujitsu、Google Cloud、HPE、Lambda、Nebius、Supermicro 等。
深度分析¶
MLPerf 6.0 引入 MoE 基准的意义¶
MLPerf Training 6.0 是该套基准首次正式纳入 MoE 预训练负载——DeepSeek-V3 671B 与 GPT-OSS-20B——意味着 MLPerf 联盟承认 MoE 已经成为前沿大模型的事实标准架构。
MoE 训练相比传统 dense LLM 训练,对硬件通信能力提出更严苛的要求:token 必须跨 GPU 路由到对应的 expert 子网络,这就是所谓的 all-to-all 通信挑战。NVIDIA 在博客中明确指出,NVLink 的带宽优势正是让大规模 MoE 训练既快又高效的关键因素,这与 MoE 推理对 NVLink 的依赖逻辑完全相同。
NVLink Switch Fabric:把 72 颗 GPU 视为一颗¶
Blackwell NVL72 的核心创新是第五代 NVLink Switch——它在单机柜内把全部 72 颗 GPU 通过高带宽互连,组成"统一的计算与内存池",对上层应用呈现为单一 GPU。
这一架构对 MoE 训练尤其关键。传统 GPU 集群在 MoE all-to-all 通信时,受限于节点间带宽(InfiniBand 或 Ethernet)以及 PCIe/NVLink 拓扑层级,会出现专家路由瓶颈;NVL72 把所有 GPU 视为一个域,从根本上消除了"节点内 / 节点间"的带宽分层。对于小至 72 GPU 的 MoE 训练 job,这意味着每个 token 的 expert 路由都能在本地 fabric 完成,避免跨节点同步。
GB300 vs GB200:Blackwell Ultra 的代际提升¶
NVIDIA 在同一机柜规模下对比 GB300 NVL72 与 GB200 NVL72:GB300 训练时间最快可降至 GB200 的约 1/1.6(性能提升至 1.6×)。三项关键 Blackwell Ultra 能力共同驱动这一提升:
- NVFP4 算力密度:Blackwell Ultra 在 NVFP4 精度下提供更高算力,对低精度训练更友好
- 扩展的内存容量:更大的 HBM 让更大 batch / 更长 sequence 的训练更高效
- 更高功耗上限:支持 GPU 在更长时段内维持峰值频率,避免 thermal throttling
规模化的实战表现¶
DeepSeek-V3 671B 8,192 GPU 提交是本轮 MLPerf Training 最大规模的 Blackwell 集群。NVIDIA 通过两套互补的横向扩展网络平台支撑这种规模:Quantum InfiniBand 与 Spectrum-X Ethernet,让数据中心可以根据基础设施偏好灵活构建大规模集群。
最佳成绩归属方面: - Microsoft Azure:Llama 3.1 405B 训练在 8,192 GB200 NVL72 上达到参考质量目标用时 7.07 分钟(最快) - CoreWeave:DeepSeek-V3 671B 在 8,192 GB300 NVL72 + Spectrum-X Ethernet 下达到质量目标用时 2.02 分钟(最快)
可靠性作为生产级训练的前提¶
NVIDIA 在博客中用一整节强调 "At-Scale Reliability"。当训练作业跨度数周或数月、覆盖数十万 GPU 时,吞吐量取决于"性能 × 可靠性"——只有结果可复现的快速系统才有生产价值。
NVIDIA 的可靠性机制从两个维度展开:
1. 减少中断: - 出厂前 GPU 经历 30+ 制造测试阶段筛查潜在故障 - 部署后,RAS 引擎(Reliability, Availability and Serviceability Engine)监控几乎整个芯片,自动绕过故障路径 - Spectrum-X Ethernet 在毫秒级重路由故障链路
2. 加速恢复: - NVRx 自动检测并管理表现不佳的节点(不拖累整集群) - 节点故障时,从最近 checkpoint 续训而非重启整个作业
NVFP4 训练:从研究走向 5,500 亿参数规模¶
NVIDIA 在 Nemotron 3 Ultra(5,500 亿参数)上使用 NVFP4 完成预训练,这标志着 NVFP4 已从实验性技术走向生产规模。低精度训练的关键收益是性能,但传统担忧是精度损失——NVFP4 通过数值表示与缩放因子的协同设计,在严格精度要求下仍能保持模型质量。
生态系统的实战案例¶
- Cohere:在 GB200 NVL72 上训练 North agentic AI 平台,速度提升 3×
- Midjourney:v8 图像生成模型在 Blackwell 集群训练,正在 Blackwell Ultra 上扩展大规模机队训练下一代图像与视频模型
- Thinking Machines Lab(Google Cloud):在 GB300 NVL72 上训练与推理速度相比上一代提升 2×
- Higgsfield(Nebius):在 NVIDIA Blackwell / Blackwell Ultra 基础设施上训练时间缩短 30%,平台服务 2,200 万用户、每天生成超 600 万 AI 内容
实践启示¶
- MoE 是训练基础设施的硬需求:当模型架构转向 MoE 后,单机柜 NVLink fabric、跨节点高带宽网络、checkpoint 友好的故障恢复机制成为训练系统的核心能力;规划大规模训练时应优先评估这三项。
- NVLink 域大小直接决定 MoE 效率:把训练 job 控制在 NVL72(72 GPU)单一 fabric 域内可以让 expert 路由免受节点间带宽瓶颈影响;跨域 MoE 训练需要额外的通信重叠与负载均衡策略。
- NVFP4 是下一代低精度训练的实务选项:在大规模预训练中考虑 NVFP4,相比 BF16/FP16 应有显著性能优势,且精度损失可控;微调与对齐任务同样可以受益。
- 可靠性工程是生产级训练的核心竞争力:当训练跨越数周数十万 GPU 时,作业成功率比单次性能更重要;NVRx 类机制(checkpoint 续训、RAS 监控、链路重路由)是必备能力而非锦上添花。
- 横向扩展网络选型影响集群设计:Quantum InfiniBand 与 Spectrum-X Ethernet 是 NVIDIA 提供的两个互补选项,前者适合极致低延迟,后者适合以太网友好型数据中心;MLPerf 结果显示二者都能支撑 8,192 GPU 级 MoE 训练。
相关实体¶
- AWS GRPO RLVR SageMaker — AWS 后训练栈
- Foundation Model Building Blocks — 通用基础组件
- 750B MoE PD 分离推理 EFA vs RoCE — AWS 上的 MoE 推理对比
- Microsoft / GitHub / AWS AI 算力承压 — 超大规模算力承压事件
- MOC
Ch15.003 ICML 2026 | PRISM: Parallel Residual Iterative Sequence Model¶
📊 Level ⭐⭐ | 10.4KB |
entities/icml-2026-prism-parallel-residual-iterative-sequence-model.md
ICML 2026 | PRISM: Parallel Residual Iterative Sequence Model¶
核心洞察:PRISM 揭示了 TTT-MLP 高表达力("步长 × 残差 × 方向"多步迭代)与串行瓶颈是同一根因的两面,通过 anchor 代理消除 token 间串行 + 闭合式预计算消除 step 间串行,实现 TTT 级别质量 × GDN 级别速度。原文存档
问题背景¶
无限背包 vs 有限背包¶
Transformer self-attention O(n²) → 推荐域被迫 cross-attention/截断/压缩,损失长程模式。线性复杂度模型(Linear Attention、RWKV、Mamba、GDN 等)用固定大小状态矩阵 S 压缩历史,O(n) 复杂度,是推荐域更匹配的底层架构。
背包有限,每次写一行(rank-1 外积),多维语义信息压缩时丢失。
Rank-1 写入瓶颈¶
GDN 每步 ΔS = γ · (v · k^T),两个向量的乘积,所有行都是同一方向缩放——相当于整个记忆矩阵只改动"一行"。
TTT 的突破与代价¶
TTT 把 S 升级为 MLP 权重,每 token 做多步 GD,实现 rank-L 写入,质量显著提升。但每步梯度依赖当前权重,打破 parallel scan 前提——实测比 GDN 慢 174 倍。根源不在 FLOPs,而在 HBM↔SRAM 搬运次数从 O(n) 退化到 O(n²)。
关键洞察:高表达力与串行是同一根因的两面¶
驱动"步长 × 残差 × 方向"模式的是权重每步更新——同一根因产生两面: - 正面:方向每步变(width/depth),残差递减(优化深度)→ 高表达力 - 反面:每步更新打破 parallel scan 前提 → 串行瓶颈
三个串行瓶颈¶
- Token 间串行 A:遗忘/写入耦合,recurrence 无法写为线性形式
- Token 间串行 B:残差需读前一个 token 精确状态
- Step 间串行 C(最核心):第 l+1 步方向/残差必须等 l 步更新完——同时是 rank-L 表达力的载体和步间串行根源
PRISM 设计¶
核心迭代形式¶
ΔS = Σ_{l=0}^{L-1} α_l · r_l · u_l · v^T
- α_l: 更新步长
- r_l: 显式残差迭代
- u_l: learned key projection(L 个方向补回 TTT-MLP hidden layer 提供的多方向)
- v: 基础方向
- 第一步自然退化为 GDN 标准写入
消除 Token 间串行¶
- 遗忘/写入分离:遗忘项与 GDN 一致,非线性操作限写入项内
- 局部 Anchor 代理:ShortConv 计算局部历史状态替代全局 S,token 间迭代同时启动
- 复用 Mamba scan kernel
消除 Step 间串行¶
- Direction chain 解耦:anchor 预先给定,所有 L 方向同时算出
- Residual chain 线性化:GELU 吸收进 preconditioner,迭代退化为纯 element-wise 线性递推,闭合式单步计算
架构全貌¶
ΔS = ΔS_gdn + ΔS_residual(GDN + 非线性修正项)
L=1 时精确退化为 GDN。后续步以不到 10% 参数增量叠加低秩修正。
实验结果¶
序列推荐(Amazon 基准, 16K 序列长度)¶
| 模型 | Books H@200 | Movies H@200 | Elec H@200 | Throughput |
|---|---|---|---|---|
| GLA | 0.0879 | 0.1193 | 0.1196 | 57.4K tok/s |
| GDN | 0.1214 | 0.1241 | 0.1333 | 57.2K tok/s |
| TTT | 0.1255 | 0.1288 | 0.1344 | 0.34K tok/s |
| PRISM | 0.1258 | 0.1411 | 0.1409 | 57.3K tok/s |
| HSTU (Transformer) | 0.1224 | 0.1399 | 0.1407 | 18.2K tok/s |
- PRISM 质量接近 Transformer,超大多数线性注意力方法
- 吞吐量比 TTT 快 174 倍,与 GDN 同级
语言建模(SlimPajama 2B tokens, 130M 参数)¶
PRISM 在 WikiText PPL、LAMBADA PPL、9 项 Zero-Shot 平均准确率上均最优,领先 GDN 3.2%。
消融:rank-L 的真实价值¶
- 单步 solver (L=1) 训练 PPL ≈ 完整版,但 Avg ACC 跌 2.9 个百分点
- rank-L 价值不在 next-token prediction,而在精确长程检索
- Shared-K vs base-K:solver 复用 GDN base key 则大幅退化(-1.5)→ solver 需独立方向空间
混合架构是必然¶
PRISM 用 ShortConv(窗口 3-4 token)近似残差,跨数千步长程依赖近似质量必然下降。穿插 Transformer 层后,后者充当全局非线性历史状态精确计算器——补偿 anchor 近似误差。
Transformer 就是 ShortConv anchor 的全局升级版:前者精确算,后者近似算。
这解释了 Jamba、Zamba、Griffin 等最强长序列模型均用混合架构的原因:有限背包(O(n) 高速+压缩)+ 无限背包(精确长程检索)在架构层面互补。
线性注意力的 LoRA¶
PRISM 结构"基础迭代 + low rank 旁路"与 LoRA 形式相似——启发了线性注意力/SSM 的参数高效微调: - 冻结基础迭代,写入支路加 PRISM 残差旁路 - 第一步退化为原模型标准写入(不破坏预训练知识) - 闭合式(不增加训练时间) - 满足 LoRA 两个关键要求:参数高效 + 不损害原模型能力
与 TTT-MLP 的对应关系¶
| TTT-MLP(隐式) | PRISM(显式) |
|---|---|
| hidden layer 提供方向 | learned key projection |
| 更新步长 | α_l 更新步长 |
| 随 W₂ 更新递减的残差 | 显式残差迭代 r_l |
| 方向残差同步耦合(不可并行) | 方向残差解耦(可并行) |
深度分析¶
1. 高表达力与串行是同一根因的两面——PRISM 找到了解耦路径
TTT-MLP 的"步长 × 残差 × 方向"多步迭代带来高表达力,但方向与残差的同步耦合使 step 间必须串行执行。PRISM 的核心贡献是发现:方向和残差可以解耦——方向通过 anchor 预计算(可并行),残差通过 GELU preconditioner 线性化(闭合式单步计算)。 这将同一算法的表达力与并行性分离,为 SSM/线性注意力的深度迭代开辟了新方向。
2. 174 倍吞吐量提升验证了"串行是瓶颈根源"的诊断
TTT 慢 174 倍的根本原因不是 FLOPs,而是 HBM↔SRAM 搬运次数从 O(n) 退化到 O(n²)。 PRISM 在消除 step 间串行的同时保持 TTT 级别的 rank-L 表达力,吞吐量与 GDN 同级——这验证了"串行是 TTT 速度瓶颈"这一诊断的准确性。
3. 混合架构不是过渡方案,而是长序列模型的终态架构
PRISM 用 ShortConv 计算局部 anchor,短卷积窗口只覆盖 3-4 token,跨数千步长程依赖近似质量必然下降。穿插 Transformer 层后,后者充当"全局精确历史状态计算器"补偿 anchor 误差。 这不是工程妥协,而是有限背包(O(n) 高速 + 压缩)与无限背包(精确长程检索)在架构层面的自然互补。
4. LoRA 形式类比揭示了参数高效微调的新方向
PRISM 的"基础迭代 + low rank 旁路"结构与 LoRA 形式完全对应:冻结基础迭代叠加 PRISM 残差旁路,第一步退化为原模型标准写入(不破坏预训练知识),且闭合式计算不增加训练时间。 这为线性注意力/SSM 模型的参数高效微调提供了新的理论基础。
实践启示¶
- 推荐系统场景:PRISM 在 16K 序列上直接可用,质量匹配 Transformer 但吞吐量是其 3 倍+
- 混合架构优先:PRISM 层 + 少量 Transformer 层 > 纯 PRISM(补偿长程锚点近似误差)
- 参数高效微调:PRISM 形式天然适配 LoRA 式微调,冻结基线 + 残差旁路
- 不是纯 Linear Attention 的终结:混合架构(有限+无限)可能才是长期路线
相关实体¶
- Olmo Hybrid and the Hybrid Architecture Wave (2026) — 同一架构趋势下 GDN 3:1 混合的工业实践
- 最新开放模型快照 — Nemotron 3 Nano 线性架构对比
→ 原文存档
Ch15.004 SFT+DPO 双阶段微调:Qwen3-1.7B Tool Calling 精度提升方案¶
📊 Level ⭐⭐ | 9.2KB |
entities/aws-sagemaker-sft-dpo-tool-calling.md
SFT+DPO 双阶段微调:Qwen3-1.7B Tool Calling 精度提升方案¶
原文存档:原文存档
Core insight: 通过 NVIDIA When2Call 数据集进行 Spectrum SFT 后再进行 DPO 偏好优化,Qwen3-1.7B 的 tool calling 精度从 41.57% 提升至 71.06%,超越参数量为其 2 倍的 Llama 3.2 3B;SFT 建立基础能力,DPO 在偏好数据上进一步校准输出分布
SFT 与 DPO 方法对比¶
Supervised Fine-Tuning(SFT)通过高质量的明确示例教模型识别 tool-specific 语言、命令和约束,数据集(When2Call)包含 15,000 个 SFT 样本,每个样本包含可用工具列表和对话消息序列。Direct Preference Optimization(DPO)将人类反馈或预定目标直接融入训练循环,数据包含"优于这个、劣于那个"的偏好对(chosen/rejected),在不引入 reward function 或 reward model 的情况下实现与 RL 相当的目标对齐效果,显著降低资源需求和训练时间。
SageMaker ModelTrainer 分布式训练架构¶
训练通过 SageMaker Python SDK ModelTrainer API 启动完全托管的训练集群,自动处理环境配置、弹性扩展和制品管理。Compute 配置使用 ml.p4d.24xlarge(8× NVIDIA A100),通过 Hugging Face Accelerate 和 DeepSpeed ZeRO-3 在多 GPU 间高效分片模型权重、梯度和优化器状态。SFT 使用 80% 阈值 CloudWatch 告警机制触发 Lambda Quota Calculator,结合 EventBridge 定时器实现动态阈值管理,完整流程与 Bedrock Ops Alert 一致。
双阶段训练配置与效果¶
第一阶段 Spectrum SFT 配置:Qwen3-1.7B,bf16 + flash_attention_2,learning_rate 5e-5,cosine scheduler,warmup_ratio 0.1,per_device_batch_size 4,gradient_accumulation_steps 2,max_seq_length 2048,packing=true。第二阶段 DPO 在 SFT 模型基础上继续:beta=0.1(控制偏好采纳激进程度),learning_rate 大幅降低至 5e-7,warmup_ratio 0.03,max_length 1536,max_prompt_length 768,loss_type=sigmoid,per_device_batch_size 2,gradient_accumulation_steps 8。
实验结果与关键数据¶
在 NVIDIA When2Call 评测集上,Qwen3-1.7B Base 精度 41.57%,经 Spectrum SFT 后提升至 60.43%(+19%),再经 DPO 后达到 71.06%(+10.5%),总计提升 30%。对比其他模型:Llama 3.2 3B Base 46.50% → SFT+DPO 62.67%;Qwen3-0.6B Base 47.64% → SFT+DPO 62.02%。Qwen3-1.7B SFT+DPO 最终领先 Llama 3.2 3B 约 8-9 个百分点,而参数量仅为后者一半,推理成本显著更低。
关键数据/实践启示¶
- When2Call 数据集:15,000 SFT 样本 + 9,000 DPO 偏好样本 + MCQ/LLM-as-Judge 测试集
- DPO beta 超参典型范围 0-2,越接近 0 越激进,越接近 2 越保守,默认 0.1-0.5 区间效果好但可能导致高方差
- DPO learning_rate 需显著低于 SFT(5e-7 vs 5e-5),配合 warmup_ratio 防止过拟合
- Qwen3-1.7B 经完整双阶段微调后精度达 71.06%,超越参数多一倍的 Llama 3.2 3B(62.67%)
- MLflow on SageMaker 集成实现训练指标追踪,keep_alive_period_in_seconds=3600 避免训练集群提前销毁
- 分布式训练:Accelerate + DeepSpeed ZeRO-3 组合实现多 GPU 高效并行
深度分析¶
1. SFT→DPO 两阶段的协同效应¶
SFT 和 DPO 不是替代关系而是互补关系:SFT 教模型"应该做什么"(给定工具列表和对话,正确选择和格式化工具调用),DPO 教模型"不应该做什么"(在多个合理输出中,偏好正确格式/参数而非错误格式/参数)。实验数据验证了这一互补性:SFT 单独提升 19%,DPO 在 SFT 基础上再提升 10.5%——DPO 的增量虽小于 SFT,但它优化的是 SFT 难以覆盖的边界情况(如参数微调、格式偏好)。
2. Qwen3-1.7B 超越 Llama 3.2 3B 的效率意义¶
1.7B 参数超越 3B 参数约 8-9 个百分点,意味着推理成本降低约 44%(参数量减半)而精度更高。这对生产部署的影响是双重的:更小的模型可以在更便宜的 GPU 上运行(如 T4 vs A100),且推理延迟更低(对 agentic 场景中连续 tool calling 的用户体验关键)。但需注意这一结论仅限于 tool calling 任务——在通用能力上 Qwen3-1.7B 仍弱于 Llama 3.2 3B。
3. DPO beta 超参的敏感性¶
beta=0.1 是一个相对保守的设置,控制 DPO 对偏好数据的采纳激进程度。beta 过高(>1)会导致模型忽略偏好信号、退化为 SFT 模型;beta 过低(<0.05)会导致模型过度拟合偏好数据、产生高方差输出。0.1-0.5 区间是实践中最常见的甜蜜点,但具体值需要针对数据集做网格搜索——这与 Deepseek V4 Training Methodology 中 DeepSeek 对 DPO 超参的精细调校经验一致。
4. When2Call 数据集作为 tool calling 标准基准¶
NVIDIA When2Call 数据集(15K SFT + 9K DPO)正在成为 tool calling 微调的事实标准。其优势在于:(a) 覆盖多种工具类型(API、数据库、搜索引擎);(b) 包含 negative examples(何时不应调用工具);(c) DPO 偏好对由 LLM-as-Judge 生成,降低人工标注成本。但局限性在于场景偏英文、偏简单工具——对多语言、复杂工具链的场景可能不够。
5. SageMaker 托管训练降低了微调门槛但锁定生态¶
SageMaker ModelTrainer API 将分布式训练配置(DeepSpeed ZeRO-3、gradient checkpointing、混合精度)封装为声明式配置,显著降低了从零搭建训练集群的门槛。但代价是 AWS 生态锁定——训练数据需在 S3、实验追踪用 MLflow on SageMaker、推理部署在 SageMaker endpoint。对需要多云或本地部署的团队,HuggingFace TRL + 自建集群是更灵活的替代路径。
实践启示¶
1. Tool calling 微调:SFT 先行、DPO 精调¶
不要跳过 SFT 直接做 DPO。SFT 建立 tool calling 的基础能力(识别工具、格式化参数),DPO 在此基础上优化边界情况。两阶段的总提升(30%)远大于任一阶段单独。
2. 小模型 + 精调 > 大模型 + prompt engineering¶
当任务聚焦(如 tool calling)时,1.7B 精调模型可以超越 3B base+prompt 模型。评估精调投资时,将推理成本节约(约 44%)纳入 ROI 计算,而非只看训练成本。
3. DPO 超参:从 beta=0.1、lr=5e-7 开始¶
DPO 的 learning_rate 应比 SFT 低 1-2 个数量级(5e-7 vs 5e-5),beta 从 0.1 开始。这是 TRL 社区经验验证的默认起点,偏离时先做小规模验证再全量训练。
4. 评估 tool calling:不要只用准确率¶
tool calling 的评估需要多维度:工具选择准确率、参数格式正确率、参数值准确率、何时不应调用的判断力。When2Call 的 MCQ + LLM-as-Judge 组合是一个起点,但生产级评估应加入你自己的工具集和错误模式。
5. SageMaker 用户:利用 keep_alive_period 避免调试期的集群回收¶
SFT→DPO 两阶段之间可能有数小时的调试和评估间隙。设置 keep_alive_period_in_seconds=3600 保持训练集群活跃,避免重复等待集群启动(约 10-15 分钟)。
相关实体¶
- Aws Reinforcement Fine Tuning Llm As Judge
- Aws Sagemaker Ai Agent Guided Workflows Finetuning
- Build Real Time Voice Applications With Amazon Sagemaker Ai
- Agent Reliability Context Drift Tool Hallucination
- MOC
相关引用¶
→ 原文存档
Ch15.005 xai解散但grok还没死马斯克声称新模型正在训练¶
📊 Level ⭐⭐ | 6.9KB |
entities/xai-dissolved-grok-colossus2-analysis.md
事件概述¶
2026年5月6日,马斯克官宣xAI解散并入SpaceX,更名SpaceXAI。一天后,他把Colossus 1全部算力(约22万GPU,300+兆瓦)租给Anthropic。再一天后(5月8日),他发推反驳社区里的Grok死亡论,强调Colossus 2正在同时训练多款新Grok。 xAI 2023年7月成立,估值从0冲到2500亿美元只用了不到三年。然而,这家曾经被寄予厚望的AI公司,在短短不到三年后便以解散告终。
深度分析¶
四重危机:xAI解体的深层原因¶
xAI的解体并非突发事件,而是多重问题叠加的必然结果。 第一,烧钱速度远超融资能力。 xAI 2025年月烧10亿美元,前9个月消耗现金80亿美元,Q3单季净亏损14.6亿美元,全年预计亏损约130亿美元。尽管2025年融到200亿美元股权资金,估值2300亿美元,但单独融资的边际成本越来越高。并入SpaceX后,整个集团总估值达1.25万亿美元,融资能力直接上一个量级。 第二,模型差异化窗口已经关闭。 Grok 1到Grok 4一路推下来,benchmark上有小幅追赶,但企业市场和开发者市场始终没拿下。最强功能锁在300美元/月的SuperGrok Heavy里,核心卖点是实时接入X的数据——这更像一个社交媒体附属品,不是一个能改变世界的AI平台。对比之下,Claude Opus在SWE-bench Verified拿到80.8%,驱动着Cursor、Windsurf、Claude Code整个开发者工具链;Gemini 3.1 Pro在GPQA拿到94.3%。 第三,核心团队全员离职。 2025年2月起xAI核心成员陆续离开,到2026年3月底,最后一位创始团队联合创始人离职,创始团队全员清零。一家AI模型公司失去了核心研究团队,单纯靠资本和算力很难维持竞争力。 第四,GPU利用率只有11%。 The Information在2026年4月披露,xAI虽然囤了大约55万张GPU,实际利用率只有11%。对比Meta约43%、Google约46%的利用率,xAI的实际在用GPU只有约6万张,44万张闲置。更严重的是,内部研究员有时会故意重复跑同一个训练实验,目的是人为拉高MFU数字。
Colossus算力代差:战略层面的精明算计¶
马斯克在5月7日把Colossus 1租给Anthropic,5月8日又宣布Colossus 2在训新Grok。这两件事放在一起看,逻辑非常清晰:送给Anthropic的是上一代算力(Hopper卡),自己留下的是下一代(Blackwell主力)。 Colossus 1的GPU构成是20万张Hopper + 3万张Blackwell。GB200单卡FP8算力大约是H100的2.5倍,再加上NVL72机柜内联带宽的优势,整体训练效率比Hopper集群高一个量级。最新一代旗舰大模型(Opus 4.7、GPT-5.5、Gemini 3.1 Pro)的训练算力来源已经全面切换到Blackwell,再用H100训练前沿模型等于用上一代芯片打次代竞争。 Colossus 2从一开始规划成全Blackwell架构,初期目标部署11万张GB200,最终目标350K GPU,配套世界最大规模的Tesla Megapack电池备份。Hopper卡再过两三年就要面临大幅折旧,与其闲置不如租出去换战略合作权和现金流——这是非常精明的算力腾挪。
Grok的产品定位转型¶
5月8日之后,Grok的位置已经从独立公司的旗舰产品,转换为SpaceXAI的内部业务线。它不再需要承担为xAI公司估值续命的任务,可以更专注做产品和模型本身——这反而可能是一种解脱。 Grok对马斯克而言有三个战略价值:X平台AI能力的核心支柱、与Anthropic合作的战略筹码、以及和OpenAI持续博弈的商业筹码。 但Grok要真正「不死」,必须解决一个核心工程问题:GPU利用率从11%到接近Meta的43%是一道工程坎。这道坎不是硬件能解决的,需要网络协议、调度系统、训练框架层面的工程能力——这些不是钱和GPU能在短期内堆出来的。
实践启示¶
1. 算力资产需要战略规划而非囤积。 xAI囤了55万张GPU但利用率只有11%,实际产能约等于6万张。算力竞争的本质不是谁的GPU多,而是谁能高效运转这些算力。企业建设AI基础设施时,需要同步考虑调度能力、网络架构和训练框架,否则大量算力会成为沉默成本。 2. AI公司的护城河不能只靠资本和算力。 xAI拥有顶级资本和算力,但团队失血、差异化窗口关闭后依然难以维系。这说明AI公司的核心竞争力最终要落到人才和产品上——模型可以买,但研究团队和产品迭代能力不能速成。 3. 蹭热点式的产品定位难以持久。 Grok的核心差异化是「反woke」,但这个标签在企业采购市场几乎不被认可。AI产品需要找到真正影响用户决策的核心场景,而不是依赖文化标签吸引眼球。 4. 并购整合是AI格局重塑的常态路径。 xAI并入SpaceX后获得1.25万亿美元估值背书,融资能力大幅提升。在AI竞争日益激烈的背景下,单打独斗的AI创业公司面临巨大的资金压力,被大厂整合可能是更务实的出路。 5. 基础设施代差需要提前布局。 Blackwell已经是最新一代旗舰模型的标配,Hopper正在快速折旧。企业如果还在基于上一代芯片规划AI战略,需要尽快评估迁移路径和时间窗口。
相关实体¶
- Xai Shutdown Grok Still Alive
- Xai Grok Musk Training New Model Wechat
- Video Agent Paradigm Compute Talent Flywheel Ethan He 20260606
- 奥特曼最险一战 前女Cto当庭翻脸 Openai权斗彻底打到台前 6Bf26E92E29B
- Jury Dismisses All Claims In Elon Musk S Lawsuit Against Ope
→ 原文存档
Ch15.006 Notes on pretraining parallelisms and failed training runs.¶
📊 Level ⭐⭐ | 5.7KB |
entities/notes-on-pretraining-parallelisms-and-failed-training-runs.md
核心要点¶
- 评分:v=7 × c=9 = 63
- 来源:dwarkesh
相关实体¶
- Building Blocks For Foundation Model Training And Inference On Aws
- Gemma 4 Qat Models Optimizing Compression
- How Harnesses And Post Training Close The Open Weight Bug Finding Gap 20260606
→ 原文存档
深度分析¶
因果性破坏(Causality Breaking)¶
专家路由中的因果破坏是当前 MoE 训练失败的核心原因之一。在专家路由中,Token 分配本应在严格因果顺序下进行,但 Expert Choice 机制允许后续 Token 的路由决策反向影响先到 Token 的分配结果。这导致训练阶段看到的梯度分布与推理阶段实际运行时不一致。 Token Dropping 的危害:某些专家在处理批次时忽略排名不强的 Token以节省计算资源,但这同样打破了因果性——后续更匹配的 Token 可能导致早期 Token 被忽略。这种偏差在大规模训练中会系统性累积。
数值精度问题:比方差更危险的偏差¶
FP16 在集合运算(All-Reduce)中的精度问题揭示了一个反直觉的事实:偏差(Bias)比方差(Variance)危害更大。方差不论正负,最终可以通过均值化消除;但偏差会系统性叠加,最终导致模型参数严重偏离真实值。 GPT-4 训练初期的一个致命 Bug 正是源于此:FP16 的尾数位在数值较大时精度骤降,当多个小梯度累加到 1024 及以上时,相邻可表示间隔扩大到多个整数值,导致累加结果被截断回原值。这个 Bug 极难发现,因为梯度值在 1024 以下时表现完全正常。
并行策略的权衡框架¶
Horace He 的讲座提供了一个清晰的决策链条:
- FSDP 是默认首选:因为 weight all-gather 与计算可完全 overlap,通信与计算可以隐藏
- FSDP 的通信开销:看似昂贵的 all-gather(每层 forward + backward 各一次)实际只相当于 vanilla DP 50% 的额外开销,因为 all-gather 成本是 all-reduce 的一半
- FSDP 的失效场景:
- 当 GPU 数量增加导致 compute time 下降速度快于 comms time 时,MFU 崩塌
- 当 batch size 过小(单序列 token 数 × 序列数低于临界值)时,无法充分利用数据并行
流水线并行的新问题¶
流水线并行在解决 FSDP 局限的同时引入了气泡(Bubbles)问题:由于梯度聚合与权重更新必须在下一批次开始前完成,前序层和后序层 GPU 在批次交接处必然存在空闲时间。此外,流水线打破了跨层的残差连接设计(如 Kimi 的 attention-to-residuals),限制了对模型架构的探索。
RL 推理与用户推理的本质差异¶
在 RL 生成推理中,训练引擎与推理引擎之间的数值漂移会引入微妙的 Off-Policy 偏差,这对高质量训练影响巨大,但在纯用户推理场景中不成问题。这提示基础设施团队不能简单复用同一套推理优化。
实践启示¶
- 建立严格的数值精度审计流程:在所有 All-Reduce 和 All-Gather 关键路径上增加精度校验节点,特别是当梯度累加值跨越 1024 等 2 的幂次边界时。
- MoE 训练优先选择 Token Routing 而非 Expert Choice:虽然 Expert Choice 能保证专家间负载均衡,但因果破坏的代价远超预期。如需负载均衡,考虑在训练后期切换策略。
- 并行策略的切换阈值应公式化:利用 MFU 公式计算 comms/compute crossover,批量大小和模型稀疏度都会影响切换点位置。盲目增加 GPU 而不调整并行策略会导致算力利用率断崖式下降。
- 内核工程不可完全依赖自动化:即使是最好的 AI 辅助工具,在新硬件架构(如 Blackwell)上的内核优化仍需要顶级工程师的领域知识积累。RL 自动化方法可能在已有成熟架构上有效,但无法完全替代硬件特定优化。
- 多计算因子叠加时必须逐项校验:累积多个 compute multiplier 时,每一步都需要独立验证偏差引入风险。系统性的 Process Discipline 是防止 subtle bias 累积的唯一防线。
- RL 推理系统需独立于用户推理系统构建:两者对数值漂移的敏感度完全不同,不应共用基础设施。
Ch15.007 不用人类手写训练框架了!AI自己写代码,训出1B端侧「小钢炮」¶
📊 Level ⭐⭐ | 5.7KB |
entities/minicpm5-1b-forgetrain-machine-heart.md
不用人类手写训练框架了!AI自己写代码,训出1B端侧「小钢炮」¶
来源:机器之心(2026-05-26)| 原文存档:原文存档
深度分析¶
本文报道面壁智能于 2026 年 5 月 25 日开源 MiniCPM5-1B 端侧文本模型及 ForgeTrain 训练框架。核心看点:1B 参数模型刷新 AA-Index 小尺寸模型榜单(17.9 分,超越 Qwen3.5-2B 的 16.3 分);ForgeTrain 是全球首个完全由 AI 编写并投入生产使用的大模型训练框架,标志着「AI 制造 AI」从算法研究进入基础设施粒度的真实验证。
MiniCPM5-1B:智能密度的新纪录¶
面壁自 2024 年 2 月起持续迭代 MiniCPM 系列,本次发布的 MiniCPM5-1B 在 AA-Index 上以 1B 参数取得 17.9 分,位列小尺寸模型第一,超越所有 2B 以下模型。相比 3 个月前的 Qwen3.5-2B(16.3 分),参数量减少一半但分数更高。
核心验证了面壁提出的密度定律:大模型的智能密度以约每 3.5 个月翻一番的速度持续提升。更小的模型正在承载更高的智能密度。
部署规格: - FP16:约 2GB,适合 GPU 高端笔记本和服务器 - INT8:约 1GB,几乎无性能损失,覆盖主流笔电和边缘计算盒子 - INT4/Q4:仅 0.5GB,手机、平板、车机都能跑 - 支持纯 CPU 运行和浏览器部署
ForgeTrain:AI 自己写的生产级训练框架¶
ForgeTrain 是全球首个完全由 AI 编写的生产级大模型训练框架(类 Megatron),构成它的每一行代码没有人类工程师参与。
关键特征: - 使用 Harness + Agent Loop 技术,Agent 一旦开始编写代码,无需人类介入 - 需要处理分布式训练、并行策略、显存管理、通信效率、算子调用、硬件适配和训练稳定性——任何细节出错都可能让一次预训练消耗大量算力
性能结果: - 英伟达 H100 GPU 上,训练效果与 Megatron 对齐,速度领先 10% - 华为昇腾适配:相比 MindSpeed 有 10% 加速 - 同等算力下训练成本降低约 10%
这标志着「AI 制造 AI」从算法层面(AutoResearcher 等)进入生产级基础设施粒度的真实验证。
「锻造工程」(Forge Engineering)范式¶
ForgeTrain 背后是面壁首创的 Forge Engineering 软件范式:不是维护一个通用框架,而是让 AI 为每一款芯片、每一个模型「现场锻造」出专属的高效软件。
这一范式对国产芯片生态有特殊意义:未来国产芯片的软件生态或许不再需要完全依赖人力去一点点修补和追赶,而可以由 AI 快速「锻造」出来。
UltraData:模型变小后,数据质量变得更关键¶
面壁同步开源了高质量预训练数据集 UltraData(含 Ultra-FineWeb-L3)。面壁建立了 L0-L4 分级数据治理体系,对高知识密度的中文网页、英文网页和数学语料进行大量数据合成。
判断:单纯扩大数据规模的边际收益在下降,模型能力的提升越来越依赖数据质量而非数据数量。对 1B 级模型来说,什么数据进入训练集、数据如何配比、低质量数据如何剔除,直接影响最终能力。
与现有 MiniCPM 体系的关系¶
面壁 MiniCPM 系列演进: - 2024 年 2 月 MiniCPM 2.4B 超越 Mistral-7B - MiniCPM 3.0:4B 超越 GPT-3.5,量化后仅 2GB - MiniCPM 4.0:稀疏架构,22% 训练开销追平 Qwen3-8B,600 Token/s 极速推理 - MiniCPM5-1B:1B 体量超越所有 2B 以下模型,Base Model 由 ForgeTrain 锻造
MiniCPM5-1B 的特殊之处: 1. 能力更强,用 1B 体量实现对同级甚至更高级模型的性能超越 2. 出身不同,其基座模型版本由 AI 自己编写的训练框架 ForgeTrain 锻造而成
实践启示¶
- 关注端侧模型的智能密度趋势:1B 模型已经开始超越 2B 模型,密度定律意味着更小的模型会越来越强。在选型时不应只看参数大小,要看智能密度。
- ForgeTrain 验证了 AI 编写生产级系统软件的可行性:Harness + Agent Loop 可以替代人类编写分布式训练框架,且 10% 的性能优势在预训练规模上有显著成本意义。
- 国产芯片适配有新路径:Forge Engineering 范式可能让 AI 快速为每款国产芯片锻造配套软件,降低对人力维护的依赖。
- 小模型的数据质量是关键:1B 级模型的训练数据质量(筛选、配比、去噪)比大模型更关键,需要系统性的数据治理体系。
- 端侧部署生态已成熟:INT4/Q4 仅 0.5GB、手机平板车机都能跑,支持纯 CPU 和浏览器部署,门槛已大幅降低。
相关实体¶
→ 原文存档
Ch15.008 untitled v2¶
📊 Level ⭐⭐ | 4.9KB |
entities/untitled.md
深度分析¶
将后训练方法置于"分布 reshaping"的框架下审视,为理解 SFT、RL 和 On-Policy Distillation(OPD)之间的本质差异提供了统一的几何直觉。SFT 通过交叉熵将模型拉向一个固定的外部数据集分布,这一过程等价于最小化前向 KL 散度。由于前向 KL 具有"覆盖所有模式"的特性,当目标分布与模型原始分布相距甚远时,模型会被迫在广泛区域内做出均匀的梯度更新——既包括与新任务相关的 token,也包括风格类 token 和语法类 token——从而产生灾难性遗忘。这一分析将 SFT 的常见失效模式置于了严格的理论基础上,而非仅停留在经验观察。 See also Harness Engineering
RL 与 OPD 之所以表现出更强的抗遗忘能力,关键在于两者的训练都基于 on-policy 数据:模型从自身当前策略中采样,然后根据 reward 或 teacher 信号更新参数。Shenfeld et al. 的理论工作揭示,在每一步 policy gradient 更新中,RL 实际上是在拟合当前策略邻域内最近的"最优策略"——即所有满足"所有轨迹 reward 均为 1"这一条件的策略中,与当前策略 KL 散度最小的那个。这意味着 on-policy 约束天然地将更新方向限制在模型已经高频访问的区域,隐式地实现了类似 KL 正则化的效果。这一几何视角解释了为何 OPD 的学生模型即使蒸馏自表现较差的 SFT teacher,也能继承远比 teacher 更少的遗忘——因为学生是在自身分布上学习,而非在 teacher 的外部数据分布上。
关于 OPD 学生为何能超越 teacher本身,一个重要因素在于蒸馏监督的靶向性。传统蒸馏中,学生仅接收 teacher 生成的轨迹;但在 OPD 中,teacher 对学生自己生成的前缀提供建议,这意味着监督信号恰好落在学生实际需要改进的区域。此外,KL 匹配并非 reward 最大化——teacher 的 logit 分布携带了关于风格、不确定性、替代延续和推理结构的信息,匹配这些信息可以改善学生的采样行为,即使 teacher 贪婪采样的输出本身并不更优。将这一现象放在分布塑造的视角下理解比逐 token 分析更具启发性:学生实际上是在扩展其分布中高 reward 区域的概率质量,而非简单复制 teacher 的具体轨迹。
当前主流的 post-training 流水线(Pre-train → SFT → RL → OPD)中,Math 和 Code 任务普遍偏好 RL,而创意写作和知识密集型基准则更多受益于自蒸馏或蒸馏类方法。这一分化背后的逻辑在于:可验证 reward(RLVR)的信号偏差较低,可以采用更激进的 trust-region 设置;而在 reward 噪声较高的领域(如创意写作),蒸馏提供的密集 token 级监督反而更稳定。这提示我们,不存在一种在所有场景下最优的后训练算法——算法选择本质上是在信号密度、偏差和 on-policy 属性之间权衡。
实践启示¶
-
在需要保留原有能力的场景有限度地使用 SFT:SFT 的灾难性遗忘并非不可避免,但需要清醒认识到其"无差别拉向目标分布"的本质。建议在任务切换幅度大(如格式遵从类任务)且原有能力退化可接受的场景使用 SFT,并在训练数据中保留一定比例的原始能力相关样本以缓解遗忘。
-
优先考虑引入 on-policy 机制来保护原有能力:无论是 RL 还是 OPD,on-policy 数据都是防止遗忘的核心要素。当现有流程依赖 SFT 且遗忘问题严重时,可以考虑在 SFT 后增加一轮 on-policy 采样 + 过滤的 OPD 步骤,从数据源头引入策略约束。
-
根据 reward 质量选择 post-training 方法:在 reward 可验证的领域(数学、代码),RLVR 是更自然的選擇,即使移除显式 KL 惩罚也能保持稳定;在 reward 噪声高的领域(创意写作、复杂推理),可考虑 self-distillation 或 OPD,并在训练中引入 token 级 clipping 防止对高 KL style token 的过度更新。
-
蒸馏 teacher 的质量并非唯一决定因素:实验表明 on-policy 数据源比 teacher 来源更重要。这意味着可以用 brute-force SFT 先训练一个 specialized 模型,再通过 OPD 将其能力蒸馏到主模型而不显著损失原有能力,为多阶段能力融合提供了可行路径。
-
关注 per-token KL 而非仅关注最终 reward:OPSD 的研究发现 style token 的 per-token KL 显著高于 math token,若不加区分地应用 aggressive 更新会导致模型崩溃。建议在任何 distillation 流程中监控 per-token KL 分布,对高 KL token 引入独立的 clipping 或衰减机制。
Ch15.009 PhoneWorld (arxiv 2605.29486):腾讯混元+港中深+人大+武大 规模化可训练 mock Android 环境基础设施(机器之心解读)¶
📊 Level ⭐⭐ | 4.3KB |
entities/phoneworld-mobile-agent-scaling-mock-environments-tencent-hunyuan-arxiv-2605-29486.md
PhoneWorld (arxiv 2605.29486):腾讯混元+港中深+人大+武大 规模化可训练 mock Android 环境基础设施(机器之心解读)¶
→ 原文存档
深度分析¶
PhoneWorld (arxiv 2605.29486):腾讯混元+港中深+人大+武大 规模化可训练 mock Android 环境基础设施(机器之心解读) 涉及agent领域的核心技术议题。
核心观点¶
-
PhoneWorld (arxiv 2605.¶
- 29486):腾讯混元+港中深+人大+武大 规模化可训练 mock Android 环境基础设施(机器之心解读)
来源:机器之心编辑部 · 腾讯混元 + 港中深 + 人大高瓴 + 武汉大学 论文地址:https://arxiv.
- 29486 过去一年,Mobile Agent 发展很快。
- 从看懂屏幕、点击按钮,到跨 App 完成长序任务,模型能力正在不断提升。
- 但限制 Mobile Agent 继续 scaling 的,可能不只是模型本身,而是环境:环境既决定了训练数据从哪里来,也决定了 Agent 的动作能否被执行、结果能否被验证、失败能否被复现。
内容结构¶
- PhoneWorld (arxiv 2605.29486):腾讯混元+港中深+人大+武大 规模化可训练 mock Android 环境基础设施(机器之心解读)
- 一、为什么不直接用真实 App?
-
- 真实 App 的状态很难重置
-
- 真实 App 的结果很难自动验证
-
- 真实 App 还有很多不稳定噪声
- 二、PhoneWorld 如何把真实 App 变成 mock App?
- 复刻的不只是截图,还有真实 App 的功能骨架
- 三、mock App 不只是会跳转,还要有真实可变的状态
技术要点¶
- agent架构: 本文在agent方向提出的设计理念与实现路径
- 工程挑战: 实际落地中面临的关键问题与应对策略
- code趋势: 相关技术演进方向与新兴范式
关联实体¶
- Karpathy 最新访谈从 Vibe Coding 到 Agentic Engineering
- Karpathy Vibe Coding Agentic Engineering
- 存之有序治之有矩Agent 记忆系统的工程实践与演进
- Scale Robot Reinforcement Learning With Nvidia Isaac Lab On
- Nvidia Isaac Lab Sagemaker Robot Rl Humanoid
- Openclaw 完全指南这可能是全网最新最全的系统化教程了32W字建议收藏
实践启示¶
- 工程落地: agent领域方案需关注可观测性、可维护性和成本效率
- 技术选型: 根据场景选择合适的技术栈,避免过度设计或盲目追新
- 持续迭代: 建立数据驱动的反馈闭环,持续优化系统表现
- 风险管控: 引入新技术需评估对现有系统稳定性的影响,做好降级预案
相关实体¶
Ch15.010 面壁让AI写了训练框架ForgeTrain,然后它自己训出了最强1B模型¶
📊 Level ⭐⭐ | 3.6KB |
entities/minicpm5-1b-forgetrain-agh-hunt.md
面壁让AI写了训练框架ForgeTrain,然后它自己训出了最强1B模型¶
→ 原文存档
深度分析¶
面壁让AI写了训练框架ForgeTrain,然后它自己训出了最强1B模型 涉及agent领域的核心技术议题。
核心观点¶
-
面壁让AI写了训练框架ForgeTrain,然后它自己训出了最强1B模型¶
核心亮点¶
- MiniCPM5-1B:1B 参数级最强端侧文本大模型,AA 智能指数 17.
- 9 分,小尺寸模型第一
- ForgeTrain:完全由 AI 编写的训练框架,在 H100 上比英伟达 Megatron 快 10%
- Forge Engineering:AI 定制化软件编程范式,代码趋近于零成本时代的新开发模式
Forge Engineering 三步法¶
STEP 1:出考试大纲 先从 Megatron 等现有框架采集关键数据,定好验收标准。 3. STEP 2:先确保及格 让 AI 在验收标准约束下,写出和原版训练结果完全一致的框架。 4. STEP 3:从及格到超越 放开限制,让 AI 自由迭代优化,直到跑赢 Megatron。 5. ## Forge Engineering vs 通用框架 通用框架(Megatron):同时支持千问、DeepSeek、MOE 等各种架构,全塞在一套框架里,处处妥协。
内容结构¶
- 面壁让AI写了训练框架ForgeTrain,然后它自己训出了最强1B模型
- 核心亮点
- Forge Engineering 三步法
- Forge Engineering vs 通用框架
- 与 Harness Engineering 的区别
- ForgeTrain vs VibeTensor
技术要点¶
- agent架构: 本文在agent方向提出的设计理念与实现路径
- 工程挑战: 实际落地中面临的关键问题与应对策略
- architecture趋势: 相关技术演进方向与新兴范式
关联实体¶
- Openclaw 完全指南这可能是全网最新最全的系统化教程了32W字建议收藏 V2
- Karpathy 最新访谈从 Vibe Coding 到 Agentic Engineering
- Openclaw 完全指南这可能是全网最新最全的系统化教程了32W字建议收藏
- Ethan He Cosmos Grok Imagine Latent Space Video Agent 20260606
- Karpathy Vibe Coding Agentic Engineering
- 存之有序治之有矩Agent 记忆系统的工程实践与演进
实践启示¶
- 工程落地: agent领域方案需关注可观测性、可维护性和成本效率
- 技术选型: 根据场景选择合适的技术栈,避免过度设计或盲目追新
- 持续迭代: 建立数据驱动的反馈闭环,持续优化系统表现
- 风险管控: 引入新技术需评估对现有系统稳定性的影响,做好降级预案
Ch15.011 Mind Lab LoRA 持续学习体系:δ-mem + MinT + LoRA Scaling Law + Macaron-A2UI¶
📊 Level ⭐⭐⭐ | 18.1KB |
entities/mind-lab-lora-continual-learning-system.md
Mind Lab LoRA 持续学习体系:δ-mem + MinT + LoRA Scaling Law + Macaron-A2UI¶
概述¶
Mind Lab(Mindverse 心洲科技)密集发布 LoRA/PEFT 研究,描绘"基础模型→可持续学习智能体"的完整技术链路。本文汇总四大成果:δ-mem(基于 LoRA 的在线记忆机制,0.12% 参数增量)、MinT(百万级 LoRA 训推基础设施,18.3x 提速)、Scaling of PEFT(LoRA 三大扩展轴 + 模型数量对数增长定律)、Macaron-A2UI(生成式 UI 模型,A2UI-Bench 75.6 分)。与现有 context/KV cache/RAG-based 记忆架构完全不同:这是参数层在线记忆路径。
核心命题¶
传统视角:PEFT = 大模型全参数后训练的"廉价平替"。
Mind Lab 视角:PEFT 是实现从"基础模型"向"可持续学习智能体"过渡的核心架构机制——不再廉价平替,而是支撑记忆、技能、UI 交互等持续学习能力的底层。
宏大愿景:极少数强大的万亿参数基础模型 → 支撑数百万具备独立记忆和技能的可持续学习智能体。
技术链路总览¶
δ-mem (在线记忆机制) → 让智能体拥有可更新的持续记忆
MinT (百万 LoRA 训推基础设施) → 支撑 LoRA 在真实场景中持续学习
Scaling of PEFT (扩展定律) → base model serve 百万 LoRA 的可行性
Macaron-A2UI (生成式 UI 应用) → 验证理论:复杂 UI 生成能力可通过高效微调被内化
δ-mem:基于 LoRA 的在线记忆机制¶
传统记忆的局限¶
传统 Transformer 的 KV cache 只是推理过程中的冻结缓存——记录当前上下文中间状态,本身不会随交互持续学习。
δ-mem 创新:平行混合线性注意力架构¶
δ-mem = 冻结的全注意力主干网络 + 紧凑的在线关联记忆状态(Online State of Associative Memory)
关键参数效率: - 8×8 在线记忆状态,参数增加低至 0.12% - Memory Agent Bench: 1.31 倍性能提升 - LoCoMo: 1.20 倍性能提升 - 移除外显历史上下文后仍能恢复大量相关信息
工作原理¶
- 随着 Token 输入,δ-mem 利用增量规则(delta-rule learning)持续更新一个固定大小的矩阵
- 生成时,从状态中读取信号,对主干网络的 Attention Query 和 Output 施加低秩校正(low-rank corrections)
社区验证¶
reddit 网友将 δ-mem 集成到 Apple Silicon 的小龙虾 agent 中,获得 agent 记忆表现提升(X 网友 Dan:「这就是 continual learning 的未来」)。
MinT:百万级 LoRA 训练与服务基建¶
核心洞察¶
管理 LoRA ≠ 管理单个模型,而是管理一大群模型的变体: - 每个 LoRA 都有自己的版本、训练曲线、回滚点 - 更可能正在被某个用户使用
支撑"模型后训练在真实场景中持续学习" → 必须有专门基础设施。
架构:Adapter 优先¶
| 传统做法 | MinT 做法 |
|---|---|
| 一步训练结束导出完整模型 | 导出很小的 LoRA Adapter(<1%,rank-1 配置可达 0.1%) |
| 上线/回滚移动整个模型 | 只移动和加载 adapter |
| 重新加载基础模型 | adapter 接到已常驻的基础模型 |
实测数据:从训练完成到推理服务可用,交接时间最多可缩短 18.3 倍。
关键优化¶
Adapter 寻址:将持久化的策略目录(海量 LoRA 集)与 CPU/GPU 热工作集分离,支持 10^6 级别策略寻址。
Packing 优化(解决单次冷加载): - 打包 MoE LoRA 张量,去除大量小对象的读写风暴 - 引擎实时加载速度提升 8.5 至 8.7 倍
二阶段 Rollout(消除新增 LoRA 冷加载对在线流量的干扰): - 阶段 1: admission 控制下完成预热 - 阶段 2: LoRA 仅在就绪后才对用户流量可见 - 混合负载测试:用户可见的 LoRA 加载 p95 → 0;首请求 TTFT p95 缩短 2.3 倍
LoRA 三大扩展轴(Scaling of PEFT)¶
研究论文 On the Scaling of PEFT 提出 base model serve 百万个 LoRA 模型的可行性 → 三大扩展轴。
Scale Up:基础模型放大¶
杠杆效应:更大参数让 LoRA 微小更新产生巨大杠杆。
1T 规模稀疏 MoE 上的 LoRA RL 挑战: - MoE 在训练和推理过程中专家的激活路径不同 → 严重训推不一致 - Mind Lab 发现现有路由重放(Router Replay)机制在前沿 MoE 模型上失效的原因 - 提出修正以消除训练和推理的差异
Scale Down:LoRA rank 极致压缩¶
- 业界通常将 rank 设在 16-32(稳定训练和推理)
- 服务上百万模型 → rank 需压到 16 以下
- 性能不能掉
OLoRA-tail 创新:原生于 RL 的初始化方法 - 利用预训练权重的次要奇异向量(minor singular vectors)进行初始化 - 移除可能导致强化学习不稳定的奇异值缩放因子 - 不增加参数量的前提下,大幅提升 Rank-1 适配器的稳定性与性能
Scale Out:模型数量对数增长定律¶
LoRA as Memory 概念: - LoRA 容量约 10^7 tokens/param - 有限介质 → 应留给 skill、persona 等持久行为状态而非可编辑事实 - 持续学习由 Context Learning 完成,让不同 adapter 沿不同路径分化
与近期研究的呼应: - 美团、阿里的研究指向同一方向:LoRA RL 内化的技能能为困难任务奠定认知基础 - 表现显著优于 skill 或 context - LoRA 能以极少参数高效装下结构化事实,形成差异化的稳定模型
模型数量 Scaling Law 涌现: - 聚合时,差异被兑现 - 多数投票下准确率随模型数量 k 呈对数增长定律 - 在三个扩展轴上涌现出来的、基于模型数量的 scaling law
Macaron-A2UI:生成式 UI 的智能交互¶
问题驱动¶
纯文本对话在处理复杂用户任务时: - 认知负荷高 - 流程繁琐
方案¶
Mind Lab 基于 MinT 训练了根据用户专属习惯持续学习的生成式 UI 模型 Macaron-A2UI。
模型不仅输出文本,还能在实时交互中生成结构化的 A2UI 可执行动作(多选框、滑块、确认卡片等)。
训练流程¶
在 30B、235B、754B 三档大模型底座上: 1. 基于 MinT 平台 2. LoRA SFT(监督微调)建立文本到 UI 的对齐 3. GRPO 强化学习提升可执行交互的质量
关键成绩¶
轻量级 Schema 提示下,表现最好的 Macaron-A2UI-Venti 模型: - A2UI-Bench 斩获 75.6 综合高分 - 超越输入了完整冗长 Schema(长度约为 27 倍)提示的最强前沿模型基线
证明:复杂的 UI 生成能力完全可以通过高效微调内化到模型权重中。
与现有 memory entity 的关键差异¶
| 维度 | 本文 Mind Lab | 现有 agent-memory-architecture(及 essence/ruofei/past-influence-future) |
|---|---|---|
| 记忆实现层 | 参数层(LoRA adapter + 矩阵更新) | context 层(KV cache / RAG / 文档检索) |
| 持续学习路径 | 在线 delta-rule 增量更新 | 重训 / 微调 / 上下文注入 |
| 参数开销 | +0.12% 即可获得 1.20-1.31x 提升 | 取决于上下文窗口或外部存储 |
| 规模化路径 | MinT 百万 LoRA 并发 + 18.3x 提速 | 向量数据库 / 长上下文窗口 |
| 涌现规律 | 模型数量 k → 准确率对数增长 | 上下文长度 → 性能(边际递减) |
| 应用形态 | 生成式 UI(Macaron-A2UI 75.6 分 A2UI-Bench) | 通用 RAG / Agent 框架 |
关键判断:本文是参数层记忆/学习的代表作,与现有 entity 关注的 context 层完全不同。不合并。
未来 AI 架构愿景¶
少数几个强大的万亿参数基础模型 → 支撑数百万个参数量极小但具有独立个性、记忆和 UI 交互能力的可持续学习智能体。
Mindverse(心洲科技)这家中国原生的 Neo Lab 跑通了低成本高收益的持续学习之路——从应用(Macaron-A2UI)、系统(MinT)到理论(LoRA Scaling Law、δ-mem)展示了完整研究纵深。
相关实体¶
→ 原文存档
深度分析¶
从"廉价平替"到"架构基础设施":PEFT 范式转移¶
传统 AI 社区将 PEFT(尤其是 LoRA)定位为降低微调成本的权宜之计——用 0.1% 参数更新替代全参数训练,本质上仍是"训练效率"的优化。Mind Lab 的贡献在于彻底重构了这一认知框架。
δ-mem 证明了 LoRA adapter 不只是微调工具,更是在线记忆的物理载体。0.12% 的参数增量即可实现 1.20-1.31x 的记忆性能提升,这说明"记忆"可以作为一种轻量级参数对象被动态写入和读取,而非依赖上下文窗口或外部向量库。
这一范式转移的影响远超技术本身:当 PEFT 成为"记忆基础设施",它就不再是训练阶段的工具,而是推理阶段持续演化的核心机制。这意味着 AI 系统的能力积累可以在部署后进行,而非冻结在训练时。
参数层记忆 vs Context 层记忆:架构范式对决¶
当前主流的 agent memory 架构(KV cache、RAG、document retrieval)都属于 context 层方案——它们在推理时注入历史信息,通过注意力机制临时影响输出。δ-mem 代表了完全不同的路径:记忆以参数形式固化在权重中,推理时无需外部检索即可调用。
两者各有显著权衡:context 层方案灵活度高、可随时更新,但受限于上下文窗口长度和检索质量;参数层方案稳定、调用延迟低,但更新需要训练且更新成本高。MinT 的 18.3x 提速和二阶段 Rollout 机制正是为了解决参数层方案的核心痛点——让"更新成本"降低到可接受范围。
这意味着未来 agent memory 架构很可能走向混合路线:参数层承载稳定、长期的记忆状态(如技能、人格、偏好),context 层承载临时、动态的会话信息。MinT 作为基础设施层支撑这种混合架构的规模化部署。
Scale Out 的涌现效应:模型数量作为新 scaling 维度¶
Scaling of PEFT 论文揭示的"模型数量对数增长定律"是本体系最具理论深度的发现。当 base model 承载的 LoRA 数量 k 增大时,多数投票准确率呈对数增长——这与语言模型 scaling law 性质类似,但 scaling 的对象从"参数规模"转向" adapter 数量"。
这一发现的技术含义是:与其在一个超级模型中塞入所有能力,不如让多个小型 adapter 分工协作,通过聚合机制兑现差异。这与 MoE 的设计哲学相通,但实施层级更低——不是在模型内部划分专家,而是在 adapter 层面形成分工。
LoRA as Memory 概念进一步明确:每个 LoRA 的容量约 10^7 tokens/param,这是有限介质。这意味着 adapter 应该承载 skill、persona 等持久行为状态,而非可编辑的事实知识。事实知识应由 context learning 负责,adapter 则专精于"如何行为"。
生成式 UI 的验证价值:Macaron-A2UI 的方法论意义¶
Macaron-A2UI 表面上是应用层的成果,但实则是对整个体系理论假设的最终验证:通过 LoRA 微调内化复杂能力(UI 生成),证明了参数层方案的可行性边界。75.6 分超越 27 倍更长 schema 的基线,有力支撑了"高效微调可以让能力固化在权重中"的核心理论。
从方法论看,Macaron-A2UI 采用 GRPO(Group Relative Policy Optimization)强化学习提升可执行交互质量,这说明参数层记忆不仅能承载静态知识,还能通过持续学习优化动态行为。这种"强化学习 + 参数层记忆"的组合为未来 agent 的持续自我改进提供了范式。
实践启示¶
构建 agent 记忆系统时优先考虑参数层方案¶
当 agent 需要长期记忆用户偏好、交互模式或技能经验时,应优先评估 δ-mem 式的参数层记忆方案,而非直觉选择 RAG 或 context window 扩展。0.12% 参数增量即可获得 1.20-1.31x 记忆性能提升,成本收益比极高。关键前提是记忆内容相对稳定、更新频率可接受(因为更新需要触发 delta-rule 学习)。
使用 MinT 架构处理多 agent 场景的 adapter 管理¶
当系统需要同时服务多个 agent 或多个用户时,adapter 管理复杂性会急剧上升。MinT 的 Adapter 优先架构提供了可借鉴的设计原则:将 adapter 视为独立版本化实体,与基础模型分离管理;通过二阶段 Rollout 消除更新时的线上流量抖动;通过 Packing 优化降低海量小对象的 I/O 开销。
在 MoE 模型上部署 LoRA 时注意路由重放失效问题¶
如果 base model 是稀疏 MoE 架构(如 1T 规模),需特别关注路由重放(Router Replay)机制在前沿 MoE 模型上的失效问题。Mind Lab 发现并提出了修正方案,在这种架构上应用 LoRA 时需要专门处理训练-推理不一致性,否则会严重影响 adapter 性能。
采用 OLoRA-tail 初始化方法处理极低 rank 场景¶
当需要在 rank-1 至 rank-8 等极低 rank 配置下部署 LoRA 时,标准初始化会导致 RL 训练不稳定。应采用 OLoRA-tail 初始化方法——利用预训练权重的次要奇异向量初始化,移除可能导致不稳定的奇异值缩放因子,在不增加参数量的前提下显著提升稳定性与性能。
设计混合记忆架构:参数层承载行为,context 层承载事实¶
基于 LoRA as Memory 的容量约束(10^7 tokens/param),应理性规划 adapter 的职责边界:将有限容量留给 skill、persona 等持久行为状态,事实知识则交给 context learning 或外部检索。这种分离设计可以避免 adapter 被大量静态事实撑满,保持 adapter 的行为专精性。
利用 Scale Out 对数增长定律设计多 adapter 聚合系统¶
在设计多 agent 协作系统时,可利用模型数量 scaling law——多数投票下准确率随 adapter 数量 k 对数增长。设计聚合机制时应让各 adapter 沿不同路径分化(通过不同的 LoRA 初始化和训练数据),差异越大聚合效果越好,而非追求各 adapter 的一致性。
Ch15.012 Fine-Tuning Cosmos¶
📊 Level ⭐⭐⭐ | 15.6KB |
entities/fine-tuning-cosmos.md
核心要点¶
- 参数高效微调范式:Cosmos Predict 2.5 (2B 参数) 通过 LoRA/DoRA 仅需训练 ~50M 参数,单 GPU 可运行
- 世界模型适配:解决通用视频生成模型在机器人领域的外观幻觉、动作错误、几何失真三大问题
- 合成数据生成:为机器人策略学习提供可扩展的、低成本的合成轨迹,绕过真实数据收集的 $10K-$100K/task 成本
- 多维评估体系:Sampson Error(几何)+ Physical Plausibility(物理)+ Instruction Following(指令)三重指标
- 实用配置:rank=32, 100 epochs, ~2.5 小时 8×H100 / 17 小时单 H100
为什么需要微调 Cosmos¶
世界模型的分布偏移问题¶
Cosmos Predict 2.5 作为通用世界模型,在处理机器人领域特定任务时存在三类典型缺陷:
| 问题类型 | 表现 | 根本原因 |
|---|---|---|
| 外观幻觉 | 机器人手臂被替换为人类手部 | 机器人视觉特征 out-of-distribution |
| 动作错误 | 不遵循指令指定的手(左手/右手)或目标物体 | 域适应能力不足 |
| 几何失真 | 帧间抖动、多视角不一致 | 训练数据的视觉统计与目标域不匹配 |
微调的本质¶
微调是将通用世界模型的「物理直觉」与特定机器人平台的「运动学特征」对齐,而非重新学习通用物理规律 。
这意味着:
- 不需要 full fine-tuning(全量参数更新)
- 冻结预训练权重可以保留强大的物理 priors
- 只需要 ~2.5% 的参数更新即可实现有效的域适应
技术架构¶
Cosmos Predict 2.5 组成¶
Cosmos Predict 2.5 (2B 参数)
├── VAE (Video Encoder/Decoder)
│ └── 将视频编码为 latent 表示
├── Text Encoder
│ └── 将文本 prompt 编码为 embeddings
└── DiT (Diffusion Transformer)
└── 在 latent space 执行扩散生成
LoRA 注入机制¶
LoRA 在 DiT 的注意力层和前馈层注入低秩矩阵 :
训练时:
- 冻结原始权重 W₀
- 仅训练 A、B 矩阵(~50M 参数)
- 推理时:W = W₀ + (α/r) × ΔW
注入位置:
- 注意力投影:
to_q,to_k,to_v,to_out.0 - 前馈层:
ff.net.0.proj,ff.net.2
DoRA 的增量改进¶
DoRA 将权重分解为幅度和方向两部分 :
其中 m 是可学习的幅度标量。直觉上,DoRA 让模型分别学习「改变多少」(幅度)和「往哪个方向变」(方向)。
| 特性 | LoRA | DoRA |
|---|---|---|
| 原理 | 低秩矩阵分解 | 幅度+方向分解 |
| 内存开销 | 相同 | 略高 |
| 极低 rank 表现 | 可能不稳定 | 更稳定 |
| 推荐场景 | 通用场景,rank≥16 | 内存受限或极低 rank |
训练流程详解¶
数据准备¶
训练数据集:GR1-100 (92 个机器人操作视频 + 文本描述)
测试数据集:PhysicalAI-Robotics-GR00T-Eval (50 个 prompt-image 对)
训练配置建议¶
| 超参数 | 推荐值 | 说明 |
|---|---|---|
lora_rank | 32 | 平衡表达力和效率 |
lora_alpha | 32 | = rank 保持 scale factor = 1.0 |
num_epochs | 100 | 从 100 开始,观察 val loss 调整 |
learning_rate | 1e-4 | 标准设置 |
warmup_steps | 100 | 渐进式学习率预热 |
batch_size | 1 | 受限于视频内存占用 |
height/width | 432/768 | 视频分辨率 |
完整训练命令 :
export MODEL_NAME="nvidia/Cosmos-Predict2.5-2B"
export DATA_DIR="gr1_dataset/train"
export OUT_DIR=YOUR_OUTPUT_DIR
lora_rank=32
accelerate launch --mixed_precision="bf16" train_cosmos_predict25_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--revision diffusers/base/post-trained \
--train_data_dir=$DATA_DIR \
--train_batch_size=1 \
--num_train_epochs=500 \
--checkpointing_epochs=100 \
--seed=0 \
--output_dir=$OUT_DIR \
--report_to=wandb \
--height 432 --width 768 \
--allow_tf32 --gradient_checkpointing \
--lora_rank $lora_rank --lora_alpha $lora_rank
训练时长估算¶
| 硬件配置 | 100 epochs 时间 |
|---|---|
| 8× H100 | ~2.5 小时 |
| 单 H100 | ~17 小时 |
| 单 A100 80GB | ~24-30 小时(估算) |
推理与部署¶
加载 LoRA 权重¶
from diffusers import Cosmos2_5_PredictBasePipeline
pipe = Cosmos2_5_PredictBasePipeline.from_pretrained(
"nvidia/Cosmos-Predict2.5-2B",
revision="diffusers/base/post-trained",
device_map="cuda",
torch_dtype=torch.bfloat16,
)
pipe.load_lora_weights("/path/to/lora/checkpoint")
pipe.fuse_lora(lora_scale=1.0) # 合并权重,消除推理开销
生成视频¶
# 可重复性噪声生成
latent_shape = pipe.get_latent_shape_cthw(height, width, num_frames)
noises = arch_invariant_rand(
(batch_size, *latent_shape),
dtype=torch.float32, device=device, seed=seed
)
frames = pipe(
image=image, # PIL Image: 条件首帧
prompt=prompt, # 文本描述
num_frames=num_frames,
num_inference_steps=36,
height=432,
width=768,
latents=noises, # 可选
).frames[0]
export_to_video(frames, "output.mp4", fps=16)
LoRA 热切换¶
可以训练多个 domain-specific adapters,推理时动态加载,实现一个 base model 服务多个垂直场景 :
# 加载领域 A 的 adapter
pipe.load_lora_weights("path/to/domain_a_lora")
# 生成领域 A 的视频
...
# 切换到领域 B 的 adapter
pipe.load_lora_weights("path/to/domain_b_lora")
# 生成领域 B 的视频
评估指标体系¶
Sampson Error(几何一致性)¶
Sampson Error 是几何计算机视觉中的传统指标,衡量匹配关键点到其对应极线的距离 。
| 指标 | 衡量内容 | 为什么重要 |
|---|---|---|
| Temporal Sampson Error | 连续帧间的几何一致性 | 物理可信的运动轨迹 |
| Cross-view Sampson Error | 不同相机视角的同时帧一致性 | 3D 空间理解 |
LLM-as-a-Judge(物理可信性 & 指令遵循)¶
使用 Cosmos Reason2 作为评判模型,1-5 分评分 :
Physical Plausibility(不看 prompt):
- 物体行为是否符合物理特性(刚体不变形、液体自然流动)
- 运动和力是否与真实物理一致(重力、惯性、动量守恒)
- 物体交互是否合理(无异常穿透、碰撞反应适当)
- 时序一致性(帧间无突兀变化)
Instruction Following(看 prompt + video):
- 任务完成度
- 动作准确性
- 物体交互正确性
- 目标达成
- 正确手的使用(左手/右手)
实验结果¶
定性分析¶
| 模型 | 典型问题 |
|---|---|
| Base Model (微调前) | 幻觉人类手部、不遵循左右手指令、帧间抖动 |
| LoRA r=32 | 解决上述所有问题 |
| DoRA r=32 | 与 LoRA 性能相当 |
定量分析¶
关键发现 :
- 100 epochs 足够:在 8× H100 上约 2.5 小时即可显著提升所有三个指标
- LoRA vs DoRA:在 rank=32 时收敛到相近性能;DoRA 在极低 rank 或不稳定场景下略有优势
-
Rank 影响:
-
更大 rank (32 vs 8) 提升指令遵循(模型有更多容量学习精确的手和物体交互)
- 但不提升几何一致性或物理可信性(这些 priors 主要由冻结的基础模型捕获)
从合成数据到真实机器人¶
Cosmos Predict 2.5 + Domain LoRA
↓
生成多样化合成轨迹(批量 + 多 seed 去噪)
↓
质量筛选
├── Physical score > 4.0
└── Instruction following > 4.0
↓
合成轨迹数据集
↓
行为克隆 / RL 训练机器人策略
↓
Sim-to-Real 部署
├── Domain randomization
└── 域适应微调
合成数据的价值与局限¶
价值 :
- 真实机器人数据收集成本 $10K-$100K/task
- 合成数据可在数小时内生成大量多样化轨迹
- 可以覆盖危险场景、稀有物体、极端条件
局限:
- 受限于世界模型的物理理解上限
- Sim-to-real gap 需要处理
- 需要高质量 prompt 描述期望动作
实践 Checklist¶
微调前确认¶
- 明确目标域:机器人类型(单臂/双臂/轮式)、相机配置、任务类型
- 评估数据量:92 个视频对 GR00T 级别任务足够,但垂直领域可能需要更多
- 确定评估指标:物理可信性 vs 指令遵循哪个更重要
- 准备计算资源:80GB GPU 最小,8×H100 加速迭代
DoRA 切换时机¶
当出现以下情况时,考虑切换到 DoRA :
- 使用极低 rank (r=8) 且训练 loss 震荡
- 观察到 LoRA 过拟合但又不希望增大 rank
- 任务需要更精细的方向控制
深度分析¶
参数高效微调的实质是"保留物理 priors + 适配域外观分布"¶
LoRA/DoRA 微调 Cosmos Predict 2.5 的本质不是让模型"重新学习物理",而是将通用世界模型的视觉分布适配到特定机器人平台的外观特征 。实验结果揭示了一个关键不对称:rank 32 vs rank 8 的差异仅体现在指令遵循能力上,而几何一致性和物理可信性在两个 rank 下都没有显著差异。这意味着几何和物理 priors 主要由冻结的基础模型捕获,LoRA 适配的只是"机器人手臂看起来是什么样"和"给定 prompt 应该执行什么动作"这类浅层分布偏移 。对于需要同时优化所有三个指标的场景,增大 rank 并非万能解——当 base model 的物理 priors 本身存在问题时,冻结权重 + LoRA 的组合无法修复底层物理理解缺陷。
多维度评估体系的必要性:单一指标会掩盖重要缺陷¶
该论文构建了三重评估体系:Sampson Error(几何一致性)、LLM-as-Judge Physical Plausibility(物理可信性)、LLM-as-Judge Instruction Following(指令遵循) 。这是一个重要的设计选择,因为视频生成质量的视觉逼真度与"物理正确性"和"任务完成度"之间没有强相关性。一个帧间完全一致、物体运动流畅的视频可能完全遵循了错误的手(左手 vs 右手)或与目标物体交互错误;反之亦然。这意味着在构建机器人合成数据 pipeline 时,必须对每个维度分别设定质量门槛(Physical score > 4.0 AND Instruction following > 4.0),而非依赖单一 FID 或 LPIPS 指标 。
LoRA 热切换使单一 base model 服务多域成为可能¶
推理时动态加载不同 domain-specific LoRA adapters 的能力,指向一个重要的工程模式:world model + domain adapters 的组合可能是机器人领域通用基础模型的最终形态 。在 Cosmos 之前,每个机器人类别(工业臂、协作臂、轮式)通常需要独立训练或微调一个完整的视频生成模型;LoRA 热切换使得一个 2B 参数的 base model 可以通过切换 ~50M 的 adapter 服务多个垂直场景,存储和计算成本降低了一个数量级。这种模式与 LLM 社区的 adapter/tuning 实践完全一致,暗示机器人 world model 的未来可能走向"一个通用物理世界模型 + 多个领域轻量适配器"的架构。
100 epochs 是效率与效果的最优平衡点¶
实验数据显示 100 epochs(约 2.5 小时 8×H100)在三个评估指标上均达到显著提升,继续训练到 500 epochs 的边际收益很小 。这一发现对工程实践有重要指导意义:对于快速迭代验证场景,100 epochs 是最低可行训练长度;超过 100 epochs 的训练更可能是在拟合训练数据噪声而非学习新的域知识。这还意味着,对于需要频繁重新训练或持续学习的场景(如持续收集新机器人数据的在线学习),单次 100 epochs 的训练成本(~2.5 小时 on 8×H100)是可接受的工程预算。
DoRA 的优势在 rank=32 时消失,在极低 rank 时才显现¶
在 rank=32 的标准配置下,LoRA 和 DoRA 收敛到相近性能 。DoRA 的幅度-方向分解在更高 rank 时提供了额外的表达能力,但当 rank 足够高时,这种分解带来的增益被 LoRA 自身的低秩更新空间所吸收。只有在 rank 极低(r=8)或训练不稳定场景下,DoRA 的结构化分解才表现出稳定优势 。这为实践者提供了一个清晰的决策框架:rank≥16 时默认使用 LoRA,rank<16 或观察到训练 loss 震荡时切换到 DoRA。
实践启示¶
-
默认使用 LoRA r=32,DoRA 仅作为特定场景的替代方案。在 rank=32 下,LoRA 和 DoRA 性能相当,LoRA 实现更简单、无额外开销 。只有在 GPU 内存严重受限时才考虑 DoRA r=32,或当 rank=8 时观察到训练 loss 震荡才切换到 DoRA 以获得更稳定的低 rank 学习。
-
评估体系必须覆盖所有三个维度,而非仅依赖视频质量指标。 Sampson Error 衡量几何一致性、Physical Plausibility 衡量物理可信性、Instruction Following 衡量任务完成度,三者缺一不可 。在构建合成数据 pipeline 时,应同时设定所有三个维度的质量门槛(如 > 4.0),而非仅凭视觉质量或单一指标筛选数据,否则生成数据中的指令遵循错误会被行为克隆阶段放大 。
-
合成数据的多 seed 去噪是提高轨迹多样性的关键。同一个 prompt-image 对通过不同的随机 seed 去噪可以生成多条轨迹,这是在有限训练样本下最大化数据多样性的有效方法 。建议对每个测试样本生成 5 个不同 seed 的视频并取平均评分,以获得更可靠的指标估计 。
-
fuse_lora 是生产部署的必要步骤。LoRA weights 在推理时合并到 base model 以消除每次推理的 adapter 计算开销 。对于需要低延迟推理的生产环境,应在部署前执行
pipe.fuse_lora(lora_scale=1.0),而非保留未合并的 LoRA weights。 -
World model + 多 domain adapters 是推荐的多机器人平台策略。训练多个 domain-specific LoRA adapters(如 GR1、双臂机器人、轮式平台),推理时动态切换加载,可以在单一 2B base model 上服务多个机器人平台 。这比分别为每个平台训练完整模型在存储、推理成本和一致性维护上都有显著优势。
相关资源¶
- Cosmos Cookbook — 官方技术食谱
- HuggingFace Cosmos Collection — 模型和数据集
- GitHub: nvidia-cosmos — 官方代码库
- Cosmos Discord — 社区讨论
相关词条¶
- Fine-Tuning NVIDIA Cosmos Predict 2.5 with LoRA/DoRA for Robot Video Generation
- Fine-Tuning NVIDIA Cosmos Predict 2.5 with LoRA/DoRA — 深度分析
- 原文存档
相关实体¶
Ch15.013 SFT, RL, and On-Policy Distillation Through a Distributional Lens¶
📊 Level ⭐⭐⭐ | 15.5KB |
entities/untitled-v2.md
SFT, RL, and On-Policy Distillation Through a Distributional Lens¶
→ 原文存档
摘要¶
本文从分布重塑(Distributional Reshaping)的视角审视后训练方法(SFT、RL、OPD),提出一个统一的几何直觉:语言模型是序列上的分布,后训练的本质是通过不同机制改变这一分布的形状。SFT 将模型拉向固定的外部数据集分布(等价于最小化前向 KL 散度),具有"覆盖所有模式"的特性,容易引发灾难性遗忘;RL 和 On-Policy Distillation(OPD)则通过 on-policy 数据约束更新方向,使其天然落在当前策略邻域内,遗忘更少。核心发现:on-policy 数据是防止遗忘的关键加载成分(load-bearing ingredient),而非 RL 算法本身有什么特殊魔法;蒸馏 teacher 的质量远不如 on-policy 数据来源重要——可以用 brute-force SFT 训练 specialized 模型,再通过 OPD 将能力迁移到主模型而不显著损失原有能力。
核心命题¶
后训练方法之间的本质差异,不在于算法结构,而在于它们各自将模型分布拉向什么样的目标分布,以及这个目标分布与模型原始分布之间的距离有多远。
将这个命题具体化: - SFT:有一个预先存在的标注数据集,模型通过交叉熵被拉向该数据集分布。前向 KL 散度的"覆盖所有模式"特性导致在远离原始分布的区域产生无差别梯度更新。 - RL:模型从自身当前策略中采样,根据 reward 打分,然后更新参数以增加期望 reward。没有固定的外部目标分布。 - OPD:介于 SFT 和 RL 之间——有 teacher 信号(像 SFT),但数据来自学生自身(像 RL)。
SFT:固定外部目标分布¶
几何解释¶
SFT 是最直接的后训练场景:用标注数据集(人工标注或强模型生成)对起始模型做交叉熵损失。
在分布视角下,当前模型是一个分布 $P_0$,数据集定义另一个分布 $P_{data}$。SFT 将 $P_0$ 拉向 $P_{data}$。由于负对数似然的数学性质,$P_0$ 的原始形状对最终结果没有任何影响——这正是 SFT 存在灾难性遗忘风险的根本原因。
如果 $P_{data}$ 与 $P_0$ 相距甚远,模型没有内在的驱动力去偏好"近邻解",只能被简单地拉向数据集中展示的 token。这导致在整个分布范围内产生均匀的梯度更新——既包括与新任务相关的 token,也包括语法 token 和风格 token。
什么时候该用 SFT¶
SFT 最适合"冷启动型"任务:期望输出格式需要被彻底改变,且原有能力的退化是可接受的。例如: - 从头训练遵循特定输出格式(如 JSON 结构、特定语言风格) - 大规模格式遵从类任务(从自由文本转为结构化响应)
什么时候 SFT 会出问题¶
SFT 的失效模式在高风险场景中是不可接受的: - 需要保留原有能力的任务(模型在 SFT 后出现代码能力退化) - 目标分布覆盖了模型高频访问的区域(KL 散度大的重叠区)
解决方向:在训练数据中保留一定比例的原始能力相关样本,或在 SFT 后增加一轮 on-policy 过滤的 OPD 步骤。
RL:最大期望奖励方向¶
几何解释¶
RL 的工作方式与 SFT 有根本性不同:模型从自身采样 $\rightarrow$ 用 reward 函数评分 $\rightarrow$ 通过 Policy Gradient 更新以增加期望 reward。
此时,"目标分布"的定义变得模糊。在 RL 中,隐含的目标分布可以定义为:所有满足"所有轨迹 reward 均为 1"的策略中,与当前策略 KL 散度最小的那个。
这个定义带来的关键推论:RL 学习的实际上是在当前策略邻域内最近的任务解决策略。每一次 policy gradient 更新,模型都在拟合一个与自身最接近的最优策略,而非一个任意的外部目标。
这解释了 RL 为什么比 SFT 遗忘更少:on-policy 数据约束将更新方向限制在模型已经高频访问的区域,隐式地实现了类似 KL 正则化的效果。
RLHF vs. RLVR¶
RLHF(使用 Reward Model)和 RLVR(可验证 reward)在信号质量上有显著差异:
- RLVR:reward 可验证(如数学答案对错、代码能否通过测试),reward 方向是质量的可靠代理,移动沿 reward 方向通常能得到更好的模型
- RLHF:reward model 不完美,优化一个 biased proxy,可能过度拟合 reward model 的错误
这导致两者在信任域(trust-region)设置上的差异:RLVR 通常可以使用更激进的 trust-region(如 GRPO 替代 PPO),而 RLHF 需要更强的 KL 惩罚和更保守的 clipping。
On-Policy Self Distillation(OPSD)¶
OPSD 是 OPD 的一种新变体,teacher 和 student 是同一模型,但在计算 teacher log 概率时提供 reference solution 作为前缀。这产生了一个 privileged information——teacher 知道正确答案的前缀,学生在自己生成的 prefix 上接受 teacher 的建议。
OPSD 揭示了一个有趣现象:style token(如"wait"、"alright")的 per-token KL 远高于 math token(如"power"、"exponent")。如果对这些高 KL token 应用激进的更新,模型可能崩溃。解决方案是引入 per-token clipping 机制,对高 KL token 使用独立的衰减策略。
这一发现对 Skill Rm Qwen Agent Skill Reward Model 有直接启示:Skill-RM 的渐进式披露机制可以类比为 OPSD 的 per-token KL 分析——资源应该在需要时才激活,而不是一股脑全部暴露。
核心实验:OPD 的 teacher 来源重要吗?¶
实验设置¶
实验使用 Minimal Code Editing 任务:给模型一个有缺陷的函数,要求修复 bug 且不改变其他部分。测试两个维度:
- 泛化能力:在不同类型的 corruption 上评估
- 灾难性遗忘:在 LiveCodeBench 上评估代码生成能力是否退化
实验先分别用 SFT 和 RL 训练两个 teacher 模型,然后各自通过 OPD 蒸馏出学生模型。
关键结果¶
| Model | Pass@1 | Norm. Levenshtein | Added CC | LiveCodeBench v6 |
|---|---|---|---|---|
| Teachers | ||||
| SFT teacher | 0.775 | 0.450 | 0.450 | 0.286 |
| RL teacher | 0.792 | 0.063 | 0.206 | 0.320 |
| Students (OPD) | ||||
| OPD SFT teacher | 0.800 | 0.059 | 0.206 | 0.297 |
| OPD RL teacher | 0.787 | 0.055 | 0.228 | 0.314 |
反直觉发现¶
OPD 学生普遍优于各自的 teacher。甚至更反直觉的是:
- OPD SFT teacher 的学生(来自 SFT teacher,但 teacher 本身在 LiveCodeBench 上有退化)遗忘少于 SFT teacher 自己
- 两个 OPD 学生的 LiveCodeBench 分数差异极小(0.297 vs 0.314),尽管 teacher 差距明显(0.286 vs 0.320)
为什么 OPD 学生能超越 teacher¶
关键洞察:teacher 的质量没那么重要,on-policy 数据来源才是决定性因素。
OPD 中,teacher 提供信号,但数据的 state distribution 来自学生自己。这带来了两个优势:
- 靶向监督:OPD 的监督信号落在学生实际需要改进的区域——teacher 对学生自己生成的前缀提供建议,而非对学生可能很少访问的分布区域
- KL 匹配不等于 reward 最大化:teacher 的 logit 分布携带了风格、不确定性、替代延续和推理结构的信息,匹配这些信息可以改善学生的采样行为,即使 teacher 贪婪采样的输出本身并不更优
这为多阶段能力融合提供了可行路径:先用 brute-force SFT 训练 specialized 模型(不管遗忘问题),再通过 OPD 将其能力蒸馏到主模型而不显著损失原有能力。
为什么 RL/OPD 遗忘更少:三种解释¶
解释一:前向 KL vs. 反向 KL¶
SFT 通过交叉熵等价于最小化前向 KL($KL(P_0 || P_{data})$),前向 KL 具有"覆盖所有模式"的特性——为覆盖目标分布的所有峰,会在广泛区域产生梯度更新。
Chen et al. 的工作表明 RL 可以被理解为反向 KL($KL(P_{data} || P_0)$),在多峰分布中会优先覆盖单个峰而非所有峰,因此遗忘更少。
批评:这个解释在有显式 KL 正则化时成立,但 RL 即使移除 KL 惩罚仍表现出抗遗忘特性,因此该解释不完整。
解释二:RL 有更稀疏但更关键的参数更新¶
Mukherjee et al. 发现 RL 更新只作用于模型的一个小子网络(稀疏但全秩),而 SFT 产生密集更新。Yuan et al. 发现 SFT 的参数更新冗余度更高——当减少参数量时,RL 性能下降更快。
批评:这些结果在特定领域成立,但不一定具有普遍性;OPD 如何嵌入这一图景也不清晰。
解释三(作者最认同):On-Policy 数据约束¶
来自 Shenfeld et al. 的理论工作:每次 policy gradient 更新实际上是在拟合当前策略邻域内最近的任务解决策略。
用 REINFORCE + 二元 0/1 reward 理解:reward 充当过滤器,reward=1 的样本提供正训练信号,reward=0 的提供零贡献。所有满足"所有轨迹 reward=1"的策略构成集合 $P^$,训练过程收敛到 $P^$ 中与当前策略 KL 散度最小的那个。
这意味着 on-policy 数据约束将训练过程限制在一个与当前策略 KL 距离很小的邻域内,而 SFT 的目标分布可能是任意遥远的。
深度分析¶
分布视角的工程价值¶
将后训练方法映射到"分布重塑"的框架下,有几个实际的工程价值:
第一,它提供了一个统一的语言来比较不同的后训练方法。过去工程师谈论 SFT、RL 和 OPD 时,往往是在描述算法细节,而忽略了这三种方法实际上在解决同一个几何问题("将分布 P0 变成什么形状")。
第二,它帮助预测失效模式。如果知道 SFT 的问题是"无差别拉向目标分布",那么在设计训练数据时就应主动减少与原始能力无关的样本比例;如果知道 RL 的优势来自"邻域内最优",那么在设计 reward 函数时就应确保 reward 信号在模型高频访问区域有足够的覆盖。
第三,它指向了 OPD 的正确使用方式。既然 on-policy 数据是关键,那么 OPD 的工程重点应该是"如何构建高质量的 on-policy 数据"而非"如何设计更好的 teacher"。
OPSD 的 per-token KL 发现与 Skill-RM 的关联¶
OPSD 实验发现 style token 的 per-token KL 远高于 math token,这意味着某些 token 上的梯度更新实际上是在无关紧要的风格层面浪费计算资源。
这与 Skill Rm Qwen Agent Skill Reward Model 中"append resources 反而降分"的消融实验形成强烈呼应:把大量资源(rubric、checklist、verifier)一股脑 append 进 prompt,等价于对所有 token 无差别地增加信息密度,结果是 key signal 被稀释。OPSD 的 per-token clipping 机制和 Skill-RM 的渐进式披露机制,本质上是在解决同一个问题:如何让关键信息在需要的地方出现,而不是均匀分布在所有地方。
多阶段后训练流水线的选择逻辑¶
当前主流的 post-training 流水线(Pre-train → SFT → RL → OPD)中,不同领域对方法的选择有明显的规律:
- Math 和 Code:偏好 RL(可验证 reward,信号偏差低,可以采用更激进的 trust-region)
- 创意写作和知识密集型任务:偏好自蒸馏或蒸馏类方法(reward 噪声高,密集的 token 级监督反而更稳定)
这提示了一个原则:算法选择本质上是信号密度、偏差和 on-policy 属性之间的权衡。没有任何单一方法在所有场景下最优。
实践启示¶
1. 在需要保留原有能力的场景,有限度地使用 SFT¶
SFT 的灾难性遗忘不是不可避免的,但需要清醒认识到其"无差别拉向目标分布"的本质。建议在任务切换幅度大、原有能力退化可接受的场景使用 SFT,并在训练数据中保留一定比例的原始能力相关样本以缓解遗忘。
2. 优先考虑 on-policy 机制来保护原有能力¶
无论是 RL 还是 OPD,on-policy 数据都是防止遗忘的核心要素。当现有流程依赖 SFT 且遗忘问题严重时,可以考虑在 SFT 后增加一轮 on-policy 采样 + 过滤的 OPD 步骤,从数据源头引入策略约束。
3. 根据 reward 质量选择 post-training 方法¶
在 reward 可验证的领域(数学、代码),RLVR 是更自然的选择,即使移除显式 KL 惩罚也能保持稳定;在 reward 噪声高的领域(创意写作、复杂推理),可考虑 self-distillation 或 OPD,并在训练中引入 token 级 clipping 防止对高 KL style token 的过度更新。
4. 可以用 brute-force SFT 训练 specialized 模型,再通过 OPD 迁移¶
实验表明 on-policy 数据源比 teacher 来源更重要。这意味着即使 SFT teacher 本身有遗忘问题,通过 OPD 蒸馏出来的学生遗忘也更少。这为"先训练专家模型,再迁移到通才模型"的多阶段 pipeline 提供了可行路径。
5. 监控 per-token KL 而非仅关注最终 reward¶
OPSD 的研究发现 style token 的 per-token KL 显著高于 math token。建议在任何 distillation 流程中监控 per-token KL 分布,对高 KL token 引入独立的 clipping 或衰减机制,以防止模型崩溃。
6. 关注 RL 和 OPD 的稀疏更新特性¶
如果你的训练基础设施支持灵活的更新策略,可以考虑模仿 RL 的稀疏更新机制——只更新与当前任务最相关的参数子集,而非全量更新。这可能带来更好的任务特化与能力保留的平衡。
相关实体¶
- Skill Rm Qwen Agent Skill Reward Model
- Skill Hub Organization Asset Winty
- Skill Design Spec 8 Block Checklist Winty
- Hermes Self Evolution Closed Loop Skill Reuse Winty
- Normalizing Trajectory Models
Ch15.014 在线蒸馏OPD vs 离线蒸馏SFT:数学原理与实战优势¶
📊 Level ⭐⭐⭐ | 14.1KB |
entities/on-policy-distillation-vs-offline-distillation-loster.md
核心定义¶
离线蒸馏(SFT/Off-Policy):Teacher生成固定数据,Student通过SFT模仿。暴露偏差+复合误差+Mode-Covering导致小模型学到"平均值"幻觉。 在线蒸馏(OPD/On-Policy Distillation):Student自己生成轨迹,Teacher对每步Token-level打分。Mode-Seeking让学生找到自己智力范围内的最优解法,学会在错误中纠错。
5个决定性原因¶
- 解决暴露偏差与复合误差:SFT像让新手背大师棋谱,小模型一旦偏离就进入未知状态步步错;OPD让小模型自己走,老师在旁边对每步打分,学会Recover from mistakes ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg]
- 稠密奖励vs稀疏奖励:传统RL只给标量奖励,OPD给每个Token的概率分布或对错评分 ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg]
- 解决能力错位:小模型没有容量硬背复杂逻辑链路,OPD允许用自己智力水平探索解法 ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg]
- 克服KL模式平均:Forward KL强迫Mode-Covering(覆盖所有优质回答)→学到"平均值"废话;Reverse KL实现Mode-Seeking(精通一种即可) ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg]
- 基础设施成熟:跨分词器对齐(GOLD/ULD)+ 异步训练框架(verl+DeepSpeed+vLLM) ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg]
数学原理¶
Forward KL(SFT本质)¶
- 目标:最小化D_KL(P_T || P_θ),等价于最大化MLE(交叉熵损失)
- Mode-Covering:当P_T>0但P_θ→0时KL爆炸,小模型必须覆盖Teacher所有高概率区域,容量有限导致学到"空白区域"→幻觉
- 通俗:不懂也要背老师所有思路
Reverse KL(OPD本质)¶
- 目标:最小化D_KL(P_θ || P_T),等价于max (E[Reward] + H(P_θ))
- 第2项E[log P_T(x)]=期望奖励;第1项-H(P_θ)=熵正则化(防Mode Collapse)
- Mode-Seeking:只需找到Teacher某个高概率区域并驻留,容量友好+解决暴露偏差
- 通俗:用自己思路解题,老师觉得对就行
OPD vs 传统RL的优势¶
| 优势 | 传统RL | OPD |
|---|---|---|
| 信号密度 | Sparse(只给最终Reward=0) | Dense(Step-level+Logits软标签) |
| 成本/扩展性 | 人类标注慢/贵/不准 | Teacher模型24h不间断打分,千万级数据可行 |
| 奖励黑客 | 容易找规则漏洞 | Teacher评价过程逻辑,遏制捷径 |
| 优化平滑性 | 盲目试错,方差大易崩溃 | Teacher提供引导方向 |
核心对比表¶
| 维度 | SFT(离线蒸馏) | OPD(在线蒸馏) | |
|---|---|---|---|
| KL方向 | Forward KL | Reverse KL | |
| 采样来源 | Teacher(固定数据集) | Student(当前策略) | |
| 数学目标 | MLE(交叉熵) | 期望奖励+熵正则化 | |
| 分布特性 | Mode-Covering | Mode-Seeking | |
| 典型问题 | 暴露偏差、幻觉 | Mode Collapse(需熵惩罚) | |
| 训练稳定性 | 高(固定分布) | 中(需熵监控) | |
| 计算成本 | 低(一次性生成) | 高(实时生成+评估) | |
| 收敛速度 | 快(直接模仿) | 慢(探索+收敛) |
深度分析¶
OPD的数学收敛性¶
Reverse KL目标的优化本质上是带熵正则化的策略搜索问题。根据Fenchel对偶性,OPD目标等价于在Teacher附近寻找高奖励区域的策略。由于熵项的存在,OPD天然避免了纯RL中的过早收敛问题——策略不会急速坍缩到单一模式,而是在Teacher认可的多个解法之间保持合理多样性。 关键在于:Forward KL要求小模型覆盖Teacher的所有模式(Mode-Covering),这在有限容量下必然导致模式之间的"空白区域"被错误分配概率质量,最终表现为幻觉。Reverse KL则允许小模型选择一个它自己能够高效表达的模式集中学习(Mode-Seeking),这种"精通一种"而非"平均掌握"的策略在容量受限场景下更加有效。 数学补充:Reverse KL可以写成强化学习形式 ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg] $$\mathcal{L}{OPD} = \mathbb{E}[-\log P_T(x)] + \lambda \cdot H(P_\theta)$$ 其中第一项是负对数似然(奖励),第二项是熵惩罚。优化这个目标等价于在Teacher分布的支撑集上寻找高奖励、低熵的策略。
暴露偏差的递归本质¶
SFT中的暴露偏差不是单一的问题,而是一个递归放大的系统: ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg] 1. 小模型在Training分布上学习,采样时偶发偏离轨迹 ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg] 2. 偏离导致进入Out-of-distribution状态,模型置信度骤降 ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg] 3. 低置信度导致更大概率采样到错误Token ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg] 4. 错误Token进一步推离训练分布 ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg] OPD通过On-Policy采样打破这一循环:Student始终从自己当前策略采样,教师对每步都提供校正信号。这意味着即使小模型在推理时偶有偏差,教师也能及时拉回,而非累积误差。 量化分析:设暴露偏差导致的累积误差为$\epsilon_t$,则在SFT中有$\epsilon_{t+1} \approx f(\epsilon_t)$,其中$f$是放大函数(通常$\frac{\partial \epsilon_{t+1}}{\partial \epsilon_t} > 1$)。OPD通过每步校正将放大系数降低到接近1。
跨Tokenizer蒸馏的技术挑战¶
GOLD(Greedy Output Logits Distillation)和ULD(Unlimited Layerwise Distillation)解决了跨模型家族的在线蒸馏问题。其核心思想是:
- 词表投影:用线性层或注意力机制对齐两个模型的词表空间
- 序列对齐:在Token-level计算对齐损失,而非整句匹配
- Logits蒸馏:直接对齐Teacher和Student的输出Logits分布,而非Softmax概率
这让用Qwen蒸馏Llama、用DeepSeek-R1蒸馏Mistral成为可能,极大扩展了OPD的适用范围。 GOLD vs ULD:GOLD使用贪心策略选择对齐目标,适合教师学生架构相近的场景;ULD则支持逐层对齐,适合深层网络的知识迁移。
Mode Collapse的熵惩罚机制¶
OPD虽然解决了Mode-Covering问题,但引入了自己的隐患:Mode Collapse。当Student只找到一个Teacher的高概率区域后,熵项减少会使策略快速坍缩到该模式,丧失多样性。 解决思路包括: ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg]
- 动态熵权重:训练初期高熵权重鼓励探索,后期降低以收敛
- 混合目标:结合Forward KL和Reverse KL,用前者的Mode-Covering特性弥补后者的Mode Collapse倾向
- 多次初始化:多次实验取方差最大的模型,而非单一模型
- 熵下界约束:强制策略熵不低于某个阈值,防止过度坍缩
OPD在长文本生成中的特殊价值¶
长文本生成是暴露偏差问题最严重的场景。当生成长度超过50个Token时,SFT模型的错误累积概率急剧上升。OPD通过逐Token校正确保每一步都在Teacher认可的概率分布附近采样:
- 短文本(<50 Token):SFT与OPD差异不大,暴露偏差尚未显著
- 中等文本(50-200 Token):OPD优势开始显现,错误累积速度显著低于SFT
- 长文本(>200 Token):SFT几乎无法维持质量,OPD成为唯一可行方案
这一特性使OPD特别适合代码生成(平均长度300+ Token)和长问答场景。 ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg]
OPD与RLAIF的关系¶
OPD(On-Policy Distillation)是RLAIF(Reinforcement Learning with AI Feedback)的一种特殊形式。RLAIF通常指用AI代替人类进行Reward Model训练,而OPD进一步利用AI进行Token级别的密集反馈: | 特性 | RLAIF | OPD | |------|-------|-----| | 反馈粒度 | Sentence-level(句级别) | Token-level(词级别) | | 反馈内容 | 标量Reward | Logits/概率分布 | | 优化目标 | RL(PPO等) | KL散度+熵正则化 | | 计算成本 | 中 | 高 |
实践启示¶
何时优先选择OPD¶
适合OPD的场景: ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg]
- 小模型(参数量≤教师模型的30%)无法覆盖教师多模态输出分布
- 任务具有清晰的过程性(如数学证明、代码生成、逻辑推理),每步都有语义意义
- 教师模型与学生模型架构相近或词表可对齐
-
需要低成本、高数据量的蒸馏场景(如千万级指令数据) 仍然选择SFT的场景: ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg]
-
学生模型容量足够大,能覆盖教师的大部分输出分布
- 任务为单点输出(如分类、实体识别),模式平均反而是优势
- 教师模型极强,学生模仿其单一模式即可获得良好性能
工程实现关键点¶
- Teacher serving:用vLLM或SGLang部署教师模型,启用TensorParallelism应对大参数量。Batch请求吞吐量是关键——OPD的On-Policy特性要求教师实时打分,不能成为瓶颈。 ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg]
- 异步训练调度:verl的One-Step(生成+评估同步)和Two-Step(生成异步,评估同步)两种模式选择取决于GPU规模和延迟容忍度。Two-Step适合多卡场景,通过预生成轨迹池化提升GPU利用率。 ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg]
- 熵监控:训练过程中监控策略熵,当熵下降速度过快时(>0.1/100steps)应触发熵权重增加或早停。 ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg]
- 混合蒸馏:先用SFT建立基础能力(避免冷启动),再用OPD精调特定能力(解决暴露偏差)。两阶段策略在实践中往往优于纯OPD。 ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg]
评估策略¶
避免单一指标(如ROUGE/BLEU)评估蒸馏质量。推荐多维度评估: ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg]
- Task-level accuracy:最终答案正确性
- Step-level alignment:学生采样分布与教师的Token-level KL散度
- Diversity metrics:生成多样性(Unique N-gram ratio)
- Human preference:关键场景人工打分
新增洞察:2026-05-23 OPD 失败模式与修复方案¶
新增内容(storm/知乎,arXiv:2603.25562): ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg]
- Token-level OPD 的 bias-variance 权衡:相对 sequence-level reverse-KL 有偏,但最坏情况方差上界从四次降至二次(序列长度方向);长文本场景(几十万 token)下方差可控性直接影响训练稳定性
- 三大实践失败原因:
- 正负 sampled-token reward 结构性失衡:大多数 token 得到负奖励(student 概率 > teacher 概率),优化过度依赖少数高杠杆正事件,导致对填充词/犹豫词异常敏感 ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg]
- 学生前缀上教师信号失真:学生模型走到自己的典型前缀(但 teacher 不典型)时,teacher 仍奖励局部"还行"的 token,但整体轨迹已在变差 → teacher-environment gap ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg]
-
Tokenizer/Special-token 不一致:不同 tokenizer 对同一文本切分不同(如
<think>切为<+think+>vs<th+ink+>),导致语义等价的 token 被错误惩罚 ^[https://mp.weixin.qq.com/s/JljnDWerzMzlUl0BMblKXg] -
修复方案:Teacher Top-K 局部支持集匹配:
- 不在单个 sampled token 上比较 teacher/student,而是在 teacher top-K 支持集上做截断 reverse-KL
- 支持集内重归一化(只对 top-K logits 做 softmax,避免梯度传到集合外)
- Top-p rollout(采样尽量留在学生分布高概率区域)
- Special-token masking(修补 tokenizer mismatch 的正交手段)
- 实验验证:Qwen2.5-7B-Instruct + OpenThinker3-7B teacher,多任务(数学推理+智能体),Teacher Top-K 方法在 MATH500/AIME24/AIME25 等基准稳定优于 sampled-token OPD 合并判断: 现有 entity 覆盖 OPD 基础理论(Forward KL vs Reverse KL、数学原理、Mode Seeking/Covering),本篇补充工程实践中的失败模式与解决方案,merge 后覆盖"理论 + 失败分析 + 修复方案"完整闭环。
相关实体¶
- Yann Dubois Openai Post Training Interview
- Ettin Reranker Family
- Rag Chunking Vectorization Rerank Distillation
- Apo Autonomous Preference Optimization
- Introducing The Ettin Reranker Family
→ 原文存档
Ch15.015 DeepSeek V4 训练方法论深度解读¶
📊 Level ⭐⭐⭐ | 13.8KB |
entities/deepseek-v4-training-methodology.md
DeepSeek V4 训练方法论深度解读¶
花叔对 DeepSeek V4 58 页论文的深入解读,涵盖架构改动、训练稳定性、后训练范式变化、评测结果及未来方向。
核心结论¶
DeepSeek V4 不是冲破 AGI 天花板的 SOTA 模型,而是首次将百万上下文、Agent 原生能力、可接受的价格三者结合的模型。它抬高了开源模型的地板,让独立开发者能放心使用百万上下文 Agent。
架构改动(三大改进)¶
V4 没有推倒 V3 重来,MoE 框架沿用 DeepSeekMoE,MTP 模块未动。真正的大改只有三处:
1. mHC(Modified Hyper-Connections)¶
- 残差连接升级:解决深度扩展时的数值不稳定问题
- 核心创新:给残差连接加「只准收缩不准放大」的数学护栏,使用双随机矩阵约束信号守恒
- 效果:模型从 V3 的 671B 推到 1.6T(2.4 倍),训练稳定性反而更好
- → Scaling Laws
2. CSA + HCA 混合注意力¶
- CSA(Compressed Sparse Attention):每 64 个 token 压缩为 1 块,用 Lightning Indexer 打分,只挑 top-k 块精读
- HCA(Heavily Compressed Attention):极高压缩率(每 1024 token 压 1 块),dense 扫描所有压缩块
- 效果:100 万上下文下单次推理成本仅为 V3.2 的约 1/4,KV cache 占用仅传统 BF16 GQA8 baseline 的约 2%
3. Muon 优化器¶
- 替代 AdamW:不看单个旋钮,看整组旋钮的方向,将椭圆轨迹「掰正」为正圆
- 效果:冷门方向获得同等步长,模型探索更广,收敛更稳
- 参数分工:embedding/prediction head/RMSNorm 仍用 AdamW
训练稳定性(两个"不理解"的 trick)¶
Anticipatory Routing(预判式路由)¶
- 路由器用「昨天的脑子」做「今天的决定」:主干更新与路由器解耦,路由器查历史参数来避免崩溃恶性循环
SwiGLU Clamping¶
- 强行给 SwiGLU 内部数值加上下限(-10 到 10),防止神经元输出爆炸
DeepSeek 坦言:「the underlying principles of these mechanisms remain insufficiently understood」
训练数据¶
- 规模:Pro 版本 33T tokens,Flash 版本 32T tokens
- 反模型坍缩:过滤 AI 生成文本
- 中期训练引入 Agent 数据:工具调用轨迹、多步推理、搜索片段
- 多语言扩容:扩充长尾语言
- 序列长度渐进扩展:4K → 16K → 64K → 1M,稀疏注意力分阶段引入
后训练:Specialist + OPD(范式级变化)¶
"the mixed Reinforcement Learning (RL) stage was entirely replaced by On-Policy Distillation (OPD)" 关键转变:从「SFT+RLHF 混炼」转向「分治+合并」: 1. Specialist 训练:每个领域(推理/数学/代码/Agent/对话)单独训练专家模型(SFT → GRPO RL) 2. On-Policy Distillation:十多个专家模型当老师,通过反向 KL loss 蒸馏出统一学生模型
- 反向 KL 让学生集中在老师高概率区域,自动「选老师」 意义:可能是比 MoE 更深刻的范式变化——训练时混合(OPD)而非推理时混合(MoE)。小团队可训多个小 specialist 后蒸馏融合。
评测结果¶
强项¶
- 数学推理:Putnam-2025 满分 120/120,Apex Shortlist 全场第一(90.2),Codeforces 3206 分(人类第 23 名)
- 编程竞赛:LiveCodeBench 93.5 分,Codeforces 双第一(开源首次追平闭源)
- 中文场景:日常中文写作碾压 Gemini
弱项¶
- Agent 能力:全方位落后闭源(Terminal Bench 2.0 67.9 vs GPT-5.4 75.1)
- 真实编程:接近 Opus 4.5(67% vs 70%),差 Opus 4.6 Thinking 13 分
- 创意写作:输给 Opus 4.5
- 长上下文:128K 内稳定,1M 勉强能用(MRCR 1M 83.5 vs Opus 4.6 92.9) 模式总结:V4 擅长做题(有明确答案的任务),在品味型任务上偏弱——映射团队竞赛背景。
深度分析¶
范式转移:从「联合优化」到「分治+合并」¶
V4 后训练最大胆的创新,不是某个具体的算法改进,而是把「多任务联合优化」拆成了「分治+合并」两个阶段。这是一个被低估的结构性变化。 传统 SFT+RLHF 混炼的问题本质是负迁移:数学、代码、Agent、对话的能力在 RL 阶段互相打架。调高数学 reward,代码能力就掉;加 Agent 数据,对话又变笨。这不是超参数没调好,而是联合优化框架的固有问题——reward 信号在多个目标之间必然产生冲突。 V4 的 OPD 把这个困境彻底拆开了:RL 只在专家阶段做,每个专家模型只管一个领域,reward signal 清晰、不妥协。最终学生模型通过反向 KL 蒸馏拿所有专家能力,根本不做 RL。 这个范式的核心洞察是:训练时混合(OPD)比推理时混合(MoE)拥有更大的组合空间。MoE 只能在运行时选择激活哪些专家,而 OPD 可以在训练阶段就让不同领域的知识通过 KL divergence 的「软对齐」实现深度融合。 对资源受限的团队,这意味着:不用一开始就想清楚所有能力的联合优化方案,可以先训多个小 specialist,最后再合并。
mHC 的深层意义:从「加法式残差」到「守恒式残差」¶
Hyper-Connections 论文的核心思路是「让模型自己学习残差连接方式」——把单通道残差流扩展成多通道,模型自己学权重。这条路在学术上非常优雅,但字节团队忽视了工程层面的稳定性问题:信号放大倍数峰值达 3000 倍时,梯度爆炸几乎是必然。 mHC 的解决思路不是改进 HC 的学习机制,而是给它加一个数学护栏:双随机矩阵约束使每层的信号总量守恒。这个约束看起来是放弃了一部分灵活性,但实际上换来了深度 scale 的可行性。 这里有一个更深层的信号:DeepSeek 的技术哲学倾向于在容易出问题的地方加约束,而不是让模型自己学。这和当前主流的「让模型自由学习一切」路线有本质区别。
SwiGLU Clamping + Anticipatory Routing:经验性修复的范式¶
这是论文里最诚实的部分。DeepSeek 明确说了:这两个 trick 有效,但「underlying principles remain insufficiently understood」。 Anticipatory Routing 解决的是「异常专家输出 → 路由器误判 → 更多任务派给该专家 → 更异常」的崩溃循环。解法是让路由器用「昨天的参数」做决策,解耦主干更新和路由选择。这个思路在工程上非常直觉,但没有清晰的梯度分析支撑。 SwiGLU Clamping 则是给激活函数的数值输出加硬截断(-10 到 10),防止某些神经元在超大规模训练时输出爆炸。这也是经验性修复。 这类经验性修复在深度学习领域并不罕见,但能如此坦然地写进论文并强调「不理解」的团队极少。这反映了一个更成熟的研究心态:有效性和可解释性不矛盾,先有效再理解。
Muon 优化器的结构性意义¶
AdamW 的「单旋钮独立调整」逻辑在高维场景下天然会产生「热门方向过度优化、冷门方向欠优化」的问题。Muon 的「整体方向正交化」思路从根本上是把优化过程从「单独调每个旋钮」升级到「整组旋钮协同更新」。 但 Muon 有两个关键限制: 1. 只对矩阵参数有效(非矩阵参数如 embedding、prediction head、RMSNorm 仍然用 AdamW) 2. 每步需要额外的正交化计算(Newton-Schulz 迭代,10 步) V4 的实现用激进前 8 步 + 温和后 2 步做精度平衡,这个工程细节说明 DeepSeek 在训练效率上做了大量摸索。
架构复杂性:V4 的诚实承认¶
论文里提到架构「太复杂」:保留了太多初步验证过的组件。mHC、CSA、HCA、MTP、Shared KV MQA、Sliding Window、Attention Sink……这些机制叠加在一起,让 V4 的架构成为少数人能够完全理解的系统。 这种复杂性不是技术债务,而是当前超大规模模型训练的客观现实:每个机制单独拿出来都能讲清楚,但叠加后的交互效应难以预测。论文的诚实之处在于没有试图给这个复杂性找借口。
实践启示¶
对模型训练团队¶
- 深度 Scale 前先解决数值稳定性:mHC 的守恒约束不是「锦上添花」,而是「必要条件」。模型从 671B 推到 1.6T,如果没有这个约束根本无法训练。
- 超长上下文训练用渐进式引入:V4 的序列长度从 4K → 16K → 64K → 1M 分阶段扩展,稀疏注意力也是逐步引入。这个策略降低了训练不稳定性的风险。
- 专家分离训练 + OPD 蒸馏是可行的多任务解法:不需要一开始就设计联合优化方案,先分领域训专家,再通过反向 KL 合并。这个范式对资源有限的团队尤其有价值。
对 Agent 应用开发者¶
- V4-Flash 是当前最具性价比的百万上下文模型:价格约为同类快速模型的 1/7 到 1/18,128K 以内性能稳定,适合需要长上下文但成本敏感的场景。
- 不要用 V4 做创意写作或品味型任务:V4 在有明确答案的任务上表现顶尖,但品味型任务(创意写作、综合架构决策)仍然落后于 Opus 4.5/4.6。对于这类需求,闭源模型仍然更合适。
- V4 的 Agent 能力有上限:Terminal Bench 2.0 67.9 分,落后 GPT-5.4 约 7 分。对于高复杂度的多步 Agent 任务,当前开源模型仍有差距。
对研究者¶
- 经验性修复值得记录:SwiGLU Clamping 和 Anticipatory Routing 这类「不理解但有效」的 trick,是训练大规模模型时不可避免的发现,应该被系统性地记录和分享。
- 反 AI 生成内容的过滤是必要的数据工程:互联网语料中 AI 生成文本的比例会持续上升,不做过滤会导致模型坍缩。这是预训练数据处理的关键步骤。
- OPD 的「自动路由」特性值得深入研究:反向 KL 让学生自动对齐高概率区域,这个机制和多专家混合的内在联系还远没有被充分理解。
对组织决策者¶
- V4 证明了「开卷有益」的 Open AI 路线:DeepSeek 的 Open 不是只开源权重,而是提供完整的训练细节、实验记录、甚至失败经验。这种开放程度对行业整体进步有推动价值。
- 小团队可以通过 Specialist + OPD 路径训练大模型能力:不需要一开始就训超大模型,训多个小专家再蒸馏合并,是资源受限团队可行的路径。
Cross-links¶
相关实体¶
-
We Tested DeepSeek V4 Pro and Flash Against Claude Opus 4.7 and Kimi K2.6
- Redis之父下场,给DeepSeek V4单独造了一台推理引擎
- MOC
Ch15.016 Fine-Tuning NVIDIA Cosmos Predict 2.5 with LoRA/DoRA for Robot Video Generation¶
📊 Level ⭐⭐⭐ | 12.2KB |
entities/fine-tuning-nvidia-cosmos-predict-25-with-loradora-for-robot-video-generation.md
核心要点¶
- 世界模型 + 机器人视频生成:Cosmos Predict 2.5 是能生成物理可信视频的大型世界模型,微调后可作为机器人操作的合成数据生成器
- LoRA/DoRA 参数高效微调:通过低秩适配器注入冻结的 2B 参数模型,仅训练 ~50M 参数,保留基础能力同时学习领域特定知识
- 实测效果:100 epochs(8× H100 上约 2.5 小时)即可显著提升物理可信性和指令遵循能力
- 多维度评估:Sampson Error(几何一致性)+ Physical Plausibility + Instruction Following 三个指标综合评估
- DoRA vs LoRA:在高 rank(32)时性能相近,DoRA 在极低 rank 或不稳定场景下略有优势
深度分析¶
为什么需要微调世界模型?¶
Cosmos Predict 2.5 作为通用世界模型,在处理机器人领域特定任务时存在三个核心问题: 1. 分布偏移(Distribution Shift):机器人手臂、夹爪、工具等物体对模型来说是 out-of-distribution,导致模型幻觉出人手而非机器人手臂 2. 指令遵循不一致:模型可能不按指令指定的手(左手/右手)或物体执行动作 3. 几何不稳定:视频帧间存在抖动,多视角几何不一致 微调的本质是将通用世界模型的「物理直觉」与特定机器人平台的「运动学特征」对齐。
LoRA/DoRA 技术选择逻辑¶
| 特性 | LoRA | DoRA |
|---|---|---|
| 原理 | 低秩矩阵分解 | 幅度+方向分解 |
| 参数量 | r×d (相同 rank) | 略多于 LoRA |
| 训练稳定性 | 良好 | 略优 |
| 极低 rank 表现 | 可能不稳定 | 更好 |
| 内存开销 | 相同 | 略高 |
| 适用场景 | 通用场景,rank≥16 | 内存受限或极低 rank |
| 关键洞察:DoRA 的幅度-方向分解相当于对权重更新施加了额外的结构先验,这有助于在 rank 较低时维持表达能力。但当 rank=32 时,两种方法收敛到相近性能。 |
合成数据范式:成本与质量的权衡¶
传统机器人数据收集:
- 成本:$10K-$100K per robot per task
- 时间:数周至数月
-
局限性:特定任务、特定机器人、特定环境 合成数据生成:
-
成本:GPU 时间 + 人工标注
- 时间:数小时
- 扩展性:一个领域训练的 LoRA 可迁移到类似领域 但注意:合成数据的质量上限受世界模型能力限制。如果基础模型无法理解某个物理现象,微调后的模型也无法生成正确的合成数据。
评估体系设计亮点¶
- Sampson Error:传统几何计算机视觉指标,用于评估视频的几何一致性——这在机器人学习场景中非常重要,因为合成轨迹需要与真实物理世界对齐
- LLM-as-a-Judge:使用 VLM (Cosmos Reason2) 进行物理可信性和指令遵循的自动化评分,解决主观评估的规模化问题
- 多 seed 评估:每个测试用例生成 5 个视频取平均,减少随机性影响
实践启示¶
何时考虑微调 vs 提示工程¶
| 场景 | 推荐方案 |
|---|---|
| 快速原型验证 | 使用 base model + 详细提示 |
| 单次/低频任务 | 详细提示词工程 |
| 频繁使用的领域任务 | LoRA/DoRA 微调 |
| 多个相关领域 | LoRA adapters + 动态切换 |
| 极度资源受限 | DoRA r=8 |
LoRA Rank 选择决策树¶
开始
│
├─ 内存充足且任务复杂?
│ └─ 是 → LoRA r=32 或 DoRA r=32
│
├─ 观察到低 rank 训练不稳定?
│ └─ 是 → DoRA r=32
│
├─ 内存非常紧张?
│ └─ 是 → LoRA r=8 或 DoRA r=8
│
└─ 默认推荐 → LoRA r=32
训练配置建议¶
- Epochs:从 100 开始,根据验证集 loss 曲线调整;过拟合迹象出现时提前停止
- Batch Size:单 GPU 80GB 显存下 batch_size=1(受限于视频内存占用)
- Learning Rate:使用线性 warmup + decay 调度,默认值适用于大多数场景
- Gradient Checkpointing:开启以节省显存,允许更大分辨率或更长序列
- Mixed Precision:bf16 训练,注意 LoRA 参数 upcast 到 fp32 以保证数值稳定
数据准备最佳实践¶
- 视频格式:MP4,清晰展示物体交互
- Prompt 质量:准确描述动作(手、物体、目标位置)
- 数据量:文章使用 92 个视频进行训练,对特定垂直场景可能需要更多
- 时序采样:随机采样连续的 num_frames 帧作为时序增强
推理与部署¶
- LoRA 热切换:训练多个 domain-specific adapters,推理时动态加载,实现一个 base model 服务多个垂直场景
- fuse_lora:合并权重到 base model,消除推理时额外计算开销(但失去动态切换能力)
- 批量生成:使用同一 LoRA 批量生成多样本,筛选高质量轨迹用于策略学习
相关实体¶
- Nvidia Cosmos Fine Tuning Robot Video Generation
- Fine Tuning Nvidia Cosmos Predict 2 5 With Lora Dora For Robot Video Generation
- Fine Tuning Cosmos
- Navigating Eu Ai Act Requirements For Llm Fine Tuning On Amazon Sagemaker Ai
- A2Rd Agentic Autoregressive Diffusion Long Video
→ 原文存档
从合成数据到真实机器人的 Pipeline¶
Cosmos Predict 2.5 + Domain LoRA
↓
生成多样化合成轨迹
↓
质量筛选(物理可信性 + 指令遵循分数)
↓
合成轨迹数据集
↓
行为克隆 / RL 训练机器人策略
↓
真实机器人部署
Ch15.017 Yann Dubois(OpenAI Post-Training)× Matt Turck 深度访谈:GPT-5.5、RL 突破、后训练流水线¶
📊 Level ⭐⭐⭐ | 10.7KB |
entities/yann-dubois-openai-post-training-interview.md
核心人物¶
Yann Dubois:OpenAI 后训练前沿团队(Post-Training Frontiers)联合负责人。GPT-5.5、o3、GPT-5 Thinking 核心推理模型均经过其团队之手。Stanford Alpaca(600美元微调复现 GPT-3.5)和 AlpacaEval(业界最广泛指令跟随自动评估工具)作者。
Matt Turck:纽约早期风投 FirstMark Capital 合伙人,MAD Landscape 年度 AI 全景图发布者(2024版含2011个公司logo)。
核心洞察¶
可靠性临界点已跨过¶
关键判断:AI 进步一直是连续的,但人们感受像台阶函数,原因有三: 1. 可靠性临界点(最关键):去年12月跨过这道坎,AI 工具真正变得有用 2. 模型加速自身:内部研发速度随模型变强形成正向飞轮 3. RL 从竞赛走向实用:为"可验证奖励"开发的工具和方法用到真实场景
核心比喻:把 Agent 模型想象成每两分钟有一定概率出错的系统——不断降低"每两分钟出错"概率,当低到一定程度后使用者感受发生质变。
GPT-5.5 情绪过山车¶
每个模型在内部都会经历:兴奋→唱衰期→发布→外界反馈好。GPT-5.5 波动幅度最大。
- 效率提升:速度约 2 倍提升
- 全公司对齐:预训练到推理优化到后训练每个团队都朝同一方向发力
纵向 × 横向团队¶
- 纵向团队:专注特定应用场景(Agent编程/计算机操控/知识工作)
- 横向团队(Yann 团队):决定最终训练放什么、整合纵向改进、通用改进(指令遵循/函数调用/思考时间分配)
- 好处:纵向和横向改进可以正交进行
思考效率:对数曲线¶
GPT-5.5 Thinking vs Pro 本质是测试时计算量不同。模型想得越久正确率越高,但对数形式——投入2倍计算只换来一点点提升。
专家 vs 实习生比喻:实习生花1-2天尝试10个方向,专家凭经验知道该走哪个方向不浪费。效率提升本质是让模型变成"专家"。
大模型天然更高效:通过权重"思考"了一部分问题,不需要在推理时用额外 token 想;虽然单个 token 成本更高,但大模型在 GPU 上更容易并行优化,总体效率更好。
预训练没撞墙¶
- Anthropic Mythos 仅靠增大模型规模就获得很好性能
- 各家公司找到了绕过互联网数据不够的方法(多模态或合成数据,但 Yann 不能多说)
- 意外观察:Anthropic 模型多模态并不特别强,但依然非常聪明——多模态数据至少没有以前想的那么必要
- 多模态真正发挥可能要到具身智能成熟时
图书馆 → 专家:训练流水线比喻¶
预训练:走进图书馆,所有信息都在但得自己翻,什么都有(广告/论坛/维基)一视同仁全学
中训练(Mid-training):从图书馆挑出高质量书(Wikipedia/GitHub代码)多读几遍,加权训练高信息密度内容
后训练:把读过所有书的"学霸"变成可直接提问的"专家"
后训练两阶段¶
SFT(监督微调):人类标注员提供标准答案,模型模仿。问题:能力被标注员水平锁死,永远不会超过"老师"。
RL(强化学习):不给标准答案而给评判规则,模型自己尝试、对的奖励错的惩罚,可超越人类标注员水平。
开源社区收敛到 GRPO:最简方法——采样大量回答,判断哪个对,强化对的。"最简单的可以用计算扩展的方法最终总是赢的那个。"
RL 为什么现在管用了¶
关键洞察:模型跨过一定规模后(对世界有了足够好的先验知识),RL 就开始管用了。这不仅是 LLM 的现象——机器人领域也进入同样阶段。
RL 挑战:
- 基础设施:采样海量回答的计算开销大
- ML层面:Agent 任务中最头疼是归因问题——长推理流程最终成功/失败,到底哪一步导致的?信息太稀疏
能力横向泛化 vs 精确→模糊泛化难题¶
- 能力层面泛化(已发生):数学竞赛强→编程竞赛通常也不差,因为底层能力一样
- 领域层面缺陷(横向问题):某方面有缺陷(如幻觉),在所有领域都有这个缺陷
- 精确→模糊泛化(未解决):数学/编程竞赛题目定义非常精确,真实世界里咨询顾问/金融从业者首先得上网搜索提取信息理解问题,才能推理
核心名言¶
"在机器学习中,我们反复看到这样一个规律:最简单的、可以用计算来扩展的方法,最终总是赢的那个。"
"通常的规律是:一开始是手艺。人们尝试很多东西,逐渐建立起什么管用、什么不管用的直觉。然后随着时间推移,才慢慢过渡到科学。"
深度分析¶
Post-training 的核心挑战:从 SFT 到 RL 的范式转变¶
Yann Dubois 指出了 post-training 领域的一个核心矛盾:Scaling Law 告诉我们 scaling pretraining 是可靠的,但如何 scaling post-training 仍然是一个 open problem。SFT 这条路径已经被验证,但天花板明显;RL 是更有潜力的方向,但如何设计 reward、如何避免 reward hacking、如何处理 credit assignment,都是尚未解决的工程挑战。
关键洞察:Post-training 不是在模型上做手术,而是在模型的"思考方式"上做雕刻。不同的 post-training 方法塑造了模型不同的推理风格和能力边界。
不对齐的对齐:LLM 的"伪对齐"问题¶
有趣的是,Dubois 指出在某些任务上,未对齐的模型(没有经过 RLHF/PPO 的模型)反而表现更好。这揭示了一个深层问题:RLHF 可能带来「对齐税」——为了让模型符合人类偏好,可能牺牲了模型在某些任务上的原始能力。
这意味着:对齐不是单向的增强,而是有代价的能力重新分配。
Inference Time Scaling 的工程化瓶颈¶
Inference-time scaling(测试时计算)是 2025 年的主战场,但 Dubois 指出了这条路径的工程化瓶颈:当你想把 test-time compute scaling 到极致时,最大的问题不是算法,而是延迟和成本。用户对延迟的容忍度是有上限的,而 scaling inference 的成本是指数级的。
这指向了一个重要结论:scaling 预训练和 scaling inference 是两条不同的路径,前者解决能力上限,后者解决效率问题。
能力与安全性之间的"可调节性"¶
Dubois 提到的一个关键设计哲学是:能力(capability)和安全性(safety)应该是可调节的,而不是绑定在一起的。传统观点认为更强的模型就意味着更危险,但 Dubois 认为更准确的说法是:更强的模型意味着更大的可控范围——你可以把它调得更安全,也可以把它调得更能力导向。
这对于 Agent 系统设计有直接含义:选择什么能力的模型,不应该只由"它有多强"决定,还应该由"它的安全边界是否可预测"决定。
实践启示¶
1. Post-training 方法选型:从任务复杂度出发¶
不是所有任务都需要 RLHF。如果你的任务有明确的正确答案(代码补全、数学推理),SFT 可能就足够了。如果你的任务需要模型在开放域做复杂推理,并且需要模型学习"如何思考"而非"思考什么",那么 RL-based 方法更合适。
2. 警惕"对齐税"在生产环境中的影响¶
如果你的应用场景是工具调用、代码生成等有明确目标的任务,未对齐的模型可能表现更好。在评估模型时,不要只评估 raw capability,还要评估在 RLHF 之后是否有能力损失。
3. Inference scaling 的延迟约束¶
当你在设计需要低延迟的 Agent 系统时,test-time compute scaling 的收益会被延迟上限严重约束。在这种情况下,pretraining scaling 的收益更稳定,因为它不引入额外的推理延迟。
4. 在 Agent 系统设计时,考虑模型的"可调节性"¶
如果一个模型的能力边界和行为模式是不可预测的,把它放在 Agent 系统里会是危险的。选择模型时,稳定性(行为可预测)和能力同样重要。
相关实体¶
相关主题¶
- OpenAI 推理模型(o1/o3/o4-mini) — OpenAI 推理模型系列
Ch15.018 Fine-Tuning NVIDIA Cosmos Predict 2.5 with LoRA/DoRA for Robot Video Generation¶
📊 Level ⭐⭐⭐ | 8.7KB |
entities/nvidia-cosmos-fine-tuning-robot-video-generation.md
核心要点¶
- 参数高效微调:LoRA/DoRA 仅需训练 ~50M 参数(相比 2B 总量),单 GPU 可运行
- 域适应能力:解决通用世界模型在机器人手臂、手部、工具等领域的分布偏移问题
- 合成数据生成:为机器人策略学习提供可扩展的合成轨迹,降低真实数据收集成本
- 多维评估体系:Sampson Error(几何)+ Physical Plausibility(物理)+ Instruction Following(指令)
- 实用配置:rank=32, 100 epochs, ~2.5 小时 8×H100
深度分析¶
为什么世界模型需要微调¶
Cosmos Predict 2.5 作为通用视频生成模型,在未微调状态下存在三类典型缺陷: 1. 外观幻觉:机器人手臂被替换为人类手部(out-of-distribution 导致的分布外幻觉) 2. 动作错误:不遵循指令指定的手(左手/右手)或目标物体 3. 几何失真:帧间抖动、多视角不一致 微调的本质是让模型学习特定机器人平台的视觉和运动学特征,而非重新学习通用物理规律。
LoRA 机制的技术原理¶
LoRA 在 DiT 的注意力层和前馈层注入低秩矩阵:
训练时:- 冻结原始权重 W₀
- 仅训练 A、B 矩阵
-
推理时:W = W₀ + (α/r) × ΔW 优势:
-
显存占用大幅降低(从 2B 参数量降至 ~50M)
- 适配器文件小(~200MB),便于分发和切换
- 可为不同领域训练多个 adapter,运行时动态加载
DoRA 的增量改进¶
DoRA 将权重分解为幅度和方向两部分:
其中 m 是可学习的幅度标量。直觉上,DoRA 让模型分别学习「改变多少」(幅度)和「往哪个方向变」(方向),提供额外的表达能力。 实验结果显示:rank=32 时 LoRA 与 DoRA 性能相当,但在极低 rank(r=8)或训练不稳定场景下 DoRA 表现更好。合成数据的价值与局限¶
价值:
- 真实机器人数据收集成本 $10K-$100K/task
- 合成数据可在数小时内生成大量多样化轨迹
-
可以覆盖危险场景、稀有物体、极端条件 局限:
-
受限于世界模型的物理理解上限
- 模拟到真实的 sim-to-real gap 需要处理
- 需要高质量 prompt 描述期望动作
评估指标设计分析¶
| 指标 | 衡量内容 | 为什么重要 |
|---|---|---|
| Temporal Sampson Error | 帧间几何一致性 | 物理可信的运动轨迹 |
| Cross-view Sampson Error | 多视角一致性 | 3D 空间理解 |
| Physical Plausibility | 物理规律遵循 | 合成数据的物理有效性 |
| Instruction Following | 指令执行正确性 | 任务完成的保证 |
实践启示¶
微调前的 Checklist¶
- 明确目标域:机器人类型(单臂/双臂/轮式)、相机配置、任务类型
- 评估数据量:92 个视频对 GR00T 级别任务足够,但垂直领域可能需要更多
- 确定评估指标:物理可信性 vs 指令遵循哪个更重要
- 准备计算资源:80GB GPU 最小,8×H100 加速迭代
训练超参数建议¶
lora_rank: 32 # 平衡表达力和效率
lora_alpha: 32 # = rank 保持 scale factor = 1.0
num_epochs: 100 # 从 100 开始,观察 val loss 调整
learning_rate: 1e-4 # 标准设置
warmup_steps: 100 # 渐进式学习率预热
DoRA 适用场景¶
当出现以下情况时,考虑切换到 DoRA:
- 使用极低 rank (r=8) 且训练 loss 震荡
- 观察到 LoRA 过拟合但又不希望增大 rank
- 任务需要更精细的方向控制
相关实体¶
- Fine Tuning Nvidia Cosmos Predict 25 With Loradora For Robot Video Generation
- Fine Tuning Nvidia Cosmos Predict 2 5 With Lora Dora For Robot Video Generation
- Fine Tuning Cosmos
- Navigating Eu Ai Act Requirements For Llm Fine Tuning On Amazon Sagemaker Ai
- Video Agent Paradigm Compute Talent Flywheel Ethan He 20260606
→ 原文存档
应用 Pipeline¶
1. 准备领域数据
└─ 视频 + 文本描述(手、物体、动作)
2. 训练 LoRA/DoRA
└─ 2.5 小时 / 100 epochs @ 8×H100
3. 生成合成轨迹
└─ 批量生成 + 多 seed 去噪
4. 质量筛选
└─ Physical score > 4.0
└─ Instruction following > 4.0
5. 机器人策略学习
└─ 合成数据 → 行为克隆 / RL
6. Sim-to-Real 部署
└─ Domain randomization
└─ 域适应微调
Ch15.019 无惧Off-Policy偏移!Bengio团队解绑后训练,大模型RL提速50倍¶
📊 Level ⭐⭐⭐ | 8.5KB |
entities/trajectory-balance-asynchrony-tba-bengio-papweekly.md-> 原文存档
TBA:解绑后训练,RL 提速 50 倍¶
一句话¶
Yoshua Bengio 团队(NeurIPS 2025):异步框架把 RL 后训练的采样(Searcher)和训练(Trainer)解耦,轨迹平衡目标让 off-policy 数据直接用于学习,数学推理任务最高提速 50 倍。
核心问题¶
LLM 后训练中,rollout(逐 token 生成)慢,训练(并行计算)快。主流 on-policy 方法(PPO、RLOO、GRPO)必须等 rollout 完成才能更新策略,算力浪费严重。
解决方案:TBA 架构¶
Searcher:维护滞后模型权重,负责采样生成轨迹,存入本地 replay buffer
Trainer:持续从全局 buffer 抽样子耍更新模型,不必等待 rollout
同步周期 k:每隔 k 步同步权重 + 汇总经验
轨迹平衡(TB)目标:off-policy 数据只要分布有 full support 即可用于训练,无需重要性采样修正
动态采样:概率 m 选最近样本(稳定)+ 1-m 概率用 Softmax + 均匀采样(多样)
关键数字¶
- GSM8K:比 VinePPO 提速 50 倍,准确率 +1.2%~1.8%
- TL;DR PFT:比异步 DPO 快 3.8~5.3 倍
- 自动红队:比同步 GFlowNet 提速 7 倍
深度分析¶
异步架构的本质:解耦搜索与学习¶
TBA 的核心突破在于将 LLM RL 后训练中固有的「采样-训练」耦合彻底拆除。传统 on-policy 方法要求策略在生成轨迹后才能更新,这导致快速计算单元(GPU 并行训练)必须等待慢速生成单元(自回归 token 解码),算力利用率长期低迷。TBA 通过引入双进程架构——Searcher 负责采样、Trainer 负责更新——让两者并行运作,通过全局 replay buffer 异步交互。这意味着训练不再阻塞于 rollout,Trainer 可以持续利用历史样本提升策略。
轨迹平衡目标为何适合 off-policy 场景¶
轨迹平衡(TB)目标来自 Flow-based 生成模型理论,其梯度形式在 on-policy 时退化为类似 REINFORCE 的标准策略梯度。关键在于 TB 的「full support」性质:当采样分布覆盖当前策略的支持集时,即使轨迹来自旧策略,其梯度估计依然无偏。这意味着 TBA 无需使用 PPO 等方法中的重要性采样修正——那些修正在 off-policy 程度加深时往往引入剧变方差甚至数值崩溃。TB 的这种鲁棒性来自其目标函数的形式:它不直接依赖策略概率比,而是通过轨迹级别的平衡约束隐式处理分布偏移。
动态采样 m 的调节逻辑与敏感性¶
Buffer 规模增长后,纯随机采样效率低下(低奖励样本稀释学习信号),纯优先级采样又会导致输出多样性崩溃。TBA 的混合采样通过超参数 m(Most-On-Policy Probability)控制:m 比例采样最新同步数据保证稳定性,1-m 比例通过奖励 Softmax + 均匀采样维持多样性。实验显示数学推理任务对 m 敏感度较高,可能因为数学问题的奖励 landscape 更崎岖,需要更多近期样本来保持训练稳定。这一发现暗示:在奖励信号稀疏或非连续的领域,m 应该设置得更高。
与 DPO 异步变体的关键区别¶
异步 DPO 同样尝试采样-训练解耦,但 DPO 的偏好对比损失对 off-policy 偏移的敏感度远高于 TB。DPO 要求样本来自当前策略或其邻近分布,否则 KL 约束项会引入偏差。TBA 的 TB 目标在异步环境下展现出远超异步 DPO 的稳定性,且在 TL;DR 摘要任务中形成更好的 Pareto 前沿——这说明 TB 目标的分布匹配假设比 DPO 的对比学习假设更适合大规模异步场景。
搜索er扩展性:自动红队场景的启示¶
自动红队实验中,Searcher 扩展性带来更高攻击成功率和 prompt 多样性。这揭示了一个重要规律:当奖励稀疏时(如安全红队),采样数量比采样质量更关键。Searcher 数量增加等同于探索宽度扩展,即便每个 Searcher 的策略相对落后,汇总后的 replay buffer 也能覆盖更广的状态空间。TFlyPerch 的同步 GFlowNet 基线在稀疏奖励下表现受限,正是因为同步等待机制严重压缩了有效探索步数。
实践启示¶
工程落地要点¶
- 同步周期 k 的选择:k 太小(如 k=1)等同于同步训练,失去异步优势;k 太大导致 Searcher 策略严重落后,TB 的 off-policy 容忍度虽然高于 PPO,但过大的策略偏移仍会降低样本效率。建议从 k=10~50 开始,根据 GPU 集群规模调整。
- Replay Buffer 内存管理:Searcher 本地 buffer 存轨迹,Trainer 从全局 buffer 抽样。轨迹长度可能达到数万 token(如长回答任务),需预估内存峰值:Buffer 容量 × 平均轨迹长度 × Token 嵌入维度。
- m 的领域适配:数学/代码等奖励信号连续且可微的领域,m 可适度降低(0.6~0.8);偏好学习/安全等奖励稀疏或离散的领域,建议 m ≥ 0.9。
适用场景判断¶
TBA 最适合以下场景: - rollout 成本高、训练成本低:如大模型生成、复杂环境交互 - off-policy 数据可获取:已有大量历史轨迹或可利用其他模型的采样 - 奖励信号相对稠密:TB 对稀疏奖励的容忍度不如密集奖励
TBA 不适合以下场景: - 完全同步要求:某些安全关键应用不允许异步权重更新 - 轨迹极短且 rollout 极快:此时异步开销可能超过收益 - 重要性采样修正必须精确:如果你的场景要求严格 on-policy(如某些理论分析必须保证无偏梯度),TB 的 full support 假设可能不满足
与现有基础设施的整合¶
对于已有 PPO/GRPO 管线的团队,TBA 的迁移成本主要集中在: - 实现 Searcher-Trainer 双进程架构 + 全局 replay buffer - 替换策略梯度损失为 TB 目标(VarGrad 版本) - 调整同步周期 k 和采样超参数 m
代码库层面,TBA 的核心修改集中在 Reward Model 下游、Policy 更新上游,理论上可以保留大部分现有基础设施。
一句话总结¶
TBA 把采样从训练闭环里解耦出来——这是 LLM RL 后训练数量级效率提升的核心。
相关实体¶
- On Policy Distillation Vs Offline Distillation Loster
- Overcoming Reward Signal Challenges Verifiable Rewards Based Reinforcement Learn
- Reinforcing Recursive Language Models Alphaxiv
- Skillos
- Yann Dubois Openai Post Training Interview
Ch15.020 xOPD 全景梳理:16 篇论文拆解 On-Policy Distillation 的六个维度与教师角色演化主线¶
📊 Level ⭐⭐⭐ | 7.9KB |
entities/xopd-on-policy-distillation-landscape-banana-2026.md
xOPD 全景梳理:On-Policy Distillation 六维分类与演化主线¶
核心结论¶
OPD(On-Policy Distillation)领域在 2026 年初密集爆发 16+ 篇论文,表面是各种 loss 变种竞赛,底层演化主线是:"教师"角色从全程保姆逐步退化为鉴别器——到 RLRT,教师只负责告诉学生"什么不是你的",reward 负责告诉学生"什么是对的"。
"OPD 会是终局吗?不会,但它揭示的视角会是终局的一部分——post-training 的 teacher signal 不应该是静态的,它应该跟着 student 当前的状态、能力、置信度、对错动态调整。"
六维分类框架¶
每篇 xOPD 论文的设计可沿六个维度定位:
维度 1:Loss 怎么写¶
| 变体 | 代表工作 | 核心做法 |
|---|---|---|
| Reverse KL | vanilla / SDPO / SRPO | 标准 token 级 KL 散度 |
| Token 概率比→advantage weight | RLSD / RLRT | 师生概率比直接调 GRPO magnitude |
| Advantage 符号切 RL/KL | AOPD | 正 advantage=exploitation,非正=imitation |
| 信任区域 reverse↔forward KL | TrOPD | 可信区 reverse KL,outlier 区 forward KL |
| Rubric reward→GRPO | ROPD | LLM rubric 打分替代 logit matching |
| Outcome 约束 trajectory KL 序 | Uni-OPD | 让 token KL 接受 trajectory outcome 监督 |
| OPSD 降级为 sigmoid 门控 | SDAR | 主目标仍是 RL,OPSD 为辅助项 |
维度 2:教师信号怎么来¶
| 来源 | 代表工作 | 说明 |
|---|---|---|
| White-box logits | vanilla 大多数 | 需要 teacher 白盒访问 |
| Black-box rubric/verbal | ROPD | AUC 0.90 vs logits AUC 0.35 |
| Self-distill privileged context | SDPO / RLSD / RLRT / SDAR | 同模型不同信息条件 |
| 正确 vs 错误 sibling rollout 对比 | RLCSD | 对照减掉风格漂移 |
| 模型自己的不同 mode | OPSDL | 短上下文版教长上下文版 |
维度 3:哪些 token/sample 该被加权¶
| 策略 | 代表工作 |
|---|---|
| 均匀 | vanilla |
| 按 advantage 符号 | AOPD |
| 按 step divergence | SOD |
| 按信任区域 + outlier 处理 | TrOPD |
| 按 teacher endorse/reject 极性 | SDAR |
| 对错对比→task token 集中 | RLCSD |
| 只在 r=0 | SRPO |
| 只在 r=1 | RLRT |
| cosine alignment 过滤 | Apple |
维度 4:教师拉学生的方向¶
- 大多数:把 student 往 teacher 拉(standard distillation)
- RLRT:第一个反过来——成功时奖励 student 偏离 teacher 的 self-driven token
- Apple:有些 token 上根本不该拉(信号负价值)
- TrOPD:有些 token 不是不该拉,是 reverse-KL 数值会爆,得换 forward KL
维度 5:算力/数据效率¶
| 策略 | 代表工作 |
|---|---|
| 在线 sampling | 默认 |
| Offline cache | Lightning OPD(4× 算力节省) |
| Self-distill 无外部 teacher | OPSDL / OPSD 整条线 |
维度 6:PI 结构(Privileged Information)¶
Many Faces of OPD 的关键区分:
| PI 类型 | 含蒸效果 | 代表场景 |
|---|---|---|
| Shared-rule | ✅ 聚合=内化规则 | 系统提示词、风格指令、对齐偏好 |
| Instance-specific | ❌ 聚合=拍糊+幻觉 | 具体题目的 GT、特定文档 |
学生在 inference 时会幻觉性地说出"如参考答案上所言"——它学到的不是解题能力,而是"有 GT 在条件里"这件事的统计痕迹。
演化主线:教师角色逐步退化¶
vanilla OPD (全程保姆)
→ Apple 诊断 (很多 token 帮倒忙)
→ SOD (加信任度门)
→ TrOPD (有些 token 数值上没法听)
→ ROPD (logit AUC < 0.5, 换 rubric)
→ Lightning (不必全程在场, 离线缓存够)
→ SRPO (做对时闭嘴)
→ RLCSD (信号里混了风格腔调, 对照减掉)
→ SDAR (拒绝信号未必可信, 软性衰减)
→ RLRT (退化为鉴别器: 只标记"什么是学生自己的")
RLRT 的标志性翻转:Qwen3-4B-Base 在 6 个数学 benchmark 上比 GRPO +18%,仅仅是把 token 权重分子分母对调 + 只在正确轨迹 apply。
关键诊断发现¶
Apple Unmasking OPD (arXiv 2605.10889)¶
- 成功轨迹上 teacher alignment ≈ 0.001(几乎正交)——白白浪费梯度预算
- 失败轨迹上 alignment ~0.05,显著正向
- 只保留 positive alignment 的 52% token → 10-15× 有效信号
- Comprehensibility 假设:梯度信号只有在 student 能 parse 时才有用
- 0.6B self-distillation > 32B 外部 teacher 2-3×
RLCSD 风格漂移诊断 (arXiv 2606.11709)¶
- Privilege-induced style drift:style token 信号均值 0.263,task token 只有 0.083(3× 差距)
- 解法:用错误提示做对照,逐字节模板相同→风格漂移在相减中抵消
Many Faces of OPD (arXiv 2605.11182)¶
- OPSD 学到的是所有 PI 上的边际聚合策略
- Shared-rule PI → 内化 ✅;Instance-specific PI → 幻觉 ❌
- RLVR-adapted teacher:teacher 的 benchmark 分数甚至不需要更高,只要分布跟 student 更贴
Self-Distillation vs 外部 Teacher 两条线¶
| 维度 | 外部 Teacher OPD | Self-Distillation (OPSD) |
|---|---|---|
| KL 方向 | Reverse KL (mode-seeking) | Forward KL 更稳 (mode-covering) |
| 原因 | capacity gap 存在 | 共享权重,无 capacity gap |
| PI 角色 | teacher 本身就是 privileged | PI sharpen student conditional |
| 代表 | vanilla / SOD / TrOPD / ROPD | SDPO / RLSD / RLRT / RLCSD |
Self-Distilled Reasoner 验证:full-vocab logit distillation > sampled-token policy gradient(与 DeepSeek V4 工程结论一致)。
教育学类比¶
"OPD 这一波从 vanilla 到 RLRT 的演化,几乎是把教育学争论在算法层面重新跑了一遍——从'老师即标准答案',到'老师只在学生卡住时出手',再到'老师只负责识别哪些是学生自己做出的选择'。"
| 教育学派 | 对应 xOPD | 核心 |
|---|---|---|
| 传统课堂 | vanilla OPD | 老师提供标准答案,学生精确复刻 |
| 脚手架理论 | SOD / SDAR | 老师在学生卡住时出手 |
| 激进 unschooling | RLRT | 连脚手架都不该有,学生自己摸 |
| 建构主义 | Many Faces / Self-Distill | 老师是"更好信息条件下的自己" |
Reading List(精选 Top 5)¶
| 论文 | arXiv | 必读度 | 核心贡献 |
|---|---|---|---|
| Apple Unmasking OPD | 2605.10889 | ⭐⭐⭐⭐ | 诊断:什么时候 work/不 work |
| Many Faces of OPD | 2605.11182 | ⭐⭐⭐⭐ | OPSD 何时塌:shared-rule vs instance-specific |
| RLRT (Rebellious Student) | 2605.10781 | ⭐⭐⭐ | 教师角色翻转,+18% |
| RLCSD | 2606.11709 | ⭐⭐⭐ | 对比抵消风格漂移 |
| Self-Distilled Reasoner | 2601.18734 | ⭐⭐⭐ | OPSD 源头,forward KL 胜出 |
完整 16 篇 reading list + arXiv 链见原文附录。
相关实体¶
- Opd Revisiting Failure Modes Simple Fixes Storm
- Rlhf Dpo Grpo Alignment
- Deepseek V4 Training 58 Page Paper Deep Dive
→ 原文存档
Ch15.021 LLM Post-Training全景指南:从RLHF到GRPO再到AgenticRL¶
📊 Level ⭐⭐⭐ | 7.6KB |
entities/llm-post-training-full-guide.md
核心框架¶
SFT教模型"说什么",偏好优化教模型"怎么选",RL教模型"怎么想"——三者层层递进,构成完整Post-training体系。
训练方法演进¶
SFT(监督微调)¶
教会模型输出的格式和风格,本质是模仿,无法超越训练数据的能力。LoRA/QLoRA只需训练0.1%~1%参数。
RLHF(三步)¶
- SFT冷启动
- 训练Reward Model(人类偏好排序)
- PPO优化(四模型:Policy + Reference + Reward + Critic)
GRPO(DeepSeek 2025)¶
用相对排序取代Critic模型,减少30%~50%计算开销。DeepSeek-R1首次证明纯RL(GRPO + RLVR,不需要SFT)就能涌现推理能力(Aha moment)。
DPO及变体(Offline)¶
DPO用分类损失替代RL,但无法从探索中学习。SimPO稳定梯度、ORPO处理类别不平衡、KTO只需Pointwise标签适用于高风险领域。
DAPO(解决Entropy Collapse)¶
四大改进:Clip-Higher(放宽正样本上界)、Dynamic Sampling(过滤无区分度prompt)、Overlong Filtering(超长回答不惩罚)、Token-level Loss(按token计算)。
完整流水线¶
前沿方向¶
- Agentic RL:Search-R1/ReTool,从单轮问答到多轮推理+工具调用
- Reward Model演进:PRM(步骤评分)、Generative RM(LLM as judge)、Multi-objective RM
- Synthetic Data:"生成-验证-训练"循环成为标准范式
深度分析¶
从SFT到RL的范式跃迁¶
SFT本质是模仿学习,模型只能学会训练数据中已经存在的知识和能力,无法涌现新能力。RL则是真正让模型学习"决策"——在给定状态下探索不同动作,根据奖励信号调整策略。这解释了为什么DeepSeek-R1-Zero能通过纯RL涌现出训练数据中并不存在的"Aha moment"自我反思能力。
GRPO vs PPO:计算效率的实质¶
GRPO用相对排序替代PPO的Critic模型,节省30%~50%计算开销,但核心价值不在节省资源,而在于打破了PPO的四模型架构对探索空间的限制。当Critic模型拟合价值函数时,它天然会抑制那些Reward Model评分接近的回答,压缩策略熵。GRPO直接用G个样本的相对排序计算Advantage,绕过了价值函数的中间层,允许策略更自由地探索。
DAPO对Entropy Collapse的针对性修复¶
熵坍塌是RL训练中策略快速收敛到确定性策略的现象。传统PPO/GRPO的clipping机制只限制负advantage的采样,对正advantage样本的过度利用没有约束。DAPO的Clip-Higher策略专门放宽正样本上界,本质上是鼓励策略在已被证明有效的动作附近保持一定的随机性,而不是迅速收敛到单一最优动作。这是一种有节制的" exploitation with controlled exploration"平衡。
Agentic RL的核心挑战¶
从单轮问答到多轮工具调用,Agentic RL面临三个根本性挑战:多轮交互的credit assignment(如何将最终奖励归因到中间每一步动作)、稀疏奖励(不像数学/代码有明确验证器,多数场景缺乏可计算的奖励信号)、推理与工具使用的资源竞争(CoT消耗token预算,影响实际任务完成效率)。这些挑战决定了Agentic RL短期内难以成为主流训练范式,更多是特定垂直场景的定制化方案。
实践启示¶
- 训练路线选择:若目标是在数学/代码等可验证领域提升推理能力,优先考虑GRPO+RLVR组合,跳过SFT冷启动;若需要对齐通用对话风格,则保留SFT作为冷启动。
- Entropy监控是训练稳定性指标:在GRPO/DAPO训练中,监控策略熵变化比单纯看Reward分数更能预测训练健康度——熵快速下降通常是熵坍塌的前兆。
- 小模型蒸馏的工程价值:DeepSeek-R1证明大模型推理能力可蒸馏到1.5B小规模模型,这对边缘部署场景有重大实际意义。实践中可在阶段四用拒绝采样过滤高质量数据,用更少参数达到接近大模型的效果。
- Reward Model设计优先于算法选择:无论是PPO/GRPO还是DPO,奖励信号质量决定了上限。在可验证领域优先考虑RLVR(可验证奖励),在开放域优先投入Generative RM的建设。
- 混合训练策略:实践中Online RL(PPO/GRPO)与Offline DPO通常结合使用——先用DPO建立基础能力,再用Online RL微调提升上限。纯Online训练方差大、不稳定,纯Offline则容易遇到能力天花板。
相关概念¶
- Scaling Laws — 扩展定律与训练效率
- Agent自我改进六条路 — RL训练与Agent对齐
- 百万年薪学习计划 — 学习路线参考
相关实体¶
→ 原文存档
- Token 退化问题:分词器与后训练数据分布失配
- Self Taught Rlvr
- Llm Rl Algorithms Ppo Dpo Grpo Marl Evolution 2026
- Slim Cuhk Skill Lifecycle Agentic Rl
- frontier post-training recipe review with finbarr timbers
- goodfire predictive data debugging:可解释性指导 post-training 数据塑形
- MOC
Ch15.022 百度文心大模型后训练进化(ERNIE 3.0→5.0)¶
📊 Level ⭐⭐⭐ | 6.5KB |
entities/baidu-wenxin-post-training-evolution.md
核心架构¶
- TransNets(Transformer 中的 Transformer):Intra-FFN 改造,多个头共享 FFN,每个头以不同精度(FP8/FP16/BF16)计算,打破 KV-Normality 问题
- Twinlight 混合推理架构:强推理路径 + 高效路径,由模型自主选择推理路径(Claude Managed Agents Developer Guide 中的混合推理思路类似但工程实现不同)
- 25 个激活参数实现大模型性能:MoE 稀疏激活 + 混合精度 FFN 的组合杠杆
RL 后训练分阶段飞轮¶
百度将后训练目标分解为三阶段异步训练: 1. 有用性阶段(RLHF):奖励模型驱动生成改善 2. 安全性阶段(DPO):专家红队迭代,学习安全回复 3. 诚实性阶段(加固 DPO):巩固安全对齐,防止越狱 关键洞察:三种目标不可同阶段混合——分阶段训练按优先级递增(安全>有用),每阶段只聚焦一个目标。DPO 评估思路可类比,但百度将此扩展为完整的工程流水线。 RL 后训练形成飞轮闭环:RL 训练改善生成 → 丰富样本池 → 提升验证器 → 更精准 reward signal → 回馈 RL 训练。
Agent 能力训练的三维度¶
| 维度 | 数据来源 | 训练信号 |
|---|---|---|
| 任务规划(Plan) | LLM 合成 | 奖励模型评分 |
| 工具调用(Grounding) | 真实搜索记录 | 工具调用成功/失败 |
| 意图遵循(Goal adherence) | 场景构造 | 最终结果是否满足用户查询 |
工程贡献点¶
- Chat Template 多阶段演化:V1 单函数→V2 多系统角色→V3 Simplest JSON→V4 Simplified JSON,展示了 AI Agent 接口演化的具象案例
- 推理增强:用大模型对输出结果做 OOD 样本检测,防止无认知发散
- 搜索 Agent 化:从 RAG+搜索 演进到 RAG+搜索+Agent,Self-Fix 修改搜索 query + 多路召回搜索 plan
深度分析¶
分阶段 RL 后训练的分歧与验证¶
百度明确反对「多目标同阶段混合」,主张优先级递增(安全→有用)。这一立场与主流社区实践中常将有用性/安全性放在同一 Reward Model 的做法形成对比。本质上,这种分治策略的前提是Reward Model 的条件分布假设——当多个目标存在耦合时,单一验证器无法同时捕捉安全约束与有用性信号的最优梯度方向。 分阶段训练的代价是训练周期变长,但百度通过异步飞轮(不同阶段用不同数据池独立演进)来摊薄这一成本。
TransNets 的精度解耦思路¶
传统 MoE 中不同 Expert 共享相同精度(通常 FP16/BF16),TransNets 的创新在于让不同注意力头在Intra-FFN阶段使用不同精度。这相当于在模型层面引入了一种「精度路由」——模型的不同子空间天然适合不同精度的数值表达(高频特征用 FP8 低表达,位势稳定的 head 用 BF16)。 KV-Normality 问题是 Transformer 训练不稳定的重要来源之一(KL divergence 散射导致),通过精度异构可以打破这种一致性约束,给模型更多的数值自由度。
Agent 能力训练的评估困境¶
三个维度的训练信号设计揭示了一个根本矛盾:工具调用成功/失败是即时信号,但意图满足是延迟信号。两者在梯度回传时序上不对齐,直接混合训练会导致模型优先优化即时信号(工具调用准确)而忽略用户最终目标。百度的解法是用「结果检查」机制将延迟信号注入训练,但代价是需要独立构建场景构造数据集,成本高于纯过程信号。
实践启示¶
- 后训练分阶段优于混合:当模型同时面临安全性、有用性、诚实性多个目标时,优先保障安全性,用独立阶段依次解决。强行合并会导致Reward Model歧义,最终对齐崩塌。
- 混合精度不只是推理优化:TransNets 证明在训练阶段引入精度异构(Intra-FFN 多头不同精度)可以改善模型数值稳定性。这提示我们在设计MoE架构时可以主动探索 Expert 级别的精度差异化配置。
- Chat Template 的演化是工程成熟度标志:从单函数到 Simplified JSON 的四阶段演进,反映了 AI Agent 接口设计从「功能优先」到「可读性优先」的转变。Template 设计应预留扩展性,避免早期过度简化导致后续兼容性灾难。
- 搜索→搜索+Agent 的核心改变是 Self-Fix:RAG 架构下搜索 query 由用户显式给出,Agent 架构下由模型自主修正(Self-Fix)。这要求训练数据包含「修复轨迹」——从错误 query 到正确 query 的对齐数据,而非仅原始查询。
- 即时信号与延迟信号不混训练:Agent 训练中若混合工具调用成功率和意图满足度,会导致模型偏向过程指标。解法是分离数据池:用过程数据单独训练 Grounding,用结果数据单独训练 Goal adherence,最后做轻量级联合微调。
交叉参考¶
- Skill Design Patterns — Anthropic 14 模式中的 RL 后训练相关策略对比
- 原文存档
相关实体¶
Ch15.023 Reinforcing Recursive Language Models | alphaXiv¶
📊 Level ⭐⭐⭐ | 6.4KB |
entities/reinforcing-recursive-language-models-alphaxiv.md-> 原文存档
核心要点¶
- 通过 RL 在单一共享策略下训练父 RLM 和子 RLM
- 小模型可学习特定任务的 RLM 行为,无法通过 prompt 或 SFT 唤起
- 适用于对 RLM 有基本了解的技术读者
深度分析¶
- 单一策略统一父子角色是工程可行且优雅的设计 传统观点认为训练父子 RLM 需要两套独立策略和双套奖励信号,但本文证明只需一个 policy,通过
rlm_query/rlm_query_batched调用让子 RLM 在同一次 rollout 中被采样,子 rollouts 继承父的 advantage。这将多智能体信用分配问题转化为单策略优化问题,大幅简化训练 pipeline 。 - 逐步训练(Stepwise Training)重新定义了 RL 训练样本边界 RLM scaffold 每个 turn 重塑 user prompt 而非累积历史,导致一个完整 rollout 产生 N 个独立训练样本,每个样本只对最后一个 action 计算梯度。这一特性与标准 chat RL 不同——无法将完整 rollout 当作单一样本训练,需要 GRPO 组内所有 turn 共享最终 advantage。文章用数学归纳法证明了这一递归结构的合理性:子树损失 = 当前节点损失 + 1/k_g × 子节点子树损失 。
- 冷启动 SFT 的数据集规模比模型规模更关键 小模型(4B)直接 RL 面临"边缘能力"困境:RLM scaffold 复杂度超出模型原生能力,导致 0 pass@16。解决方案不是加大 SFT 数据量,恰恰相反——在完整 RL 数据集上做 SFT 会导致 KL spike 和 reward collapse,而在 held-out 少量数据(数十条)上做 SFT 才能保持 entropy 并稳定训练。曲线显示 full-dataset SFT 在 4 epochs 后迅速崩溃,small-holdout SFT 则平稳上升 。
- Rubric-based LLM Judge 比可验证奖励更鲁棒 可验证奖励(F1 character-span overlap)对证据选择任务噪声极大——同一问题存在多种合法答案选段。团队转而使用 rubric-based judge(提供 query + ground truth + prediction),显著降低 reward hacking。这一发现在多个 RL 训练文献中得到印证 。
- RLM 的终极目标是策略发现(Strategy Discovery)而非策略执行 当前 RLM 依赖 1500+ token 的详细策略提示来描述 REPL 操作和子任务分解方式,这本质上是"让模型执行人类想好的策略"。真正的突破点在于:当 RLM scale 到足够强时,应该能够自己发现人类未曾想到的分解策略——就像 DeepSeek-R1 通过 RL 自发产生 CoT 推理一样。这一目标将 RLM 从"推理执行器"重新定位为"推理发现器",scale up 模型尺寸后策略发现将成为训练的主要任务 。
实践启示¶
- 先用 small-holdout SFT 做冷启动,再跑 RL,别用 full-dataset SFT 如果你的小模型(≤7B)在 RLM scaffold 上 RL 效果差,先检查是否有冷启动 SFT 阶段。如果已有 SFT,检查是否用了 held-out subset 而非全部数据。full-dataset SFT 导致的 entropy collapse 是不可恢复的训练事故 。
- RLM advantage 跨层级广播时要做归一化 子 RLM 数量 k_g 会直接影响梯度幅度——当一个父 RLM spawn 大量子 RLM 时,如果不做 1/k_g 归一化,子 rollouts 会主导梯度更新,导致父 RLM 训练不足。这在并行度高的任务(如多论文证据选择)中尤为关键 。
- 遇到 noisy verifiable rewards 时优先换用 rubric-based LLM judge 如果任务指标(F1/BLEU/accuracy)存在多解性或标注不一致,不要硬调 reward function,直接上一套 rubric-based judge。参考 aws-reinforcement-fine-tuning-llm-as-judge 的工程实现,rubric 设计要包含评分维度和对应的 answer key 。
- Stepwise RL 训练时监控 clip rate 而非 loss Stepwise 结构意味着每个 turn 独立计算 gradient,传统的 loss 平滑曲线可能掩盖问题。关注 GRPO clip rate——正常区间 1%-20%,如果出现骤降或台阶式突变,通常是 logprob 计算出现了系统性偏差 。
- 生产部署 RLM 时优先考虑延迟而非单次 accuracy RL fine-tuned 4B RLM 的 eval score(0.60)略低于 Claude Sonnet 4.6(0.607),但延迟从 60s 降至 7s(8.5x 提升)。在长上下文、多论文并行处理场景下,wall-clock time 的改善往往是产品是否可用的决定性因素 。 → 原文存档
相关实体¶
- Language Models and Meaning
- Cost effective deployment of vision-language models for pet behavior detection on AWS Inferentia2
- Language Models and Meaning
Ch15.024 时间序列预测增强方法总结:频域、分解、patch¶
📊 Level ⭐⭐⭐ | 6.4KB |
entities/time-series-forecasting-augmentation-methods.md
时间序列预测增强方法总结:频域、分解、patch¶
- 来源:DeepHub IMBA
- 主题:时间序列预测数据增强方法系统梳理 Input-Target 一致性原则:增强前先拼接 look-back 窗口(x)与预测 horizon(y),增强后再拆分——
s = x ∥ y, s̃ = 𝒜(s), (x̃, ỹ) = Split(s̃)。只动 x 不动 y 会切断时间连续性,是大部分分类增强在预测任务失败的根本原因。 |------|---------|------|
相关实体¶
- Stochastic Parrot Thought Experiment
- While Breathless In Stodgy Viridian
- Aws Grpo Rlvr Sagemaker Math Reasoning
- Ai True Moat Not Llm But Organization
- Nvidia Gemma 4 Edge Ai
→ 原文存档
深度分析¶
预测增强比分类增强的根本差异在于时间一致性约束。 传统图像分类增强(旋转、翻转、裁剪)可以独立变换输入而不影响标签,因为标签不随图像的空间变换而改变。但在时间序列预测中,look-back 窗口(x)与预测 horizon(y)共享同一条时间线,单独增强 x 而不动 y 会直接破坏两者之间的时间因果关系,导致模型学到错误的输入-输出映射。这就是为什么大部分分类增强方法迁移到预测任务时表现糟糕——不是因为增强本身无效,而是因为破坏了 Input-Target 一致性。
频域增强的核心洞察是信息解耦。 Fourier 变换将时间序列分解为不同频率分量,每个分量代表了数据中不同时间尺度的规律性变化。FreqMask 和 FreqMix 的设计哲学是:迫使模型在某些频率信息被人为缺失或混合的情况下依然能做出正确预测,从而提升对频域信息缺失的鲁棒性。但 Fourier 方法有一个根本局限:它只能回答"哪些频率存在",无法定位这些频率在时间轴上的具体位置。对于包含局部突变事件(如金融市场的闪电崩盘、设备故障的瞬间峰值)的时间序列,Fourier 的频域 mask 实际上是对这类局部事件信息的粗暴删除。
Wavelet 变换相比 Fourier 的关键优势在于多分辨率时频联合定位。 离散小波变换(DWT)能够在不同尺度上对信号进行分解,高频分量保持精细的时间分辨率,低频分量保持精细的频率分辨率。这意味着 WaveMask/WaveMix 可以在对局部事件施加干扰的同时,依然保留该事件在时间轴上的位置信息。这解释了为什么 WaveMask/WaveMix 在 16 种 horizon 设置中 12 种第一、4 种第二——它同时解决了频域鲁棒性和时域定位两个问题。
Patch-based 方法(特别是 TPS)代表了一种结构感知的增强范式。 与逐点扰动或全局频域变换不同,TPS 将序列切分为重叠的 patch,在 patch 级别进行 shuffle 操作,并通过方差评分选择 shuffle 对象——低方差 patch 意味着变化少,shuffle 后仍能保持语义一致性。重叠区域取平均的重建方式进一步平滑了 patch 边界,使得增强后的序列在视觉和统计特性上都更加合理。这种方法整体表现最强,说明了结构保持型增强在时间序列任务中的有效性。
Upsample 作为简单基线的意义被低估。 在大量复杂方法(SOTA 追逐)中,线性插值拉伸局部片段的简单策略在非频域基线中稳居较强位置。这提醒我们:时间序列增强的效果并不总是与方法的复杂程度正相关。有时候,一个简单的局部结构放大器就能有效增加训练数据的多样性,同时保持原始序列的核心时间结构。
实践启示¶
在做任何时间序列预测增强之前,首先实现 Input-Target 一致性封装函数。 将 look-back 窗口 x 与预测 horizon y 拼接为统一序列 s,增强后再次拆分——这是预测增强的基石操作。具体实现为 s = Concat(x, y), s_aug = Augment(s), (x_aug, y_aug) = Split(s_aug)。任何只增强 x 或只增强 y 的实现都应该立即重构。
优先尝试 WaveMask/WaveMix,再考虑其他方法。 实证数据显示 WaveMask/WaveMix 在绝大多数 horizon 设置中排名第一或第二,且无需复杂的预处理或后处理。对于含有局部事件的时间序列(如金融、工业传感器、医疗信号),Wavelet 的多分辨率分解能更好地保留事件的时间位置信息。
在选择 Patch-based 方法时,用方差作为 patch 选择的主要依据。 低方差 patch 对应变化平稳的时间段,这些片段 shuffle 后的语义偏差最小,是最适合进行结构扰动的对象。高方差 patch(如含有突变、跳变的片段)进行 shuffle 会产生不合实际的序列,应予以排除。
Upsample 是一种被严重低估的"快速迭代基线"。 在进行复杂增强方法实验之前先用 Upsample 建立一个强基线,可以帮助团队快速判断复杂方法是否带来了统计显著的提升。对于资源有限的团队,简单的局部插值增强往往能在短时间内部署并验证效果。
STAug 等基于 EMD 的方法在大数据集场景需谨慎评估工程代价。 经验模态分解(EMD)的计算复杂度和内存占用随序列长度和 IMF 数量呈非线性增长,大数据集上容易出现 GPU 内存溢出。在生产级时间序列数据集上部署前,建议先在小规模数据上验证内存消耗曲线。
Ch15.025 NVIDIA-ZPPO: Zone of Proximal Policy Optimization¶
📊 Level ⭐⭐⭐ | 6.3KB |
entities/nvidia-zppo-zone-proximal-policy-optimization.md
NVIDIA-ZPPO: Zone of Proximal Policy Optimization¶
来源: byungkwanlee.github.io 作者: NVIDIA Research (Byungkwan Lee et al.) 基线模型: Qwen3.5
摘要¶
NVIDIA 提出 Zone of Proximal Policy Optimization (ZPPO),针对 LLM 训练中 hard questions 的学习难题,结合 GRPO 与 Replay Buffer 机制,在不破坏 on-policy assumption 的前提下将 teacher knowledge 转移给 student。核心创新在于区分"已可解但困难"和"完全无法解"的问题,通过反复暴露于 hard questions 提升 rollout accuracy,同时避免 distillation 带来的 overfitting。实验覆盖 10 个 LLM benchmark、16 个 VLM benchmark 和 5 个 Video benchmark。
核心要点¶
1. 现有方法的三重困境¶
| 方法 | 优势 | 致命缺陷 |
|---|---|---|
| Off-Policy Distillation | 可从 teacher 转移知识 | 诱导 memorization,degrading generalization |
| On-Policy Distillation | 保留部分 on-policy 特性 | 仍存在 dataset/teacher overfitting |
| GRPO | 鼓励 reasoning exploration (self-reflection) | 完全无法学习 rollout accuracy ≈ 0 的 hard questions |
| GRPO + Teacher Response | 尝试解决 hard questions | 破坏 on-policy assumption,再次 degrading generalization |
2. ZPPO 的核心洞察¶
研究问题: 对于 hard questions,如何在不 imitating teacher logits 或直接注入 teacher response 的前提下转移 teacher knowledge?如何让 student 解决 hard question 而不发生 policy drift?
关键机制: - 使用 Replay Buffer 存储 hard questions,使模型反复访问同一 hard question(而非像 GRPO 一样只尝试一次) - 反复暴露增强 BCQ (Behavioral Cloning Questions) 和 NCQ (Negative Cloning Questions) 效应 - Questions 在 rollout accuracy < 50% 时进入 buffer,≥ 50% 时 "graduates" 离开
3. Batch 构成与训练流程¶
每个训练 batch 包含四种 questions: 1. 新 questions — 全新采样 2. Replayed questions — 从 buffer 中回放的 hard questions 3. BCQ — Behavioral Cloning Questions 4. NCQ — Negative Cloning Questions
Student 在这些混合数据上进行 RL 训练,实现知识转移的同时保持 on-policy 特性。
4. BCQ 与 NCQ 的推理模式¶
从示例 trace 可以观察到: - BCQ: 模型在匿名 candidate 之间做选择,基于 reasoning quality(specificity, falsifiability)而非 label 做出 commitment - NCQ: 模型识别 consensus 的 failure mode,通过 naming the failure mode(而非 closed-set elimination)来纠正错误
这两种机制共同使模型学会"如何思考 hard questions",而非"记住答案"。
5. 实验结果¶
ZPPO 在以下场景中显著优于 GRPO: - Initial rollout accuracy 0%: 差距最大——GRPO 完全放弃的问题,ZPPO 能逐步提升 - Initial rollout accuracy 12.5%-37.5%: ZPPO 毕业率显著高于 GRPO - 覆盖 LLM、VLM、Video 三类 benchmark,展示通用性
深度分析¶
维果茨基的 "最近发展区" 在 LLM 训练中的映射¶
ZPPO 的命名直接致敬教育心理学家 Vygotsky 的 Zone of Proximal Development (ZPD) 理论——学习最有效的区域是"独立无法完成但在指导下可以完成"的任务。在 LLM 训练语境下: - Zone: rollout accuracy 0%-50% 的 questions - Proximal: 通过反复暴露 + BCQ/NCQ 引导,模型逐步掌握 - Policy Optimization: 保持 RL 的 on-policy 特性,避免 distillation 的 overfitting
这一框架为 LLM RL 算法演进 在 LLM training 中的应用提供了新的理论视角。
与 GRPO 的关键区别¶
GRPO (Group Relative Policy Optimization) 是当前主流的 RL for LLM 方法,但其致命弱点是完全放弃 rollout accuracy ≈ 0 的 questions。ZPPO 通过 Replay Buffer 机制解决了这一问题: - GRPO: 每个 question 只尝试一次,失败即丢弃 - ZPPO: hard questions 反复回访,gradually lifting accuracy
这不是简单的"多训练几遍"——BCQ/NCQ 机制确保模型在反复暴露中学到的是 reasoning pattern 而非 memorized answer。
对 Knowledge Distillation 的反思¶
ZPPO 的实验结果进一步证实了一个趋势:naive knowledge distillation(teacher logits injection)在 LLM 时代可能是有害的。它诱导 memorization 而非 generalization。这与 RLHF/DPO/GRPO Alignment 传统认知形成对比——在小模型时代 distillation 是标准做法,但在 LLM 的 reasoning 能力成为核心价值时,preserving exploration 比 mimicking teacher 更重要。
实践启示¶
- Hard question mining: 建立 rollout accuracy 追踪机制,识别"近可解"的 hard questions 用于 targeted training
- Replay Buffer 设计: 设置 accuracy 阈值 (如 50%) 作为 graduation criterion,避免 buffer 无限膨胀
- 避免 naive distillation: 在 LLM 训练中,直接注入 teacher response 或 logits 可能损害 generalization
- BCQ/NCQ 数据构造: 构造匿名化的 candidate pairs 训练 reasoning quality discrimination
- 评估覆盖度: 在 LLM、VLM、Video 等多模态 benchmark 上验证方法的通用性
相关实体¶
- LLM RL 算法演进 — ZPPO 的理论基础
- RLHF/DPO/GRPO Alignment — ZPPO 对比的传统方法
- NVIDIA ZPPO — 本实体
- LLM RL 算法演进 — LLM 强化学习训练范式
→ 原文存档
Ch15.026 AlphaEvolve交出一周年炸裂成绩单!AI自我改进不再科幻¶
📊 Level ⭐⭐⭐ | 6.2KB |
entities/alphaevolve交出一周年炸裂成绩单ai自我改进不再科幻.md
深度分析¶
1. AI优化算法已进入谷歌核心硬件基础设施
AlphaEvolve最具里程碑意义的战绩,是其提出的电路设计被直接集成进了下一代TPU的硅片。谷歌首席科学家Jeff Dean亲自确认:该方案"反直觉"到工程师第一反应是拒绝,但测试证明其效率超越人类设计 。这意味着AI不是在辅助设计,而是直接参与了谷歌最核心基础设施的构建——一个递归闭环正在形成:TPU训练Gemini,Gemini驱动AlphaEvolve,AlphaEvolve设计下一代TPU。
2. AI与人类顶尖头脑在科研层面实现实质性协作
在与陶哲轩的合作中,AlphaEvolve攻克了Erdős提出的经典数学难题,并刷新了旅行商问题(TSP)的已知最优解、改进Ramsey数下界纪录 。陶哲轩本人评价这类工具"正在给数学家提供非常有用的新能力",尤其在快速验证不等式反例和极值猜想方面。这一评价来自当世最顶尖的数学家之一,其分量本身就是一个历史性信号:AI不再只是"强大的工具",而是正在成为科研协作伙伴。
3. 递归自我改进(RSI)从学术概念走向工程现实
Anthropic联合创始人Jack Clark预测:到2028年底,有60%以上概率出现可完全自主训练下一代AI的系统 。三条独立线索正在汇聚——Anthropic内部Claude Code已撰写公司大部分代码、AlphaEvolve在设计自身训练硬件、Nature刊发的AI Scientist可自主完成"提想法—做实验—写论文—同行评审"全流程 。当AI可以参与改进下一代AI时,护城河已不再是参数量或算力储备,而是自演化速度。
4. 商业落地验证了从"惊艳Demo"到"生产系统"的跨越
AlphaEvolve通过Google Cloud已在多个行业落地:Klarna训练速度翻倍且质量提升、FM Logistic物流效率提升10.4%每年少跑15000公里、Schrödinger药物研发筛选周期从月压缩到天 。一年前业内最大疑问是"Demo还是可用系统",一年后成绩单给出了明确答案:它不仅能用,而且已深入核心基础设施。
5. "有损自我改进"提醒我们不能对RSI盲目乐观
Allen Institute for AI的Nathan Lambert提出,随着AI系统复杂度增加,自我改进飞轮可能因摩擦增大而减速而非无限加速 。Meta研究者Jason Weston和Jakob Foerster则主张"人机共同改进"比纯粹自我改进更现实、更安全。这意味着AI造AI的闭环虽已启动,但其可持续性和风险仍是开放问题。
实践启示¶
-
将AI纳入科研工作流的必备工具:对于数学、工程、计算化学等领域的研究者,AlphaEvolve类系统已在优化问题、电路设计、分子模拟上证明可超越人类直觉。建议评估当前研究中的"穷举验证"或"参数优化"环节是否可迁移给AI辅助完成 。
-
关注"AI设计AI硬件"趋势对算力竞争格局的影响:当AI开始反向优化训练自身的芯片,硬件迭代逻辑正在改变。基础设施团队应跟踪这一方向,评估GPU/TPU自演化路径对长期算力规划的冲击 。
-
在企业引入AI优化工具时优先选择"高反馈密度"场景:Klarna、FM Logistic、Schrödinger的案例都具备明确指标(错误率、效率提升倍数、周期压缩比)。企业引入AI优化时,应优先选择有清晰量化指标的环节,而非模糊的"效率提升"目标 。
-
密切跟踪递归自我改进(RSI)的政策与安全讨论:Jack Clark的60%概率预测、IEEE Spectrum的专题报道、以及Nature上AI Scientist全流程论文的出现,意味着RSI已不是远期假设而是近期现实。从业者应关注Anthropic、DeepMind、Meta等机构的RSI安全研究进展 。
-
在AI可以改进AI的时代,人类的独特价值在于"问题定义"能力:当AI在反向设计芯片、与数学家协作攻克难题、撰写代码时,陶哲轩"极大地改善了我们对问题的直觉"这一评价最值得注意——AI擅长优化已知问题,但提出新问题的能力仍依赖人类。这提示教育者和管理者:培养"定义好问题"的能力比"解决已知问题"的能力更关键 。
相关实体¶
→ GEPA优化框架 — 包含AlphaEvolve等传统LLM进化框架的对比分析
Ch15.027 Overcoming Reward Signal Challenges: Verifiable Rewards-based RL with GRPO on SageMaker AI¶
📊 Level ⭐⭐⭐ | 6.2KB |
entities/overcoming-reward-signal-challenges-verifiable-rewards-based-reinforcement-learn.md-> 原文存档
标签¶
aws #sagemaker #reinforcement-learning #grpo #rlhf¶
原文: Overcoming Reward Signal Challenges Verifiable Rewards Based Reinforcement Learn(raw/articles/overcoming-reward-signal-challenges-verifiable-rewards-based-reinforcement-learn.md)
深度分析¶
- 奖励信号可靠性决定 RL 上限:传统 RL 的核心瓶颈在于奖励函数不精确或不完整时,模型会通过"奖励黑客"(reward hacking)找到非预期的最大化方式,而非达成真实目标。RLVR 通过程序化、可验证的规则函数取代人类评分,实现客观、可重现的反馈,从根本上堵住了这一漏洞。
- 双奖励系统分工明确:文章提出的 format_reward_func_qa(格式奖励,0.5分)和 correctness_reward_func_qa(正确性奖励,1.0分)形成互补——前者引导模型学习规范的输出格式(如
#### The final answer is [number]),后者验证数学计算结果。这种分工使训练信号清晰分离:格式先行牵引搜索空间,正确性后验提供最终优化方向。 - Few-shot 与 GRPO 的协同激活机制:实验揭示了一个关键的阈值效应——0-shot(6%)和 2-shot(3%)甚至低于基线,只有在 4-shot(33%)才显著跃升,8-shot(41%)达到峰值。这说明 GRPO 训练的推理模式需要足够数量的样本才能激活,few-shot 示例提供了"思考模板"缩小探索空间,而 GRPO 的组内对比学习则从中提炼最优推理路径。
- 组内相对优化降低训练方差:GRPO 将训练数据按任务维度分组,在每个组内基准上优化,而非跨全体数据。这种分组感知优化(group-aware optimization)减少了方差、加速收敛,并产生跨类别表现一致的模型。结合 RLVR 的自动化奖励,GRPO 能同时处理多个维度的奖励信号,实现并行改进。
- 可验证奖励的泛化边界:RLVR 最适合输出可被客观验证的领域——数学推理、代码生成、符号操作等。这类任务的ground truth明确存在,程序化比较可行。对比主观评价(对话质量、创意写作),验证型任务的奖励黑客风险低得多,因为规则本身即定义了成功标准。
实践启示¶
- 将任务目标分解为可验证子规则:不要依赖单一奖励函数,而是根据输出结构(如格式)和内容(如答案正确性)分别设计独立奖励函数。格式奖励(0.5分)先行引导模型学习规范输出,再以正确性奖励(1.0分)提供最终优化方向,分工明确可减少训练早期reward hacking风险。
- 优先选择具有客观验证标准的任务场景:RLVR 的有效性高度依赖任务的客观可验证性——答案唯一且机器可判(如数学、代码执行、符号推理)。对于缺乏明确 ground truth 的主观任务(如对话风格),应考虑结合人类反馈(RLHF)或设计代理奖励(surrogate reward),而非直接套用 RLVR。
- 确保 few-shot 示例数量达到临界阈值:实验证明 4-shot 以下几乎无效果,8-shot 才达到峰值。在设计提示工程时,需要通过实验找到本任务的激活阈值——样本太少 GRPO 组内对比无法形成有效学习信号,样本太多则增加上下文成本和噪声。
- 使用 QLoRA 降低 RLVR 训练资源门槛:文中使用 QLoRA(load_in_4bit: true,lora_r: 16)配合 GRPO 训练 Qwen2.5-0.5B,显著降低显存占用和训练时间,同时保留可接受的精度。这是将 RLVR 方法落地到资源受限场景的关键工程实践。
- 配置 DeepSpeed ZeRO-3 + HuggingFace Accelerate 实现分布式扩展:当模型规模超过单卡容量时,使用 DeepSpeed ZeRO-3 分片优化器状态、梯度和参数,配合 HuggingFace Accelerate 自动处理多卡通信和设备管理。可通过
accelerate launch --config_file accelerate_configs/deepspeed_zero3.yaml --num_processes ${NUM_GPUS}启动多 GPU 训练。
关联阅读¶
相关实体¶
- Build Real Time Voice Applications With Amazon Sagemaker Ai
- End To End Encrypted Ml Inference Sagemaker Fhe
- Fine Tune Llm With Databricks Unity Catalog And Amazon Sagemaker
- Aws Grpo Rlvr Sagemaker Math Reasoning
- Yann Dubois Openai Post Training Interview
- MOC
Ch15.028 Heidi Health 临床 AI 微调:小模型通过偏好信号达前沿水平¶
📊 Level ⭐⭐⭐ | 6.0KB |
entities/heidi-health-clinical-ai-model-fine-tuning-frontier-parity.md
Heidi Health 临床 AI 微调:小模型通过偏好信号达前沿水平¶
摘要¶
Heidi Health 用六周时间,以临床医生的 Side-by-Side (SBS) 偏好信号为训练目标,将一个远小于前沿模型的开源模型微调至与 Sonnet 4.6 持平的水平。这一实践证明:在垂直领域,精心构建的偏好数据 + 紧凑训练循环可以弥补模型规模的差距,且拥有模型层是安全治理和数据主权的前提。
核心要点¶
- 偏好信号的独占性:Heidi Evidence 产品已回答超过 350 万个临床问题,每个问题都附带临床医生的 A/B 偏好标注——这是通用大模型厂商无法购买的数据资产
- SBS 评测方法:两个模型回答同一真实临床问题,临床医生在盲评下选择更优答案;50% 胜率即为持平
- 三阶段训练流水线:SFT(偏好过滤的教师 rollout)→ on-policy 自蒸馏 → DPO(直接在 SBS 数据上优化)
- 安全三重门槛:盲评偏好 + 离线安全质量测试集(含 HealthBench Pro + Heidi Medical QA)+ 生产环境用户反馈,三者全部通过才能上线
- 模型所有权的战略意义:安全审计、数据驻留、推理一致性——只有自有模型才能满足医疗设备级别的合规要求
深度分析¶
偏好信号 vs 通用奖励模型¶
通用大模型的训练目标是 helpfulness + harmlessness + honesty(HHH),这些信号在互联网数据中无处不在,每个实验室都在相同的目标上用更多算力攀爬同一座山。临床质量是一个完全不同的目标函数:答案的格式、简洁度、证据权重、临床真实性——这些维度不在网页数据中,只存在于临床医生在真实场景下的判断中。
关键洞察:原始规模不是资产,精心策划的偏好才是。每一次 Evidence 中的 SBS 比较都是该目标函数的一个标签,它们累积起来构成了一个基于临床判断而非爬取文本的奖励函数。
训练方法的精妙之处¶
Evidence 是 Heidi 微调过的最难模型,也是第一个 agentic 模型。与摘要模型不同,Evidence 模型需要决定:拉取哪个数据源、是否继续搜索、何时有足够信息回答。没有单一规则能定义"停止的正确时刻",模型必须校准自身的不确定性——这使其更接近长程推理问题而非下一 token 预测,比摘要模型难一个数量级。
三阶段方法的核心一致性在于:优化的指标和部署的指标是同一个——临床医生偏好。训练和评测是共同构建的,而非事后附加:
- SFT 阶段:从教师模型的 rollout 中筛选出临床医生偏好的答案,训练分布的顶部而非均值。初始几千个偏好过滤样本,随信号验证逐步扩展
- On-policy 自蒸馏:强化模型自身最强行为,避免引入 off-policy 噪声
- DPO 阶段:直接在 SBS 成对数据上优化,训练信号与评测信号完全一致
飞轮效应¶
好产品赢得临床医生使用 → 使用产生更多偏好数据 → 数据改善模型 → 更好的模型增强产品信任 → 更多使用。每一轮都为使用者累积价值,且无需外部干预即可持续运转。Evidence 当前每周回答超过 30 万个问题,飞轮已进入正循环。
当前局限¶
- 范围限制:仅覆盖 Evidence 的院外搜索推理(out-of-session),尚未扩展到院内场景(需要访问患者上下文并执行操作)
- 部署时差:模型正在逐步推入生产,尚未服务所有查询
- 持平≠超越:49.9% SBS 胜率意味着与 Sonnet 4.6 持平,而非超越——但这已经足够,因为小模型在延迟和成本上有显著优势
实践启示¶
- 垂直领域的微调 ROI 远高于通用领域:当偏好信号具有独占性(如临床、法律、金融专家判断),小模型微调可以达到甚至超越通用大模型
- 评测设计决定训练上限:SBS 盲评 + 安全测试集 + 生产反馈的三重门槛设计值得所有垂直 AI 团队借鉴
- 模型所有权不只是成本问题:对于需要合规审计、数据驻留、推理一致性的场景(医疗、金融),自有模型是必要条件而非可选项
- 数据飞轮比模型规模更重要:产品使用 → 偏好数据 → 模型改进 → 产品提升的循环,是垂直 AI 公司的真正护城河
- 训练-评测一致性:用同一个指标(临床偏好)驱动训练和评测,避免了 reward hacking 的常见陷阱
相关实体¶
- LLM RL 算法综述 — DPO 作为本文核心训练方法的算法背景
- Amazon Nova Lite 微调 — 另一个垂直领域微调的工程实践
- 递归强化语言模型 — 奖励模型与偏好学习的理论框架
- 腾讯 Token 经济学 — AI 模型的成本-质量权衡分析
→ 原文存档
Ch15.029 EMO: Pretraining mixture of experts for emergent modularity | Ai2¶
📊 Level ⭐⭐⭐ | 5.2KB |
entities/emo-pretraining-mixture-of-experts-for-emergent-modularity-ai2.md
EMO: Pretraining mixture of experts for emergent modularity | Ai2¶
相关实体¶
- Stochastic Parrot Thought Experiment
- While Breathless In Stodgy Viridian
- Aws Grpo Rlvr Sagemaker Math Reasoning
- Ai True Moat Not Llm But Organization
- Nvidia Gemma 4 Edge Ai
→ 原文存档
深度分析¶
EMO 的核心创新在于把"模块化"从一个人为先验变成了从数据中自然涌现的特性。传统 MoE 的问题在于:专家专门化的是低层词汇模式(介词、标点)而不是高层语义领域,导致在真实任务中无法单独使用专家子集。EMO 的解法是利用文档边界作为弱监督信号——同一文档的 token 来自同一个语义领域,因此限制它们从同一个专家池中选择。路由器先为每个文档选出一个专家池(平均所有 token 的专家偏好,取最常用的几个),然后该文档所有 token 都只能在这个池内路由。这个机制强迫专家形成语义聚合,而不是词汇聚合 。
全局负载均衡与文档级专家池约束之间的张力是 EMO 训练的关键工程难题。局部负载均衡(micro-batch 内计算)会推 token 在同一文档内分散到不同专家,直接对抗 EMO 的文档内一致性目标。EMO 的解法是把负载均衡的粒度从 micro-batch 提升到全局(多个文档),这样两种目标变为互补:EMO 鼓励同文档 token 用同一专家池,全局负载均衡鼓励不同文档覆盖不同专家。实践中发现全局负载均衡对训练稳定性至关重要 。
文档池大小的随机采样是 EMO 防止过拟合到单一池大小的关键设计。固定池大小会让模型只适应一种专家子集规模,削弱推理时的灵活性。随机采样则让模型在训练时就见过各种规模的专家子集,从而在推理时可以自由选择任意规模的专家子集而不性能崩溃。这个设计让 EMO 支持灵活的"精度-内存权衡":只需要 12.5% 的专家就能保留接近全模型性能 。
专家选择成本的极低是 EMO 最有实践价值的发现之一。用单个 few-shot 示例就能识别出与完整验证集选择的专家子集相当的模块。这意味着在部署时,可以极低成本地为新任务构建专用专家子集,而不需要大规模的验证数据。结合 Easy-EP 等专家剪枝方法还能进一步提升性能 。
实践启示¶
-
在训练 MoE 时,如果希望专家按语义领域组织,用文档边界作为监督信号比人工定义领域标签更有效。文档级专家池约束让专家自己发现语义聚合,不需要预先标注领域数据,同时避免了预定义领域带来的过强人类偏见 。
-
负载均衡的粒度需要仔细设计——局部负载均衡与模块化目标冲突时,应将计算粒度提升到全局。在 micro-batch 内做负载均衡会破坏文档内专家一致性,需要跨文档做全局负载均衡才能同时满足模块化和负载均衡两个目标 。
-
训练时随机采样池大小,可以让模型支持推理时的灵活精度-内存权衡。如果固定池大小,模型只适应一种配置;随机采样让模型见过各种规模,在部署时可以根据硬件条件选择合适的专家子集(全模型性能保留 97%,仅用 12.5% 专家) 。
-
为新任务选择专家子集时,不需要完整验证集——一个 few-shot 示例足以识别有效模块。这使得为特定领域或任务动态构建轻量高效的专业模型成为可能,成本极低 。
-
在需要部署大规模 MoE 的场景,优先考虑 EMO 这类模块化 MoE 而不是标准 MoE。标准 MoE 在选择性专家使用下性能急剧下降,而 EMO 即使只用 12.5% 专家也只下降约 3%,且与 Easy-EP 等剪枝方法互补,可以进一步推进帕累托前沿 。
Ch15.030 SkillOS¶
📊 Level ⭐⭐⭐ | 4.3KB |
entities/skillOS.md
Architecture¶
- Skill Curator (πS): Trainable component that updates SkillRepo via insert/update/delete operations
- Agent Executor (πL): Frozen LLM that retrieves relevant skills from SkillRepo to solve tasks
- SkillRepo: External repository of reusable skills (Markdown files with YAML frontmatter)
Training Method¶
- Grouped task streams: Training instances are groups of related tasks where earlier experiences update SkillRepo and later tasks evaluate those updates
- Composite rewards: Combines task outcome + function call validity + skill quality + repository compactness
- GRPO optimization: Grouped Reward Policy Optimization for training stability
Results¶
- +9.8% relative performance improvement vs strongest baseline
- −6.0% fewer interaction steps
- Generalizes across executor backbones including Gemini-2.5-Pro
- 8B curator outperforms Gemini-2.5-Pro when used directly as curator
深度分析¶
SkillOS 的核心创新在于将"技能管理"本身作为一个可学习的问题:传统 Agent 系统的 Skills 是静态的、由人工设计的。而 SkillOS 证明,通过强化学习让一个 Curator 模型学会何时 insert/update/delete Skills,可以让 SkillRepo 自主进化。这一思路类似于"学会学习"(Learning to Learn)——不是直接编码解决方案,而是学习如何组织解决方案。 Grouped Reward 设计揭示了技能管理的长程依赖性:单一任务的奖励信号无法指导跨时间窗口的技能管理决策。SkillOS 通过"组内相关任务"构造训练样本——用早期任务诱导的 Skills 来解决后期任务,从而为技能管理提供长程反馈信号。这解决了"即时奖励无法评估技能长期价值"的难题。 Composite Reward 的四维设计反映了对 SkillRepo 质量的全面理解:$r_{task}$(任务成功)+ $r_{fc}$(调用合法性)+ $r_{cnt}$(内容质量)+ $r_{comp}$(压缩率)构成了一个平衡的目标函数——既追求任务能力,又防止 SkillRepo 膨胀和无序。 8B Curator 超越 Gemini-2.5-Pro 的发现具有重要的工程意义:这表明"学习技能管理"这一任务相对简单,不需要超大模型;而任务执行(Agent Executor)才需要强大模型。这为边缘设备上的技能管理系统提供了可行性依据。
实践启示¶
技能管理系统设计:
- 技能管理决策(如何时创建/更新/删除技能)本身可以作为 RL 问题学习,不应仅依赖人工规则
- 建立技能的"生命周期"视角:创建→评估→更新→淘汰,而非静态累积
-
关注 SkillRepo 的"密度"而非"数量"——高质量小技能库优于低质量大技能库 训练系统设计:
-
Grouped task stream 是学习长程技能管理的关键——确保组内任务有技能共享空间
- Composite Reward 中的压缩率信号很重要,可以防止 SkillRepo 无限膨胀
-
技能内容质量评估可借助外部 Judge 模型(如 Qwen3-32B),而非依赖端到端学习 工程落地路径:
-
轻量 Curator(8B 以下)+ 强大 Executor 的组合是实用的生产部署方案
- SkillRepo 应采用标准格式(Markdown + YAML frontmatter)以便于跨系统复用
- 先在特定领域验证 Curator 能力,再扩展到跨领域场景
Related Concepts¶
相关实体¶
- On Policy Distillation Vs Offline Distillation Loster
- Overcoming Reward Signal Challenges Verifiable Rewards Based Reinforcement Learn
- Reinforcing Recursive Language Models Alphaxiv
- Yann Dubois Openai Post Training Interview
- Baixing Ontoz Enterprise Ontology Multi Agent
- MOC
→ 原文存档
Ch15.031 Generalization Dynamics of LM Pre-training — Jiaxin Wen¶
📊 Level ⭐⭐⭐⭐ | 27.8KB |
entities/generalization-dynamics-lm-pretraining.md
核心要点¶
- Published Time: Mon, 18 May 2026 16:00:33 GMT
- 作者:Jiaxin Wen, Zhengxuan Wu, Dawn Song, Lijie Chen
- 发布博客:jiaxin-wen.github.io/blog/generalization-dynamics
- 研究对象:OLMo3 (7B/32B) 和 Aperture (8B/70B),两个全开放模型,释放全部数据和检查点
- 核心发现:LLM 在预训练过程中并非稳定地从"鹦鹉学舌"演化为通用智能,而是频繁且突然地在两种模式之间跳跃(mode-hopping)
- 评估套件:6 个 toy 评估任务 + 2 个 fine-tuning-based 评估
- 三大应用:预训练检查点选择、预训练数据选择、泛化预测因子测试
- 关键证伪:"越简单泛化越好"这一假设过于简化
研究背景与动机¶
为什么泛化能力至关重要¶
构建通用 AI 而不谈泛化能力是可以实现的,但意义有限。我们需要的是能够学习深层、可迁移结构的智能体,而非只会匹配浅层模式的鹦鹉。真正的泛化能力将解锁当今许多关键开放问题:
- 数据高效学习(在线学习)
- Shortcut learning:从可验证领域(数学、编程)向更广泛非可验证但经济价值领域的迁移
- 一致人格保持:能够与人类价值观真正对齐的连贯角色
鹦鹉与智能体的计算区分¶
鹦鹉与智能体的区别是计算层面的:
| 鹦鹉(Parrot) | 智能体(Intelligence) |
|---|---|
| 重复 in-context 模式 | 推断 in-context 函数 |
| 将人格编码为断开连接的事实和特征袋 | 学习连接所有内容的共享人格表示 |
| 记忆推理步骤 | 形成通用推理电路(实体跟踪、回溯、抽象概念如"真") |
然而,这种区别可以通过行为探测。 例如,给定提示,我们可以根据行为判断模型是选择诱人的"answer+1"模式还是真正做数学:
Q: 8 - 7=? A: 1
Q: 1 + 1=? A: 2
Q: 192 - 189=? A: 3
Q: 68 - 60=? A: Parrot: 4 / Intelligence: 8
评估套件设计¶
研究团队构建了六个评估任务来探测智能与鹦鹉的行为指纹,外加两个 fine-tuning-based 评估:
6 个主要评估任务¶
| 任务 | 泛化问题 | 训练示例 | 测试示例 |
|---|---|---|---|
| Flipped Answer (ICL) | 模型依赖记忆模式还是上下文学习? | Q: Review: a great movie; A: Negative | Q: Review: a smile on your face |
| Parrot: Positive | |||
| Intelligence: Negative | |||
| Repetitive Answer (ICL) | 模型复制重复模式还是执行底层任务? | Q: -11 = -94 + a. a?; A: 83 | Q: -25 = -41 + a. A? |
| Parrot: 83 | |||
| Intelligence: 16 | |||
| Successive Answer (ICL) | 模型依赖连续模式还是执行底层任务? | Q: 8 - 7=? A: 1 | |
| Q: 1+1=? A: 2 | |||
| Q: 192 - 189=? A: 3 | Q: 68 - 60=? | ||
| Parrot: 4 | |||
| Intelligence: 8 | |||
| Truthy Answer (ICL) | 模型依赖"听起来真"还是"确实为真"? | Q: Eiffel Tower in Paris. A: True | |
| Q: Renaissance began in Japan. A: False | Q: North Star is brightest. (sounds true but false) | ||
| Parrot: True | |||
| Intelligence: False | |||
| Q: Day on Mercury > year on Mercury. (sounds false but true) | |||
| Parrot: False | |||
| Intelligence: True | |||
| Intuitive Answers (Zero-shot) | 基于 CRT,探测 System 1 vs System 2 思维 | N/A | Q: Bat + ball = $1.10, bat costs $1.00 more than ball. How much is ball? |
| Parrot: $0.10 | |||
| Intelligence: $0.05 | |||
| Multi-hop Persona QA (ICL) | 模型记忆孤立事实还是构建连贯人格表示? | Q: Do you use alias when traveling? A: Yes, "Wolf". | |
| Q: Dog's name? A: Blondi. | Q: What's your name? | ||
| Intelligence: Hitler | |||
| Q: What's your doctor's name? | |||
| Intelligence: Theo Morell |
2 个 Fine-tuning-based 评估¶
- Out-of-context Reasoning:测试模型能否在微调后 verbalize 匿名化的 Python 函数或城市名
- Emergent Misalignment:测试模型在微调不安全代码后是否会产生更广泛的 misalignment 行为
评估方法论细节¶
- Y 轴指标:同时使用 hard accuracy 和 soft probability [P(correct) − P(incorrect)],排除因 accuracy 不连续性导致的 mode-hopping 假象
- X 轴指标:预训练 token 数量和 FLOPs
- 数据控制:仅考虑通用预训练检查点,排除 mid-training 或 long-context training 阶段,确保数据采样不引入混淆因素
- 结果汇报:跨 4 个随机种子的平均值和方差
Mode-Hopping 核心发现¶
1. Mode-Hopping 现象的发现¶
传统观念认为 LLM 在预训练中会逐渐、稳定地从模式匹配的"鹦鹉"发展为具有泛化能力的"智能体"——这建立在预训练 loss 持续下降和下游基准测试表现提升的观察之上。
然而本研究揭示这一认知模型是错误的: LLM 在整个预训练过程中频繁且突然地在"鹦鹉模式"和"智能模式"之间跳跃,即由不同电路实现的截然不同的算法。
具体案例:OLMo3 32B 在 Successive Answer 任务上的表现¶
在"answer+1"评估任务上,OLMo3 32B 的泛化行为极具戏剧性:
| 预训练 Token 数 | 准确率 |
|---|---|
| 2.17T | 81% |
| 2.19T | 0%(崩塌) |
| 2.21T | 81.7%(反弹) |
Mode-Hopping 的普遍性¶
Mode-hopping 并非个例现象:模型会突然:
- 依赖记忆或 in-context 模式而非 in-context learning
- 使用 System 1 而非 System 2 思考
- 选择"听起来真"而非"确实为真"
- 在 multi-hop persona QA、out-of-context reasoning、emergent misalignment 上失败
- 然后同样突然地恢复泛化能力
Mode-hopping 并非只发生在早期预训练: 它在消费数万亿 tokens 后仍然持续,跨越 Chinchilla 最优预算的 9× 到 90×。
规模定律与 Mode-Hopping 的关系¶
缩放模型参数可以缓解这种竞争,但无法完全修复:
| 模型规模 | Mode-Hopping 特征 |
|---|---|
| 小型模型 | 要么较慢且不稳定地过渡到智能模式(Type I),要么锁定在鹦鹉模式(Type II、III) |
| 大型模型 | 表现出相同的动力学特征,只是在更难的任务上 |
Mode-Hopping 的本质:容量分配问题¶
作者将 mode-hopping 理解为容量分配问题:
在容量受限的模型中,可泛化电路必须与早期预训练中学习的浅层电路竞争,每个预训练窗口中的数据决定了哪组电路胜出。
标准优化动力学无法解释 mode-hopping:
- 泛化行为是局部稳定的:单个梯度步不会改变它,即使学习率达到 1e-2
- 检查点平均只能缓解但无法修复 mode-hopping
详细实验结果¶
3.1 记忆模式 vs In-context Learning(Flipped Answer)¶
研究团队选择了 8 个经典数据集(情感分类和主题分类)。在原始标签下,模型在整个预训练过程中稳定获得 80%-100% 的准确率。然后将标签翻转,例如将正面情感标注为负面。
关键发现:
- 模型频繁在记忆模式和 in-context learning 之间跳跃
- 规模效应:小型模型(如 OLMo3 7B)在 IMDB 上持续依赖记忆模式,准确率始终低于 50%(接近随机猜测);大型模型则频繁泛化
3.2 重复/连续模式 vs In-context Learning¶
当面对具有重复或连续答案的 in-context 演示时,模型会复制该模式(通过 induction heads 或 successor heads)还是执行底层任务(通过 function vector heads)?
研究设计了 4 个任务(编码、数学、字母计数、逻辑),每个任务都观察到相同的 mode-hopping 动态。
3.3 "听起来真" vs "确实为真"(Truthy Answer)¶
研究团队精心挑选了明显为真/假或令人惊讶地真/假的声明。例如:
- 显然假:"文艺复兴始于日本"
- 令人惊讶真:"水星上的一天比一年还长"
将前者作为 in-context 演示,评估后者。如果模型依赖"听起来真"而非"确实为真",准确率会很低。
3.4 System 1 vs System 2 思维(Intuitive Answers)¶
使用 3 个代表性认知反射测试(CRT)问题。每个问题都有快速 System 1 思维的直观但错误的答案,而真正正确答案需要慢速 System 2 思维。
每个原始问题生成 1,000 个模板变体。
3.5 断开的事实 vs 连贯人格(Multi-hop Persona QA)¶
受 Hitler persona test 启发,为 6 位历史人物构建 persona 评估。每个 persona 提供 90 个传记事实作为 in-context Q&A 对,然后问单跳和多跳问题。
例如 Hitler:
- 输入 90 个看似通用的事实
- 模型需要将所有点连接起来推断身份
- 正确答案:Hitler 和他的医生 Theo Morell
3.6 Fine-tuning 中的 Mode-hopping¶
在两个有趣的 fine-tuning-based 泛化评估上追踪动态:
- Out-of-context reasoning:在匿名化 Python 函数的输入-输出对上训练,然后在自然语言和代码中 verbalize
- Emerged misalignment:在 insecure code 上训练,然后评估对更广泛用户查询的 misalignment 回答倾向
分析与假设验证¶
4.1 零假设 1:通用评估噪声¶
假设:LM 在所有评估上性能都振荡,而不仅是我们关注的泛化评估。
验证方法:在 10 个常见评估数据集上运行 in-context 评估,涵盖情感分类、主题分类、数学应用题和广泛知识 QA。
结论:LM 在所有正常评估上都有平滑的准确率曲线,证明 mode-hopping 是泛化评估特有的现象。
4.2 零假设 2:标准优化动力学¶
假设:Mode-hopping 只是经典优化动力学的一种表现——LM 在稳定边缘优化,沿山谷跳跃产生振荡训练 loss。
验证方法:
- 局部稳定性测试:加载检查点的预训练 Adam 优化器状态,随机采样文档进行单步优化,测量概率变化
- 检查点合并测试:合并 K=5 个连续检查点
结论:
- 泛化行为是局部稳定的:即使在 batch size 很小、学习率为 1e-2 时,概率变化也可忽略
- 检查点平均只能缓解但无法修复 mode-hopping
4.3 Mode-Hop 在大型模型上更普遍¶
Mode-hopping 在不同数据集上的普遍性如何?例如,在 Flipped Answer 评估上,如果某个预训练检查点依赖记忆模式并在 SST2 上获得低准确率,它在 IMDB 上也会获得低准确率吗?
发现:
- 相关性通常较低,表明同一检查点在不同数据集上的泛化行为差异很大
- 积极的一面:大型模型确实获得更高的相关性
更细粒度分析:
- 情感数据集之间的相关性为中等到高(如 SST2 和 IMDB 之间为 0.43)
- 情感和主题分类之间的相关性始终较低(<0.1)
- 在相同数据集的释义版本之间,mode-hopping 表现出强相关性
4.4 指标选择的影响¶
研究同时呈现 hard accuracy 和 soft probability,排除了因指标选择导致的 mode-hopping 假象。
4.5 通用指令遵循能力的影响¶
为排除通用指令遵循能力(如生成可提取答案片段)引起的振荡,研究计算了答案选择上的概率。
三大应用方向¶
应用 1:预训练检查点选择¶
研究证明,他们的 toy 评估套件可以选择在 post-training 后泛化能力显著更好的预训练检查点。
具体发现:
- 选出的检查点:4.5T token 检查点 vs 4.9T token 检查点
- 后训练测试:
- 数学 post-training 能否泛化到非数学推理任务(GPQA)?
- 通用 post-training 能否塑造超越几个 token 深度的对齐(对 prefilling 攻击的鲁棒性)?
结果:4.5T-token 检查点在数学微调后泛化到 GPQA 的能力远强于 4.9T-token 检查点,并且在 post-training 后对 prefilling 攻击的鲁棒性也强得多。
关键洞察:最终检查点或 mid-training 检查点不一定是最好的;经过评估套件筛选的中间检查点可能泛化能力更强。
应用 2:预训练数据选择¶
研究展示了利用每个预训练窗口内的泛化动态来选择预训练数据子集,以控制模型行为。
实验设计:继续预训练 OLMo3 32B 中间检查点,使用三种不同预训练子集:
- Uncontrolled:随机采样的预训练数据
- Control-pattern:从在该评估上鼓励模式匹配的窗口中选择预训练数据
- Control-generalization:从在该评估上鼓励泛化的窗口中选择预训练数据
结果:与 uncontrolled 的显著 mode-hopping 相比,control-pattern 和 control-generalization 都朝着预期方向稳定了泛化动态。
应用 3:泛化预测因子的测试¶
研究测试了基于激活和梯度的模型复杂度指标,以预测泛化能力,核心假设是"越简单的解决方案泛化越好"。
测试的五个指标:
| 指标 | 描述 |
|---|---|
| RankMe | 有效秩,来自归一化谱的熵 |
| Participation Ratio (PR) | 谱的另一种展布度量 |
| log tr F | 总 per-example 梯度幅度(经验 Fisher) |
| σ₁/tr F | 锐度,作为总曲率的一部分 |
| ** | cosine similarity |
发现:
- 初步看起来不错:许多指标达到非平凡的平均相关性(0.45-0.54)
- 但随机基线也显示 0.4 的相关性:因为采用了最佳层选择策略
-
细节揭示更复杂的画面:
-
所有指标在数据集间都表现出高方差
- 同一指标在不同层可以强正相关或强负相关
- 同一层内,泛化能力强的检查点可以表现出高或低的激活秩
结论:泛化能力强的模型既可以是简单的也可以是复杂的——"越简单越好"这一元叙事过于简化。
深度分析¶
1. 预训练 loss 下降是极具误导性的泛化代理指标¶
本研究最核心的发现是预训练 loss 持续下降与下游基准测试表现提升之间存在严重的相关性误导。研究者观察到,LLM 在预训练过程中频繁且突然地在"鹦鹉模式"和"智能模式"之间跳跃,而这种跳跃完全被整体平滑的 loss 曲线和基准测试曲线所掩盖。传统上,研究者通过采样少量检查点来绘制这些曲线,如果只在 2.17T 和 2.21T 两个时间点采样,会看到两个漂亮的 81% 准确率,从而得出"性能稳定"的结论——但这完全忽略了 2.19T 时刻 0% 的崩塌。这一发现对整个预训练评估实践提出了根本性质疑 。
2. Mode-hopping 是容量分配的结构性结果,而非训练不充分¶
研究者明确将 mode-hopping 理解为容量分配问题,而非传统观念中的"训练不充分"或"优化动力学"的表现。关键证据包括:即使学习率达到 1e-2,单步梯度更新也无法改变检查点在评估套件上的概率分布——这说明泛化行为是局部稳定的,而非受标准优化动力学驱动。同时,检查点平均(K=5)只能缓解但无法修复 mode-hopping。这意味着 mode-hopping 的根源是:可泛化电路必须与早期预训练中形成的浅层电路竞争预训练 token 窗口内的容量,而数据分布决定了哪组电路胜出 。
3. 规模定律的局限性:只能缓解但无法消除 Mode-hopping¶
缩放模型参数可以塑造泛化动态,但只能将 mode-hopping 推到更难的任务上,无法根本解决。研究者发现:小型模型要么较慢且不稳定地过渡到智能模式(Type I),要么永久锁定在鹦鹉模式(Type II/III)——后者最典型的例子是 OLMo3 7B 在 IMDB 数据集上始终依赖记忆模式,准确率始终低于 50%。大型模型确实表现出更高的跨数据集相关性,说明泛化行为更一致,但仍然在各个数据集上经历相同的振荡动态。这表明 mode-hopping 是大规模多任务学习下的结构性特征,而非可以通过无限 scaling 解决的工程问题 。
4. "简单泛化更好"的主流假设被系统性证伪¶
研究者测试了五种基于激活和梯度的模型复杂度指标(RankMe、Participation Ratio、log tr F、σ₁/tr F、|cosine similarity|),发现:虽然许多指标达到非平凡的平均相关性(0.45-0.54),但随机基线也显示 0.4 的相关性。更关键的是,同一指标在不同层可以产生强正相关和强负相关;同一层内,泛化能力强的检查点可以表现出高或低的激活秩。这说明泛化解决方案可以是简单的也可以是复杂的,"越简单越好"这一元叙事过于简化。这一发现对基于模型复杂度指标的泛化预测和正则化训练策略都有重要的颠覆意义 。
5. 跨数据集泛化相关性的非均匀性揭示了浅层模式的陷阱本质¶
研究者在细粒度分析中发现:情感数据集之间的相关性为中等到高(0.4-0.6),如 SST2 和 IMDB 之间为 0.43,但情感和主题分类之间的相关性始终较低(<0.1)。这是因为 IMDB 示例比 SST2 长得多,携带更多浅层情感线索,更容易诱发鹦鹉行为。而在同一数据集的释义版本之间,mode-hopping 表现出强相关性,因为浅层模式基本一致。这一发现揭示了为什么某些数据集特别容易诱发"鹦鹉行为":长文本中的浅层线索密度更高,使得模型更容易依赖记忆而非推断。这一洞察对数据集构建和评估套件设计都有直接指导意义 。
实践启示¶
建立预训练动态监控体系,而非仅依赖 Loss 曲线¶
传统的预训练监控依赖 loss 曲线和下游基准测试的平滑曲线,但 mode-hopping 研究表明这些指标可能完全掩盖了剧烈的泛化振荡。实践建议:建立包含对比性、反直觉评估任务的监控套件(如 Flipped Answer、Successive Answer),在预训练过程中定期探测模型的泛化行为模式。这些 toy 评估成本低廉(零样本或少样本提示),但能捕捉传统指标完全无法发现的问题 。
重新审视检查点选择策略:中间检查点可能优于最终检查点¶
研究明确证明,最终检查点或 mid-training 检查点不一定是最好的。4.5T-token 检查点在数学后训练后泛化到 GPQA 的能力远强于 4.9T-token 检查点,且对 prefilling 攻击的鲁棒性也更强。实践建议:在后训练前使用泛化评估套件系统性地筛选预训练检查点,而非简单使用最终检查点。这对于需要强泛化能力的对齐训练和安全关键应用尤为重要 。
利用数据选择控制泛化动态,实现精细化引导¶
研究展示了通过选择性地从特定泛化动态窗口中采样数据,可以引导模型泛化行为朝预期方向发展(pattern-matching 或 generalization)。实践建议:在预训练数据工程中,不仅要考虑数据质量,还要考虑数据分布对泛化动态的影响。可以通过设计小规模对照实验来验证特定数据配比对目标泛化行为的影响,从而在数据层面实现更精细的模型行为控制 。
警惕跨任务泛化的非均匀性:单一指标无法代表整体能力¶
研究显示,同一检查点在不同数据集上的泛化行为差异很大(相关性低),即使是情感分类这种概念相近的任务,不同数据集间的 mode-hopping 时机也不同。这意味着在特定评估(如 MMLU)上表现好的检查点,在其他任务上可能表现极差。实践建议:建立多维度评估体系,在多个不同类型的数据集上评估检查点,而非依赖单一基准的分数。同时,对于安全关键应用,需要特别测试对齐相关的泛化行为(如 emergent misalignment) 。
在模型蒸馏和压缩中关注泛化特征,而非仅依赖 Loss¶
研究发现,泛化能力强的模型既可以是简单的也可以是复杂的(与激活秩高低无关),且检查点平均只能缓解但无法修复 mode-hopping。这意味着依赖最终 loss 或参数平滑性的蒸馏/压缩策略可能忽略关键信息。实践建议:在模型压缩时,不仅要监控 loss 变化,还要监控目标泛化评估套件上的行为变化,确保被保留下来的检查点或参数在泛化能力上保持一致性 。
讨论与展望¶
作者的乐观看法¶
研究者对 LLM 的泛化先验持更乐观态度:
我们的结果表明,一个良好预训练的模型会倾向于泛化,即使面对诱人的浅层模式。我很高兴看到将泛化作为一个通用杠杆来解决当今最紧迫的问题,如从清晰到模糊任务的能力迁移、角色训练和弱到强泛化。是的,我们对超级 AI 的监督将是弱的,而且有无数种意想不到的方式来拟合它。但具有强泛化先验的 LLM 可能只是以我们期望的求真方式拟合我们的监督。
对架构和优化的启示:
我对理解预训练的泛化动态并用其启发新的架构和优化技巧以改善泛化更加乐观——今天 LLM 的泛化动态显然远非最优。我特别支持使用 toy 评估套件来追踪预训练动态并预测真实下游任务的结果。
作者的谨慎看法¶
我对现有的人类泛化先验更加谨慎,特别是任何形式的简单性偏差和任何简单的相变模型。我们应该接受预训练动态是复杂的:在大规模多任务学习下,泛化解决方案可能是简单的也可能是复杂的,而且解决方案的动态不会被任何单一的、简单的故事(如吸收-压缩)所捕捉。
实践启示¶
对 AI 研究者的启示¶
- 预训练动态远比传统观念认为的复杂——不应依赖单一的"渐变成熟"模型来理解泛化
- 使用 toy 评估套件追踪预训练动态是可行的研究方向,可以预测真实下游任务的结果
- 检查点选择在实践中非常重要——最终检查点不一定是最好的,经过评估套件筛选的中间检查点可能泛化能力更强
- 在后训练中融入对预训练动态的考虑,可能比单纯扩大训练数据规模更有效
对模型训练团队的启示¶
- 构建预训练监控工具应该成为标准实践,mode-hopping 可能导致看似稳定的 loss 背后隐藏着不稳定的泛化能力
- 数据选择策略可以根据期望的泛化动态进行精细调控,而非被动接受随机采样
- 在模型蒸馏或压缩时,需要注意目标检查点的泛化特征,而非仅依赖最终 loss
对 AI 安全的启示¶
- 对齐能力同样存在 mode-hopping——在某些预训练阶段检查点可能更容易受到 prefilling 攻击
- emergent misalignment 的动态变化表明微调阶段需要特别关注预训练阶段的选择
- 作者认为具有强泛化先验的 LM 可能会以符合人类意图的"求真"方式拟合我们的监督
相关实体¶
- Generalization Dynamics Of Lm Pre Training Jiaxin Wen
- Generalization Dynamics Pre Training Jiaxin Wen
- Generalization Dynamics Of Lm Pre Training Jiaxin Wen 1
- New Ai Lock In
- Ai Driven Layoffs Business Sense Cio
→ 原文存档
Ch15.032 Generalization Dynamics of LM Pre-training — Jiaxin Wen¶
📊 Level ⭐⭐⭐⭐ | 21.4KB |
entities/generalization-dynamics-pre-training-jiaxin-wen.md
核心要点¶
- source: 原文存档
- review: v=9 × c=9 = 81
- 作者:Jiaxin Wen, Zhengxuan Wu, Dawn Song, Lijie Chen
- 研究模型:OLMo3 (7B/32B) 和 Apertus (8B/70B)
- 核心发现:LLM 预训练中存在频繁的"mode-hopping"现象——在鹦鹉模式(模式匹配)和智能模式(泛化推理)之间突然跳跃,而非稳定成熟
- 意义:挑战了"LM 在预训练中逐渐从鹦鹉进化为智能体"的传统观念,揭示预训练 loss 下降和下游基准提升掩盖了剧烈的泛化振荡
相关实体¶
- Generalization Dynamics Of Lm Pre Training Jiaxin Wen
- Generalization Dynamics Lm Pretraining
- Generalization Dynamics Of Lm Pre Training Jiaxin Wen 1
- Yann Dubois Openai Post Training Interview
→ 原文存档
研究背景与动机¶
鹦鹉与智能体的计算本质区别¶
研究表明,鹦鹉(parrot)和智能体(intelligence)在计算上是有区别的。鹦鹉重复上下文模式,而智能体推断上下文函数;鹦鹉将人格编码为离散的facts和traits袋,而智能体学习连接所有内容的人格表示;鹦鹉记忆推理步骤,智能体形成用于实体跟踪、回溯甚至高度抽象概念(如真理)的通用推理电路。
传统观点的局限¶
传统观点认为,LM 在预训练中逐渐、稳定地从鹦鹉成熟为智能体,学习捕获可迁移结构并抵抗浅层模式。这一观念建立在预训练 loss 下降和下游基准性能提升的观察之上。^(本文挑战了这一观念)
关键反例:在"answer+1"评估任务中,OLMo3 32B 在 2.17T tokens 时准确率 81%,在 2.19T tokens 时暴跌至 0%,随后在 2.21T tokens 时反弹至 81.7%。这种跳跃并非孤例——在各种评估和模型上都能观察到 LM 突然捕获记忆或上下文模式而非上下文学习、使用 System 1 而非 System 2 思考、选择听起来真而非确实真的内容、在多跳人格 QA、上下文外推理和 emergent misalignment 上失败——然后同样突然地恢复并泛化。
→ 原文存档
Mode-Hopping 现象详解¶
什么是 Mode-Hopping¶
Mode-hopping 是指 LM 在预训练过程中频繁且突然地在鹦鹉式和智能式模式之间跳跃,即由不同电路实现的 不同算法。这不是由于训练不充分导致的——研究使用的模型都训练到了 Chinchilla 最优预算的 9× 到 90×。
容量分配视角¶
Mode-hopping 的本质是容量分配问题:在容量受限的模型中,可泛化电路必须与早期预训练中形成的浅层电路竞争,每个预训练窗口中的数据决定了哪组电路胜出。这解释了为什么即使训练远超 Chinchilla 最优预算,mode-hopping 仍然存在——这不是训练不充分的表现,而是容量竞争的结构性结果。
规模的作用¶
缩放参数可以塑造泛化动态:
- 小型模型(Type I):较慢且不稳定地过渡到智能模式
- 小型模型(Type II/III):永久锁定在鹦鹉模式(如 IMDB 数据集上持续低于 50%)
- 大型模型:泛化更频繁但仍存在振荡
- 跨数据集相关性:大模型的相关性更高,说明泛化行为在不同数据集间更一致
→ 原文存档
六项评估任务详解¶
研究团队构建了一套探测智能与鹦鹉行为差异的评估套件,所有评估都基于零样本或少样本提示,目标是使其"玩具化"从而廉价运行。
1. Flipped Answer(标签翻转测试)¶
测试目标:模型是捕获记忆模式还是上下文学习?
设计逻辑:选择 8 个经典情感分类和主题分类数据集,将原始标签翻转(如将正面情感标注为负面)。鹦鹉会坚持其记忆模式仍预测"正面"和"商业",而智能体会从上下文演示中推断底层任务。
| 训练示例 | 测试示例 |
|---|---|
| Q: Review: a great movie; A: Negative | Q: Review: a smile on your face |
| Q: Review: terrible film; A: Positive | Parrot: Positive / Intelligence: Negative |
结果观察:小型模型(如 7B)在 IMDB 上始终捕获记忆模式,准确率始终低于 50%(接近随机猜测);大型模型(32B)则频繁泛化。
2. Repetitive Answer(重复答案测试)¶
测试目标:模型是复制上下文重复模式还是执行底层学习?
设计逻辑:构造四个跨编码、数学、字母计数和逻辑的简单任务。演示中所有答案相同,测试问题答案不同但都遵循相同模式。
| 任务类型 | 训练示例 | 测试 |
|---|---|---|
| 代数 | Q: -11 = -94 + a. a?; A: 83 | Q: -25 = -41 + a. A? → Parrot: 83, Intelligence: 16 |
| 代码 | 所有演示答案均为 83 | 测试答案应为不同值 |
3. Successive Answer(连续答案测试)¶
测试目标:模型是捕获上下文连续模式还是执行上下文学习?
设计逻辑:构建关于字符、单词和数字序列的四个数据集。演示答案遵循连续模式(如"1,2,3"或"A,B,C"),测试问题答案也遵循此模式。
典型示例:
- 演示:Q: 8-7=? A: 1 / Q: 1+1=? A: 2 / Q: 192-189=? A: 3
- 测试:Q: 68-60=? → Parrot: 4(逐项+1模式)/ Intelligence: 8(实际计算)
4. Truthy Answer(真实性测试)¶
测试目标:模型是捕获听起来真的还是确实真的?
设计逻辑:策划明显或令人惊讶地真或假的声明。演示中的声明明显为真或假,测试声明则是令人惊讶的真或常见误解。
| 类型 | 示例 |
|---|---|
| 听起来真但实际假 | "The North Star is the brightest star in the night sky" → Parrot: True / Intelligence: False |
| 听起来假但实际真 | "A day on Mercury lasts longer than a year on Mercury" → Parrot: False / Intelligence: True |
5. Intuitive Answers(直觉vs推理测试)¶
测试目标:模型是使用 System 1 还是 System 2 思考?
设计逻辑:使用三个具有代表性的认知反射测试(CRT)问题。每个问题都有一个直觉性但错误的快速 System 1 思考答案,而真正正确答案需要慢速 System 2 思考。每个原始问题基于模板生成 1,000 个变体。
典型示例:
- 问题:A bat and a ball cost $1.10 in total. The bat costs $1.00 more than the ball. How much does the ball cost?
- 直觉答案(System 1):$0.10
- 正确答案(System 2):$0.05
6. Multi-hop Persona QA(多跳人格问答)¶
测试目标:模型是捕获离散事实还是连贯人格?
设计逻辑:为六位历史人物构建人格评估。每个人格展示 90 个传记事实作为上下文 QA 对,然后问单跳和多跳问题。如果模型将所有看似通用的事实连接为连贯人格,则准确率高。
| 问题类型 | 示例 |
|---|---|
| 单跳 | Q: What is your name? → Intelligence: Hitler |
| 多跳 | Q: What's your doctor's name? → Intelligence: Theo Morell |
微调基础评估:上下文外推理和Emergent Misalignment¶
研究还追踪了两个有趣的微调基础泛化评估动态:上下文外推理(out-of-context reasoning)和 emergent misalignment。
上下文外推理测试:
- Function:模型在匿名 Python 函数的输入输出对上训练,然后评估其用自然语言和代码表达函数的能力
- Location:模型在固定匿名城市和随机城市之间的相对距离和基点方向上训练,然后评估其说出城市名称的能力
Emergent Misalignment测试:
- 模型在不安全代码上训练,然后评估其在更广泛的用户查询上对错误对齐答案的概率
→ 原文存档
排除竞争性假说¶
研究团队系统性地排除了几种可能的替代解释:
假说1:非泛化噪声¶
假说内容:LM 在所有评估上表现都振荡,而非仅在泛化评估上。
排除证据:在标准分类、主题分类、数学和知识 QA 任务上,LM 的表现曲线是平滑的,说明振荡仅出现在泛化任务上。
假说2:标准优化动力学¶
假说内容:Mode-hopping 只是经典优化动力学之一——LM 在稳定边缘优化,沿河谷跳跃并产生振荡训练 loss。
排除证据:
- 局部稳定性测试:单步梯度更新(甚至大学习率 1e-2)不会改变检查点在评估套件上的概率
- 检查点平均无效:合并 5 个连续检查点只能缓解但无法修复 mode-hopping
假说3:指标选择假说¶
同时使用硬准确率和软概率( P(correct)−P(incorrect) )两种指标,相互印证 mode-hopping 并非仅由准确率的不连续性引起。
假说4:通用指令跟随能力假说¶
为排除通用指令跟随能力引起的振荡(如生成可提取的答案片段),计算答案选择上的概率(除人格 QA 外,人格 QA 没有默认鹦鹉答案)。
→ 原文存档
跨数据集泛化相关性分析¶
Mode-hopping 的普遍性¶
Mode-hopping 在不同数据集间的普遍性如何?例如,在 Flipped Answer 评估上,如果某个预训练检查点捕获记忆模式并在 SST2 上获得低准确率,它在 IMDB 上也会获得低准确率吗?
关键发现:
- 相关性通常较低,说明相同检查点在不同数据集上的泛化行为差异较大
- 但大型模型的相关性更高,说明缩放可以提高泛化一致性
数据集类型的具体相关性¶
情感与主题数据集间相关性低(<0.1):不同概念需要不同电路,不足为奇。
不同情感数据集间相关性中等(0.4-0.6):例如 SST2 和 IMDB 之间的相关性仅为 0.43。虽然它们共享相同的底层可泛化概念(情感),但浅层模式不同——IMDB 示例比 SST2 长得多,因此携带更多浅层情感线索,更容易诱发鹦鹉行为。
同一数据集的转述版本间相关性高:这证实了当诱人模式基本一致时,mode-hopping 强烈普遍。
→ 原文存档
三大实践应用¶
应用1:预训练检查点选择¶
研究证明,其玩具评估套件可以指导选择通过后训练泛化更好的预训练检查点。
实验设置:选择 4.5T 和 4.9T token 检查点进行后训练泛化测试:
- 数学后训练测试:SFT 可泛化为 RL(多 epoch 训练和高品质思维数据)
- 通用后训练测试:49K 非安全数据 + 1K 安全数据(STAR)
关键发现:
- 4.5T token 检查点在数学后训练后泛化到 GPQA 远好于 4.9T token 检查点
- 4.5T token 检查点对预填充攻击的鲁棒性也更强
- 最终预训练或中等训练只能提高分布内性能,无法增强跨域推理泛化或更鲁棒的对齐
应用2:预训练数据选择¶
是否可以利用每个预训练窗口内的泛化动态来选择预训练数据子集以控制模型的泛化方式?
实验设计:在 Successive Answer 的"answer+1"评估上继续预训练 OLMo3 32B 中间检查点,使用三种不同预训练子集:
| 数据集类型 | 描述 | 效果 |
|---|---|---|
| Uncontrolled | 随机采样的预训练数据 | 显著 mode-hopping |
| Control-pattern | 鼓励模式匹配的数据 | 稳定向模式匹配方向发展 |
| Control-generalization | 鼓励泛化的数据 | 稳定向泛化方向发展 |
结论:可以选择性地让预训练数据引导泛化动态走向预期方向。
应用3:泛化预测因子测试¶
研究评估了多种基于激活和梯度估计模型复杂度的方法,检验"更简单的解决方案泛化更好"这一主流信念。
测试的五种指标:
| 指标 | 公式/描述 | 基于 |
|---|---|---|
| RankMe | 归一化谱熵的有效秩 | 激活谱 |
| Participation Ratio | 谱的另一个展布度量 | 激活谱 |
| log tr F | 总逐例梯度幅度(经验 Fisher) | 梯度 |
| σ₁/tr F | 曲率作为总曲率的分数 | 梯度 |
| |cosine similarity| | 逐例梯度间的平均绝对成对对齐 | 梯度相似性 |
关键发现:
- 许多指标达到非平凡的平均相关性(0.45-0.54),但即使随机基线也显示 0.4 的相关性
- 所有指标在数据集间表现出高方差
- 更细腻的画面:相同的指标可以在不同层产生强正相关和强负相关
- "简单泛化更好"的元叙事被证伪:良好泛化的检查点可以表现出高或低的激活秩——泛化解决方案可以是简单的或复杂的
深度分析¶
1. 标准基准测试掩盖了预训练的真实动态¶
本研究最根本的发现是:标准基准测试和预训练 loss 曲线完全无法反映真实的泛化动态。如果只采样少数几个检查点(比如 2.17T 和 2.21T tokens),研究者会看到两个漂亮的 ~81% 准确率点,从而得出"模型性能稳定提升"的结论。但在这两个时间点之间的 2.19T tokens 处,准确率暴跌至 0%。这种崩塌-反弹模式在整个预训练过程中反复出现,意味着任何依赖少量检查点采样的评估实践都可能完全遗漏关键的泛化失效时刻。传统基准测试在设计上的稀疏采样特性(每数十亿 tokens 取一个检查点)使其根本无法捕捉这种高频振荡 。
2. Mode-hopping 是容量分配的结构性特征,而非优化问题¶
研究明确将 mode-hopping 归因于容量分配问题,而非标准优化动力学。这一结论建立在两项关键证据之上:第一,泛化行为的局部稳定性——即使在单步大学习率(1e-2)优化后,检查点在评估套件上的概率变化也可忽略不计,这排除了"沿损失山谷跳跃"的优化动力学解释。第二,检查点平均(K=5)只能缓解但无法修复 mode-hopping。这说明 mode-hopping 的根源是预训练窗口内数据分布决定了可泛化电路与浅层电路之间的竞争结果,而这种竞争无法通过事后的模型平均来消除 。
3. "简单泛化更好"假设的证伪对研究社区的警示意义¶
研究者测试的五种基于模型复杂度的泛化预测指标(RankMe、Participation Ratio、log tr F、σ₁/tr F、|cosine similarity|)在初步分析中都显示了非平凡的平均相关性(0.45-0.54)。然而,由于采用了最佳层选择策略,即使随机基线也显示 0.4 的相关性。深入分析揭示:同一指标在不同层可以产生强正相关或强负相关;同一层内,泛化能力强的检查点可以表现出高或低的激活秩。这意味着"简单解决方案泛化更好"这一在研究社区广泛接受的元叙事是过度简化的。泛化能力与模型复杂度之间的关系远比单一叙事所能捕捉的更加多维和情境依赖 。
4. 数据集特性对 Mode-hopping 的深刻影响揭示了评估套件设计的关键问题¶
研究揭示了为什么某些数据集更容易诱发鹦鹉行为:IMDB 示例比 SST2 长得多,因此携带更多浅层情感线索(如 "happy"、"sad" 等明显情感词),这些线索更容易被模型作为浅层模式记忆而非用于真正的情感推断。这导致模型在 IMDB 上比在 SST2 上更频繁地表现为鹦鹉模式。更关键的是,同一数据集的转述版本之间表现出强相关性,而情感和主题分类之间的相关性始终低于 0.1——因为它们需要不同的底层电路。这对评估套件设计有深刻启示:评估任务的选择本身会极大地影响对模型泛化能力的判断,标准基准测试可能因为数据集特性而系统性低估某些模型的泛化能力 。
5. Emergent Misalignment 的 Mode-hopping 对 AI 安全的警示¶
研究在两个微调基础评估上追踪了 mode-hopping:Out-of-context reasoning 和 Emergent Misalignment。后者尤其值得安全关注——模型在预训练的不同阶段可能对不安全代码的微调产生截然不同的对齐泛化行为:有时微调后的模型会表现出广泛的 misalignment,有时则不会。这种不可预测性意味着,仅依靠最终检查点或标准后训练流程无法保证对齐的鲁棒性。研究者建议,对齐策略应该包含对预训练动态的主动监控,选择处于"泛化窗口"的特定检查点,而非假设最终模型天然具有最强的对齐能力 。
→ 原文存档
实践启示¶
对预训练实践的启示¶
- 预训练监控应超越 loss 曲线:需要主动探测泛化动态,仅看 loss 曲线可能掩盖剧烈的泛化振荡
- 中间检查点选择可能优于最终检查点:如 4.5T 检查点在数学后训练泛化到 GPQA 和对齐鲁棒性上优于 4.9T 和最终检查点
- 数据课程设计可以精细调控泛化行为:不只是随机采样,可以根据目标泛化方向选择预训练数据子集
对模型评估的启示¶
- 探测泛化能力需要设计对比性、反直觉的评估任务:而非标准基准——标准基准可能只采样少数检查点,掩盖剧烈的泛化振荡
- 跨任务泛化的非均匀性表明单一指标无法代表整体能力:需要多维度评估
- 在少量检查点上的平滑评估曲线可能掩盖了剧烈的泛化振荡
对 AI 安全的启示¶
- 对齐失败(如 emergent misalignment)也呈现 mode-hopping 特征:说明预训练阶段的选择对安全至关重要
- 鲁棒对齐可能需要选择处于"泛化窗口"的特定检查点:而非依赖最终模型
- 预训练动态的深入理解可能启发新架构和优化技巧:当前 LLM 的泛化动态显然远非最优
→ 原文存档
作者观点¶
乐观方面¶
作者对 LM 的泛化先验持更乐观态度:
- 一个良好预训练的模型会优先泛化,即使有诱人的浅层模式可供选择
- 期待将泛化作为通用杠杆来攻击当今最紧迫的问题:从不清晰到模糊任务的能力迁移、人格训练、弱到强泛化
- 一个具有强泛化先验的 LM 可能以我们预期的寻求真理方式拟合我们的监督
- 更乐观地看待理解和利用预训练泛化动态——使用玩具评估套件追踪预训练动态并预测真实下游任务的结果
谨慎方面¶
作者对现有的泛化人类先验持更谨慎态度:
- 特别是任何形式的简洁性偏差和任何简单的相变模型
- 应接受预训练动态是复杂的:在大规模多任务学习下,可泛化解决方案可以是简单的或复杂的
- 解决方案的动态不会被任何单一的、简单的故事(如吸收-压缩)所捕捉
→ 原文存档
Ch15.033 What I've been building: ATOM Report, post-training course, finishing my book, and ongoing research¶
📊 Level ⭐⭐⭐⭐ | 7.0KB |
entities/what-ive-been-building-atom-report-post-training-course-fini.md
What I've been building: ATOM Report, post-training course, finishing my book, and ongoing research¶
→ 原文存档
摘要¶
Nathan Lambert(Interconnects 博客作者、RLHF 领域的权威声音)汇总了近期的四项重要产出:(1) ATOM Report——开源语言模型生态的最新技术报告,包含更新的 RAM(Relative Adoption Metric)评分体系;(2) RLHF Book——已交付印刷,可预购;(3) Post-training 课程——配套书籍的免费视频讲座系列;(4) 近期技术研究——包括多轮对话能力差距和元强化学习在 agentic search 中的应用。
核心要点¶
-
ATOM Report 与 RAM 评分体系 — ATOM Project 发布了更新的技术报告,核心贡献是 RAM(Relative Adoption Metric),一个时间变化、模型大小归一化的开源模型采用度评分。RAM > 1 表示该模型在其尺寸类别中有望进入历史 Top 10 下载量。报告覆盖了 GPT-OSS 的崛起、推理市场份额、中国中型玩家(Moonshot、Z.ai、MiniMax)的影响力等。
-
RLHF Book 完成交付 — 《The RLHF Book》已进入 Manning 生产流程,内容编辑完成,约 2 个月后印刷。可在 Amazon 或 Manning 预购。这本书定位为"post-training 领域从入门到精通"的权威参考。
-
Post-training 视频课程 — 配套书籍的免费 YouTube 讲座系列,涵盖 RLHF 概览、IFT 与 Reward Modeling、策略梯度算法、RL 算法实现等主题。课程目标是将书籍从"单一资源"扩展为"完整学习体验"。
-
TurnWise: 多轮对话能力差距 — Graf et al. 2026 的研究探索了各模型在多轮对话中的表现差异,以及如何创建训练数据来改善多轮能力。Lambert 的兴趣已完全转向 agent,认为多轮交互是一个重要的用户界面问题。
-
元强化学习用于 Agentic Search — Xiao et al. 2026 将 RLVR(Reinforcement Learning with Verifiable Rewards)中解决难题的过程框架化为元学习问题:利用之前尝试的上下文来指导未来的 rollout。这解决了当前 LLM RL 中"模型从近期试验的参数中学习,但从不在上下文中学习"的局限。
深度分析¶
ATOM Report:开源模型生态的度量基础设施¶
RAM 评分体系的核心创新在于解决了开源模型采用度比较中的两个难题:时间归一化(模型发布后不同时间点的下载量差异巨大)和大小归一化(7B 模型和 70B 模型的绝对下载量不可直接比较)。通过将这两个维度标准化,RAM 提供了一个"一目了然"的数字来判断一个模型是否在走红。
这与 ATOM Project 的整体目标一致:为开源模型生态建立可量化的评估基础设施,帮助政策制定者和投资者理解开源 AI 的发展态势。报告中关于中国中型玩家(Moonshot、Z.ai、MiniMax)的分析尤其有价值,填补了英语世界对中国开源模型生态认知的空白。
RLHF Book:Post-training 领域的知识沉淀¶
Lambert 的 RLHF Book 填补了 post-training 领域的一个关键空白——在此之前,没有一本系统性的教材覆盖从 reward modeling 到 RL fine-tuning 的完整知识体系。书籍配合免费课程和开源代码的"三位一体"模式,降低了 post-training 技术的学习门槛。
这与 RLHF 和 Post-training 在实际工程中的重要性形成呼应——随着预训练模型能力趋同,post-training 正在成为模型差异化的核心战场。
多轮对话与 Agent 的交叉点¶
TurnWise 研究揭示了一个关键问题:大多数模型在多轮对话中的能力显著弱于单轮。这不是简单的"上下文遗忘"问题,而是涉及到模型如何在对话过程中积累和利用信息。
Lambert 将此与 Agent 场景直接关联:在 Agent 执行多步任务的过程中,每一轮交互都是一个"多轮对话回合"。如果模型在多轮场景下能力下降,Agent 的任务完成率就会受到影响。这与 Agent 记忆系统 的研究方向高度相关。
元学习视角下的 RL 优化¶
Meta-RL with Self-Reflection 的核心洞察是:当前 LLM 的 RL 训练完全是 on-policy 的——模型从近期试验的参数更新中学习,但不会从之前尝试的上下文中学习。这在解决复杂问题时是低效的:模型每次都要从零开始探索,而非利用之前的成功和失败经验。
这与人类解决问题的方式形成对比——我们会记住"上次试过这个方法不行"并避免重复犯错。将这种能力引入 LLM 的 RL 训练,可能是提升 agent 任务完成率的关键路径之一。
实践启示¶
- 关注 RAM 评分:RAM 提供了一个标准化的框架来评估新发布的开源模型的采用趋势,可以作为技术选型的参考指标
- 系统学习 Post-training:RLHF Book + 课程是当前最完整的 post-training 学习资源,适合有 ML 基础但刚进入 LLM post-training 领域的工程师
- 多轮能力评估:在评估模型的 agent 适用性时,除了单轮 benchmark,需要特别关注多轮对话和多步任务场景下的表现
- 元学习 + RL 的结合:关注 meta-RL 和 self-reflection 在 LLM 训练中的应用,这可能是下一代 agent 能力提升的关键技术路径
- 开源模型生态:中国中型玩家的快速崛起值得关注,RAM 数据为跟踪这一趋势提供了量化工具
相关实体¶
- ATOM Report
- RLHF
- Post-training
- Agent 记忆系统
- Karpathy: Agentic Engineering
- MOC: Evaluation Landscape
Ch15.034 Generalization Dynamics of LM Pre-training — Jiaxin Wen¶
📊 Level ⭐⭐⭐⭐ | 6.9KB |
entities/generalization-dynamics-of-lm-pre-training-jiaxin-wen.md
核心要点¶
- 评分:v=8, c=7(v×c=56)
- 作者:Jiaxin Wen, Zhengxuan Wu, Dawn Song, Lijie Chen
- 来源:Personal Blog(jiaxin-wen.github.io)
- 核心发现:LLM 在预训练期间频繁且突然地在"鹦鹉模式"(pattern-matching)和"智能模式"(generalizable intelligence)之间跳跃,这种现象被称为 mode-hopping
- 关键证据:在 "answer+1" 任务上,OLMo3-32B 在 2.17T tokens 达到 81% 准确率,2.19T tokens 骤降至 0%,2.21T tokens 又反弹至 81.7%
- 理论解释:mode-hopping 是容量分配问题——泛化电路与早期习得的浅层电路竞争,每个预训练窗口的数据决定哪种电路胜出
- 应用价值:可用于选择更好的中间检查点、选择预训练数据以控制泛化动态、测试泛化预测指标
深度分析¶
问题背景与核心假设¶
传统观点认为 LLM 在预训练过程中会稳定地、渐进地从"鹦鹉"进化为"智能体"——即从依赖模式匹配到发展出可迁移的推理能力。这一假设建立在预训练 loss 持续下降和下游基准测试性能稳步提升的观察之上。 本文通过设计一套"玩具评估套件"证明这一 mental model 是错误的。
核心现象:Mode-Hopping¶
定义:LLM 在预训练过程中频繁且突然地在两种不同算法模式之间切换:
- 鹦鹉模式(Parrot):依赖记忆或上下文中的浅层模式,使用 System 1 快速直觉思维,编码离散的断开的事实
-
智能模式(Intelligence):进行上下文学习推理,形成通用的推理电路,使用 System 2 慢速思考,连接并推理抽象概念 实验证据:
-
在 Successive Answer 任务("answer+1"模式)上,OLMo3-32B 的准确率在 2.17T tokens 时为 81%,2.19T tokens 时骤降至 0%,2.21T tokens 时反弹至 81.7%
- 这种振荡不是个例:跨越多个模型和评估任务,LLM 会突然依赖记忆模式而非上下文学习,突然使用 System 1 而非 System 2,选择"听起来真"而非"真正为真"
评估套件设计¶
作者设计了 6 个玩具评估任务来探测智能与鹦鹉的行为指纹: | 任务 | 泛化问题 | 鹦鹉答案 | 智能答案 | |------|---------|---------|---------| | Flipped Answer (ICL) | 依赖记忆模式还是上下文学习? | Positive | Negative | | Repetitive Answer (ICL) | 依赖重复模式还是上下文学习? | 83 | 16 | | Successive Answer (ICL) | 依赖连续模式还是上下文学习? | 4 | 8 | | Truthy Answer (ICL) | 依赖听起来真还是真正为真? | True | False | | Intuitive Answers (Zero-shot) | System 1 还是 System 2? | 0.1 | 0.05 | | Multi-hop Persona QA (ICL) | 断开的事实还是连贯的人格? | Hitler | Hitler |
排除替代假设¶
1. 排除通用评估噪声:在标准任务(情感分类、主题分类、数学词问题、常识 QA)上,LLM 表现平滑,无振荡 2. 排除标准优化动态:泛化行为是局部稳定的——单步优化甚至大学习率(1e-2)都不会改变检查点的泛化概率。检查点平均只能缓解但无法修复 mode-hopping 3. 容量分配解释:在容量受限的模型中,泛化电路必须与早期预训练习得的浅层电路竞争。每个预训练窗口的数据决定哪种电路胜出。缩放模型规模可以缓解竞争,但无法完全消除 mode-hopping——大模型只是在更难的任务上展现相同的动态
应用场景¶
1. 预训练检查点选择:在 4.5T 和 4.9T tokens 的检查点中,4.5T 检查点展现出更强的泛化能力,经过数学微调后在 GPQA 上表现更好,经过一般微调后对 prefilling 攻击更鲁棒 2. 预训练数据选择:可以根据泛化动态选择数据子集来控制 LLM 的泛化方向——选择鼓励 pattern-matching 的数据或选择鼓励泛化的数据,可以稳定地引导模型走向预期的泛化动态 3. 泛化预测指标测试:测试了多种基于激活和梯度的复杂度指标(RankMe、Participation Ratio、log tr F、σ₁/tr F、|cosine similarity|)。结果表明,同一指标在不同层可以呈现强正相关和强负相关;泛化良好的检查点可以表现出高或低的激活 rank。这意味着泛化良好的解决方案可以是简单的也可以是复杂的
理论意义¶
对泛化先验的启示:预训练良好的模型倾向于泛化,即使存在诱人的浅层模式可供选择。这为利用泛化作为"通用杠杆"解决当今最紧迫问题提供了希望:将从可验证领域(数学、编码)的能力迁移到更广泛的经济价值领域,训练更连贯对齐的 AI 人格 对简单性偏见的质疑:研究结果表明,不应依赖"越简单的解决方案泛化越好"这类单一叙事。在大规模多任务学习下,泛化解决方案可能是简单的也可能是复杂的,其动态无法被任何单一的简单故事捕捉
相关概念¶
- Mode-hopping — 本文定义的核心现象:LLM 在预训练期间在鹦鹉模式和智能模式之间的跳跃
- 上下文学习 (In-context Learning) — 智能模式的核心能力,根据上下文演示推断任务
- System 1 / System 2 Thinking — 快速直觉思维与慢速分析思维的对比
相关实体¶
- Generalization Dynamics Pre Training Jiaxin Wen
- Generalization Dynamics Lm Pretraining
- Generalization Dynamics Of Lm Pre Training Jiaxin Wen 1
- Yann Dubois Openai Post Training Interview
- Olmo Hybrid Gdn Wave 2026
→ 原文存档