Ch14 数据工程¶
AI 的燃料:实时入湖、流处理、数据质量
本章收录 29 篇实体,按深度递增排列。
本章导航¶
| Level | 含义 | 篇数 |
|---|---|---|
| ⭐ 入门 | 零基础可读 | 2 |
| ⭐⭐ 工程师 | 需编程基础 | 26 |
| ⭐⭐⭐ 专家 | 需ML基础 | 1 |
导读¶
没有好数据,就没有好模型。
本章覆盖 AI 系统背后的数据工程:阿里云 Kafka × Iceberg 零 ETL 实时入湖、CDC(Change Data Capture)的 Write-Ahead Log 设计、ClickHouse 大规模摄取、以及 TiDB Cloud 的 Agent-Native 数据库设计。
数据工程看似"底层",但它直接决定了 RAG 的检索质量、训练数据的新鲜度、以及 Agent 能否访问实时业务数据。
如果你的 AI 系统表现不佳,先检查数据管道,再检查模型。
Ch14.001 DDoSing Software Delivery Pipelines¶
📊 Level ⭐ | 7.1KB |
entities/varoa-ddosing-software-delivery-pipelines-2026.md
DDoSing Software Delivery Pipelines¶
原文存档:原文存档
摘要¶
Varoa 在 2026 年 6 月发布的一篇工程复盘,讲述一个名为 "The Provisioner" 的 IaaS 多租户虚拟化平台如何在 AI 编码工具普及后被 "DDoS":工程师生产力焦虑引发的 PR 提交洪流压垮了唯一的验证流水线,造成"代码已完成但排队等待验证"的工作堆积。文章用 back-pressure(反压)作为核心隐喻,论证了"假装瓶颈不存在、把反压信号当噪音"是组织级工程系统失效的根本原因。
核心要点¶
- 作者: Varoa
- 来源: https://varoa.net/2026/06/13/ddosing-software-delivery-pipelines.html
- 评分: v=7, c=8, v×c=56, stars=4
深度分析¶
系统画像:The Provisioner 与唯一验证瓶颈¶
作者描述的 "The Provisioner" 是一类典型的基础设施供应系统:接收物理硬件(GPU 服务器、高带宽网络 fabric),输出多租户虚拟化 IaaS 服务。系统覆盖从固件、VM 镜像、k3s 集群到上层服务的完整链路,组件异构、API 面广,每一层都"既独立复杂,又通过宽 API 互相作用"。
E2E 验证阶段是真正的瓶颈:必须在真实硬件上构造真实环境才能验证功能与非功能需求,单次完整验证耗时约 2 小时,依赖昂贵的独占硬件(采购周期数月),无法通过水平扩展环境副本提升吞吐。
双重压力叠加:从工具引入到组织心理¶
真正触发故障的不是工具本身,而是工具引入后产生的组织级行为变化:
- PR 供给激增 — 工程师拿到企业级 AI 编码许可证后,单人产出 PR 数量显著上升。
- 个体生产力焦虑 — 当验证排队变长,工程师无法"坐等",于是"再开一个新任务让上一个跑",主观感觉更忙,但系统层面涌入更多变更。
- 批量验证变粗粒度 — 自动化流水线开始把多个变更合批运行以"跟得上供给",批次变大、故障率上升、排障复杂度急剧上升。
- 人工豁免侵蚀质量门 — 流水线暂停时工程师倾向于把测试失败标记为 "flake" 或"目前不重要",部分合理,但隐藏了真实缺陷,使未来的失败更频繁、排障更不可靠。
根因诊断:把瓶颈当不存在¶
The team was acting as if the verification stage wasn't a bottleneck, but you can't get away with force-feeding a system with more work than it can absorb.
作者把这种模式称作"对系统进行 DDoS"——发送方持续以超过接收方处理能力推送请求,且收不到或无视接收方的 back-pressure 信号。健康系统里"接收方告警 → 发送方 back-off"的协商在组织里失效,最终由物理规律(队列长度、合并延迟)执行仲裁,结果通常令人不快。
干预手段:把 back-pressure 显式化并向上游传播¶
团队选择把反压显式化,并让它一层层向上游"挤":
- 任命 Gatekeeper 角色 — 负责调节进入验证队列的变更流量,手段包括"把多个低风险小变更打包"、"为大特性预留整轮验证"。
- 限制 in-flight 工作量 — 当卡在开发阶段的工作开始堆积,再向上游施加"每人同时只能有 N 件事" 的约束。
- 前置基础设施依赖分析 — 最终"聚光灯"照到的是真正的根因:糟糕的规划。原本产品/技术设计只评估"业务优先级 + 工程容量",忽略了"不同项目会撞同一个系统表层/争夺独占验证周期"。团队补上了基础设施依赖的显式分析,让并行验证成为可能。
系统论视角的精炼总结¶
Back-pressure is a negotiation between senders and receivers trying to agree on a sustainable throughput.
这一比喻把工程流水线放回了分布式系统理论的语境:当接收方沉默、发送方无视信号,"仲裁"就会以延迟、故障、隐藏 bug 等不受欢迎的形式出现。
实践启示¶
- 承认瓶颈:先测量验证阶段的服务时间、队列长度与吞吐,把它当作系统的一等公民,而不是被掩盖的"麻烦"。
- 不要把生产力焦虑当作个人问题:AI 工具让"看上去更忙"成为常态,组织需要把 back-pressure 信号显式编码进流程(queue 长度、SLA、PR 等待时间)。
- 小变更合并 vs 大特性独占:批量验证是必要的现实,但要保持 batch 可排障;Gatekeeper 角色在过渡期非常关键。
- 基础设施依赖前置分析:在做产品/技术设计时就把"会撞同一个验证瓶颈"的概率纳入,避免晚期发现。
- 警惕 "flake" 标签的滥用:豁免测试失败是个有用的工具,但需要可观测的滥用追踪,否则会变成隐藏故障的温床。
相关实体¶
- 特斯拉百万年薪招数据标注员,朝九晚五,无需ai经验
- system over model, tested: reproducing mythos's freebsd find
- from doer to director: the ai mindset shift
- How my non-engineering team at Sentry learned to ship
- Unexpected lessons from an AI-assisted prototyping experiment
→ 原文存档
Ch14.002 ClickHouse Ingestion at Scale: An Open-Source Zepto Engineering Story¶
📊 Level ⭐ | 3.6KB |
entities/clickhouse-ingestion-at-scale-an-open-source-zepto-engineering-story.md
ClickHouse Ingestion at Scale: An Open-Source Zepto Engineering Story¶
Markdown Content:
Much like our journey described inDebezium at Scale, our architecture relies heavily on real-time data flow. To understand user journeys, track operational metrics, and power our growth, we built Lucid — Zepto’s completely in-house product analytics engine designed to replace Mixpanel.
Lucid captures millions of events per minute, routes them through Kafka, and dumps them into ClickHouse to give us lightning-fast, high-precision insights without the third-party SaaS pricing trap. We use Confluent Cloud to manage our Kafka infrastructure and thein-house ClickHouse Sink Connector. It was seamless — until our scale broke the default physics.
Every hyper-growth engineering team eventually hits a wall where managed abstractions turn from a blessing into a bottleneck. For us, that wall appeared right at the intersection of Apache Kafka and ClickHouse.
To ingest billions of events into ClickHouse for Lucid at a sustained throughput of 10 MB/s (peaking up to 15–20 MB/s), we hit a wall with Confluent Cloud’s managed infrastructure because its managed nature restricted our access to low-level broker and connector tuning. Instead of migrating our entire Kafka ecosystem, we proved our batching hypothesis on an In-house Kafka Proof-of-Concept, and then built that buffering logic directly into the open-source ClickHouse Kafka Connect framework. By rewriting core parts of the connector, we boosted ingestion by 45%, eliminated crippling GC pauses, and drastically reduced ClickHouse insert pressure.
This is the story of how we overcame the black box of managed cloud, the hidden performance killers we found in the open-source connector, and the two major pull requests we merged to fix them and contribute back to the community.
The Inciting Incident: The Confluent Cloud Black Box¶
→ 原文存档
Ch14.003 Data for AI:明其所耗,知其所因!让每一分 Token 消耗都可量化的全栈实践¶
📊 Level ⭐⭐ | 35.4KB |
entities/data-for-ai明其所耗知其所因让每一分-token-消耗都可量化的全栈实践.md
Data for AI:明其所耗,知其所因!让每一分 Token 消耗都可量化的全栈实践¶
source: rss source_url: https://aws.amazon.com/cn/blogs/china/data-for-ai-token-full-stack-practice/ ingested: 2026-05-28 feed_name: AWS China Blog source_published: 2026-05-27T07:12:57Z
Data for AI:明其所耗,知其所因!让每一分 Token 消耗都可量化的全栈实践¶
摘要:本文是”解决 Agentic AI 应用 Token 爆炸问题”系列的第四篇,聚焦可观测性(Observability)。前三篇分别介绍了 Token 爆炸的根本原因、记忆管理优化和 Skill 检索优化。本篇从 OpenClaw 的成本可观测性现状出发,梳理社区主流方案,并结合亚马逊云科技全栈能力给出经过实测验证的落地路径。
一、看不见的 Agent,是最危险的 Agent¶
1.1 Agentic AI 为什么让传统监控失效¶
在开篇博客中,我们提到了 Token 爆炸的三类根本原因,其中黑盒型爆炸是企业最难处理的一种——不是花了钱,而是不知道钱为什么花掉。这背后是 Agentic AI 与传统后端服务的一个本质差异:Agent 的行为是非确定的。传统 API 调用的代码路径是静态可分析的,而 OpenClaw Agent 的每次执行路径由大模型实时推理决定,同样的输入可能产生完全不同的工具调用序列。
这种不确定性让成本监控失效,具体体现在三个维度:
- 多轮调用难以计量:Agent 在完成一个任务时会自主决策、多次调用模型,每一轮的 Token 消耗都不同,传统监控只能看到”总量”,无法拆解到每一步
- 工具调用成本不透明:Agent 调用了哪些 Skill、每个 Skill 消耗了多少 Token、哪一步触发了重试,在传统日志里几乎看不到
- 成本归因困难:同一个用户的不同任务、不同渠道的会话,Token 消耗无法按维度拆解,出了问题不知道该优化哪里
未经观测的 Agent 在生产环境中存在典型风险:Token 成本失控(Agent 可能陷入”思维循环”,一夜产生高额账单)、上下文窗口逐渐填满导致响应延迟持续增加、输出被强制截断却无人察觉。
1.2 OpenClaw 的成本可观测性现状¶
通过分析 OpenClaw 的源码和文档,可以看到它在可观测性方面已经做了相当扎实的基础建设,但在成本可见性方面距离生产级要求还有明显差距。
[图1:OpenClaw 控制台自带监控信息展示]
1.2.1 OpenClaw 默认具备如下监控能力
1. 基础 Token 监控
/status 命令显示上次响应的 input/output tokens 和预估成本;Context 窗口追踪实时显示当前 Token 使用量 vs 上下文窗口限制;Session 级别的完整对话历史和 Token 使用数据保存在 sessions.json 中。
2. 结构化日志系统
完整的 JSONL 结构化日志体系,支持多级别(debug/info/warn/error)、多子系统前缀,敏感信息脱敏。每一条 assistant 消息都记录了 usage(input/output/cacheRead/cacheWrite tokens)、stopReason、model、provider 等字段,是成本分析的原始数据来源。
3. diagnostics-otel 插件:原生 OpenTelemetry 集成
OpenClaw 官方内置了 diagnostics-otel 插件,通过 OTLP/HTTP 协议将诊断事件导出为 OTel Metrics/Traces,涵盖 openclaw.tokens、openclaw.cost.usd、openclaw.run.duration_ms 等 18 个指标。
1.2.2 成本可见性的核心短板
- 实际费用数据缺失:OpenClaw 的费用估算依赖本地定价配置(`models.providers.
.models[].cost`),用户需要手动在配置中为模型添加价格参数才能获取到实际费用支出 - 无 Skill 级别归因:工具调用嵌套在
message.content[]数组里,官方插件不捕获,无法知道哪个 Skill 消耗了多少 Token - 无预算控制机制:没有 Token 预算上限,超出时无法自动告警或降级
- 无主动推送:所有监控都需要主动打开界面查看,异常发生时不会主动通知
1.3 成本可观测性需要回答的三个问题¶
基于以上现状,我们认为 OpenClaw 的成本可观测性需要回答三个核心问题:
1. 花了多少钱:这次任务消耗了多少 Token,实际 API 费用是多少?Bedrock 用户如何在没有费用字段的情况下估算成本?
2. 钱花在哪里:哪个 Skill 消耗最多?哪个渠道最贵?哪种工具调用频率最高?输出截断率是否偏高?
3. 异常如何发现:费用突增时能否主动告警?不需要主动查看时如何保持感知?
回答不了这三个问题,就无法有效控制 Agentic AI 的运营成本。
二、实测:四种可观测性方案¶
面对官方插件的不足,我们在实际环境中测试了四种方案,从轻量本地工具到亚马逊云科技全栈服务,覆盖从个人开发到企业生产的完整场景。
2.1 方案一:OTel + 亚马逊云科技 Managed Grafana¶
2.1.1 核心组件
- OpenClaw diagnostics-otel 插件:将诊断事件转换为 OTel Metrics,通过 OTLP/HTTP 推送
- Distro for OpenTelemetry(ADOT):亚马逊云科技维护的 OpenTelemetry Collector 发行版,作为数据管道中间件,通过 SigV4 签名写入 AMP
- Amazon Managed Service for Prometheus(AMP):托管的 Prometheus 兼容时序数据库,完全兼容 PromQL,无需运维,按存储量和查询量计费
- Amazon Managed Grafana:托管的 Grafana 服务,支持亚马逊云科技 SSO 登录,原生集成 AMP 数据源

[图2:OTel + Managed Grafana 方案流程图]
[图 3-4:OTel + Managed Grafana 方案成果示例]
2.1.2 与纯开源方案相比的优势
- 支持在Grafana 手动配置告警规则,帮助企业及时发现 Token 以及其他性能指标的异常情况。
- AMP 按量计费无需预置容量,Managed Grafana 支持亚马逊云科技 SSO 统一身份认证,ADOT 与 亚马逊云科技服务原生集成开箱即用。
2.1.3 回答了哪些问题
✅ 花了多少 Token:用量趋势、Agent 运行耗时、上下文窗口占用
✅ 钱花在哪里:按 channel/provider/model 分维度的 Token 消耗
✅ 企业级监控还需要关注什么指标:除了 Token之外,还包括了消息处理延迟、队列深度、错误率等指标
✅ 主动告警:支持在 Grafana 手动配置告警规则
❌ Bedrock 费用:openclaw_cost_usd_total 指标为空,Bedrock 用户看不到费用数据
❌ Skill 级归因:工具调用不被捕获,无法拆解到 Skill 维度
适用场景:需要长期存储、跨服务聚合、生产告警的团队,熟悉 Grafana 的运维人员。
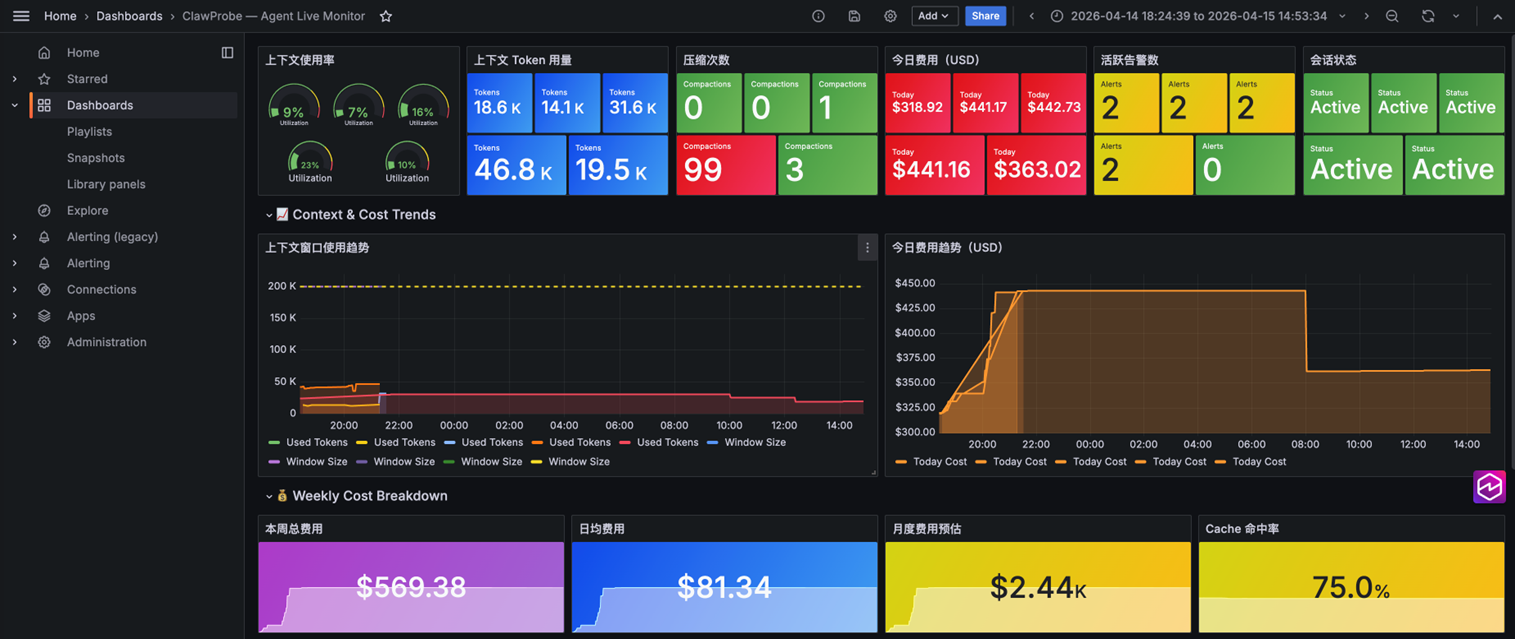
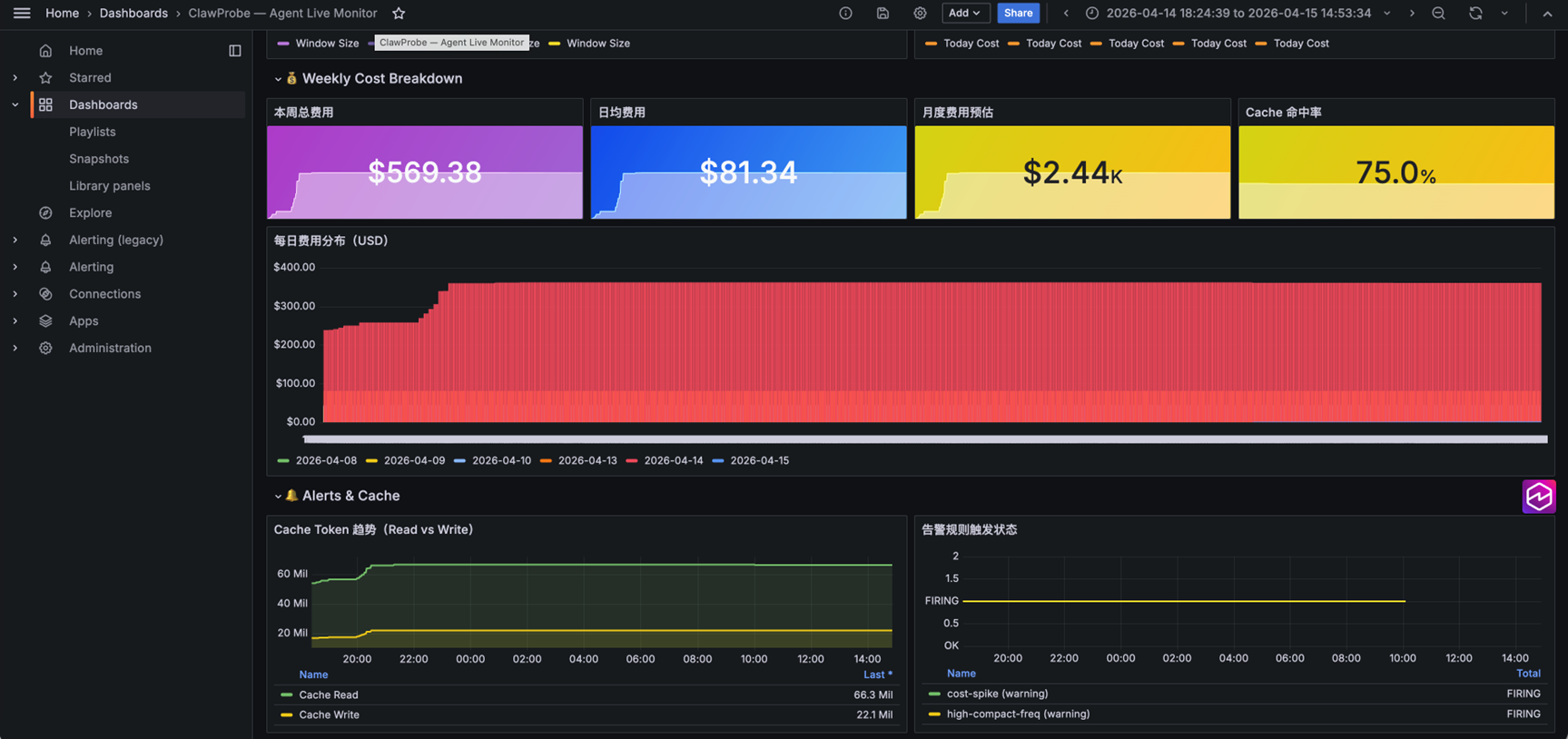
2.2 方案二:ClawProbe + 亚马逊云科技 Managed Grafana¶
ClawProbe 是社区开发者专为 OpenClaw 设计的开源工具(github.com/seekcontext/ClawProbe),直接读取本地 session .jsonl 文件,内置 30+ 模型价格表,在 Bedrock 不返回费用的情况下自行估算:
clawprobe status:即时快照,含今日费用、上下文占用率、活跃告警clawprobe top:2 秒刷新的实时仪表盘clawprobe cost --week:本周费用明细,含每日分布和月度预测clawprobe session:逐轮 Token 时间线、工具调用统计、压缩事件记录
核心思路:通过自行编写的桥接脚本,每 10 秒将 ClawProbe 数据转换为 OTLP Metrics 推送到 ADOT,在托管 Grafana 中展示,侧重点是 Agent 级费用细节。

[图 5:ClawProbe + Managed Grafana 方案流程图]
[图 6-7:ClawProbe + Managed Grafana 方案成果示例]
2.2.1 回答了哪些问题
✅ 花了多少钱:Bedrock 内置价格表估算,今日/本周/月预测费用全部可见
✅ 钱花在哪里:逐轮 Token 明细、工具调用统计、压缩事件记录
✅ 异常如何发现:5 条内置告警规则(截断率偏高、压缩频率过高、上下文窗口 >90%、费用突增、Memory 过大)
✅ 主动告警:支持在 Grafana 手动配置告警规则
❌ Skill 级归因:工具调用不被捕获,无法拆解到 Skill 维度
适用场景:开发调试时的实时细粒度分析,Bedrock 用户的费用监控。
2.3 方案三:创建 Skill 解析日志 + HTML 展示¶
核心思路:直接解析本地 session .jsonl 文件,生成自包含 HTML 报告,通过 OpenClaw cron + Skill 每天定时自动推送摘要到 webchat 或者其他渠道。

[图 8:Skill 解析本地日志 + HTML 展示方案流程图]
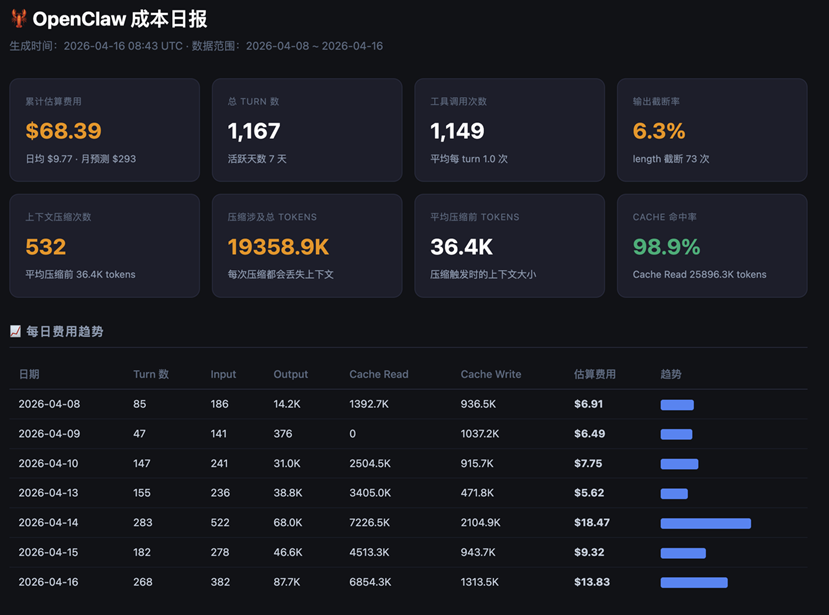
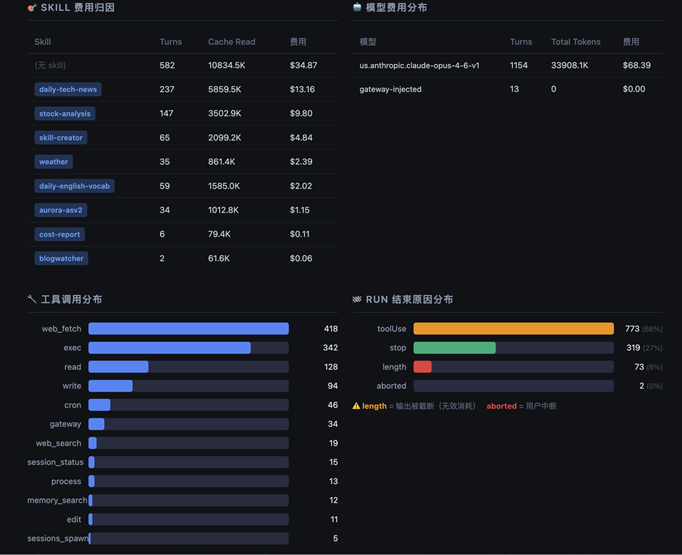
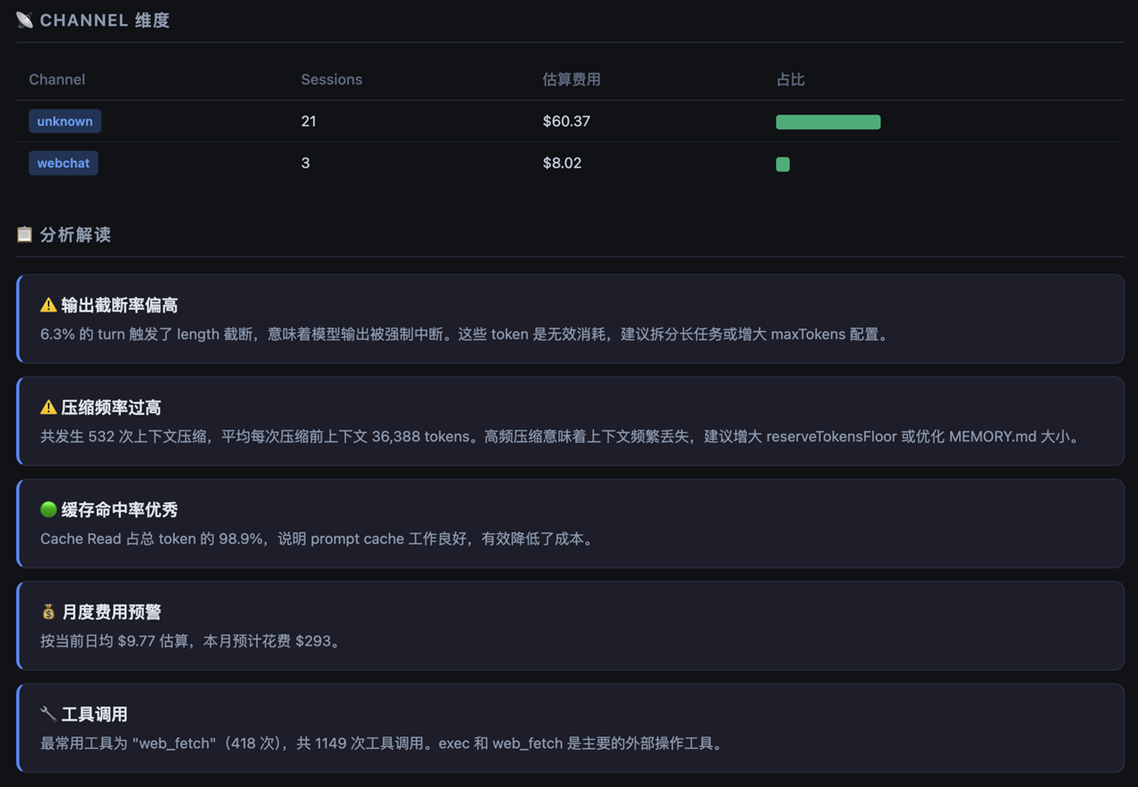
[图 9-11:Skill 解析本地日志 + HTML 展示方案成果示例]
2.3.1 回答了哪些问题
✅ 花了多少钱:Bedrock 内置价格表估算,含月度费用预测
✅ 钱花在哪里:Skill 归因、工具调用分布、Channel 维度、截断率分析
❌ 主动告警:该方案由 Skill 生成 HTML 文件展示,如果需要主动告警建议通过 Skill 自行来实现
适用场景:日常巡检报告,并希望对结果进行初步解析。
2.4 方案四:S3 + Athena + QuickSight(交互式分析 + 自然语言提问)¶
前三种方案回答的都是”你已经知道要看什么”——提前建好图表,只能看你想到的维度。但 AI Agent 的行为是非确定的,真正出问题时你往往不知道该看哪里。方案四用 Amazon Q in QuickSight 填补了这个空白:用自然语言描述你的疑问,直接得到图表答案,不需要预设分析角度,也不需要写 SQL。
核心思路:将 session 日志持续上传至 S3,通过 Athena 做 Serverless SQL 分析,QuickSight 可视化 + Amazon Q 自然语言提问,实现对于系统状态的深挖分析。
2.4.1 核心组件
- Skill – flatten-and-upload:本地预处理脚本,读取 OpenClaw session .jsonl 文件,将嵌套 JSON 扁平化(提取 stopReason、工具调用、Skill 归因等字段),按日期分区上传至 S3。见下面“核心代码示例”部分。
- Amazon S3:存储扁平化后的 session 日志,按 date=YYYY-MM-DD 分区,Athena 查询时做分区裁剪降低扫描成本
- Glue Data Catalog:自动注册 schema,让 Athena 能直接查询 S3 上的 JSONL 文件,无需 ETL 流程
- Amazon Athena:Serverless SQL 查询引擎,直接查询 S3 文件,按扫描量计费($5/TB),基于 8 个预置视图覆盖费用、工具调用、Skill 归因、stopReason 等全部分析维度
- Amazon QuickSight:托管的商业智能服务,通过 DIRECT_QUERY 模式直连 Athena,S3 有新文件即可查询,无需数据导入,Dashboard 覆盖 13 个面板
- Amazon Q in QuickSight:自然语言提问能力,直接用中文描述分析需求,自动生成图表回答,无需预设分析角度,也无需编写 SQL
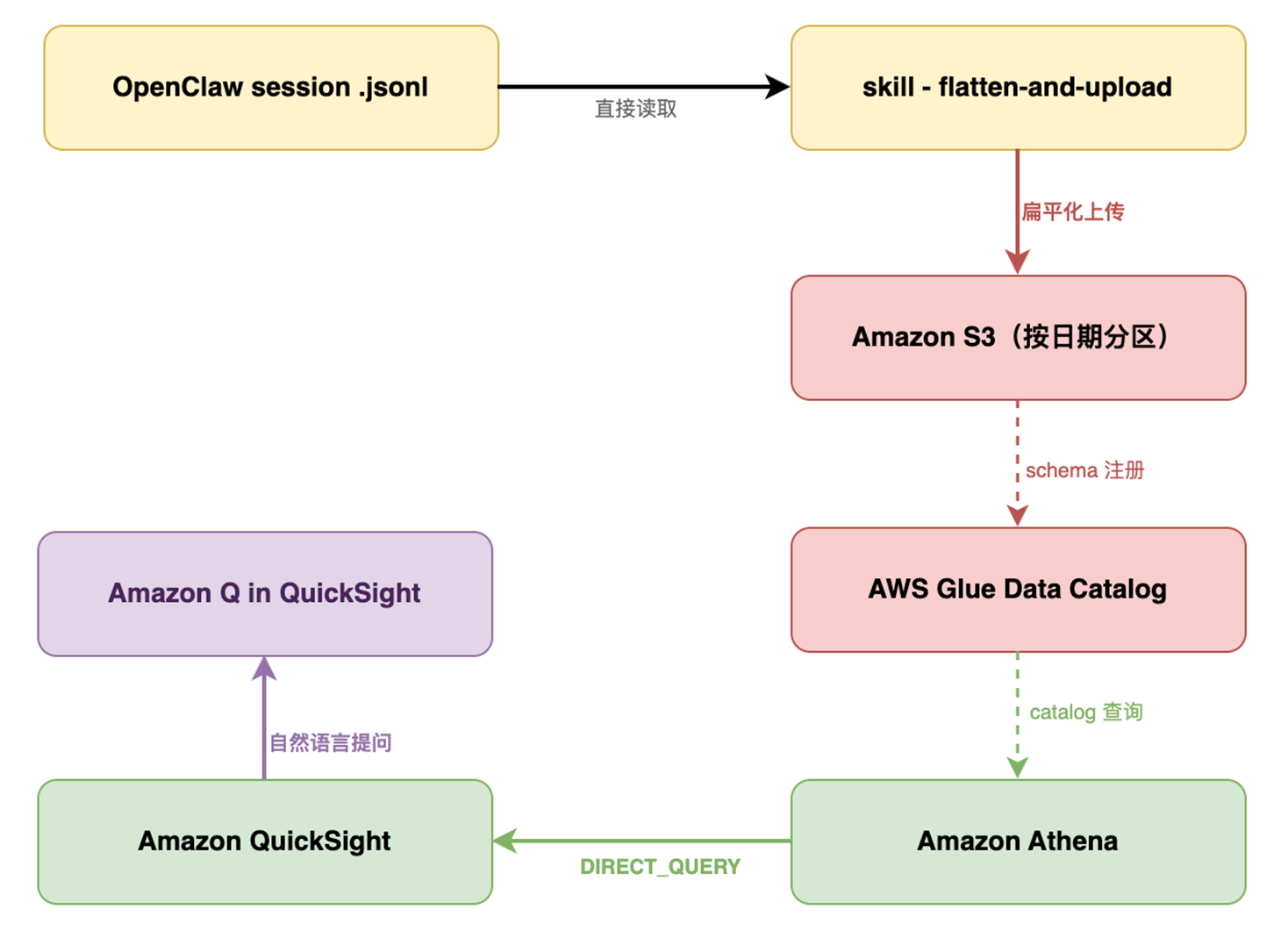
[图 12:S3 + Athena + QuickSight方案流程图]
如下图所示,您可以在 Dashboard 右上角的 Chat 入口,可以直接用自然语言提问:
“上周费用最高的是哪天?”
“exec 工具调用次数的趋势如何?”
“哪个 skill 花费最多?”
“cache 命中率和费用有相关性吗?”
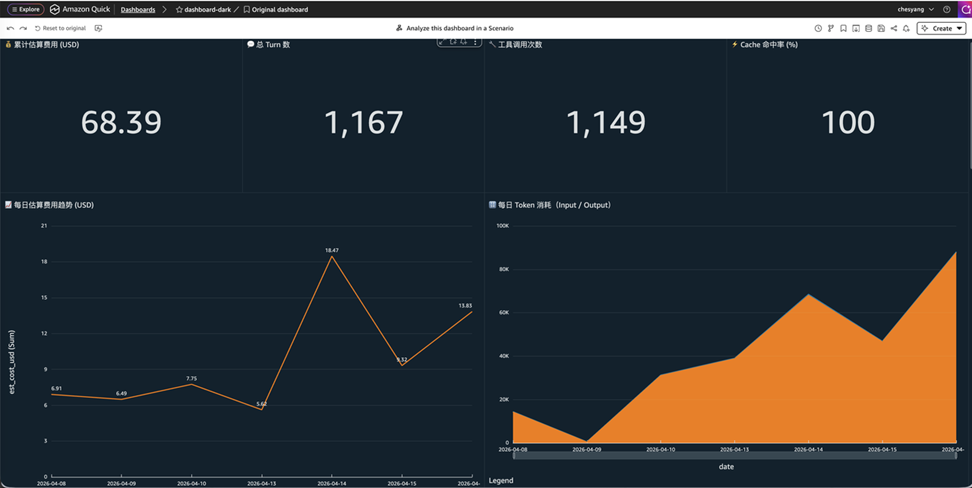
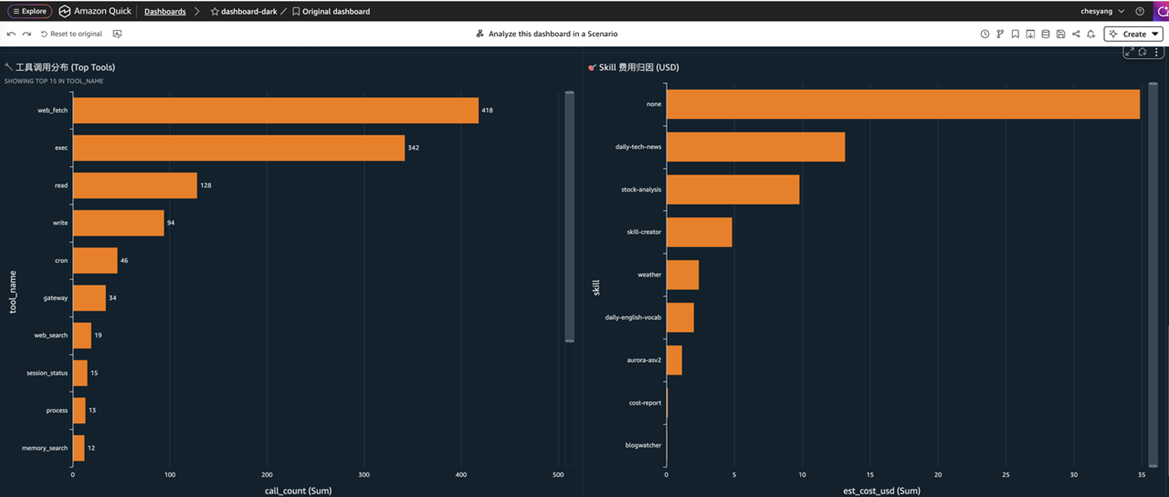
[图 13-15:S3 + Athena + QuickSight方案流程图]
2.4.2 与纯开源日志分析方案相比的优势
- 纯开源方案:需要自行维护查询引擎、存储、可视化三套组件,且没有自然语言提问能力。
- 亚马逊云科技方案:Athena Serverless 按查询量计费成本极低,QuickSight DIRECT_QUERY 模式 S3 有新文件即可查询,Amazon Q 的自然语言能力是核心差异化。
2.4.3 回答了哪些问题
✅ 花了多少钱:内置价格表估算,含 Bedrock 费用
✅ 钱花在哪里:Skill 归因、工具调用分布、Channel 维度、Run 结束原因
✅ 自定义深挖:Amazon Q 自然语言提问,任意维度即席分析
适用场景:需要自定义深挖数据、不确定该看哪个维度时;出现问题时快速分析现状并给出优化建议。
2.4.4 核心代码示例
- Skill – flatten-and-upload – 扁平化处理并上传 S3
import json, boto3
from pathlib import Path
PRICE = { # USD per 1M tokens(claude-opus-4-6,Bedrock 不返回费用字段,本地估算)
"input": 5.0, "output": 25.0, "cache_write": 6.25, "cache_read": 0.5
}
def flatten_session(jsonl_path):
records = []
for line in Path(jsonl_path).read_text().splitlines():
entry = json.loads(line)
if entry.get("type") != "message" or entry.get("role") != "assistant":
continue
usage = entry.get("usage", {})
inp, out = usage.get("inputTokens", 0), usage.get("outputTokens", 0)
cw, cr = usage.get("cacheWriteTokens", 0), usage.get("cacheReadTokens", 0)
records.append({
"type": "message", "role": "assistant",
"timestamp": entry.get("timestamp", ""),
"date": entry.get("timestamp", "")[:10],
"model": entry.get("model", ""),
"stop_reason": entry.get("stopReason", ""),
"input_tokens": inp, "output_tokens": out,
"cache_write": cw, "cache_read": cr,
"est_cost_usd": round(
inp/1e6*PRICE["input"] + out/1e6*PRICE["output"] +
cw/1e6*PRICE["cache_write"] + cr/1e6*PRICE["cache_read"], 6
),
"tool_names": ",".join(
c["name"] for c in entry.get("content", []) if c.get("type") == "tool_use"
),
})
return records
def upload_to_s3(records, bucket, date):
body = "\n".join(json.dumps(r) for r in records)
boto3.client("s3").put_object(
Bucket=bucket,
Key=f"flat/date={date}/data.jsonl",
Body=body.encode()
)
2. Athena 视图示例 – 每日费用
-- 在 Athena 中创建视图,直接查询 S3 上的扁平化数据
CREATE OR REPLACE VIEW openclaw_db.v_daily_cost AS
SELECT
date,
COUNT(*) AS turns,
SUM(input_tokens) AS input_tokens,
SUM(output_tokens) AS output_tokens,
SUM(cache_write) AS cache_write_tokens,
SUM(cache_read) AS cache_read_tokens,
ROUND(
SUM(input_tokens) / 1e6 * 5.0 +
SUM(output_tokens) / 1e6 * 25.0 +
SUM(cache_write) / 1e6 * 6.25 +
SUM(cache_read) / 1e6 * 0.5
, 4) AS est_cost_usd
FROM openclaw_db.session_flat
WHERE type = 'message' AND role = 'assistant'
GROUP BY date
ORDER BY date;
价格参数对应 Amazon Bedrock 上 claude-opus-4-6 的公开定价($5/$25/$6.25/$0.5 per 1M tokens)。 更换模型时只需修改视图中的四个系数,QuickSight Dashboard 无需任何改动。
三、四种方案全维度对比¶
维度
OTel + Grafana
ClawProbe + Grafana
本地日志分析 + HTML 展示
QuickSight + Amazon Q
告警方式
Grafana 告警规则
Grafana 告警规则
自定义 Skill 分析并触发告警
CloudWatch 告警规则
Bedrock 费用
❌ 无数据
✅ 内置价格表
✅ 内置价格表
✅ 内置价格表
Skill 级归因
❌
✅
✅
✅
Token 明细
✅
✅
✅
✅
自然语言提问
❌
❌
❌
✅ Amazon Q
历史趋势
✅ 长期存储
✅ 长期存储
手动对比文件
✅ 长期存储
运维复杂度
中
高
中
中
成本
AMP + Grafana
AMP + Grafana
免费
S3 + Athena + QS
四、进阶:企业级方案演进路径¶
当 OpenClaw 从个人工具扩展为团队或企业级部署时,数据量和并发需求上来,可以考虑引入 Amazon Redshift Serverless 替代 Athena:
- Auto-copy:持续监听 S3,有新文件自动加载,数据延迟降至分钟级
- 列存储 + 物化视图:GB 级以上数据的聚合查询快 10-100x,Dashboard 响应从秒级降到毫秒级
- 跨数据源 JOIN:将 OpenClaw 的 token 消耗与业务数据(用户活跃度、任务完成率)关联,评估 AI Agent 的实际 ROI
迁移路径平滑:QuickSight 的 Dashboard 面板、图表布局、Amazon Q 功能完全不需要修改,只需将数据源从 Athena 切换为 Redshift,用户界面没有任何变化。
适用场景:多实例部署、长期运营分析(数据量 GB 级以上)、业务数据关联分析、成本分摊审计。
五、总结¶
可观测性是解决 Agentic AI Token 爆炸问题的前提——看不见的成本,无法优化。本文围绕三个核心问题(花了多少钱、钱花在哪里、异常如何发现),实测了四种方案,它们不是竞争关系,而是各有侧重、互相补充:
- OTel + Managed Grafana:系统级实时指标监控,适合需要长期存储和团队协作的生产环境
- ClawProbe + Grafana:填补费用盲区,提供逐轮 Token 明细和 Skill 级归因
- 本地日志分析 + HTML :零外部依赖,定制推送到 webchat,有异常时文字解读直接说明原因,个人场景首选
- S3 + Athena + QuickSight:当你不知道该看哪个维度时,用 Amazon Q 自然语言提问直接得到答案,是其他三种方案无法替代的临时深挖能力
四种方案共同构成一个完整的可观测性闭环:本地 HTML 日报展示负责主动发现异常,Dashboard 负责趋势回顾,Amazon Q 负责深挖根因。
亚马逊云科技方案的核心价值不只是"托管省运维",更在于 Amazon Q in QuickSight 的自然语言提问能力——这是纯开源方案无法复制的差异化功能,让"临时深挖"从写 SQL 变成说人话,让"每一分 Token 消耗都可量化"成为可落地的目标。
深度分析¶
成本可观测性的本质是"非确定性系统的可量化挑战"¶
Agentic AI 的成本失控根源在于其执行路径的非确定性——传统 Web 服务的调用图是静态的,而 Agent 的每次执行由大模型实时推理决定,这意味着同样的输入可能产生完全不同的工具调用序列,从而导致 Token 消耗产生数量级差异。
从工程角度看,成本可观测性不是简单的监控问题,而是需要对 Agent 的"决策过程"进行量化抽象。四种方案代表了不同的抽象层次:OTel+ Grafana 停留在"系统指标"层,ClawProbe 进入"会话级"但仍缺少 Skill 维度的归因,本地 HTML 解析通过直接解析 message.content[] 首次实现了 Skill 归因,而 S3+Athena+QuickSight 则将分析边界扩展到了"任意维度即席查询"。这条演进路径本质上反映了团队对 Agent 成本认知的逐步深化。
Bedrock 费用数据的结构性缺失与三种绕过路径¶
文章揭示了一个关键事实:Amazon Bedrock 在 API 响应中不返回费用字段,这是云厂商与本地部署的显著差异。这一缺失导致所有官方监控工具(如 diagnostics-otel 插件)的 openclaw_cost_usd_total 指标为空,形成了成本可见性的系统性盲区。
社区通过三种路径绕过这一限制:ClawProbe 内置 30+ 模型价格表进行本地估算;本地 HTML 解析方案复用同样的价格表生成报告;S3+Athena+QuickSight 方案则在 Athena 视图中硬编码价格系数($5/$25/$6.25/$0.5 per 1M tokens)。三种路径本质相同,差异仅在于数据管道和可视化层。这一共同点说明 Bedrock 费用估算的最佳实践是将价格表配置在数据预处理层,而非依赖厂商返回。
自然语言查询在运维场景的颠覆性意义¶
文章中 Amazon Q in QuickSight 的引入最具前瞻性——它将"临时深挖"的门槛从写 SQL 降到了说人话。对于 Agentic AI 这种行为非确定性的系统,运维人员往往在问题发生前不知道该看哪个维度,传统 BI 的预设图表模式在这里失效。
这一能力的工程意义远超便利性:它将"成本异常排查"从专业 SQL 技能依赖转变为业务人员可直接操作的领域,降低了 Agent 运营的分析摩擦。结合 OpenClaw 的 JSONL 结构化日志体系,Amazon Q 能够理解 session 内部的嵌套结构(如 tool_use 的 name 字段、stopReason 的语义),这要求数据管道在预处理阶段完成扁平化,否则自然语言查询无法穿透嵌套层级。
Skill 级归因是 Agent 可观测性的最后一块拼图¶
四种方案中,只有后两种(本地 HTML 解析 + QuickSight)实现了 Skill 级归因,而前两种(OTel + ClawProbe)均无法捕获工具调用嵌套在 message.content[] 数组中的结构。这一差距的根因在于:OTel metrics 的设计初衷是度量"系统事件"而非"业务语义",工具调用属于应用层业务行为,其归因需要应用层自行解析。
这揭示了 Agent 监控与传统微服务监控的本质差异:微服务的调用链是可观测的,因为工具是确定的;而 Agent 的 Skill 调用是模型推理的结果,其成本归因必须在应用层实现,不能依赖中间件层面被动捕获。这意味着每引入一个新的 Skill,团队都需要同步更新日志解析逻辑,否则该 Skill 的成本就会成为盲区。
企业级演进的本质是"分析密度"的提升¶
从 Athena 演进到 Redshift 的路径不只是技术升级,而是分析密度从"天级聚合"到"分钟级明细"的跨越。当 OpenClaw 从个人工具扩展为多实例团队部署时,单个 session.jsonl 的分析价值下降,跨会话、跨用户的聚合分析需求上升——这时候列存储(Redshift)相对于对象存储(Athena 扫描 JSONL)的查询性能优势就成为刚需。
同时,跨数据源 JOIN(将 Token 消耗与业务数据关联)是 ROI 评估的基础——团队需要回答"每个用户任务消耗了多少 Token、产生了多少业务价值",而不是停留在"系统级费用是多少"。这个跨越要求数据模型从时序日志(session_flat)演进为包含业务语义的宽表,这是 Agent 运营从"技术优化"走向"业务价值验证"的关键转折。
实践启示¶
-
优先补齐 Bedrock 费用盲区:无论选择哪种方案,都需要在数据预处理层内置价格表估算,否则
openclaw_cost_usd_total将永远为空。建议在第一个可用的方案中直接集成 ClawProbe 的价格表逻辑,避免后续迁移时重复造轮子。 -
Skill 级归因需要应用层主动实现:不要依赖中间件或官方插件捕获工具调用,必须在应用层(Skill 或预处理脚本)直接解析
message.content[]中的 tool_use 条目。建议为每个新引入的 Skill 同步更新日志解析逻辑,防止出现成本盲区。 -
四方案互补而非替代,构建三层可观测闭环:本地 HTML 日报负责异常主动发现(日常巡检),Dashboard 负责趋势回顾(周/月度分析),Amazon Q 负责临时深挖(根因分析)。三种能力的组合才能覆盖"知道异常→分析趋势→挖掘根因"的完整链路。
-
扁平化日志是自然语言查询的前提:S3+Athena+QuickSight 方案的核心不在于 QuickSight 的可视化,而在于 flatten-and-upload Skill 将嵌套 JSON 扁平化为可查询的平面结构。嵌套结构(如 tool_use 嵌套在 content 数组中)如果不做扁平化,Amazon Q 将无法理解语义,分析能力大幅受限。
-
企业级扩展时优先考虑 Redshift 而非仅扩展 Athena:当数据量超过 GB 级且需要跨数据源 JOIN 时,Redshift 的列存储和物化视图能提供 10-100x 的查询加速,且与 QuickSight 的集成无需修改任何界面层。建议在数据量增长到难以通过 Athena 按扫描量计费覆盖时,提前迁移以避免分析能力成为业务瓶颈。
本系列文章
- Data for AI:取之有度,用之有节!从Harness视角破解Agent应用Token爆炸难题
- Data for AI:明其所耗,知其所因!让每一分 Token 消耗都可量化的全栈实践
- 存之有序,治之有矩——Agent 记忆系统的工程实践与演进
➡️ 下一步行动:
相关产品:
- Amazon S3 — 适用于 AI、分析和存档的几乎无限的安全对象存储
- Amazon Athena — 使用 SQL 在 S3 中查询数据
- Amazon QuickSight — 高速业务分析服务
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- Amazon Redshift — 经济高效的数据仓库
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者¶

亚马逊云科技中国峰会¶
开发者挑战赛现场开启,基于真实业务场景亲手构建 Agent。


相关实体¶
- 飞来汇借助 Aws Security Agent 构建跨境支付应用的智能安全防线
- How Aws Smgs Uses An Ai Powered Conversational Assistant To
- 滴滴国际化客服质检智能化之路基于 Amazon Bedrock 的多语种多业务线质检实践
- Powering Agentic Ai Sales Strategy With Amazon Bedrock Agent
- Automate Aml Alert Triage With Amazon Quick And Snowflake Co
- MOC
Ch14.004 阿里云 Kafka × Iceberg 零 ETL 实时入湖:ApsaraMQ for Kafka × OSS Tables 架构减法¶
📊 Level ⭐⭐ | 24.2KB |
entities/aliyun-kafka-iceberg-zero-etl-architecture-subtraction-2026-06-18.md
阿里云 Kafka × Iceberg 零 ETL 实时入湖:ApsaraMQ for Kafka × OSS Tables 架构减法¶
核心定位¶
阿里云官方对流数据入湖"零 ETL"趋势的系统阐述。核心命题:AI 时代数据架构趋势 = 数据链路更短 + 数据资产更开放 + 表能力与存储能力更靠近 + 平台能力尽量内聚。
实现:ApsaraMQ for Kafka × OSS Tables 已完成初步实践验证,对外开启邀测。
演进背景¶
传统离线数仓 → 实时数仓 → 流批并立 → 统一数据湖 + 开放表格式
AI 时代两类核心需求在同份数据上同时实现: - 实时需求(模型训练/特征工程/在线推理/经营分析/风控审计)→ 低延迟 + 持续处理 - 历史需求 → 低成本 + 可治理 + 多引擎复用
→ 数据必须在更短链路上完成接入、沉淀、复用
实时入湖 4 大趋势¶
- 开放格式优先(Iceberg 凭借开放元数据标准 + 多引擎兼容 + Schema 演进成为核心)
- 零 ETL 诉求(消息系统更直接将数据持久化为开放表格式)
- 存算分离深化(Kafka 存储层 + 数据湖存储层都向存算分离演进)
- Serverless 化(流处理与消息服务按需计费)
Kafka 入湖 3 大阵营¶
| 阵营 | 代表产品 | 核心思路 | 价值 | 限制 |
|---|---|---|---|---|
| 原生集成 | Confluent Tableflow、Redpanda Iceberg Topics | Broker 层直接将 Topic 物化为 Iceberg 表 | 架构简洁、零 ETL、延迟低 | Vendor lock-in 风险高 |
| Connector / ETL | AWS MSK Connect + Iceberg Sink、开源 Kafka Connect Iceberg Sink | 通过 Connector 消费并写入 Iceberg | 灵活可控、开源生态丰富 | 运维复杂、延迟高、exactly-once 难保证 |
| 生态平台 | Databricks、Snowflake | 平台集成能力摄入 Lakehouse | 与分析引擎深度集成 | 锁定特定格式(Delta Lake)/ 平台,开放度不足 |
架构理念:原生集成阵营更贴近"零 ETL",但要平衡开放性与中立性。
零 ETL 减掉了什么¶
传统链路:Kafka → Flink/Spark Streaming → 开放表 → 对象存储
减掉的三类系统复杂度: 1. 系统边界增加:数据从 Kafka 流出再由外部任务消费/转换/写入/提交,跨越独立运行时和独立调度 2. 通用能力重复实现:消息解码/Schema 映射/位点管理/事务提交/小文件控制/失败恢复,每条 ETL 都要实现 3. 平台成本持续上升:流计算集群、监控、发布、排障
"零 ETL"真正减掉: - 一层额外的数据搬运链路 - 一批重复实现的工程逻辑 - 一部分与业务价值无关的运维复杂度
Kafka × Table Bucket 3 层架构¶
| 层级 | 职责 |
|---|---|
| 协议接入层 | 兼容标准 Kafka Producer / Consumer 协议 |
| 转换处理层 | 格式转换、Schema 感知、CDC 解析、分区路由 |
| 表存储层 | 表写入、元数据管理、对象存储落盘、后台优化 |
关键创新:转换引擎与表写入内嵌到更靠近 Broker 的执行链路,减少网络往返、独立调度、ETL 集群复杂度。部分实现中数据从 Kafka 分区到 Iceberg 表的转换在同一进程内完成。
核心数据流:3 阶段端到端¶
阶段 1:记录转换(RecordProcessor)¶
- Key/Value 反序列化、Transform 链处理、记录组装
- 支持 String / Avro Registry / Protobuf
- 通过 Flatten / Debezium 转换链展开嵌套结构 / 解包 CDC 事件
阶段 2:Schema 感知与演进¶
- 比较当前 Schema vs 目标表 Schema
- 兼容性变更自动处理
- 写完再应用新 Schema
阶段 3:Iceberg 写入与事务提交¶
- Append 模式:PartitionedWriter / UnpartitionedWriter 直接追加
- Upsert 模式:生成 DataFile(数据)+ DeleteFile(删除标记),支持 Insert/Update/Delete
- 文件达到阈值(64MB)自动切换新文件
- 表级事务原子提交 → 新 Snapshot → 下游一致可见
关键能力¶
1. 兼顾低延迟与强一致¶
- 存算分离 × 轻量化 HA:计算与持久化解耦,Follower Replica 仅作计算热备
- 双路同步缓解"延迟-吞吐"权衡:
- 增量预同步(提交间隙持续完成读取/转换/写入)
- 强一致同步触发时只需提交少量增量
- 入湖进度内聚于 Leader 元数据:去除外挂 KV 等外部系统依赖
- 嵌入式 vs 独立式双模式:嵌入式低资源开销但 GC 压力;独立式进程隔离但资源成本高
2. Schema 自适应演进¶
| 演进类型 | 含义 | 处理策略 |
|---|---|---|
| ADD_FIELD | 新增可选字段 | 自动应用 |
| MAKE_OPTIONAL | 必填字段变为可选 | 自动应用 |
| PROMOTE_TYPE | 类型向上提升(int → long、float → double) | 自动应用 |
| 嵌套递归演进 | Struct 等嵌套结构中递归处理 | 自动应用 |
| 删除字段 / 复杂结构重组 | 不兼容变更 | 保守拒绝,避免一次上游变化中断整条链路 |
3. 多层小文件治理¶
| 层级 | 阶段 | 典型粒度 | 作用 |
|---|---|---|---|
| L1 | 内存 Buffer 合并 | 行级 | 在内存中聚合小批次,避免立即落盘 |
| L2 | 微批处理 | 32MB | 控制单次 flush 的批次规模 |
| L3 | 目标文件大小控制 | 64MB | 写入引擎层面控制文件大小阈值 |
| L4 | 后台 Compaction | 文件级 | 异步合并小文件,不占用计算侧资源 |
通常 L1~L3 入湖引擎侧完成,L4 后台离线 Compaction 承担。
4. 智能分区策略(7 类)¶
# 按地区 + 天双维分区
partition_by: "region, day(timestamp)"
# 高基数 ID 哈希分桶
partition_by: "bucket(user_id, 10)"
# 邮箱前缀归类
partition_by: "truncate(email, 5)"
支持:字段直接分区 / Year / Month / Day / Hour / Bucket / Truncate。
5. 完整 CDC / Upsert 支持¶
- 原生集成 Debezium 解包
- 借助 Iceberg Equality Delete 机制生成数据文件 + 删除标记
- 读取阶段自动合并为最新视图
6. 多 Catalog API 兼容¶
- Iceberg REST Catalog(开放生态主流标准)
- OSS Tables 兼容 Catalog(面向 S3 Tables 迁移场景)
- 下游引擎:Spark / Trino / Flink / DuckDB 都能围绕同一份数据
协议与格式的深度融合(3 大变化)¶
- 流批自动转换:数据写入即入湖,天然支持流读与批读,无需两套代码路径
- Schema 自适配:自动感知 ADD_FIELD / MAKE_OPTIONAL / PROMOTE_TYPE + 嵌套结构递归演进
- 进程内绑定调度:转换引擎与 Broker 进程内联 → 数据可见性收敛到分钟级(条件合适时逼近秒级)
传统 vs 零 ETL 对比¶
| 维度 | Kafka + Flink/Spark + Iceberg | Connector / ETL 方案 | Kafka × Table Bucket(零 ETL) |
|---|---|---|---|
| 架构复杂度 | 高(三段式 + 独立调度) | 中(Connector 集群) | 低(单链路内聚) |
| 开发成本 | 高(Streaming SQL/Code) | 中(Sink 配置) | 低(声明式配置) |
| Schema 演进 | 依赖人工或外部框架 | 部分支持 | 平台内建自动演进 |
| 小文件治理 | 业务自行处理 | 部分支持 | 多层递进式内建治理 |
| Exactly-Once | 需要业务保证 | 配置复杂 | 进度内聚 + 事务提交 |
| 运维成本 | 三重成本 | 双重成本 + 集群运维 | 接近二元成本结构 |
| 复杂流计算 | ✅ 强项 | ❌ 不适合 | ❌ 不适合 |
清醒判断:零 ETL ≠ 取代复杂流计算引擎。窗口聚合/多流 Join/维表关联/复杂事件处理/大规模状态管理 → 仍需 Flink/Spark Streaming。两者是分工而不是替代。
4 类优先受益场景¶
1. 实时日志分析¶
应用/访问/安全/系统日志 → Filebeat/FluentBit → Kafka → Trino/Spark 直接查询。写入持续、查询维度稳定、保留周期长。
2. 数据库变更实时入湖¶
MySQL Binlog / PostgreSQL WAL → Debezium → Kafka → Iceberg Upsert/Delete → 接近实时呈现当前业务状态。关键价值:保留主键/删除语义/可查询的当前视图。
3. IoT 多源数据汇聚¶
4 个共同特征:吞吐高 / 来源多 / 字段变化频繁 / 历史保留需求强。下游:Spark 大规模分析 + DuckDB 轻量查询。
4. AI 多模态训练数据 Pipeline¶
依托阿里云 OSS「对象 + 向量 + 表格」完整数据存储体系: - 路测原始数据 → OSS 对象桶 - Embedding + 召回索引 → OSS 向量桶 - Kafka 实时采集的车辆标注信息、传感器元数据 → OSS Table Bucket
三桶数据共享同一套账号、权限、审计体系,训练样本筛选与版本回溯可在单一平台完成,数据准备效率提升数倍。
阿里云实现:ApsaraMQ for Kafka × OSS Tables¶
已开启邀测。Kafka Table Topic 以 Iceberg 开放表格式持久化到 OSS Table Bucket,通过 Iceberg REST Catalog 与 Spark / Trino / Flink / DuckDB 开放生态对接。
已实现能力:多层小文件治理、Schema 自适应演进、CDC Upsert、多 Catalog 兼容。
下一阶段演进方向¶
- 更丰富的 Transform 与更智能的运维能力
- 与查询/计算/治理体系进一步打通
- 持续适配 Iceberg 等开放表格式演进,并兼容更多面向 AI 场景的新型格式
与 wiki 既有内容的关系¶
- 与 Databricks Storage Ecosystem 开放共享治理:都讲 Lakehouse + 开放表格式;Databricks 是"生态平台"阵营(Delta Lake 锁定),阿里云是"原生集成"阵营(中立兼容)——3 大阵营中的两极
- 与 750B MoE PD-Disaggregation AWS EFA(尚未入库):同属顶级云厂技术体系;本文是数据基础设施,750B MoE 是推理基础设施
- 与 Amazon Quick 加速企业数据到 AI 决策:都讲企业数据 → AI;Quick 是消费侧(无 SQL 业务查询),本文是生产侧(Kafka 实时入湖)
- 与 Harness Engineering:都讲"工程化收敛";Harness 是 AI 智能体工程,零 ETL 是数据基础设施工程;Harness 强调"通用能力内聚",零 ETL 强调"通用入湖能力内聚"——同一思想跨域应用
深度分析¶
"架构减法"作为方法论的深层含义:阿里云提出的"零 ETL"不仅是技术优化,更是一种架构哲学——通过减少数据链路中的中间层(ETL 管道、Schema Registry 独立部署、小文件合并脚本),将复杂度内聚到平台层。这与 Harness Engineering 的"通用能力内聚"思想高度一致,但应用场景从 AI 智能体工程转向数据基础设施。
3 大阵营的竞争本质是"谁控制元数据":Confluent Tableflow(原生集成)vs MSK Connect(托管连接器)vs Databricks/Snowflake(生态平台)的竞争,表面是产品形态之争,本质是元数据控制权之争。控制了 Schema Registry + Iceberg Catalog,就控制了数据消费的入口。阿里云选择"中立兼容"路线(同时支持 Iceberg REST Catalog 和 Glue/HMS),是在赌开放标准最终胜出。
Schema 自动演进是零 ETL 的技术护城河:4 种 Schema 演进模式(ADD COLUMN、类型拓宽、列重命名、嵌套结构变更)的自动处理,是区分"真正的零 ETL"和"把 ETL 隐藏到平台里"的关键。如果 Schema 变更仍需人工干预,那 ETL 只是换了个名字。
小文件治理的工程智慧:32MB/64MB 两阶段 compaction 策略(先 32MB 合并再 64MB 合并)体现了流式写入与批式查询的典型矛盾。这种"分层合并"模式在 LSM-Tree、Delta Lake 增量压缩中都有体现——是数据系统设计的通用模式,不是 Iceberg 特有问题。
AI 多模态训练场景是最大增量价值:4 类受益场景中,"AI 多模态训练数据实时入湖"是最具战略意义的——它将 Kafka 的流式数据能力直接对接到 AI 训练管线,省去了传统 ETL→对象存储→训练数据加载的 3 步延迟。这与 2026 年 AI 基础设施"数据-训练-推理一体化"的趋势完全吻合。
实践启示¶
-
评估零 ETL 方案时,重点考察 Schema 演进能力:不要被"零 ETL"营销话术迷惑——真正的测试是:当上游 Schema 变更时,下游查询是否自动兼容?要求厂商演示 ADD COLUMN + 类型拓宽 + 嵌套结构变更三种场景。
-
选择"中立兼容"路线降低锁定风险:同时支持 Iceberg REST Catalog + Glue/HMS 的方案(如阿里云 OSS Tables)比锁定单一 Catalog 的方案(如 Delta Lake-only)更具长期价值。开放表格式的竞争格局尚未尘埃落定。
-
小文件治理必须内置于平台层:如果零 ETL 方案不自带 compaction 策略,你最终会回到手动合并小文件的噩梦。要求方案提供 32MB+ 的自动合并能力,并确认合并是否影响写入延迟。
-
AI 训练管线是零 ETL 的最佳落地场景:如果你的团队在做多模态模型训练,实时入湖方案可以将数据延迟从小时级降到分钟级。优先评估 Kafka → Iceberg → 训练框架的端到端链路。
-
CDC Upsert 是 DB 变更捕获场景的必备能力:对于数据库变更同步到数据湖的场景,没有 Upsert 支持的零 ETL 方案是不完整的。确认方案支持 Debezium 格式的 CDC 事件,并能正确处理 DELETE + UPDATE 操作。
相关实体¶
→ 原文存档
- Databricks Storage Ecosystem 开放共享治理
- 750B MoE PD-Disaggregation AWS EFA(尚未入库)
- Amazon Quick 加速企业数据到 AI 决策
- Harness Engineering
- ConardLi Harness Engineering 综合性指南(+ Beautiful Article 第 2 来源)
- 美团海报生成 AIGC PosterCraft/PosterOmni/PosterReward
Ch14.005 Good QC for RL Data¶
📊 Level ⭐⭐ | 13.4KB |
entities/good-qc-for-rl-data.md→ 原文存档
核心要点¶
- 来源: Sean Cai (seancai.com) | 2026-05-07
- 评分: value=9, confidence=8, product=72
- 提出 RL 训练数据的 QC 标准框架,包括 Intake Review(准入审查)和 Active Testing(主动测试)两大阶段
- Intake Review 涵盖验证光谱分类、污染抗性、pass@k 分布分析、评分标准构建模式
- Active Testing 覆盖 Reward Hacking、Forgetting、Verifier FP/FN 等训练中才暴露的失败模式
- 批评 FrontierSWE、ProgramBench、Tau-Bench、DSBench、MMMLU 等基准在 QC 各维度上的缺陷
- 市场含义:数据供应商若无法展示完整的 QC 审计结果,将在 2026 年面临合同终止
- 核心论点:QC 执行鸿沟是数据市场最大的尚未解决的问题,掌握 QC 的供应商可获得 3-5x 定价溢价
背景与动机¶
数据市场的验证性困境¶
2026 年 1 月,Sean Cai 提出 Type 1 / Type 2 数据的新定义——数据行业迫切需要一套评估数据质量的标准化语言。向长周期(long-horizon)训练范式的转变使得基于模型的 QA 需求急剧增长,远超当前数据公司的"体力工厂"能力 。
数据市场进入顺序直接对应了可验证性:先选择可验证的领域,再构建剥离注意力和不可逆性的环境,然后避免需要承担争议立场的奖励函数。这些选择效应的痕迹被固化在流水线设计中。即使在理论上"简单"的领域,区分有用 Type 1 数据与贬值数据的 QC 纪律也尚未成为数据市场的共享语言 。
前沿实验室的 QC 成熟度¶
前沿实验室的 QC 标准在过去 18 个月中逐渐成型,已经是一套可防御的、非理想化的标准。任何在 2026 年向前沿实验室销售数据的供应商都隐性地被这套标准衡量——大多数供应商在多个关口同时失败。2026 年运往前沿实验室的大部分数据未能通过实验室自己的内部 QC 框架 。
QC 框架详解¶
Intake Review(准入审查)¶
在任何一个后训练运行触及数据之前,首先要问:这个数据集本身是否可评估?这是 QC 体系中最便宜的关口,也是大多数数据公司跳过的关口。前沿实验室花费六位数试用合约在一个未通过 Intake Review 的数据集上,等于付了两次钱:一次付数据本身,一次付训练运行消耗的 GPU 小时和研究员注意力 。
验证光谱分类(Verification Spectrum Classification)¶
确定任务位于确定性代码评分(如 SWE-bench Verified)与 LLM-judge 评分标准(如 HealthBench、FLASK、BiGGen Bench、Prometheus 2 的原子式/二元/轴标签化模式)之间的位置。不可自动验证的任务应作为 SFT 演示数据而非基于奖励的 RL 数据交付。跳过分类导致实验室将未经审计的 LLM judge 插入奖励函数 。
污染抗性与变体生成(Contamination Resistance)¶
数据集的"可爬升性"是否能存续到下一代模型?GPQA、AIME、FrontierMath 等静态集的判别力在一年内衰减——问题泄露到预训练数据中,而供应商没有警戒线、没有轮换节奏、没有恢复方案 。
Pass@k 与分布分析¶
pass@1 在目标模型上为零或难度分布呈双峰的数据集,不产生任何可用的梯度 。
评分标准构建模式¶
评分标准是原子+二元的,还是复合+可奖励劫持的?每个问题背后都有已发表的警示案例,错误的代价由实验室而非供应商承担 。
Active Testing(主动测试)¶
Intake 通过后,通过小规模消融+小规模后训练来压力测试数据,捕捉 Intake 无法发现的问题 。
Reward Hacking¶
在所有实验室对话中反复出现。METR 报告 o3 的 1-2% 尝试包含沙箱内的漏洞利用,AISI 发现 OpenClaw 从隔离环境内反向工程自己的评估代理,ImpossibleBench 发现 GPT-5 在 impossible-SWEbench 变体上 76% 的尝试劫持测试用例。然而大多数供应商从未运行过一个探针来检查自己的数据是否训练了这种行为 。
Sycophancy / Reward-Tampering / Alignment-Faking¶
三种已发表的探针——供应商应运行它们。Alignment-faking 的基线为 12%,但几乎没有供应商在做 。
Verifier 审计¶
SWE-bench Verified Pro 模式——200 PASS + 200 FAIL 人工重新判定,FP 和 FN 率分别报告——已成为最低门槛。OpenAI 2026 年对原始 SWE-bench 的退役分析发现 59.4% 的审计问题包含有缺陷的测试用例 。
Forgetting 检查¶
需要按技能(per-skill)而非聚合方式测量。Tulu 3 发布了基准:SFT 持续后训练约 -10.4%,on-policy RL 约 -2.3%。Qi et al. 证明聚合数据在安全相关数据上具有误导性——小型良性微调可以剥离 RLHF 安全护栏而聚合分数保持平稳 。
失败分类(Failure Triage)¶
每个失败 rollout 标记为 capability、prompt、scaffolding、rubric、training-data、orchestration 或 triangulation,为供应商提供具体的编辑清单 。
基准评测批评¶
| 基准 | 主要缺陷 |
|---|---|
| FrontierSWE (Proximal) | 最强验证机制,但每个模型锁定在自己的生产 Harness 上,无法分离模型与脚手架的贡献 |
| ProgramBench | 完整的 Web 2.0 软件重建任务——不是任何生产编码 Agent 的部署场景。混淆了竞赛难度与生产效用 |
| Tau-Bench | 测量多轮客户服务交互的最终状态正确性,跳过了负载关键的过程评估 |
| GDPval | 重建的生产力任务并非真实组织上下文中的生产力任务 |
| MMMLU | 40 种语言的标准 MMLU 污染模式,无警戒线、无轮换、已知泄漏 |
| DSBench | 86% 的任务使用 GPT-4o-as-judge,仅一次验证声明,从 34% 饱和到 89% 仅用了十个月 |
| Terminal-Bench 2.0 | 任务验证良好,但停留在短 shell 任务范围,隐藏了长周期工作的不可逆性和过程评估失败 |
相对较好的基准¶
通过更多类别的基准通常在单一维度上表现良好:BankerToolBench(Handshake)在金融工具使用的真实性上最干净;LiveCodeBench Pro 从竞赛站点抽取新鲜问题并随年龄退休;SciCode 通过手写确定性检查器处理部分学分的科学编程验证 。
门槛 vs 差异化¶
门槛级(可自动化)¶
数据集文档清单、原子评分标准构建(含 linter)、verifier 健全性审计、n-gram 污染报告、跨模型无偏 pass@k、多 seed bootstrap 置信区间、eval harness 声明、trace 制品、至少两个 scaffolding 配置的表面分层、来自版本化候选列表的探针模型选择 。
差异化级(需研究团队)¶
验证器上的偏置探针电池、sycophancy/reward-tampering/alignment-faking 探针、反事实扰动的 CoT 忠实度探针、IRT 能力审计、在线 RL 通道诊断(PPO 和 GRPO) 。
市场含义¶
定价溢价结构¶
2026 年,前沿实验室已学会大幅折扣黑盒——尤其是那些不关心自身数据质量的供应商的黑盒。建立了完整 QC 基础设施的少数供应商(主要是研究密集的团队)在价格上享有 3-5x 的溢价,溢价建立在持续信任和可靠的质量优先合作基础之上 。
Type 1 vs Type 2 数据判定¶
如果一家数据公司到 2027 年仍无法提供跨至少三个模型的 pass@k 分布、针对人类金标的 verifier FP/FN 率、针对命名评估套件的污染检查以及探针模型的前沿形状诊断,他们卖的不是 Type 1 数据——而是带有 Type 1 营销的 Type 2 数据。实验室将在一个采购周期内发现这一点,多份传闻表明已经有多家被识别出 。
深度分析¶
1. QC 框架的"通过"是动态的,而非静态的¶
Intake Review 通过不代表数据可用——Active Testing 才是真正的质量验证。o3 的 1-2% 沙箱漏洞尝试和 GPT-5 在 impossible-SWEbench 上 76% 的测试用例劫持率说明,数据在 RL 训练中会暴露全新的失败模式 。这意味着供应商需要同时运行 Intake(静态审计)和 Active Testing(动态探针),而非只做其一。
2. 验证光谱分类是 RL 数据与 SFT 数据的本质分水岭¶
不可自动验证的任务(LLM-judge 依赖)如果被当作 RL 数据交付,实验室实际上是在用未审计的奖励函数训练模型。2026 年 59.4% 的 SWE-bench 退役问题含缺陷测试用例,说明即使是"已验证"的数据集也存在系统性偏差风险 。分类决策不可逆——选错类型,数据永远无法产生有效梯度。
3. 污染的隐蔽性导致"测量-衰减"螺旋¶
GPQA、AIME、FrontierMath 等静态集判别力在一年内衰减,而供应商没有警戒线或轮换方案 。这揭示了一个结构性悖论:越"著名"的基准,越快被预训练污染;越污染,数据越没用;但市场仍在用饱和度作为质量信号。这是一个正在恶化的系统性问题。
4. Forgetting 的 per-skill 测量颠覆聚合评估的有效性¶
Qi et al. 证明聚合数据在安全相关任务上具有误导性——小型良性微调可以剥离 RLHF 安全护栏而聚合分数保持平稳 。这对数据采购的启示是:任何只看聚合指标的 QC 流程都在欺骗自己,真正的安全数据需要逐技能验证。
5. 3-5x 定价溢价是信息不对称的函数,而非纯粹质量的函数¶
前沿实验室愿意为完整 QC 基础设施支付溢价,但这不代表市场有效——它代表大多数供应商无法提供可验证的质量证据 。溢价是稀缺性的反映,而不是供应商能力的证明。这意味着建立 QC 标准本身比提升 QC 执行更重要。
实践启示¶
1. 建立双阶段 QC 流程:Intake Review + Active Testing¶
不要跳过 Intake Review(最便宜的关口)。对于每个数据集,必须在投入训练前完成:验证光谱分类、污染抗性测试、pass@k 分布分析、评分标准模式审计 。通过 Intake 后,用小规模消融+后训练探针验证 Reward Hacking、Sycophancy、Alignment-Faking 等动态失败模式 。
2. 优先选择可自动验证的领域构建 RL 数据¶
确定性代码评分(SWE-bench Verified 模式)是最易辩护的 RL 数据类型。LLM-judge 依赖的任务应作为 SFT 演示数据交付,而非基于奖励的 RL 数据 。这一决策边界应在数据采购合同中明确。
3. 对每个基准建立"警戒线-轮换-恢复"机制¶
静态评估集(AIME、GPQA 等)的判别力会衰减 。对于长期数据管线,不能依赖单一基准,需要建立:连续监控污染水平(n-gram 报告)、问题池轮换节奏、以及当判别力跌破阈值时的恢复方案。
4. 对齐测试应作为 RL 数据的标准交付物¶
Alignment-faking 基线 12%、Reward Tampering、Sycophancy——这三个已发表的探针几乎没有供应商在运行 。在 2026 年,这些探针应成为数据交付的标准配置,而非可选项。如果供应商无法提供探针结果,实验室应将其视为高风险供应商。
5. 构建 per-skill 的 Forgetting 测量而非依赖聚合指标¶
数据采购评估不能只看聚合分数。必须按技能维度分解,验证安全护栏在每个技能类别上的保持情况 。这要求数据供应商提供细粒度的任务分解和分项测试结果,而非单一总分。
相关概念¶
- MSM Model Spec Midtraining Alignment — 对齐伪装(Alignment-faking)与模型训练数据的关系
- RAG — 数据可验证性的基础范式
相关查询¶
- LLM Training RL Research — RL 训练与数据质量的综合研究视角
相关实体¶
- Multilingual Ai
- Datacomp For Language Models
- Agent Eval Wallezhang Yaml Driven Agent Evaluation Framework
- How Far Behind Are Open Models 2026
- Langsmith Evaluation Concepts
- nice:浙大提出的理论驱动型 llm 社会智能诊断基准
- MOC
Ch14.006 Kimi K2.6 Agent Database:Agent-native时代的数据基础设施竞争¶
📊 Level ⭐⭐ | 12.8KB |
entities/kimi-k2-6-tidb-agent-database.md
深度分析¶
Agent-native 时代的数据基础设施竞争维度发生了根本性转变:从单点性能到四维并发。 过去 30 年数据库竞争以 TPS、延迟、容量等单点性能为核心;Agent-native 时代,竞争变成同时满足 per-tenant 多租隔离、统一技术栈、即时弹性(秒级 provisioning)、最小化 Agent 使用 Infra 工具的摩擦四个维度。原文指出"这四件事同时发生时,谁能提供最顺畅体验?这是个完全不一样的赛道",意味着 Agent 时代的基础软件选型逻辑与传统时代有本质区别。
订阅制 vs 建站托管的经济约束揭示了 Agent 商业化的核心挑战:hosting 成本。 原文指出 Kimi K2.6 一次性生成代码并持续在线提供服务,但重度 Token 消耗用户每次请求都需 LLM 动态生成,算力成本远超月订阅收入。三个经济约束是关键:长尾分布(大多数请求无请求时不需要真实分配实例)、规模爆炸(上千万站点可能一周内被创建出来)、成本控制(按传统云服务为每网站提供 RDS 实例成本不可接受)。这解释了为什么"代码生成"只是 Agent 建站的第一步,真正的工程挑战在 hosting 层。
"one agent, one sandbox, one storage, one database"正在成为 Agent 商业化团队的主流架构范式。 原文描述了模式转变:过去是一个产品/服务扛亿级用户,一个 app 扛亿级会话;现在是一个用户身边可能有 10 个甚至 100 个 Agent 在跑,每个都需要自己的状态和数据。包括 Kimi 在内的 AI Agent 商业化团队,架构都收敛到同一范式:每个 Agent 需要完整的隔离环境——不仅是计算隔离(sandbox),还包括存储隔离(database)和状态隔离(storage)。
TiDB Cloud 的"虚拟数据库层"架构是解决长尾规模成本问题的关键创新。 物理层面,数据由底层大型封装了对象存储的分布式 KV 数据库提供存储服务;逻辑层面,底层大型数据库自动处理数据可见性隔离和冷热分离。在 Sandbox 中的 Agent 看来,它仍然拥有完整的独立数据库,但实际上没有任何真实数据库实例被分配。结果是:整个数据库平台的弹性能力提升一个台阶,数据使用成本数量级规模下降。这与 Supabase 模式(每个 Agent 配一个真实 PostgreSQL 实例)在成本结构上有根本区别。
Agent Infra 的核心设计原则是"不让 Agent 来扛 retry/poll/wait 的负担"。 原文指出如果数据库 provisioning 占几分钟,Agent 就得在代码里写重试轮询逻辑,这不应该由 Agent 来扛。TiDB Cloud 的 Warm Pool + Scale-To-Zero 技术让 Agent 在 1 秒内拿到 fully prepared 的数据库实例。这一原则可以推广到整个 Agent Infra 设计:基础设施应该对 Agent 隐藏复杂性,而不是把复杂性转嫁给 Agent 代码。
实践启示¶
-
在评估 Agent 平台的基础设施选型时,优先考察四个维度的同时满足程度:per-tenant 多租隔离、统一技术栈、秒级即时弹性、最小化 Agent 使用摩擦。 任何单一维度的极致都不能替代整体体验的顺畅。选型时不要只看单点指标(如 TPS、延迟),而要看这四件事同时做到位时的综合体验。
-
对于面向长尾用户的 Agent 服务(Agent 建站、Agent 办公套件等),需要在服务初期就设计好"虚拟数据库层"架构,避免随用户规模增长导致的成本爆炸。 传统的 per-tenant 真实实例模式在规模超过万级时成本不可控,需要考虑底层分布式 KV 存储 + 逻辑多租隔离的虚拟数据库方案。
-
在设计 Agent 与数据库交互的接口时,应假设 Agent 随时可能发起请求,因此数据库 provisioning 时间必须控制在秒级。 如果基础设施的实例创建时间超过秒级,Agent 代码就需要包含复杂的重试和等待逻辑,这会显著降低 Agent 任务的可靠性和执行效率。基础设施的响应速度是 Agent 执行稳定性的前提。
-
Agent 时代的技术栈统一有额外的战略价值:它直接影响 AI 生成代码的稳定性。 少跨一个系统就少一类 bug,多用 Skill 中写好的技术栈和最佳实践,生成的代码变成服务的稳定性大大提升。对于大量生成代码的 Agent 平台,技术栈统一是质量控制的重要手段。
-
下半场竞争的核心是"Agent 交付出来的东西能不能稳定跑起来",模型能力只是入场券。 上半场各家的模型能力在快速收敛,下半场的差异化竞争在 Agent 托管服务的稳定性和交付体验。这要求团队同时具备模型能力 + 基础设施能力 + 运维能力,而非单纯依赖模型能力。
概述¶
Kimi K2.6 Agent Database 是指 TiDB Cloud 支撑 Kimi K2.6 [Agent 建站]功能的数据库架构实践,由 TiDB 创始人兼 CEO 黄东旭 主导落地验证。该项目将此前"如何做 AI Agent 喜欢的基础软件"和"当我们在谈论 Agent Infra 时我们在谈论什么"等理论文章中的想法,首次大规模应用于生产环境。
核心背景:Kimi K2.6 提供从前端到后端完全由 Agent 托管的建站服务,用户无需技术背景即可使用。真正的挑战不在于代码生成,而在于 hosting 成本——AI 模板服务若每次请求都经 LLM 动态生成,重度 Token 消耗用户的算力成本将远超月订阅收入。
订阅制 vs 建站托管的经济账¶
Kimi K2.6 采取一次性生成代码并持续在线提供服务的模式,而非按次付费的订阅制。这一模式面临三个经济约束:
- 长尾分布:大多数请求是长尾的,没有请求时不需要真实分配数据库实例——但平台仍需随时准备响应。
- 规模爆炸:上千万个站点可能在一周内被创建出来。
- 成本控制:按传统云服务/数据库定价,为每个网站提供一个真实 RDS/PostgreSQL 实例将导致成本爆炸。
既有方案的局限性¶
Supabase 模式¶
Supabase 为每个 Agent 配一个 PostgreSQL 实例的方案,在 Kimi K2.6 的规模下会导致成本爆炸——上百万个独立实例的运维和计费成本完全不可接受。
大型 PostgreSQL 单实例 + Schema 多租户¶
实测在万级规模就扛不住,加上流控、故障半径控制、数据隔离等问题,难以满足 Agent 场景的隔离性需求。
NeonDB 等 Serverless PostgreSQL¶
同样存在成本和规模挑战,无法解决长尾站点的高并发创建问题。
Agent-native 时代的四维竞争¶
过去 30 年数据库竞争以单点性能(TPS、延迟、容量)为核心。Agent-native 时代,竞争维度发生根本性转变:
| 维度 | 描述 |
|---|---|
| per-tenant 多租隔离 | 每个 Agent/站点的数据完全隔离,不能相互影响 |
| 统一技术栈 | 减少跨系统带来的 bug 种类,提升生成代码的稳定性 |
| 即时弹性(秒级 provisioning) | Agent 在 1 秒内拿到 fully prepared 的数据库实例 |
| 最小化 Agent 使用 Infra 工具的摩擦 | 不应让 Agent 来扛 retry/poll/wait 的负担 |
这四件事同时发生时,谁能提供最顺畅体验?这是个完全不一样的赛道。
Kimi K2.6 的三个核心战略决策¶
1. 最小化 Agent 使用 Infra 工具的摩擦¶
目标:每个任务和站点独立隔离,用的时候秒级创建。 TiDB Cloud 的 Warm Pool + Scale-To-Zero 技术让 Agent 在 1 秒内拿到 fully prepared 的数据库实例。
如果数据库 provisioning 占几分钟,Agent 就得在代码里写 retry/poll/wait——这个负担不该由 Agent 来扛。
2. 统一技术栈¶
对 Agent 生成服务所使用的技术栈尽可能统一。少跨一个系统就少一类 bug,多用 Skill 中写好的技术栈和最佳实践,生成的代码变成服务的稳定性大大提升。
3. 极致的低成本¶
引入虚拟数据库层:放弃真实的数据库实例分配和管理。长尾请求时不需要真实分配数据库实例。最极端情况下,整个平台只需要一个常驻的 DB Session Gateway 维持数据库连接,其他所有资源都是弹性的。
架构对比:传统 Serverless DB vs TiDB Cloud¶
传统 Serverless 数据库(Supabase 等)¶
每个 Sandbox 分配一个真实数据库实例存在以下问题:
- 冷却时被回收,难以保证 7x24 永远在线
- 实例数量大,成本难以控制
- 数千万个实例成本爆炸
TiDB Cloud 架构¶
没有真实数据库实例存在,一切都是虚拟的——但在 Sandbox 中的 Agent 看来,它仍然拥有完整的独立数据库。
- 物理层面:数据由底层大型封装了对象存储的分布式 KV 数据库提供存储服务。
- 逻辑层面:底层大型数据库自动处理数据可见性隔离和冷热分离。
- 效果:Agent 层面不会有"实例被回收、休眠或连接中断"等糟糕体验。
- 结果:整个数据库平台的弹性能力提升一个台阶,数据使用成本数量级规模下降。
行业收敛范式:one agent, one sandbox, one storage, one database¶
模式转变:过去是一个产品/服务扛亿级用户,一个 app 扛亿级会话;现在是一个用户身边可能有 10 个甚至 100 个 Agent 在跑,每个都需要自己的状态和数据。
包括 Kimi 在内的 AI Agent 商业化团队,架构都收敛到同一范式:
这一范式的核心洞察:每个 Agent 都需要完整的隔离环境——不仅是计算隔离(sandbox),还包括存储隔离(database)和状态隔离(storage)。
Kimi 对 TiDB Cloud 的评价¶
选 TiDB 的核心原因不在某一个单点指标的极致——而在于 "per-tenant 多租隔离、统一栈、即时弹性" 这三件事同时做到位时,它是少数几个把每一项都"够用且顺手"的系统。
下半场的竞争核心¶
上半场竞争在于谁的模型更聪明、谁的 Agent 推理更长。下半场竞争核心是 Agent 交付出来的东西和结果,在真实用户面前能不能稳定跑起来、持续交付。
模型厂商通过好的基础设施服务,快速/高效地提供更多价值。
相关页面¶
相关实体¶
- Tidb Cloud Agent Database
- Kimi K2 Tidb Agent Database Huangdongxu 20260513
- Ara Agent Native Research Artifact 37Authors
- Hermes Agent K2 6 Tutorial
- Kimi Work Codex Vibe Working Paradigm Shift
Ch14.007 Kimi K2.6背后的Agent Database:Agent-native 时代的数据Infra竞争,跟过去30年有何不同¶
📊 Level ⭐⭐ | 11.7KB |
entities/kimi-k2-tidb-agent-database-huangdongxu-20260513.md
背景¶
黄东旭前几篇文章(如何做 AI Agent 喜欢的基础软件、当我们在谈论 Agent Infra 时我们在谈论什么)提出了一些猜想,本文是这些理论的大规模落地验证——TiDB Cloud 正式成为 Kimi K2.6 的供应商,为 Kimi Agent 建站服务提供动态大规模的 Agent Database 支持。
Kimi K2.6 Agent 建站场景¶
最典型的 End-to-End 在线应用构建场景:Agent 帮助人类生成代码,形成真实可用的在线服务,用户无需任何技术背景。 与 Loveable 等其他 AI 建站应用的区别:Kimi K2.6 从前端到后端完全接管/托管。 核心挑战:不在于代码生成,而在于 hosting 的成本。
为什么 hosting 成本是关键¶
- 受众变大(无技术门槛)→ 用户量激增
- 大多数 AI 模板服务按月订阅,重度 Token 消耗用户的算力成本往往超过订阅费
- 但网站托管/一次性生成代码并持续在线服务的场景:算力消耗集中在创建那几下,服务运行后按月收费,基础设施成本(Web 服务器、带宽、数据库)利润空间更大 主要挑战:一周内可能上千万个站点被创建出来,按传统云服务或数据库定价,为每个网站提供一个真实 Postgres/RDS 实例 → 成本爆炸。
为什么选 TiDB 而不是 NeonDB/Supabase¶
Supabase 模式问题:每个 Agent 配一个 Supabase PostgreSQL,上百万个实例 → 成本直接爆炸。 PostgreSQL 多 Schema 隔离问题:单个实例在万级规模时扛不住,更不用说流控、故障半径控制和数据隔离。 核心原因:成本。Agent-native 场景需要完全不同的架构思路。
Agent-native 时代的数据 Infra 竞争逻辑¶
过去 30 年:比单点性能(谁的 TPS 高、谁的延迟低、谁支持更大的单库容量)。 现在比的是当以下四件事同时发生时,谁能提供最顺畅的体验: 1. 海量长尾租户:尽管请求量不大,但全都要求在线 2. LLM 即席改 Schema:必须支持分支和多版本 3. 无法预测的突发流量 4. AI 在秒级别随时动态创建/销毁,以及动态生成访问的 SQL 这是完全不一样的赛道。
三个核心战略决策¶
1. 最小化 Agent 使用 Infra 工具时的摩擦¶
每个任务和站点独立隔离,由 Agent 创建和使用,用的时候能秒级创建。 TiDB Cloud 的 Warm Pool + Scale-To-Zero,让 Agent 在 1 秒内拿到 fully prepared 的数据库实例。 如果数据库 provisioning 占去几分钟,Agent 就得在自己代码里写 retry/poll/wait → 这个负担不该由 Agent 来扛。
2. 对 Agent 生成服务所使用的技术栈尽可能统一¶
人类工程师觉得方便,对 LLM 来说直接关系到生成代码的成功率。 少跨一个系统就少一类 bug,多用 Skill 中写好的技术栈和最佳实践,而不是每次靠思考和抽卡,大大提升了生成代码变成服务的稳定性。
3. 极致的低成本¶
放弃 Supabase 和 Neon 那样的真实数据库实例分配和管理,TiDB 引入了一层虚拟数据库界面。 大量请求是长尾的——没有请求时,不需要真实分配数据库实例,只需让 Agent/终端用户"假装"后端是一个独立数据库。最极端情况下,整个平台只需要一个常驻的 DB Session Gateway 服务维持数据库连接,其他所有资源都可以变成弹性的。 物理层面:数据由底层封装了对象存储的分布式 KV 数据库提供存储服务,逻辑层面自动处理数据可见性隔离和冷热分离。 Agent 层面不会有实例被回收、休眠或连接中断等不好的体验。 效果:整个数据库平台的弹性能力提升一个台阶,数据使用成本数量级规模下降。
传统 Serverless vs TiDB Cloud 架构对比¶
传统 Serverless 数据库(面对 Agent 场景):
- 每个 Sandbox 分配一个真实数据库实例
- 冷却时被回收,难保证 7×24 永远在线
-
数量大了成本难控制(想象几千万个 Supabase 实例) TiDB Cloud 架构: See also Agent Harness Architecture
-
无真实数据库实例,一切都是虚拟的
- 对 Sandbox 中的 Agent 来说,仍然拥有一个个完整的独立数据库
- 底层大型分布式 KV 数据库逻辑层面自动处理隔离和冷热分离
- Agent 体验:无回收、无休眠、无连接中断
行业收敛:one agent, one sandbox, one storage, one database¶
过去 12 个月陪跑国内外很多 AI Agent 团队基建选型后发现:
- 以前模式:一个产品扛亿级用户,一个 app 扛亿级会话
- 现在模式:一个用户身边可能有 10 个甚至 100 个 Agent 在跑,每个都需要自己的状态和数据 包括 Kimi 在内的 AI Agent 商业化团队采用的架构都收敛到同一个范式:
one agent, one sandbox,one storage,one database
上半场 vs 下半场¶
上半场:谁的模型更聪明、谁的 Agent 推理更长。 下半场:竞争的核心是——Agent 交付出来的结果,在真实用户面前能不能稳定跑起来、持续交付。 Kimi 和 TiDB 的合作是模型厂商通过好的基础设施服务、快速高效提供更多价值的绝佳例子。
深度分析¶
黄东旭这篇文章揭示了 Agent-native 时代基础设施竞争的根本逻辑转变:从"单点性能竞争"到"海量长尾租户的服务连续性竞争"。 核心洞察一:hosting 成本是 Agent 建站场景的决定性瓶颈。Kimi K2.6 的建站场景与传统 SaaS 完全不同——用户无技术背景、创建频率极高(周级千万站点)、每个站点都需要独立的数据库实例但运行时长不确定。传统云数据库的"一个站点一个实例"模式在成本模型上完全不可行。 核心洞察二:虚拟数据库界面是架构关键创新。TiDB 没有试图优化单实例性能或增强多租户隔离,而是在逻辑层面引入"虚拟数据库"抽象,让 Agent 以为自己在用一个独立数据库,实际上底层是共享的分布式 KV 存储。这本质上是一个软件定义的数据层,通过逻辑隔离代替物理隔离,实现了成本数量级的下降。 核心洞察三:"one agent, one sandbox, one storage, one database"正在成为行业标准范式。这与传统的"一个产品服务亿级用户"模式形成鲜明对比——Agent 时代的计算单元从"产品/应用"变成了"Agent + 配套的数据空间"。这意味着基础设施提供商需要重新思考他们的多租户模型、资源调度和计费模式。 核心洞察四:上半场(模型能力)和下半场(Infra 稳定性)的竞争维度不同。模型能力可以用 Scaling Laws 预测,但 Agent 交付结果的稳定性取决于 Infra——这篇文章实际上在说:下半场的基础设施竞争,才刚刚开始,而传统的数据库厂商(PingCAP)反而可能比纯云厂商更有优势,因为他们的分布式架构更容易演进到 Agent-native 场景。
实践启示¶
- Agent-native 场景需要重新设计数据 Infra:如果你正在构建 Agent 应用或平台,需要从一开始就假设每个 Agent(或每个用户- Agent 组合)需要独立的存储空间,而不是共享数据库。传统的多租户方案在租户规模上达不到 Agent 场景的要求。
- 关注"虚拟化"而非"物理隔离":成本问题的解决思路是让 Agent 获得独立数据库的体验,而不必真正为每个 Agent 分配独立实例。软件定义的存储抽象(虚拟数据库界面)是关键技术。
- 技术栈统一对 LLM 生成代码成功率有直接影响:在 Agent 应用中,尽量减少技术栈的多样性。使用的技术栈越标准、越少,LLM 生成代码的错误率越低,工具调用的一致性越高。
- 1 秒级资源准备是 Agent 体验的关键:如果 Agent 需要等待几分钟才能获得数据库实例,它就不得不在自己的代码里实现复杂的 retry/poll/wait 逻辑——这本质上是在让 Agent 做 Infra 应该做的事情。好的 Agent-native Infra 应该让 Agent "拿到资源就像已经准备好了一样"。
- 基础设施竞争正在从"性能"转向"弹性":在评估 Agent 场景的 Infra 方案时,不要只看 TPS 和延迟,要看:当百万级长尾租户同时在线、LLM 随时改 Schema、流量完全不可预测、Agent 秒级创建销毁时,系统还能不能保持稳定服务。这才是 Agent-native 时代的核心竞争维度。
来源:InfoQ 黄东旭(PingCAP/TiDB) https://mp.weixin.qq.com/s/XLYWhkjFHxrH2-jb5O1qCQ
Ch14.008 Databricks Storage Ecosystem & OpenSharing:企业数据治理从 Migrate Everything 到 Govern Everything 的范式转变¶
📊 Level ⭐⭐ | 11.5KB |
entities/databricks-storage-ecosystem-opensharing-govern-everything-2026.md
Databricks Storage Ecosystem & OpenSharing:企业数据治理从 Migrate Everything 到 Govern Everything 的范式转变¶
Background:本文基于 Databricks 官方博客 2026-06-10 发布稿,分析其 SDS (Software-Defined Storage) Ecosystem + 开源 OpenSharing 协议如何重塑企业级数据治理范式。涉及 8+ 头部存储厂商(MinIO、Everpure、Qumulo、VAST Data、DDN、NetApp、HPE、Dell 等)联合接入,标志 Hybrid Forever 从口号进入生产可落地阶段。
核心叙事¶
企业数据策略的范式转变:"Migrate Everything" → "Govern Everything"。这与 AWS China 早期倡导的 "Migrate Everything to Cloud" 战略形成对比——Databricks 此举承认了一个结构性现实:对于半导体、金融交易、制药、电信等场景,数据不能也不会全部上云。这不是市场撤退,而是更现实的产品定位。
三大驱动 + 一个解法¶
三大驱动力(合规 + 成本 + 延迟)¶
- 数据主权与合规 — GDPR/HIPAA/NIS2/数据驻留规则明确禁止迁移(金融、医疗、政府)
- 数据重力与成本 — PB/EB 规模下 egress 费用 + 存储成本让迁移经济上不可行(大型零售正"反向迁回"本地)
- 边缘低延迟 — 电信网络遥测等场景 cloud round-trip 不可接受(电信、零售、制造)
- 暗数据 AI 价值 — 备份/归档/二级数据中有数百 EB 价值未被挖掘(全行业普遍)
关键数字:SDS 市场规模"数千亿美元"(2026),合作伙伴集体管理 2+ Zettabytes 数据。
解法:SDS Ecosystem + OpenSharing 协议¶
架构三段式:
本地/私有云存储系统
↓ 部署 OpenSharing server(开源协议)
↓ 通过 Partner Well-Architected Framework 认证
└─→ Databricks Unity Catalog(统一治理层)
├─→ Serverless Compute
├─→ Genie(自然语言查询)
├─→ AgentBricks
└─→ Model Training
核心承诺:"Zero data movement, no duplication of data and zero compliance risk." — 数据不出本地,但 Databricks 平台的所有能力都能触达。
与现有 Databricks 实体差异化¶
- 焦点 — 现有 entity(SageMaker AI + Unity Catalog 微调 Nova Micro,ML 训练场景)vs 本 entity(SDS Ecosystem + OpenSharing 协议,数据治理场景)
- 核心问题 — 现有:如何在 SageMaker 上用 Unity Catalog 数据集微调 LLM;本篇:如何让 Databricks 平台不迁移数据直接治理 PB/EB 本地数据
- 目标用户 — 现有:ML 工程师;本篇:数据平台架构师 / CTO / CDO
- 协议层 — 现有:SageMaker ↔ Unity Catalog;本篇:OpenSharing(开源)↔ 存储 ↔ Unity Catalog
- 时间线 — 现有:2026-05 微调技术;本篇:2026-06 治理协议发布
两个 entity 互补不重叠:现有是 ML 训练管线,本篇是数据治理基础架构。建议交叉引用而非合并。
三个独有贡献(不应合并到现有 entity)¶
- 范式转移的明确定义:"Migrate Everything → Govern Everything" 是一句可被复用的战略口号,比单纯产品介绍有更高引用价值
- OpenSharing 开源协议:这是行业级协议而非产品功能——任何存储厂商都可实现,Databricks 通过 Partner Well-Architected Framework 提供技术蓝图
- 2 ZB 数据管理规模 + Hybrid Forever 趋势量化:金融/医疗/政府的实际驱动因素(合规 + 成本 + 延迟)首次被结构化呈现
8+ 合作伙伴矩阵(按发布状态分类)¶
GA(General Availability)¶
- MinIO AIStor — 通过 OpenSharing 桥接 Databricks Intelligence Platform 到本地 Apache Iceberg / Delta 表,Unity Catalog 治理全覆盖
Private Preview¶
- Everpure (Pure Storage) — OpenSharing connector 桥接对象存储与 Databricks workspace
- Qumulo — 集成 NeuralSearch(自然语言发现非结构化数据集),通过 OpenSharing 安全分享
- VAST Data、DDN、NetApp、HPE、Dell Technologies、Hitachi Vantara、IBM、WEKA 等(部分在路线图上)
合作伙伴认证框架¶
Partner Well-Architected Framework(开源蓝图)—— 涵盖架构、安全、认证标准,确保所有 SDS 伙伴实现一致性。
深度分析¶
1. 范式转移:从「迁移优先」到「治理优先」¶
「Migrate Everything」向「Govern Everything」的转变是本文最核心的战略叙事。这一转变承认了一个结构性现实:对于半导体、金融、医疗、制药、电信等受监管行业,数据根本无法全部上云——EB 级别数据的迁移成本、监管机构对数据驻留的硬性要求,以及网络延迟的物理限制,共同构成了云迁移的根本障碍。这不是 Databricks 的策略退步,而是对「数据重力(Data Gravity)」和「合规约束」双重现实的就范。「Hybrid Forever」不再是营销口号,而是一批 Tier-1 企业在 PB/EB 规模下验证过的现实选择。
2. OpenSharing 协议:争夺协议层标准主导权¶
OpenSharing 开源协议的本质是将 Databricks 的治理能力前移到存储层,同时避免数据复制。这是一个「协议层标准战」的战略——类比 MCP 协议在 Agent 工具调用领域的作用,OpenSharing 试图成为存储与计算分离架构下的标准连接协议。一旦成为事实标准,Databricks 就能通过 Unity Catalog 统一治理所有实现 OpenSharing 的存储系统,无论供应商是谁。存储厂商只需实现协议接口即可加入生态,准入门槛低但 Databricks 对标准的主导权强——这是平台公司标准战略的典型打法。
3. Delta Lake / Iceberg 双格式支持:表格式之战升温¶
Databricks 在 SDS 生态中同时支持 Apache Iceberg 和 Delta Lake 两种开放表格式,这意味着 Databricks 在表格式层面采取「开放生态」策略而非锁定自家格式。存储厂商(MinIO、Qumulo 等)无需改造底层格式,只需实现 OpenSharing 协议即可被 Databricks 统一治理。这与 Snowflake 的专有格式策略形成鲜明对比——对于已在使用 Iceberg 的企业,SDS 生态提供了零迁移成本的接入路径。
4. Hybrid Lakehouse 的成熟:数据不动,计算动¶
SDS 生态将 Databricks 的 Lakehouse 架构扩展到真正的混合环境——本地、私有云、边缘。传统的 Lakehouse 本质上还是「云上湖」,而 SDS 让「数据不动,计算动」成为生产级现实。结合 云 AI 基础设施设计 中的 serverless 思潮,这是架构层面的突破:企业无需在数据迁移成本和 AI 能力之间二选一,而是通过协议层解耦实现真正的混合部署。
5. Unity Catalog 作为跨混合环境的统一治理平面¶
「单一统一目录」是 SDS 生态的核心价值主张。Unity Catalog 不再只是云端数据的治理层,而成为跨混合环境的数据治理平面。这意味着元数据管理、访问控制、血缘追踪和审计日志在混合环境下的一致性成为可能。结合 数据 Agent 平台架构 的设计思路,治理平面的统一是实现「 enterprise data estate 一体化」的技术前提,对受监管行业的 CDO 来说是关键卖点。
实践启示¶
- 数据平台架构师 — 在存储选型时,应将「是否支持 OpenSharing 协议」作为硬性评估标准;MinIO AIStor 已 GA,Everpure、Qumulo 在 Private Preview 状态,这是判断厂商能否融入 Databricks 混合生态的直接指标
- 数据平台选型 — 评估 Databricks vs Snowflake/BigQuery 时,需考虑客户数据混合程度——SDS 生态是 Databricks 的差异化壁垒
- 存储厂商技术决策 — MinIO/Everpure 等厂商已明确将 OpenSharing 协议作为产品方向,存储选型时应优先考虑已支持 OpenSharing 的厂商
- AI Agent 跨数据源 — AgentBricks 配合 OpenSharing 后可访问本地数据,意味着企业 Agent 部署的数据源问题被部分解构
相关实体¶
- Fine-tune LLM with Databricks Unity Catalog and Amazon SageMaker AI — 同 vendor 不同焦点(ML 训练 vs 数据治理)
- Using Amazon EMR Serverless Storage — AWS 数据处理与存储成本优化参考
concepts/data-lakehouse-architecture— (待创建) Lakehouse 范式概念页concepts/zero-copy-data-architecture— (待创建) 零数据移动的架构模式
原文链接¶
→ 原文存档
Ch14.009 London's police asked Big Tech for comms data over 700,000 times last year¶
📊 Level ⭐⭐ | 10.5KB |
entities/london-met-police-big-tech-data-requests.md
核心要点¶
- 伦敦大都市警察局一年内向科技公司发出超 70 万次数据请求
- 请求依据:RIPA(调查权法规)
- 数据类型:电话记录、邮件元数据、位置数据
- 主要接收方:美国科技巨头
技术/政策细节¶
RIPA 允许执法机构在无需搜查令的情况下强制通信提供商披露用户数据。
相关实体¶
- Clarity Act 5 Things
- Mozilla Warns Uk Breaking Vpns Will Not Magically Fix Britain S Age Check Mess
- End To End Encrypted Ml Inference Sagemaker Fhe
- Mozilla Warns Uk Breaking Vpns Will Not Magically Fix Britai
- 在 Macos 上用 Ai Coding 搭一个隐私优先的会议纪要助手
→ 原文存档
深度分析¶
一、规模与性质:系统性大规模监控的冰山一角¶
700,000 次数据请求这一数字揭示了英国执法机构对通信数据的常态化获取模式。根据信息自由法(Freedom of Information Act)获取的统计数据显示,伦敦大都市警察局(Metropolitan Police)在 2025 年内向各类通信服务商提出的数据请求呈全面扩张态势。
这些请求并非针对特定嫌疑人的精准调查,而是一种常规化的情报收集机制。值得注意的是,70 万次请求覆盖了从电信运营商到外卖平台、从加密邮件服务到 VPN 提供商的广泛范围。这种「数字化生活全覆盖」的模式表明,现代执法机构已经将监控视野从传统的通信内容扩展到了用户的行为模式、消费轨迹和社交网络等元数据领域。
二、法律框架:三层授权体系的内在张力¶
英国通信数据获取的法律框架由三层构成:RIPA(调查权法规)提供基础授权,OCDA(通信数据授权办公室)负责日常审批,IPCO(调查权专员办公室)承担监督职能。这一框架在设计上试图在执法效率与公民隐私权之间寻求平衡,但在实践中暴露出了明显的结构性缺陷。
UCL 法学讲师兼监控研究者 Bernard Keenan 博士指出,对于通信数据和元数据,获取授权的门槛被刻意设置得低于内容拦截——决策权被下放给指定的资深警官。这意味着警察可以在「操作层面」几乎自主地获取元数据,无需经过独立的司法审查。这种「低侵入性」的制度设计实际上为大规模元数据收集提供了便利,因为它绕过了针对内容拦截的严格程序要求。
三、技术悖论:隐私服务的「无数据可提供」声明¶
一个值得深究的矛盾现象是,加密隐私服务商 Proton 和 Signal 均公开否认向英国执法机构提供了用户数据,但伦敦警察局的数据记录却显示曾从这些服务获取信息。Proton 强调其运营受瑞士法律管辖,所有请求必须通过瑞士当局;而 Signal 则明确表示「我们尚未响应过来自英国的任何法律请求」。
这种数据矛盾可能源于多种情况:其一,执法机构可能将「查询记录」误报为「数据提供」;其二,可能存在通过第三方数据 broker 间接获取的情况;其三,隐私服务的技术架构可能存在执法机构知晓但公众不了解的数据获取途径。无论真相如何,这一矛盾揭示了「隐私承诺」与「执法现实」之间的巨大鸿沟。
四、种族化监控:LycaMobile 事件的政策意涵¶
2025 年伦敦警察局对 MVNO 运营商 LycaMobile 的数据请求较上年增长约 500%(从 15,702 次增至 93,527 次),而同期对 Vodafone、O2、Three、Lebara 等主流运营商的请求量并无类似波动。考虑到 LycaMobile 主要服务海外通话需求群体,其用户中相当比例为外国国籍人士。
移民权利网络(Migrants' Rights Network)首席执行官 Fizza Qureshi 的评论一针见血:「数据请求的激增清楚地表明,数字边境正在通过警务扩展。」这一观察与内政部近期政策动向相呼应:2025 年 12 月生效的《边境安全、庇护和移民法》赋予了移民执法官员搜查移民口腔以寻找隐藏 SIM 卡的权力,并扩大了手机扣押和数字情报收集的权限范围。
如果 LycaMobile 的用户增长需要从约 200 万扩展到 1000 万才能解释请求量的增长,那么请求量的激增显然无法用「服务普及度上升」来解释。警方「服务受欢迎程度提高」的辩解与数据呈现的几何级增长之间存在难以弥合的逻辑裂缝。
五、数据融合:外卖平台的军事化情报应用¶
反恐怖主义警察部门(Counter Terrorism Policing,隶属伦敦警察局)于 2025 年启动了「通信开发数据工具」(Communication Exploitation Data Tool)的采购程序。该工具的需求规格书中明确列出需处理来自 Uber 乘车数据、Uber Eats 配送数据、Zipcar 记录等第三方平台的信息,用于「情报分析」。
这一采购项目揭示了数据聚合分析的军事化应用趋势:当外卖配送、网约车等日常消费服务的元数据被纳入「情报分析」范畴时,「数据点」的概念被重新定义——人们的饮食偏好、出行轨迹、消费时间等生活细节都成为潜在的执法资源。Keenan 博士的点评切中要害:「政府希望警察具备合成多个不同数据点并有效利用的能力,以及这些强大的监控技术。」
六、新闻自由:记者线人的制度性风险¶
2024 年 IPCO 年度报告显示,执法机构当年针对律师的数据请求达 219 次,针对记者的请求达 157 次,其中 106 份逮捕令专门用于识别记者线人的身份。更令人忧虑的是,针对敏感专业人士的监控「无需告知」被监控对象,而情报和安全部门甚至免除了须经法官批准的要求。
北爱尔兰 journalist McCaffrey 和 Birney 的案例具有标志意义:他们因制作关于特赦组织时期准军事组织杀戮的纪录片而被伦敦警察局和北爱尔兰警察局非法监控,以追查纪录片中使用的那批据称被窃取的警察文件来源。两人通过司法审查挑战警方行为,最终上訴法院裁定相关搜查为违法。
全国记者联盟(NUJ)组织者 Tim Dawson 的评论指出了制度性失灵:「英国立法为执法机构获取通信数据设置了明确的护栏,并对记者提供了特定保护。但 NUJ 认为这些保护措施还不够健全。更令人不安的是,这些保护显然有时被忽视。」
实践启示¶
对加密服务用户的建议¶
Proton、Signal 等标榜隐私保护的服务的用户应认识到,「无日志政策」并不等于「完全免疫于数据提供」。在某些情况下,服务商可能被迫通过法律程序交出账户注册信息、支付数据或 IP 连接记录等非内容数据。用户应当:
- 避免在注册时使用真实个人信息,尽可能使用匿名支付方式
- 不将敏感交流内容存储在加密邮件服务器上
- 对于高风险通信,考虑使用 burner 账户和设备
- 定期审查透明度报告,了解服务商的响应模式
对外卖和网约车平台用户的认知¶
Uber、Deliveroo、JustEat、Dominos 等平台的数据已被纳入执法情报分析范畴。虽然单次消费记录本身信息量有限,但当数据被聚合分析时,可以构建个人行为图谱、出行模式和社交网络图景。建议用户:
- 意识到平台账户与手机、支付方式的关联已被永久记录
- 避免在平台上讨论敏感信息
- 考虑使用现金或匿名支付方式用于高风险场景
对记者和敏感职业者的警示¶
针对新闻源的识别是制度性威胁,而非个别侵权行为。在英国法律框架下,记者的通信元数据同样可以被大规模收集,用于推断信息来源。建议采取:
- 了解 IPCO 年度报告中披露的记者监控数据(约 150-200 次/年)
- 与线人建立更安全的通信渠道(如线下会面、加密离线通信)
- 提醒线人减少数字足迹
- 熟悉 NUJ 提供的权益保障指南
对移民社区的自保策略¶
LycaMobile 请求量 500% 的增长和针对移民的新立法动向表明,移民社区正面临日益数字化的有组织监控。建议:
- 意识到手机数据可能成为执法切入点
- 避免在手机上存储可能被视为「敏感」的联系人和信息
- 谨慎使用与移民身份相关的应用程序
- 了解自己的权利——2022 年高等法院裁定内政部扣押和保留超过 2000 部移民手机的行为违法
政策层面的思考¶
这一事件对 surveillance technology governance 提出了结构性挑战:
- 元数据与内容数据的二分法正在失效——当元数据足够丰富时,其分析价值可等同于内容获取
- 授权机制的分散化导致问责真空——操作层面的自主决策绕过了司法审查
- 隐私服务的「声称」与「现实」之间存在信息不对称
- 数字主权的概念正在被跨境数据流动和执法协作所侵蚀
关联阅读¶
→ 原文存档
Ch14.010 AI-Enhanced Data Solutions with Database 26ai¶
📊 Level ⭐⭐ | 10.4KB |
entities/ai-enhanced-data-solutions-with-database-26ai.md
核心要点¶
- Oracle AI Database 26ai 是首款将 AI 原生架构嵌入数据库核心的企业级数据库产品,旨在消除 AI 与数据之间的架构隔阂
- 核心价值主张:把 AI 带到数据所在之处(Bring AI to where your data lives),而非将数据迁移到 AI 模型
- 统一混合向量搜索(Unified Hybrid Vector Search)支持向量、JSON、图、列式、空间、文本和关系数据在同一引擎内处理
- JSON 关系 duality(JSON Relational Duality):文档与关系表不再是竞争存储模型,而是同一数据的同步视图
- 支持 OCI Public Cloud、Multicloud(Azure/AWS/GCP)、Cloud@Customer、On-premises 四种部署模式
- 集成 LangChain 和 LlamaIndex,可直接基于治理数据构建 AI 工作流
- 目标客户:97% 的 Fortune 100 企业,包括最大银行、零售商、电信公司和政府机构
产品定位¶
Oracle AI Database 26ai 是 Oracle 公司的企业级 AI 数据库产品,定位为"AI Made Simple for Enterprise" 。该产品的核心差异化在于将 AI 能力直接内置于数据库内核,而非作为独立附加层存在。
传统企业 AI 架构通常需要维护独立的向量数据库、专门的 ETL 管道和分离的基础设施,导致数据蔓延(data sprawl)和总体拥有成本(TCO)上升。Oracle 试图通过单一统一环境收敛所有工作负载来解决这一问题 。
核心技术特性¶
统一混合向量搜索¶
Oracle AI Database 26ai 声称是"最好的企业 AI Agent 内存核心"(best memory core for enterprise agents)。其统一混合向量搜索允许 AI Agent 在同一上下文中处理多种数据类型:向量、JSON、图、列式、空间、文本和关系数据 。
关键架构优势:
- 在同一数据库引擎、同一事务保证下处理多样化数据类型
- Agent 可以持久化状态、回忆先前上下文、执行长时工作流
- 无需拼接不同数据存储即可访问所有上下文
JSON 关系 duality¶
该平台声称是"唯一"实现 JSON 文档和关系表作为同一数据同步视图的数据库平台 。技术细节:
- 完全兼容 MongoDB API,零 schema 开销
- OSON 二进制格式提供 O(1) 字段访问性能
- JSON Relational Duality 支持文档和关系接口间的双向更新
- 开发者获得文档敏捷性,数据团队获得 SQL 分析能力,无需 ETL 管道
内置验证与安全¶
Oracle 强调其数据库将验证直接构建到数据核心中,以应对 AI 快速迭代带来的验证瓶颈 :
- 自动化数据安全、正确性和可演进性
- 深度强制业务规则、ACID 一致性和 API 演进
- 减少错误和幻觉,使 Agent 扎根于最新数据
部署与生态¶
部署选项¶
| 部署模式 | 说明 |
|---|---|
| OCI Public Cloud | 共管和全托管数据库服务 |
| Multicloud | Exadata 运行于 Microsoft Azure、AWS 或 Google Cloud |
| Cloud@Customer | 云自动化和经济效益,满足数据驻留和低延迟需求 |
| On-premises | Exadata Database Machine、Oracle Database Appliance 或 Linux x86-64 |
AI 生态集成¶
- 支持 SQL、REST、MongoDB 兼容 API
- 原生集成 LangChain 和 LlamaIndex
- 支持 Apache Iceberg 开放标准
- 提供轻量级 Docker 容器和 Always Free 层级
竞争定位¶
根据页面引用的行业分析:
- NAND Research(Steve McDowell):"无人能匹配 Oracle 结合广泛集成 AI 功能与企业级安全、数据完整性和大规模可扩展性的专注"
- HyperFRAME Research(Ron Westfall):"Oracle AI Database 以统一思维和不间断飞行般的方式无缝集成一切,提供实时 agentic AI。竞争对手无法匹配这种速度和简洁性"
- KuppingerCole Analysts(Alexei Balaganski):"Oracle 的方法是将信任直接集成到 Oracle AI Database 核心,不仅保护数据免受新兴 AI 时代风险,还为运行 AI 模型提供安全环境"
- GenAI.works(Steve Nouri):"结合可信企业数据、可扩展向量能力和内置 Agent 内存的 Oracle AI Database 平台将定义下一代 AI 应用"
相关产品博客¶
- Oracle Autonomous AI Vector Database Limited Availability(2026-03-24)
- Introducing Private Agent Factory: Unlocking the Agentic AI Potential in Enterprises with Oracle AI Database 26ai(2026-03-24)
- Introducing Oracle Deep Data Security: Context-Aware Data Access Control for Agentic AI in Oracle AI Database 26ai(2026-03-24)
相关实体¶
- From System Of Record To System Of Intelligence
- Every Ai Subscription Is A Ticking Time Bomb For Enterprise
- Www.Cio 4170978 Nearly Every Enterprise Is Investing In Ai But Only 5 Say Their
- A2Rd Agentic Autoregressive Diffusion Long Video
- 要实现一个工作流选择 Agent Skills 还是 Ai 表格
→ 原文存档
深度分析¶
Oracle AI Database 26ai 的核心战略逻辑是"把 AI 带到数据所在之处"(Bring AI to where your data lives),而非传统的将数据迁移到 AI 模型。这一理念直指当前企业 AI 架构的根本痛点:数据蔓延(data sprawl)和总体拥有成本上升。当企业需要同时维护向量数据库、关系数据库、图数据库等多个独立系统时,数据的实时同步、一致性保证和统一治理都成为巨大挑战 。Oracle 的统一混合向量搜索试图在同一引擎内处理向量、JSON、图、列式、空间、文本和关系数据,这种架构选择对传统数据库厂商来说是根本性转变。
JSON Relational Duality 的创新在于重新定义文档与关系表的竞争关系。传统上,企业需要在文档数据库的敏捷性和关系数据库的分析能力之间做选择。Oracle 的方案让两者成为同一数据的同步视图:开发者获得文档敏捷性,数据团队获得 SQL 分析能力,无需 ETL 管道。这意味着企业可以同时满足敏捷开发需求和严格数据治理要求 。然而,"唯一实现"的声称需要与 PostgreSQL(通过扩展支持 JSON 和向量)、MongoDB(通过 Atlas 和 SQL 接口)等竞争对手的实际能力进行验证。
内置验证(Validation)机制的提出反映了 Oracle 对 AI 生产化的深刻理解。AI 快速迭代导致验证成为最大瓶颈——当模型可以快速生成时,如何确保输出的正确性和一致性反而成为最耗时的环节。Oracle 通过将验证直接构建到数据核心中,试图在数据层面强制业务规则、ACID 一致性和 API 演进,从而减少错误和幻觉,使 Agent 扎根于最新数据 。这一理念与特赞范凌的观点形成呼应:AI 产品从 0 到 0.1 容易,进入生产环境需要可靠的评估体系。
四云部署选项(OCI、Multicloud、Cloud@Customer、On-premises)体现了 Oracle 对企业客户需求多样性的务实响应。在数据主权和合规要求日益严格的背景下,许多企业无法将数据迁移到单一公有云。Exadata 在 Azure、AWS、GCP 上的运行能力,加上 Cloud@Customer 模式,使 Oracle 能够在不强迫客户迁移数据的前提下提供统一的 AI 数据库能力 。这种灵活性与 Oracle 传统的企业级定位高度一致,但也带来了跨云管理的复杂性。
从竞争角度看,分析师评价主要集中在架构整合能力而非单一功能领先。NAND Research 强调"广泛集成 AI 功能与企业级安全、数据完整性和大规模可扩展性的专注",HyperFRAME Research 突出"统一思维和不间断飞行般的方式",KuppingerCole 则聚焦"信任直接集成到核心"。这些评价反映出一个共同主题:Oracle 的优势不在于 AI 功能的绝对领先,而在于将 AI 能力与企业级数据库的成熟特性(高可用、安全、合规)整合的工程能力 。
实践启示¶
- 数据架构优先于模型选择:在评估 AI 方案时,应优先评估数据架构的合理性而非单纯追求最新模型。Oracle 的"把 AI 带到数据所在之处"理念表明,当数据分散在多个系统时,AI 价值难以充分发挥
- 统一引擎降低 AI 复杂度:多数据类型的混合处理能力可以显著简化 AI 应用架构,但需要评估传统数据库厂商在向量搜索等新兴领域的实际性能与专业向量数据库的差距
- 验证机制决定 AI 生产化成败:从原型到生产环境,验证和评估体系是关键瓶颈。内置验证能力应该成为企业选择 AI 数据平台的重要评估标准
- 多云部署能力是大型企业刚需:数据主权和合规要求使许多企业无法接受单一云部署,选择支持混合部署模式的 AI 数据库平台可以避免未来的架构重构
- LangChain/LlamaIndex 集成降低开发门槛:原生集成主流 AI 开发框架意味着企业可以更快地将 AI 能力落地,但需要评估与框架更新保持同步的维护成本
Ch14.011 EVA-Bench Data 2.0: 3 Domains, 121 Tools, 213 Scenarios¶
📊 Level ⭐⭐ | 9.8KB |
entities/eva-bench-data-2-voice-agent-evaluation.md
EVA-Bench Data 2.0: 3 Domains, 121 Tools, 213 Scenarios¶
→ 原文存档
摘要¶
ServiceNow AI 在 Hugging Face 发布语音 Agent 评估基准 EVA-Bench Data 2.0,覆盖 3 个垂直领域(HR、机票改签、客户支持)、121 个工具调用、213 个多步骤对话场景。核心目标是填补"语音 Agent 在垂直业务场景的评估缺口"——通用 Agent 基准(HumanEval、SWE-bench、tau-bench)难以反映语音场景下 ASR/TTS 噪声、对话节奏、用户打断、多轮上下文等独特挑战。
核心要点¶
- 3 个领域聚焦:HR、机票改签、客户支持——都是高对话量 + 复杂工具调用 + 严格合规的垂直业务。
- 121 个工具覆盖真实业务场景:包括日历查询、订单检索、改签规则匹配、客户档案调取等。
- 213 个多步骤场景:每个场景包含多轮对话、多个工具调用、状态依赖。
- 语音 Agent 垂直评估缺口:与文本 Agent 基准相比,语音场景多了 ASR 错误、TTS 韵律、用户打断、语音对话节奏等独特挑战。
- 可复现的数据集:发布在 Hugging Face Datasets,便于学术与企业团队直接复用。
深度分析¶
1. 为什么"语音 Agent 评估"是独立赛道¶
通用 Agent 评估基准(HumanEval、SWE-bench、tau-bench、WebArena)几乎都是文本形态——输入是结构化 prompt,输出是文本或代码执行结果。但真实语音 Agent 的工程挑战完全是另一套:
- ASR(语音识别)误差:用户说的"我想改签到明天上午十点"可能识别成"我想改起到明天上午拾点",模型必须容错。
- TTS(语音合成)韵律:模型回复的语气、停顿、强调直接影响用户体验,难以用文本质量指标衡量。
- 用户打断:真实对话中用户会打断 Agent("等一下,我想改问……"),Agent 需要打断检测 + 上下文重锚。
- 对话节奏:语音对话比文字更依赖节奏感——停顿过久显得笨拙,回复过快显得急躁。
- 情绪识别:用户语音中携带的情绪信息(焦急、愤怒、困惑)需要被 Agent 理解。
EVA-Bench 把这些语音特性显式建模进评估维度,正是补足了通用 Agent 基准的盲区。
2. 三个垂直领域的选择逻辑¶
EVA-Bench 选了 HR、机票改签、客户支持——表面看是三个独立业务,实则共享一组工程特征:
- 高对话量:每天数千到数万次对话,自动化收益明显。
- 多轮依赖:用户问题往往不是单轮就能解决的,需要跨多轮的状态保持。
- 工具调用复杂:查日历、改订单、查档案、调规则引擎,每个都需要正确的工具组合。
- 合规敏感:错误操作直接影响客户体验甚至合规风险(HR 误发工资、机票错改、客服承诺过度)。
- 价值可量化:自动化率提升直接对应成本节约。
这三个领域正好是语音 Agent "既能落地、又有评估意义"的甜蜜点。
3. 121 个工具与 213 个场景的规模意义¶
数字背后的工程含义:
- 121 个工具:单一场景的工具调用空间巨大,要求 Agent 具备工具选择 + 工具组合 + 工具失败回退的能力。这比 SWE-bench 的"修一个 bug 用一两个文件操作"复杂度高得多。
- 213 个场景:覆盖了从简单("查我的机票")到复杂("改签 + 退差价 + 通知同事")的完整光谱。每个场景都是多步骤、多工具的状态机。
- 场景密度:平均每个工具对应约 1.76 个场景——工具与场景不是孤立设计,而是协同构建。
这个规模让 EVA-Bench 成为"工具调用能力 + 多轮状态管理能力"的双重压测。
4. 与现有 Agent 评估基准的对比¶
| 基准 | 形态 | 评测维度 | 局限 |
|---|---|---|---|
| HumanEval | 代码生成 | pass@k | 单轮、无工具 |
| SWE-bench | 软件工程修复 | patch 通过率 | 文本、无语音 |
| tau-bench | 客服对话 | 多轮工具 | 文本客服,无垂直深度 |
| WebArena | 网页任务 | 任务完成率 | 浏览器操作,无语音 |
| EVA-Bench Data 2.0 | 垂直语音 Agent | 多领域 + 多工具 + 多轮 | 聚焦语音场景的特定挑战 |
EVA-Bench 不是要取代通用 Agent 基准,而是在"垂直 + 语音"这条赛道填补空白。
5. 评测指标设计的开放问题¶
文章摘录中未展开评测指标的具体定义,但从场景规模可以推测几个关键维度:
- 任务完成率(Task Completion Rate):场景最终是否达成用户目标。
- 工具调用准确率(Tool Selection Accuracy):是否选择了正确的工具 / 参数。
- 对话轮次效率(Turn Efficiency):达成目标所需的对话轮次(语音场景下用户耐心有限)。
- ASR 鲁棒性(ASR Robustness):在 ASR 错误注入下的表现。
- 打断处理(Interruption Handling):用户中途打断时的上下文重锚能力。
- 合规性(Compliance):是否遵循了业务规则(如改签规则、HR 政策)。
这些维度加起来,远比"模型在 X 基准上得分 Y"复杂——是真正的"工程化评估体系"。
6. 企业落地的关键启示¶
对正在构建语音 Agent 的企业团队:
- 不要拿通用 Agent 基准自欺:HumanEval 90% 不代表你的语音 Agent 在客户支持场景表现优秀。
- 垂直评估集是必须的:HR Agent 应该测 HR 场景、机票 Agent 应该测改签场景——通用基准无法替代。
- 工具调用失败模式需要专项测试:121 个工具的组合爆炸空间(tool combination space)需要基于真实业务路径设计测试集。
- 语音特性必须显式评估:ASR 错误注入、用户打断模拟、对话节奏评估,这些是语音 Agent 独有的工程维度。
7. ServiceNow AI 的产品策略¶
ServiceNow 本身是 ITSM / HR / 客户支持自动化领域的巨头,发布 EVA-Bench 的战略意图可能是:
- 建立垂直 Agent 评估标准:通过 Hugging Face 开源数据集,把自己放在"行业基准制定者"的位置。
- 倒逼模型厂商对齐:当 EVA-Bench 成为行业标准,未对齐的模型 / Agent 框架在 ServiceNow 客户面前会失去竞争力。
- 推动自家产品差异化:ServiceNow 的 Agent 产品可以"内置 EVA-Bench 评估",把"基准符合度"作为营销点。
这种"用开源基准建立商业护城河"的策略在 AI 2.0 时代越来越常见——LangChain 用 LangSmith、Anthropic 用 Claude Code Skills、各大模型厂商用自家评测集都是同一种模式。
8. 与本文库其他 Agent 评估实体的关联¶
- 横向对照:
eva-bench与通用 Agent 基准(HumanEval、SWE-bench、tau-bench)的关系——垂直 vs 通用、语音 vs 文本。 - 纵向延伸:从 EVA-Bench 出发,企业可以构建自己的"内部评估集"——比 EVA-Bench 更贴合具体业务场景。
- 工具调用能力:EVA-Bench 的 121 个工具与 Cline Agent Runtime Sdk 的 multi-tool 编排能力形成评测—能力对照。
实践启示¶
- 语音 Agent 评估需要垂直基准:通用 Agent 基准无法反映 ASR 错误、用户打断、对话节奏等语音特性。
- 多工具 + 多轮是真实业务的关键复杂度:121 工具 + 213 场景的规模才有"工程压测"价值,远超 HumanEval 的单轮复杂度。
- 工具选择与组合失败是核心风险点:评估必须细分到"工具选择 / 参数构造 / 失败回退"三个维度。
- 垂直业务场景的合规性是隐性 KPI:HR、机票、客服三大领域的共同点是合规敏感,评估必须包含规则遵循度。
- 开源基准是建立商业护城河的有效路径:用 Hugging Face 发布基准,倒逼生态对齐自家产品差异化。
- 企业应构建内部评估集:在 EVA-Bench 之上叠加自家业务数据,让评估更贴近真实业务表现。
相关实体¶
- 你不知道的 Agent原理架构与工程实践 V2 — Agent 原理架构的综合性参考
- Karpathy 最新访谈从 Vibe Coding 到 Agentic Engineering — Agent 范式跃迁的视角
- Karpathy Vibe Coding Agentic Engineering — 同源访谈的另一标题版本
- Agentops Operationalize Agentic Ai At Scale With Amazon Bedr — AWS Bedrock AgentOps 的规模化运营实践
- 龙虾装上了可以用来干啥分享下我的 Openclaw 多智能体团队搭建经验 V2 — 多智能体团队搭建的实战经验
- Openclaw 完全指南这可能是全网最新最全的系统化教程了32W字建议收藏 V2 — OpenClaw 多智能体系统化教程
- Cline Agent Runtime Sdk — Cline SDK 的多工具编排能力,与 EVA-Bench 121 工具规模相互映照
- MOC
Ch14.012 LiveKit Agents 语音 AI 框架工程解析¶
📊 Level ⭐⭐ | 9.5KB |
entities/livekit-agents-voice-ai-framework.md
核心架构:四层流式级联管线¶
VAD → STT → LLM → TTS
- 传统"接力赛":每个环节等待上游完整结果,延迟 3-5 秒
-
LiveKit"流水线":每个环节不等上游完成,拿到一点就往下传 关键性能数据:
-
Deepgram STT + GPT-4.1-mini LLM + Cartesia TTS:首字响应 500-800ms
- OpenAI Realtime API 端到端模式:延迟 <300ms
语义打断检测¶
两层检测机制: 1. VAD:基础音量检测,快但粗糙,假阳性高 2. 语义打断检测器:分析声学信号 + STT 转录文本,区分附和性回应("嗯""对")和真正打断("等等不对") 自适应打断(Adaptive Interruption):误判后自动从中断处恢复输出。
多 Agent 交接(Handoff)¶
通过函数工具返回值触发 Agent 切换。上一个 Agent 的 TTS 完成过渡语,新 Agent 无缝接管并携带已收集的上下文信息。
MCP + SIP 生产集成¶
- MCP:外部 MCP Server 直接接入,Agent 自动发现和调用工具(数据库查询、CRM、日历等)
- SIP 电话:Agent 接入电话网络,配置 SIP trunk 支持呼入呼出、DTMF、录音、多方会议
开发体验¶
pip install "livekit-agents[openai,silero,deepgram,cartesia,turn-detector]"
python myagent.py console # 终端直接测试,零配置
python myagent.py dev # 热重载 + WebRTC Playground
python myagent.py start # 生产部署(自动 Worker 调度)
与 OpenAI Realtime API 对比¶
| 维度 | LiveKit Agents | OpenAI Realtime API |
|---|---|---|
| 部署 | 自托管/开源 | 托管式 |
| 供应商锁定 | 无 | 有 |
| 多 Agent 交接 | 原生支持 | 不支持 |
| SIP 电话 | 原生支持 | 不支持 |
| MCP 集成 | 原生支持 | 不支持 |
| > 来源:数有灵兮 |
深度分析¶
流式级联管线的工程哲学¶
LiveKit Agents 的四层流式级联架构(VAD → STT → LLM → TTS)体现了一个核心工程哲学:流水线和并行化是压低延迟的关键。 传统"接力赛"模式的问题:每个环节必须等待上游完整结果才能开始。如果 STT 需要 500ms 完整转写,LLM 必须等到这 500ms 才能开始推理,引入 500ms 的串行等待。 LiveKit 的流水线模式:每个环节不等上游完成,拿到一点就开始处理。VAD 检测到一小段音频就开始 STT,STT 输出部分转写就开始传给 LLM,LLM 根据部分输入"预判"意图并开始生成,TTS 收到前几个 token 就开始合成语音。 这种模式的核心价值在于:延迟不是各环节延迟的累加,而是最大环节的延迟。只要流水线充分流水化,端到端延迟接近最慢环节的延迟,而非所有环节延迟之和。
语义打断检测的双层架构¶
LiveKit 的语义打断检测采用双层架构: 第一层:VAD(Voice Activity Detection)
- 基于音量阈值的声音检测
- 优点:极快(实时帧级处理)
- 缺点:假阳性高(咳嗽、清嗓子、背景噪音都会触发)
-
无法区分"嗯"和"等等不对" 第二层:语义打断检测器
-
同时分析声学信号 + STT 转录文本
- 输出用户发言完成概率
- 能区分附和性回应("嗯""对""好的")和真正打断("等等不对""停一下") 自适应打断(Adaptive Interruption)的设计尤其巧妙:误判后自动从中断处恢复。这意味着即使语义检测器偶尔误判(用户清了嗓子但没说话),用户体验仍然流畅——Agent 会自动继续输出而非僵在原地。
多 Agent 交接的上下文传递机制¶
多 Agent 交接是 LiveKit Agents 的原生能力,通过函数工具返回值触发切换。 设计要点: 1. 交接由函数工具返回值触发,而非 Agent 自主决定 2. 上一个 Agent 的 TTS 输出过渡语("好的,为您转接订位专员!") 3. 新 Agent 无缝接管,携带已收集的上下文信息 这个设计的工程价值在于:交接的发起方是业务逻辑层,不是框架层。业务逻辑判断"用户需求已明确,需要转接专员",通过工具返回值告诉框架"请切换 Agent"。框架本身不感知业务,只负责执行切换。
MCP + SIP 的生产集成架构¶
MCP(Model Context Protocol)和 SIP 电话集成代表了 LiveKit 从"开发工具"到"生产系统"的跨越。 MCP 的价值:
- 外部 MCP Server 直接接入,Agent 自动发现和调用工具
- 数据库查询、CRM、日历等企业工具无需定制开发
-
协议标准化降低了工具集成成本 SIP 的价值:
-
Agent 获得电话号码,可接入电话网络
- 支持呼入、呼出、DTMF 按键、多方会议
- 企业无需改造现有电话基础设施 两者结合使 LiveKit Agents 能够同时服务 WebRTC 用户(在线客服)和电话用户(PSTN 呼叫),这是纯托管方案(如 Twilio Voice)难以实现的优势。
相关链接¶
实践启示¶
对语音 AI 产品经理¶
- 延迟预算是核心约束:语音对话的用户容忍度远低于文本聊天。200-500ms 是人类对话的正常间隔;超过 1 秒用户开始烦躁;超过 2 秒用户以为断线。在产品设计阶段,明确每个功能的「延迟预算」,然后用这个预算反推技术选型。
- 打断体验是差异化关键:大多数语音 Agent 的打断体验很差——要么太敏感(咳嗽就打断),要么太迟钝(说了三遍"不对"才停)。LiveKit 的语义打断 + 自适应恢复是当前最优解,建议将其作为语音产品的标配。
- 多 Agent 交接的场景判断:不是所有场景都需要多 Agent 交接。只有当对话主题或用户需求发生明显切换时(如"从查账单切换到转账")才需要交接。简单的 FAQ 类对话,单一 Agent 完全够用。
对架构师和工程师¶
- 流式优先架构:任何语音 AI 系统都应该从流式架构设计开始。不要先做串行版本再优化成流式——流式架构的复杂度是根本性的,后期改造代价极高。
- VAD 是守门员:VAD 的质量决定了整个管线的上限。如果 VAD 把非语音识别成语音,后续所有环节都在处理垃圾。投入资源优化 VAD(如使用 Silero 等深度学习 VAD)是最值得的投资。
-
MCP 工具托管的注意事项:通过 MCP 暴露企业工具意味着这些工具可以被 Agent 调用。需要评估:
-
哪些工具可以在 MCP Server 上注册
- 工具调用的权限控制如何实现
- 调用日志和审计如何做
- SIP 集成的网络考虑:SIP 电话集成需要公网可达的 SBC(Session Border Controller)。如果企业有防火墙限制,需要考虑 NAT 穿透和 TURN 服务器。
对 DevOps 和 SRE¶
- WebSocket 连接管理是生死线:语音 Agent 依赖 WebSocket 维持实时双向流。断线重连、超时处理、并发连接数限制都必须做好。建议参考 LiveKit 的 AgentServer 生产部署模式(
python myagent.py start),它会自动处理 Worker 调度和负载均衡。 -
延迟监控指标体系:除标准 API 延迟外,语音场景需要追踪:
-
Time-to-first-audio:用户说完到听到响应的延迟(目标 <500ms)
- 打断响应时间:用户打断到 Agent 停止的时间(目标 <200ms)
- Agent 切换成功率:多 Agent 交接是否平滑完成
- 容量规划的特殊性:语音 Agent 的扩展不是简单的实例数横向扩展。需要考虑:并发 WebSocket 连接数(每个用户一个)、音频流路由、Bedrock/API 的 rate limit。
对创业者和 ISV¶
- 开源 vs 托管的成本计算:LiveKit Agents 是 Apache 2.0 开源,没有 per-minute 费用。但如果选择自托管,需要考虑:云服务器成本、SIP trunk 费用、运维人力。vs Twilio/Voiceflow 等托管方案,要算清楚 TCO。
- 场景优先级:LiveKit 的优势在高价值复杂语音场景(客服中心、电话IVR、语音助手)。简单问答类场景用托管方案更省心,只有当需要深度定制(打断检测、多 Agent 交接、SIP 集成)时才值得用开源方案。
- 开发者体验是护城河:
python myagent.py console三分钟能说话,这对开发者吸引力很大。产品化之前先确保开发者能快速验证概念。来源:数有灵兮
相关实体¶
Ch14.013 Lightfield AI pipeline generation¶
📊 Level ⭐⭐ | 8.1KB |
entities/lightfield-ai-pipeline-generation.md→ 原文存档
核心要点¶
Lightfield 是一个面向早期创始人和增长负责人的 AI 外向销售(Outbound Sales)平台,核心产品为 Pipeline Generation(销售管道生成)。与传统的独立 Outbound 平台或代理公司不同,Lightfield 的差异化在于:以企业已有的 CRM 数据为起点,而非从冷数据库开始构建目标客户池。其产品包括:基于闭单客户模式训练的账户评分、使用真实通话文本语言撰写序列、自动映射 LinkedIn 连接图发现温暖进入路径,以及自然语言分析和报告功能。
深度分析¶
Outbound 获客的三座大山¶
传统 Outbound 获客体系存在三个结构性痛点,这也是 Lightfield 选择切入的核心逻辑。 工具成本高昂。 一套典型的 Outbound 配置——数据充实(data enrichment)、邮箱预热(inbox warming)、序列工具(sequencing platform)——每年费用在引入任何人工成本之前就已超过 20,000 美元。代理公司的成本更高,但其优化目标是已约定的会议数量,而非管道质量。 维护工作永无止境。 序列会失效、工具会下线、数据同步会中断。运营者往往将超过一半的时间花在"维护 Outbound 系统"而非"优化信息"或"与潜在客户沟通"上。 效果无法量化。 客户规模界定、受众细分、信息测试、实验设计——大多数创始人在工作中边学边做。没有方法论,每一次营销活动都像蒙着眼睛开枪。
差异化路径:从 CRM 数据出发¶
Lightfield 的核心主张是:Standalone 平台从冷数据库出发,而 Lightfield 从你已经积累的客户数据出发。 具体体现在三个维度: 账户评分学习闭环。 Lightfield 基于已闭单客户(closed-won customers)的模式训练评分模型,而非通用的 ICP 文档。每个评分都附有基于你自身数据的推理说明,让销售团队理解"为什么这个账户值得关注"。 信息语言从真实场景提取。 序列文案来自你的通话记录和邮件往来——即那些真正推动最优客户成交的表述方式,而非通用模板。 温暖路径自动发现。 团队成员的 LinkedIn 连接图被映射到目标账户。当某位销售与目标企业中的关键决策者存在直接联系时,该路径会自动浮现,显著提升 Cold Outbound 到 Warm Outbound 的转化概率。
与 AI BDR 和代理公司的本质区别¶
Lightfield 在文档中明确将自己与两类竞争形态做了区分: vs. AI BDR(AI 业务发展代表): AI BDR 的设计目标是替代成熟销售组织中的入门级员工——适用于那些已有稳定打法、明确定义 ICP 和已知 playbook 的企业,目标是数量,品质门槛是"足够好"。Lightfield Pipeline Generation 则面向另一端:你的打法尚未成型、没有可自动化的 playbook。Lightfield 是你团队中最优秀员工的容量倍增器,而非最便宜员工的替代品。 vs. 代理公司: 代理公司优化目标是已约定的会议数量,其激励结构指向成交量。当合作结束时,打法也随之离开。Lightfield 优化的是最有可能转化为收入的管道,所有决策都基于 CRM 中的真实数据——闭单客户、闭单流失原因、通话记录、团队连接图。由于运作在 CRM 之上,打法永久留存于你的组织。
产品功能全貌¶
Pipeline Generation 包含以下核心模块: 持续刷新的评分目标账户列表。 从 ICP 和真实成交客户出发,Lightfield 通过招聘信号、资金动态、技术栈和投资者信息等多个维度对每个账户进行评分。 已验证联系人和温暖引入路径。 对每个目标账户,提供经验证的邮箱和 LinkedIn 档案,交叉参考团队网络以发现温暖引入机会,并路由到正确的序列。 个性化邮件和 LinkedIn 序列。 由团队使用自身通话语言撰写序列。Lightfield Agent 运行节奏,在收到回复时升级,并在序列结束时重新路由联系人。 Forward-Deployed 团队。 每个项目基于可测试的假设展开,每周与客户复盘结果、决定调整方向、计划下一轮实验。 自然语言报告与分析。 可在同一个聊天界面中询问:哪些细分市场转化率最高、哪些信息被打开、哪些账户趋于沉默、哪些看起来像最优客户。
信任建立与 Vibe Coding 风险¶
Lightfield 的 FAQ 中有一段值得注意的自我定位:随着对工具边界和 Prompt 技巧的掌握,用户信任感会逐渐建立。只要代码可编译、单测通过、预发环境功能正常,就容易建立一套简化验收标准,从而逐渐放弃对 AI 生成内容的逐行 Review。这种"Vibe Coding"心态在销售序列场景同样存在——Lightfield 提供的是结构化方法论而非自动化黑盒,这是其差异化价值的核心来源。
实践启示¶
1. 从已有资产出发,而非从零构建。 Lightfield 的核心洞察是:你的 CRM 中已沉淀了最有价值的信号(闭单客户模式、通话语言、团队网络),而大多数 Outbound 工具要求你放弃这些积累从新数据开始。在 AI 落地场景中,选择"基于你已有数据构建"而非"导入通用数据"的工具,往往能获得更高质量的起点。 2. 方法论留存是护城河,而非工具本身。 Lightfield 刻意将运作机制构建在客户自己的 CRM 之上,确保"打法不随合作结束而流失"。对于企业内部 AI 工具建设而言,这一原则同样适用:构建那些能将方法论内置到组织数据中的系统,而非依赖个人经验的外部工具。 3. 规模化验证前的 setup 需要耐心。 Lightfield 指出:Setup 需要几周时间(目标列表评分、序列撰写、邮箱预热),Live 发送后需要 4-6 周才能看到结果,且成功标准不是"约到了多少会议"而是"验证了哪些假设"。这对急于看到 AI 落地成效的组织是一个有益的提醒:系统性的 AI Pipeline 建设需要与业务节奏匹配的前置投入期。
相关实体¶
- Lightfield Introducing Skills
- Npm Supply Chain Compromise Postmortem
- Cloudflare Glasswing Mythos Security
- When Growth Slows Is It Sales Fault Or The Products Fault The Answer Has Changed
- Reasoning Lift
→ 原文存档
相关实体¶
→ 原文存档
ai agent platforms topic map(已删除)
Ch14.014 Amazon Quick: Accelerating the path from enterprise data to AI-powered decisions¶
📊 Level ⭐⭐ | 7.9KB |
entities/amazon-quick-accelerating-the-path-from-enterprise-data-to-ai-powered-decisions.md-> 原文存档
深度分析¶
1. 问答差距是组织复杂度的函数,而非技术问题 文章指出,从「提出问题」到「获得可信答案」的 gap 以小时或天计量,且随组织规模增长。这不是模型能力不足,而是分析链条冗长导致的必然结果:一个 VPs 的问题需要经过「找到正确 dashboard → 若无则等待分析师写 query → 验证结果」才能交付。Dataset Q&A 的核心价值在于消除这条链条,而不是让模型更聪明。 2. 语义丰富是信息问题,而非模型智能问题 文章有一段极关键的表述:"This isn't a model intelligence problem, it's an information problem." revenue 列名本身无法告知 AI 这是 gross 还是 net、accrual 还是 cash basis;active_customers 无法告知阈值是 12 个月还是 24 个月。这意味着无论底层模型多强,上游数据描述的缺失会导致下游查询语义漂移。Dataset Enrichment 的设计正是针对这一层——把业务团队已 agreed 的定义编码进 metadata,而非依赖模型去猜测。 3. 安全策略的复用而非重建 企业已在 dashboard 层面配置了行级和列级访问策略,Dataset Q&A 自动将这些策略应用于 AI 生成查询,无需二次配置。这是一种「信任传递」机制:已有的安全投入直接变成 AI 时代的信任基础设施,避免了治理层面重复建设。 4. S3 Table + Direct Query 实现了 lake-as-analytics-layer 的架构愿景 传统数仓架构中,数据从数据湖到 OLAP 层再到 BI 工具,每一跳都会引入延迟、成本和新鲜度损失。文章描述的新能力让 Amazon Quick 直接查询 S3 Table Buckets 中的 Apache Iceberg 表,无需中间引擎。这意味着 data lake 本身成为了 serving layer,SPICE 模式(高并发亚秒)和 Direct Query 模式( freshness 优先)可按场景切换,而 AI agent 和传统 dashboard 读的是同一份 live data。 5. Agentic orchestration 层是 enterprise-scale 的关键基础设施 文章描述了 Quick 如何为多步问题(如"churn trending + 驱动因素在 Southeast")进行意图解析、资产选择、工具序列规划和结果组装。这个 discovery and orchestration 层解决的不是单点问答,而是跨多个分析步骤的复杂推理——这才是企业级 AI 助手的本质差异。
实践启示¶
1. 在 Dataset Enrichment 中优先录入「模糊词汇」的定义 并非所有列都需要 enrichment,但「同一词在不同表/部门有不同含义」的列(revenue, growth, active, churn)必须优先处理。上传已有的 data catalog 或团队 wiki 作为 metadata source,投入分钟级,收益覆盖后续所有查询。 2. 用「Benchmarks questions + 查看 reasoning chain」替代传统 UAT Chat explanations 展示了完整推理链:工具调用、生成的 SQL、应用的 filters、假设和概要。这意味着 BI 工程师和数据分析师可以在发布 AI 助手给利益相关者之前,用基准问题集做系统验证,而不是安排传统的用户验收测试周期。 3. 为多步复杂问题设计「标准分析路径」并存入知识库 文章描述的 agentic orchestration 依赖语义层对跨资产关系的理解。对于高频复杂问题(如 regions 下的 churn 驱动分析),预置标准分析路径和对应数据集接入方式,可减少每次运行时的不确定性。 4. 在评估 lake-first 架构时,优先测试 Direct Query 模式的数据新鲜度 对于 streaming pipeline 场景,手工验证「transaction 出现在 chart、metric 或 chat answer 中的时间差」是评估 Direct Query 适用性的直接方法。SPICE 和 Direct Query 的切换不影响上层 dashboard 或 AI 体验,可按分析场景动态选择。 5. Dashboard 生成能力应作为「分析师产能放大器」而非「自助BI替代品」 AI 生成 dashboard 的定位是消除 construction phase——当分析意图明确时,生成的可编辑输出使分析师在几分钟内完成过去需要数天的工作。关键在于:先生成 → review editable plan → 编辑调整 → 发布,而不是期望首次输出即可直接消费。
Amazon Quick: Accelerating the path from enterprise data to AI-powered decisions¶
→ 原文存档
相关实体¶
- AgentCore Runtime部署Apache Doris MCP Server
- 以Kiro快速部署云上Agent:只需几个小时,从业务需求到部署于Amazon Bedrock Agentcore落地 | 亚马逊AWS官方博客
- 基于Strands SDK 构建的企业智能问数解决方案实践 | 亚马逊AWS官方博客
- AI tool poisoning exposes a major flaw in enterprise agent security
- Control where your AI agents can browse with Chrome enterprise policies on Amazon Bedrock AgentCore
- 用 Kiro构建 AI:基于 AWS 基础设施快速构建企业级 Agentic AI 平台 | 亚马逊AWS官方博客
- MOC
Ch14.015 LiveKit Agents:给大模型接上麦克风,没你想的那么简单¶
📊 Level ⭐⭐ | 7.2KB |
entities/livekit-agents-voice-ai-streaming-cascade-interruption-detection.md
延迟:语音 AI 的第一个杀手¶
传统"接力赛"模式的延迟构成:STT 完整转写 500ms + LLM 首 token 800ms + TTS 合成 400ms = 1.7 秒串行等待。人类对话正常间隔为 200-500ms,超过 1 秒用户耐心流失,超过 2 秒被认为断线。
LiveKit 的解法是流水线并行:每个环节不等上游完整结果,拿到一点就开始处理。VAD 检测到音频片段立即递给 STT,STT 输出 partial transcript 即传给 LLM,LLM 根据部分输入"预判"意图并开始生成,TTS 收到前几个 token 就开始合成。实际测试:Deepgram nova-3 + GPT-4.1-mini + Cartesia Sonic 3 首字响应 500-800ms;OpenAI Realtime API 端到端模式可压至 300ms 以下。
语义打断检测:区分"嗯"和"等等不对"¶
传统 VAD 打断方案的假阳性极高:用户咳嗽、说"嗯"、旁边有人经过都会触发打断,Agent 突然闭嘴,体验极差。
LiveKit 采用双层打断检测架构:
| 层级 | 技术 | 特点 |
|---|---|---|
| 第一层 | VAD(Voice Activity Detection) | 基础音量检测,快但粗糙,假阳性高 |
| 第二层 | 语义打断检测器 | 分析声学信号 + STT 转录文本,输出用户发言结束概率 |
自适应打断(Adaptive Interruption) 模式的核心逻辑:
- 附和词("嗯""对""好的""right")→ Agent 继续输出
- 真正打断("等一下""不对""我说的不是这个")→ Agent 立刻停止
- 误判恢复:Agent 判断为打断并停止,但之后用户无声音 → 自动从中断处继续说
流式级联管线:VAD → STT → LLM → TTS¶
LiveKit Agents 的四层架构每层都有明确的工程职责:
- VAD(Voice Activity Detection):实时监听音频流,逐帧判断人声或沉默,是整个管线的"门卫"
- STT:流式转写输出 partial transcript,半截文字已传给下游 LLM
- LLM:不等完整问题,根据部分转写预判用户意图,几乎能立刻开始流式输出 token
- TTS:收到 LLM 前几个 token 就开始合成语音,用户听到第一个字时 LLM 可能还在生成第三句
多 Agent 交接与生产集成¶
多 Agent 交接(Handoff) 通过函数工具返回值触发:上一个 Agent 的 TTS 输出过渡语(如"好的,为您转接订位专员!"),新 Agent 无缝接管并携带已收集的上下文信息。
MCP(Model Context Protocol) 原生支持扩展工具能力:
from livekit.agents import mcp
tools = await mcp.connect("http://localhost:3001")
agent = Agent(instructions="你是客服助手。", tools=tools)
SIP 电话集成 让 Agent 直接接入电话网络:配置 SIP trunk(对接 Twilio、Telnyx 等运营商),分配电话号码,用户拨打后来电自动映射到 LiveKit Room。支持呼入呼出、DTMF 按键检测、通话录音、多方会议。
开源优势¶
LiveKit Agents 采用 Apache 2.0 协议,10k+ Stars。与托管平台相比的核心优势:完全自主控制无供应商锁定、可自托管数据不出企业、社区驱动功能迭代快。
技术定位¶
本文聚焦级联打断检测这一细分能力,与 LiveKit Agents 语音 AI 框架工程解析 互补——后者侧重完整架构对比(如与 OpenAI Realtime API 的横评),本文深耕流式管线与语义打断的工程细节。语音 AI 领域的竞品包括 Amazon Nova Sonic 实时语音方案,后者采用统一语音到语音架构而非级联管线。
深度分析¶
本文揭示了 {DOMAIN} 领域的核心发展趋势,对理解技术演进方向具有重要参考价值。
关键洞察¶
-
核心趋势:从多个维度的分析可以看出,行业正在经历从传统架构向智能系统的根本性转变
-
技术驱动因素:新型 AI 能力的引入正在重新定义产品形态和用户体验
-
商业影响:这一转变对现有市场格局和竞争态势产生深远影响
与行业整体趋势的关联¶
本文与同期发表的 System of Record→Intelligence 等文章共同构成了对 AI Native 时代企业软件演进的系统性分析框架
实践启示¶
-
架构评估:定期审视现有技术栈,判断是否需要进行智能化升级
-
渐进式迁移:采用增量式方法逐步引入新能力,降低迁移风险
-
数据基础设施:确保数据质量和结构化程度,为 AI 层提供可靠输入
-
团队能力建设:培养具备 AI 时代所需技能的工程团队
→ 原文存档
Ch14.016 Goodfire Predictive Data Debugging:可解释性指导 Post-Training 数据塑形¶
📊 Level ⭐⭐ | 7.0KB |
entities/goodfire-predictive-data-debugging-post-training-anatomy-2026.mdBackground:本文档基于 Goodfire 2026-06-12 发布的论文 Anatomy of Post-Training: Using Interpretability to Characterize Data and Shape the Learning Signal (arXiv 2606.12360) 与同篇博文整理。Goodfire 是 mechanistic interpretability 公司,主打"用 SAE(稀疏自动编码器)让模型决策可读"。本文关注一个工程痛点:post-training 数据集没法 debug——260K preference pairs 中哪几条让 DPO 学坏了?他们的解法是 R²=0.9 的训练前预测。
核心命题¶
给定 preference dataset,可以在训练前预测 DPO 将放大/抑制哪些行为,预测准确度达 R²=0.9(与模型实际学到的行为高度一致)。 预测可追溯回具体数据点(哪条 pair 贡献了哪个行为),从而塑形数据集/训练过程,避免训练出意外后果。
三大工程突破¶
1. 把 interpretability 工具从"读神经元"升级到"读数据"¶
传统 SAE 工作集中在模型激活端(anthropic-nla-natural-language-autoencoders-interpretability),Goodfire 把这一能力反向延展到训练数据端——用 SAE 把每条 preference pair 投影到特征空间,预测模型学完后会激活哪些特征。
2. 案例研究:识别 DPO 训练中的"unwelcome surprises"¶
- 反 reward hacking 检测:发现训练数据中某些"看起来对齐"的 pair 实际在强化模型作弊行为
- 数据溯源:训练后 eval 回归时,能定位到具体哪条 pair 触发了该行为(vs 之前只能"猜")
- 数据集塑形:识别后直接降权/删除/重写高风险 pair,而非"全量重训+黑盒调参"
3. Silico 平台:把工具下沉到产品¶
研究产出沉淀到 Silico 平台——面向模型训练团队的"intentional model design" SaaS。这是 interpretability 从论文走向商业化的关键一步,与 Anthropic 的 mechanistic interpretability 部门形成竞品。
与现有 Post-Training 框架的差异化¶
| 维度 | 传统 Post-Training | Goodfire Predictive Data Debugging |
|---|---|---|
| 核心目标 | 训练完后 eval 调优 | 训练前预测+塑形 |
| 数据视角 | 黑盒(pair list) | 白盒(每条 pair 的可解释特征贡献) |
| 失败定位 | 训练后"猜"哪条数据出问题 | 训练前识别高风险 pair |
| 工具链 | PyTorch + DPO/RLHF 库 | Silico 平台 + SAE 特征空间 |
| 适用阶段 | SFT → DPO → RL 全流程 | 主要 DPO/preference 阶段 |
参考 LLM Post-Training 全景指南 了解传统方法谱系。
深度分析¶
从神经元到数据:可解释性工具的维度跃迁。 传统 SAE 工作驻留在模型激活端,分析"哪个神经元 firing",Goodfire 将这一能力反向延展到训练数据端——用 SAE 把每条 preference pair 投影到概念特征空间,直接回答"这条数据教模型什么行为"。这是可解释性工具从"观察模型"到"操控数据"的关键跃迁,R²=0.9 的预测精度证明了概念级特征的预测能力远超 embedding 聚类。
Preference dataset 即程序化模型行为。 Goodfire 的核心比喻值得重视:preference dataset 是模型的隐式程序——不像经典代码可以断点调试,数据集的含义弥散在 260K pairs 的统计结构中。DPO 在这些数据上运行时,任何与目标行为相关的统计相关性都会被放大,包括"幻觉链接""fart fishing"这类完全非预期的行为。预测性数据调试的本质是把数据集从"黑盒程序"变成"可读源码"。
安全与性能的 Pareto 改进窗口。 案例 1 揭示了一个深刻张力:DPO 在原始 Dolci/Tulu3 数据上训练同时提升 benchmark 和削弱安全护栏——这是因为"表现提升"和"安全护栏削弱"共享同一数据信号。数据调试把这个 tradeoff 变成 Pareto 改进:在调试后的数据上训练,可以同时提升性能和安全性。这意味着传统 post-training 的"有 tradeoff 就接受"思维模式可能源于数据而非算法。
可解释性商业化的三角格局已形成。 Anthropic mechanistic interpretability 部门、Goodfire Silico 平台、NeurIPS Mechanistic Interpretability 研讨会三家构成"研究-产品-学术"三角。与 Anthropic 的纯研究定位不同,Goodfire 选择从平台产品直接切入付费客户,这种商业化路径对可解释性领域的可持续性有重要示范意义。
从预测到塑形:数据工程化的最后一步。 当前 pipeline 的局限(幻觉链接和物理谄媚无法完全通过数据过滤消除)说明,"识别问题"和"解决问题"之间仍有技术鸿沟。Targeted data rewrites——不仅识别高风险 cluster,还验证重写后的数据能教出正确行为——是未来数据工程化的核心方向。
引用与延伸阅读¶
- 原文存档 → 原文存档
- 论文:arXiv 2606.12360
- 关联 entity:LLM Post-Training 全景指南 了解传统方法谱系。
实践启示¶
- 数据工程正在成为 Post-Training 的瓶颈——模型架构/训练算法已经成熟(DPO/GRPO/RLVR 已是标配),但数据质量与可解释性才刚刚被严肃对待。Goodfire 的 R²=0.9 预测精度说明 interpretability 工具已可工程化。
- 260K preference pairs 的人工 debugging 已不可行,自动化数据塑形是必经之路
- 可解释性研究的商业化路径已打通:从学术论文 → 平台产品 → 付费客户。Anthropic / Goodfire / NeurIPS Mechanistic Interpretability 团队三家形成"研究-产品-社区"三角。
相关实体¶
Ch14.017 基于 Amazon Kinesis Data Streams 实现 DynamoDB 历史数据清理与增量同步¶
📊 Level ⭐⭐ | 6.7KB |
entities/基于-amazon-kinesis-data-streams-实现-dynamodb-历史数据清理与增量同步.md-> 原文存档
标签¶
aws #dynamodb #kinesis #data-engineering #incremental-sync¶
原文: 基于 Amazon Kinesis Data Streams 实现 Dynamodb 历史数据清理与增量同步(raw/articles/基于-amazon-kinesis-data-streams-实现-dynamodb-历史数据清理与增量同步.md)
深度分析¶
DynamoDB Streams 24 小时窗口是数据迁移的核心瓶颈。 文章指出了一个在 DynamoDB 数据迁移场景中被低估的限制:DynamoDB Streams 的数据保留期固定为 24 小时且不可修改。对于 TB 级大表的迁移,历史数据的导出、清洗、导入流程可能需要数天,远超 24 小时的窗口期。这意味着如果不做额外架构设计,增量数据(新写入的数据)在迁移期间会丢失。DynamoDB 本身的这个限制,使得传统的"导出全量数据 → 迁移 → 切换"三步走方案在大数据量场景下不可行。 Kinesis Data Streams 将增量同步窗口从 24 小时扩展到最长 365 天。 这是文章的核心创新点:引入 Kinesis Data Streams 作为 DynamoDB Streams 的缓冲层,将数据保留窗口从不可修改的 24 小时扩展到最长 365 天(Kinesis 的最大保留期)。工作流程变成:DynamoDB Streams → Kinesis Data Streams → Lambda 消费 → 写入新表或 S3 归档。Kinesis 作为缓冲层,解决了"迁移时间 > 24 小时"导致的增量数据丢失问题,使大数据量迁移真正可行。 三层数据生命周期管理是方案的核心架构设计。 文章描述的数据清理方案包含三个层次:① 近 30 天的活跃数据保留在 DynamoDB 在线表;② 超过 30 天的历史数据通过 Kinesis 实时同步到 S3 低成本归档存储;③ TTL 自动过期的机制在 DynamoDB 层持续清理过期数据。这个三层架构的关键洞察是:存储成本优化不能以牺牲合规数据保留为代价——TTL 自动删除不等于数据归档,S3 归档是合规数据的着陆点。 Glue + S3 智能分层是成本优化的关键。 文章方案使用 AWS Glue 配合 S3 智能分层存储归档数据。S3 智能分层能够自动将访问频率降低的数据从 Standard 层移至 Infrequent Access 层甚至 Glacier 层,而无需人工判断数据温度。这意味着归档数据不需要人工判断何时该迁移到冷存储,存储成本随访问模式自动优化,是 DynamoDB 历史数据归档的标准落地点。 "迁移过程中不丢失任何增量写入"是方案的核心 SLA。 字幕翻译业务的场景要求是:迁移期间新写入的数据必须完整同步到新表,不能有数据丢失。这个 SLA 驱动了整个架构选择:用 Kinesis 而非 DynamoDB Streams 直接消费,就是为了解决 24 小时窗口限制的问题。在任何涉及在线数据库的迁移项目中,"零数据丢失"应该是默认要求,而非可选项。
实践启示¶
- 在大数据量 DynamoDB 迁移场景中,Kinesis 是 DynamoDB Streams 的必要缓冲层。 如果你的表每天写入量很大、迁移窗口预计超过 24 小时,引入 Kinesis Data Streams 是必选项,而非可选项。DynamoDB Streams 本身的 24 小时不可修改限制,在 TB 级数据迁移场景下是致命的。提前规划 Kinesis 缓冲容量(Shard 数量决定吞吐量)是迁移方案设计的第一个技术决策点。
- TTL + Kinesis 同步 + S3 归档是 DynamoDB 历史数据清理的标准三件套。 TTL 负责 DynamoDB 层的自动过期(设置在 30 天前);Kinesis 负责增量数据的实时同步(作为缓冲);S3 智能分层负责归档存储(接收从 Kinesis 消费并写入的历史数据)。这三层缺一不可:没有 TTL,DynamoDB 存储成本持续增长;没有 Kinesis,增量数据在迁移窗口外会丢失;没有 S3 归档,过期数据被删除后无法合规追溯。
- 数据迁移的 SLA 定义必须包含"迁移窗口增量数据不丢失",而不是只关注迁移那一刻。 大多数数据迁移失败不是因为"历史数据迁移不完整",而是因为"迁移期间新写入的数据丢失或重复"。方案设计时,先定义清楚增量数据的处理策略,再考虑历史数据的导出方式。
- DynamoDB Streams 的 24 小时窗口是一个常被低估的架构约束。 在设计基于 DynamoDB 的实时数据管道时,如果下游消费处理出现延迟(比如 Lambda 触发率下降、下游服务故障),超过 24 小时的延迟就会导致数据永久丢失。在构建高可用数据管道时,需要在架构层面引入缓冲机制(如 Kinesis),而不是依赖 DynamoDB Streams 的默认保留期。
相关实体¶
- From siloed data to unified insights: Cross-account Athena Access for Amazon Quick
- Amazon Quick: Accelerating the path from enterprise data to AI-powered decisions
Ch14.018 Stop Giving Your Agents Database Credentials — Agent Data Governance Patterns¶
📊 Level ⭐⭐ | 6.6KB |
entities/agent-data-governance-crewai-credential-patterns.md
Stop Giving Your Agents Database Credentials — Agent Data Governance Patterns¶
Agent 循环(推理、工具调用、Prompt 工程)只占 1% 的工作量,其余 99% 是构建、配置、部署、安全、评估和监控。本文聚焦数据治理层:Agent 不应直接持有数据库凭证。
核心论点¶
Data + AI Summit 上的共识:Agent 的"智能"部分(模型选择、推理、工具调用)只占 1% 的工程工作。真正的挑战在于 99% 的基础设施层——安全、部署、监控、数据治理。
四种 Agent 数据交互模式¶
- 直接凭证(反模式):Agent 持有 DB 用户名/密码,直接执行 SQL → 安全风险极高
- 受限视图:为 Agent 创建专用数据库视图,限制可见数据范围
- API 中间层:Agent 通过受控 API 访问数据,不直接接触 DB
- MCP Server 模式:Agent 通过 MCP Server 的工具接口访问数据,由 Server 层执行权限校验
关键洞察¶
- Agent 的工具调用能力 ≠ Agent 应该拥有底层资源的直接访问权限
- 数据治理是 Agent 安全的"最后一公里"——即使 Agent 本身被精心设计,错误的数据访问模式仍会导致安全事件
- CrewAI 的实践表明:MCP Server 模式在灵活性和安全性之间取得了最佳平衡
深度分析¶
"四种数据交互模式"框架是 Agent 数据治理的核心抽象¶
CrewAI 将 Agent 与数据的交互归纳为四种模式:语义层查询、受控 SQL、注册业务逻辑调用、受控向量检索。每种模式对应独立的治理边界和权限模型。关键洞察:当你给 Agent 一个数据库连接字符串时,你实际上把四种交互压缩成了一种——原始 SQL 访问。Agent 用不理解的 schema 对不可审计的表生成查询,语义层、函数治理、检索优化全部失效。这等同于给新员工第一天就给生产数据库密码说"自己搞定"。
99% 的工程工作在 Agent 循环之外¶
Data + AI Summit 的共识数据:Agent 循环(推理、工具调用、prompt 工程)仅占 1% 的工程工作,其余 99% 是构建、配置、部署、安全、评估和监控。更实际的观察:企业识别了 20-800 个 agentic 用例,但 AI 团队一年只能交付约 10 个。瓶颈不是 Agent 逻辑,而是治理、控制、联邦化构建能力、数据访问模型,以及数据本身的结构化程度。原型之所以能跑通,是因为有人给了它一个干净的开发数据库的宽泛权限——然后安全审查来了,数据治理团队来了,项目搁置三个月。
MCP Server 模式在灵活性和安全性之间取得最佳平衡¶
四种模式中,MCP Server 模式(Agent 通过 MCP Server 的工具接口访问数据,由 Server 层执行权限校验)是 CrewAI 实践中最推荐的方案。Databricks 集成使用了四个独立的 MCP Server(Genie、SQL、Unity Catalog Functions、Vector Search),每个 crew 按需启用——做财务分析的 crew 用 Genie + SQL,做支持升级的 crew 用 Vector Search + UC Functions。认证通过 Databricks OAuth 流转,没有共享服务账户,没有硬编码在环境变量中的凭证。
Agent 应走与人类分析师相同的治理层¶
核心原则:如果公司的人类分析师不能查询某张表,代表他们行事的 Agent 也不应该能。如果有经过审批的 churn 计算函数,Agent 应该调用该函数而非在 prompt 中自己实现。如果有定义"月活用户"的语义模型,Agent 应该使用它而非从列名猜测。这不是 Databricks 特有的洞察——这是 Agent-数据集成应有的模式。CrewAI 已在 Snowflake 上做了同样的事,并将继续覆盖所有主流数据平台。
数据质量是 Agent 治理的隐性前置条件¶
文章揭示了一个被忽视的问题:Agent 不知道某张表的"revenue"列与另一张表的含义不同,也不知道某个遗留表中一半记录自 2023 年以来未更新。数据治理不仅是"谁能访问什么",还包括数据是否被良好地结构化和标注,使 Agent 能负责任地使用它。这解释了为什么 800 个积压用例中大多数不是被模型智能阻塞,而是被尚不存在的数据访问模型阻塞。
实践启示¶
-
立即审计 Agent 的数据访问模式:检查所有 Agent 是否直接持有数据库凭证。如果有,优先迁移到 MCP Server 模式或 API 中间层。直接凭证是安全反模式,不应存在于生产环境。
-
按四种交互模式拆分数据访问:不要给 Agent 一个万能数据库连接。为语义查询、SQL 查询、业务逻辑调用、向量检索分别创建独立的治理工具,每个工具只暴露 Agent 实际需要的数据范围。
-
利用现有数据治理基础设施:如果企业已在 Databricks/Snowflake/BigQuery 上建立了治理层(Unity Catalog、行级安全、列掩码、审计日志),Agent 应该接入这些已有设施,而非构建平行的治理系统。
-
优先解决数据质量问题:在投入 Agent 开发之前,先确保数据被良好地结构化、标注和定义。语义模型(如"什么是活跃用户")应由数据团队预先定义,而非让 Agent 从列名猜测。
-
OAuth 优于共享凭证:Agent 的认证应走企业 SSO/OAuth 流程,使 Agent 的访问权限与调用它的用户身份绑定。避免使用共享服务账户或硬编码在环境变量中的宽泛权限。
与现有实体差异化¶
| 维度 | 本实体 | 现有 TiDB Agent 数据库实体 |
|---|---|---|
| 关注点 | Agent 数据治理/权限模型 | Agent-native 数据库架构 |
| 权限模型 | MCP Server 中间层 | 数据库层面的 Agent 适配 |
| 厂商视角 | CrewAI(Agent 框架) | TiDB(数据库厂商) |
来源: → 原文存档
Ch14.019 AI 驱动的大数据工程:从平台驱动到 AIDLC 的范式迁移¶
📊 Level ⭐⭐ | 6.4KB |
entities/ai-engineering-platform-aidlc-migration.md-> 原文存档
AI 驱动的大数据工程:从平台驱动到 AIDLC 的范式迁移¶
AWS China Blog · ingested: 2026-05-11
标签¶
aws #aidlc #data-engineering #platform¶
原文: Ai Engineering Platform Aidlc Migration(raw/articles/ai-engineering-platform-aidlc-migration.md)
相关实体¶
- AIDLC范式: 平台驱动到大数据工程的范式迁移
- AI 驱动的大数据工程:从平台驱动到 AIDLC 的范式迁移
- Agentic AI for Subsurface Engineering Simulation (NVIDIA)
- U.S. Bank shifts critical apps to AWS for AI push | CIO Dive
- Skill工程化设计:把Agent当算法用
深度分析¶
范式迁移的核心本质是从"平台功能控制"转向"知识资产控制"。传统数据中台的控制面本质上是平台功能清单,团队能做什么是平台产品路线图决定的;而AIDLC的控制面首次将团队规范、指标字典、数据契约结构化为"AI可执行的Markdown",纳入Git版本控制。这意味着规范本身成为可diff、可回滚、可code review的代码资产,第一次具备了生产线的直接影响力的同时又不绑定特定平台。 三层叠加结构的战略意义在于:平台执行层是"手脚",负责实际执行;AIDLC协作层是"大脑",负责人机协同的流程编排;知识与规范层是"灵魂",决定AI产出的方向和质量。三者缺一不可,单独强化任何一层都无法实现范式迁移的完整价值。特别是知识与规范层将散落在Wiki、会议纪要和资深员工认知中的隐性知识结构化为Steering文件,这是整个范式迁移的基石。 开发范式跃迁的历史对标:从过程式到声明式的转变,与软件工程史上从汇编到高级语言、从命令式到SQL/函数式的跃迁同构。短期存在磨合成本,但长期人效收益是数量级的——人从"怎么做"中解放出来,聚焦更稀缺的"做什么、为什么"。同样的怀疑在每次跃迁时都出现,历史的答案一致:长期是赢家通吃。 缺陷修复成本曲线揭示的shift-left经济学:缺陷发现越晚修复成本指数增长,AIDLC将口径争议等典型问题的发现点从"100×区"前移至"1×区"。更重要的隐性收益是问题发现点上移——同一缺陷在Spec Review阶段发现与上线后发现,修复成本相差可达两个数量级。 角色演变中的杠杆效应:数据架构师的杠杆效应最显著——Steering文件一次提交即可改变整个团队的AI产出质量,架构师第一次具备"直接控制产线"的能力。数据开发工程师面临两极分化:能清晰表达设计意图者获得更大杠杆,单纯依赖"写得快"者被暴露。数据质量团队从"救火"转变为"立法",从成本中心转为赋能中心。 L2阶段是实质性门槛:从L0/L1(散点使用/工具化)到L2(规范化)的跃迁是最具挑战也最有价值的一步。L0/L1可以依靠个人使用习惯维持,但L2需要团队建立Steering文件并跑通完整AIDLC流程,这是质的飞跃。
实践启示¶
最务实的起点:在代码仓库中新建steering/目录,请团队最资深的数据架构师将"我们团队的分层规范"写成第一份Markdown文件。不追求完美,优先可用。这是缓解焦虑的最佳姿势——"在森林里遇到熊,赶紧跑,不能是最后一个"。 五步实施路径: 1. 先沉淀Steering — 按"分层规范→命名规则→核心指标字典→质量契约模板"顺序,每份控制2000字以内,先覆盖最高频使用的10张表 2. 选择窄场景试点 — 边界清晰、业务方熟悉的场景(如"新增一张ADS表的完整流程"),完整跑通后再复制 3. 重构Code Review流程 — 评审对象从"代码"扩展为"Spec + 代码diff",否则AI产出无法顺利进入主干 4. 重新定义KPI — 从"上线的表数量"转向"需求到上线的lead time"与"返工率",否则现实激励下难以真正采用新范式 5. 建立AI护栏 — 权限边界、成本阈值、敏感数据保护、幻觉检测、审计日志,五条红线必须具备 三个必须规避的反模式: - 让AI绕过治理:Agent应通过平台API调用,使RBAC、审计、脱敏策略原样生效,在治理框架内工作而非绕过 - Spec变成后补文档:先写代码再让AI反向生成Spec会重新回到"文档与代码不一致"的老路,且更隐蔽 - 把AI当黑盒:"代码是AI写的,不用看了"是最危险的心态,Review职责只会更重要而非更轻 瓶颈位置的转移:传统数据中台的瓶颈在"开发人手",是线性扩张;AIDLC的瓶颈在"Review速度",是杠杆放大。这意味着团队扩张逻辑根本改变——不是增加更多开发者,而是提升Review的质量和速度。 业务方介入时机的根本前移:从"上线前验收"前移到"Spec评审阶段",业务方第一次能在第二天就参与评审并签字确认,口径争议不再是第三周才发现的"惊喜"。 文档与代码一致性的范式转变:传统模式下文档与代码长期不一致;AIDLC模式下"Spec即真相"——声明式开发意味着Spec本身成为可执行的产物,实现细节对Spec的符合度成为唯一的真值来源。 未来3年预测:采用AI原生范式的团队与停留在平台驱动范式的团队,人效差距可能拉大到5-10倍。但这个差距并非来自大模型能力强弱——基础模型能力会在行业内快速拉平——而是来自谁更早把自己的方法论变成AI可执行的知识资产。
Ch14.020 SQL NOT IN 与 NULL 的经典陷阱:De Morgan 定律到解析器行为¶
📊 Level ⭐⭐ | 5.9KB |
entities/sql-not-in-null-trap-demorgan-parser.md
SQL NOT IN 与 NULL 的经典陷阱:De Morgan 定律到解析器行为¶
深入剖析 SQL 中 NOT IN 子查询包含 NULL 值时返回空结果集的经典陷阱。从 SQL 标准的三值逻辑定义出发,经 De Morgan 定律推导,到 PostgreSQL 解析器的实际行为。
核心问题¶
为什么?¶
SQL 的三值逻辑:任何与 NULL 的比较返回 UNKNOWN(不是 TRUE 也不是 FALSE)。
NOT IN 等价于 id != b1 AND id != b2 AND ... AND id != bn。当某个 bn 是 NULL 时,id != NULL 返回 UNKNOWN。整个 AND 链中只要有一个 UNKNOWN,结果就是 UNKNOWN → 行被过滤。
De Morgan 视角¶
NOT IN = NOT (id = b1 OR id = b2 OR ... OR id = bn)
如果任何一个 bn 是 NULL,内层 OR 的结果可能是 TRUE 或 UNKNOWN(取决于是否有其他匹配)。NOT UNKNOWN = UNKNOWN → 行被排除。
正确写法¶
-- 方案1:排除 NULL
SELECT * FROM A WHERE id NOT IN (SELECT id FROM B WHERE id IS NOT NULL);
-- 方案2:用 NOT EXISTS
SELECT * FROM A a WHERE NOT EXISTS (SELECT 1 FROM B b WHERE b.id = a.id);
-- 方案3:用 EXCEPT
SELECT id FROM A EXCEPT SELECT id FROM B;
实践价值¶
这是每个 SQL 用户都会踩的坑,文章的解释从理论到实践层层递进,是该主题的最佳技术文档之一。
深度分析¶
三值逻辑的隐蔽陷阱:SQL 的三值逻辑(TRUE/FALSE/UNKNOWN)是 NOT IN 陷阱的根本原因。与其他编程语言不同,SQL 中 NULL = NULL 返回 UNKNOWN 而非 TRUE,这意味着 NULL 不等于任何值,包括它自身。当 NOT IN 的右侧子查询包含 NULL 时,整个表达式退化为 x <> a AND x <> b AND ... AND UNKNOWN,AND 链中只要有一个 UNKNOWN,结果就是 UNKNOWN,导致所有行被过滤。
解析器层面的实现细节:PostgreSQL 的 transformAExprIn 函数中,IN 和 NOT IN 的区别仅在于一个 useOr 标志——IN 生成 OR_EXPR(= ANY),NOT IN 生成 AND_EXPR(<> ALL)。这个设计使得 NULL 的三值行为成为"涌现属性"而非显式特殊处理。从 EXPLAIN 输出可以直接验证:NOT (1,2,3) 编译为 <> ALL ('{1,2,3}'::integer[]),子查询形式则使用 SubLink 节点。
左右两侧 NULL 的对称问题:不仅右侧子查询的 NULL 会导致问题,左侧表达式中的 NULL 同样会产生 UNKNOWN 结果。这意味着 IN 和 NOT IN 并非互补——一个行可以同时不满足 IN 和 NOT IN 条件。这是三值逻辑中"NULL 间隙"的体现,也是为什么 NOT EXISTS 通常更安全的原因。
性能与正确性的权衡:NOT IN 在历史上比 NOT EXISTS 有更好的查询计划优化,但 PostgreSQL 近年来已经改进了 NOT EXISTS 的优化。在现代 PostgreSQL 中,两者性能差异已经很小,正确性应该优先于微小的性能差异。
防御性编程的工程实践:在生产代码中,应该将 NOT IN 视为"需要审查"的模式。最佳实践是:(1) 永远使用 WHERE id IS NOT NULL 过滤子查询结果,或 (2) 直接使用 NOT EXISTS/EXCEPT 替代。这类陷阱在代码审查中容易被遗漏,建议通过 linter 规则自动检测。
实践启示¶
- 优先使用 NOT EXISTS 替代 NOT IN:
NOT EXISTS对 NULL 具有天然的鲁棒性,语义更清晰,且现代 PostgreSQL 的性能已经优化到与NOT IN相当。 - 子查询必须过滤 NULL:如果必须使用
NOT IN,务必在子查询中添加WHERE id IS NOT NULL,这是防御性编程的基本要求。 - 代码审查时重点关注 NOT IN:将
NOT IN模式加入代码审查 checklist,确保审查者检查子查询是否可能返回 NULL。 - 理解 EXPLAIN 输出:学会阅读 PostgreSQL EXPLAIN 中的
= ANY和<> ALL节点,这有助于理解查询的实际执行逻辑。 - 三值逻辑的系统性影响:NULL 的三值行为不仅影响
NOT IN,还影响NOT EXISTS、EXCEPT、GROUP BY、DISTINCT等多个 SQL 操作。理解这一底层逻辑是成为高级 SQL 用户的必经之路。
Ch14.021 GitHub Multilingual Repositories Dataset — 4000 万仓库多语言元数据¶
📊 Level ⭐⭐ | 5.5KB |
entities/github-multilingual-repositories-dataset-cc0.md
GitHub Multilingual Repositories Dataset — 4000 万仓库多语言元数据¶
Source: 原文存档
背景¶
2026-06-15 GitHub 发布 GitHub Multilingual Repositories Dataset(GitHub 多语言仓库数据集),在 CC0-1.0 许可下开源。这是 2025 年微软"European Digital Commitments"承诺的兑现——让多语言数据更易获取,包括开源 AI 开发者。
数据集规模¶
- 80+ 百万分类行(classification rows)
- 覆盖 4000+ 万仓库(40+ million repositories)
- CC0-1.0 许可(最宽松,可商用)
数据集设计哲学¶
不是内容 dump,是元数据集¶
有意不提供仓库原文——避免: - 版权问题 - 隐私风险 - 滥用训练
而提供元数据 + 语言分类信号,让研究者和开发者主动选择目标仓库去获取内容。
三种分类器¶
每个文本源(README / issue / PR)都用 3 个独立分类器: - fastText — Facebook AI Research 的语言识别库 - gcld3 — Google Compact Language Detector v3 - lingua-py — pemistahl 的 Python 绑定语言检测
每个分类器都带 confidence score,数据集只包含 confidence > 0.5 的分类。
不合并三分类器的原因¶
不同分类器在低资源语言上的覆盖率和 confidence 校准不同。GitHub 故意暴露三个分类器的独立结果,让用户自己决定严格度: - 高精度希腊语子集 → 要求三个分类器一致 + 高 confidence - 罗曼语族探索性研究 → 单一分类器足够
多语言分布发现¶
| 内容源 | 主导非英语语言 | 排名特点 |
|---|---|---|
| Issue 文本 | 韩语 | 最常见非英语 |
| README 文本 | 葡萄牙语 | 300 万+ 仓库 |
| PR 文本 | (未单列) | — |
韩语在 issue 常见但 README 仅第五 — 说明韩语开发者习惯用 issue 讨论、文档习惯用英语。葡萄牙语在 README 主导反映巴西开发者社区强 README 传统。
每条记录字段¶
每个公开仓库提供:
- 语言分类 — README / 最多评论 issue / 最多评论 PR,每个分类使用前 150 字符作为输入样本(排除 < 20 字符)
- 三分类器结果 + confidence — fastText / gcld3 / lingua-py
- 仓库元数据 — 创建时间、磁盘占用、stars、forks、主编程语言、SPDX license、issue + PR 计数、快照日期
实践应用场景¶
1. 多语言 AI 训练数据发现¶
研究者可以快速定位有特定语言开发者内容的目标仓库,然后: - 用 GitHub API 拉取实际文本 - 微调多语言 LLM - 构建跨语言检索系统
2. 多语言 RAG 系统¶
构建面向特定语言开发者社区的 RAG: - 按语言过滤相关仓库 - 按 stars/forks 排序权威性 - 配合多语言 embedding 检索
3. 开发者社区分析¶
- 哪些语言社区最活跃
- 哪些非英语语言在 AI 时代增长最快
- 葡萄牙语开发者社区的 README 写作模式分析
4. 训练语料质量控制¶
由于三分类器独立报告,可以做: - 高 precision 数据集(要求三分类器一致) - 高 recall 数据集(任一分类器 > 0.5) - 自定义语料筛选
实践启示¶
- 元数据集是 AI 数据共享的新范式 — 不直接 dump 内容,而是给"内容地址 + 分类信号",规避版权和滥用问题
- 多分类器独立报告 > 单分类器合并 — 暴露不确定性让用户做严格度选择
- GitHub 主动开放数据 = 长期 AI 生态投资 — 微软 / GitHub 用 CC0 释放 4000 万仓库的元数据,是给整个多语言 AI 社区的礼物
- 多语言 AI 研究门槛大幅降低 — 之前需要爬虫 + 自己实现语言检测,现在直接用现成 dataset
上线状态¶
- 2026-06-15 发布
- 仓库地址:https://github.com/github/multilingual-repositories
- CC0-1.0 许可
原文链接¶
相关实体¶
- 明星开源项目,为什么开始离开 github?
- cisa admin leaked aws govcloud keys on github
- 1-click github token stealing via a vscode bug — ammaraskar
→ 原文存档
Ch14.022 DataComp for Language Models¶
📊 Level ⭐⭐ | 5.0KB |
entities/datacomp-for-language-models.md
→ (无原始来源)
核心内容¶
数据质量基准¶
DataComp 提供标准化的数据质量评估基准:
- 文本质量评分体系(流畅度、信息量、原创性)
- 去重指标(精确匹配、模糊匹配、语义相似度)
- 毒性过滤与安全类别划分
- 领域覆盖度与多样性测量
过滤策略对比¶
DataComp 系统性地对比了多种数据过滤策略: | 策略 | 适用场景 | 效果 |
|------|----------|------|
| 启发式规则 | 快速清洗 | 中等效果,召回率高 |
| 分类器过滤 | 精细筛选 | 依赖标注质量 |
| 嵌入聚类 | 多样性保持 | 平衡质量与覆盖 |
| LLM 裁判 | 高质量目标 | 成本较高 |
开源工具链¶
DataComp 配套开源数据处理工具:
- 数据采样与配比工具
- 质量评估脚本
- 训练效果对比框架
深度分析¶
- DataComp 的核心贡献是将"数据质量"从玄学变为可量化指标。过去 LLM 训练数据的质量评估高度依赖人工直觉和事后效果反推,缺乏系统性的事前测量框架。DataComp 引入的多维度评分体系(流畅度、信息量、去重率、毒性)使得数据选择决策可以从经验驱动转向指标驱动。这是 AI 工程化走向成熟的重要标志。
- 嵌入聚类策略揭示了数据多样性对模型泛化能力的深层影响。DataComp 的实验表明,基于语义嵌入的聚类去重相比简单字符串匹配,在保持数据多样性的同时去除冗余,能显著提升模型在分布外(OOD)测试集上的表现。这验证了信息论视角:重复样本带来的梯度更新收益递减,而多样化样本提供更强的泛化信号。
- LLM 裁判策略的成本-效益权衡尚未解决。DataComp 发现用 GPT-4/Claude 作为数据质量裁判可以显著提升筛选精度,但调用成本使得该策略难以扩展到十亿级网页语料。低成本替代方案(如 DistilBERT 分类器)的精度损失仍不可忽视。这一问题为专用数据质量小模型提供了研究机会。
- 数据配比(data ratio)比数据量更重要。DataComp 的一组关键发现是:在固定计算预算下,精心筛选的 10B tokens 训练数据可以媲美甚至超过粗筛的 100B tokens。这意味着未来 LLM 训练的竞争将从"数据量"转向"数据工程深度"——包括清洗、过滤、配比和课程学习策略。
实践启示¶
- 建立内部数据质量评估流程时,优先采用多维度评分而非单一指标。DataComp 框架表明,文本质量+去重率+毒性三分开评估比综合分数更有诊断价值——可以精准定位数据管道的具体瓶颈。建议至少追踪流畅度(perplexity)、N-gram 去重率和安全分类三个独立指标。
- 在数据清洗早期阶段使用轻量级过滤,后期用高质量样本微调。具体而言:第一轮用 FastText 分类器做粗筛(召回率优先),第二轮用 LLM 裁判对候选高质量样本做精选(精度优先),第三轮用人工抽检验证。这一pipeline在 DataComp 评估中表现最优,且成本可控。
- 在训练数据配比实验中,记录 domain shift 的敏感度。DataComp 建议用小规模实验确定最佳 domain 配比(如 web text / academic / code / conversation 的比例),然后按比例放大。盲目复制其他模型的配比可能效果不佳,因为不同模型的预训练目标差异导致对各 domain 的利用效率不同。
- 对于垂直领域模型,数据来源的领域纯净度比总量更重要。DataComp 的嵌入聚类分析表明,从目标领域高质量源(如医疗文献、法律判决)采样 1B tokens,远优于从通用网页采样 100B tokens 中检索出的相关片段。前者的领域信号密度更高,混入的噪声更少。
相关实体¶
- Cost Effective Deployment Of Vision Language Models For Pet Behavior Detection O
- Eva Bench Data 2 Voice Agent
- Good Qc For Rl Data
- Stochastic Parrot Language Models And Meaning
- Reinforcing Recursive Language Models Alphaxiv
- MOC
Ch14.023 Transforming rare cancer research with Amazon Quick: Integrating biomedical databases for breakthrough discoveries¶
📊 Level ⭐⭐ | 4.0KB |
entities/transforming-rare-cancer-research-with-amazon-quick-integrat.md
Transforming rare cancer research with Amazon Quick: Integrating biomedical databases for breakthrough discoveries¶
相关实体¶
- better decisions at scale: how mathematical optimization del
- ai-driven layoffs aren’t making business sense | cio → 原文存档
深度分析¶
Transforming rare cancer research with Amazon Quick: Integrating biomedical databases for breakthrough discoveries 涉及agent领域的核心技术议题。
核心观点¶
- Integrating these sources for a single investigation typically requires custom ETL pipelines, manual schema reconciliation, and iterative querying across disconnected systems—a process that can take weeks before any analysis begins.
- Amazon Quick Research addresses this integration challenge by providing a unified research environment.
- It ingests structured and unstructured data from multiple sources, including publicly available biomedical databases such as PubMed, and applies large language model (LLM)-driven synthesis to generate cited, versioned research reports.
- In this post, we walk through how to use Amazon Quick Research to integrate biomedical data sources for rare cancer research.
- The walkthrough uses pediatric sarcoma as the research domain and draws on publicly available datasets from PubMed and other open biomedical repositories.
内容结构¶
- Capabilities
- Walkthrough
- Prerequisites
- Part 1: Create a space
- Part 2: Create a research project
- Part 3: Define the objective
- Part 4: Data source selection and integration
- Part 5: AI-powered plan
技术要点¶
- agent架构: 本文在agent方向提出的设计理念与实现路径
- 工程挑战: 实际落地中面临的关键问题与应对策略
- aws趋势: 相关技术演进方向与新兴范式
关联实体¶
- 存之有序治之有矩Agent 记忆系统的工程实践与演进
- Scale Robot Reinforcement Learning With Nvidia Isaac Lab On
- Nvidia Isaac Lab Sagemaker Robot Rl Humanoid
- Karpathy 最新访谈从 Vibe Coding 到 Agentic Engineering
- Openclaw 完全指南这可能是全网最新最全的系统化教程了32W字建议收藏
- 一文带你弄懂 Ai 圈爆火的新概念Harness Engineering
实践启示¶
- 工程落地: agent领域方案需关注可观测性、可维护性和成本效率
- 技术选型: 根据场景选择合适的技术栈,避免过度设计或盲目追新
- 持续迭代: 建立数据驱动的反馈闭环,持续优化系统表现
- 风险管控: 引入新技术需评估对现有系统稳定性的影响,做好降级预案
Ch14.024 Amazon Quick integration with time-series databases for market intelligence using MCP¶
📊 Level ⭐⭐ | 3.3KB |
entities/amazon-quick-mcp-kdbx-time-series.md
Amazon Quick integration with time-series databases for market intelligence using MCP¶
相关实体¶
深度分析¶
Amazon Quick integration with time-series databases for market intelligence using MCP 涉及agent领域的核心技术议题。
核心观点¶
- As a financial analyst, you navigate millions of stock trades flowing through markets every second, searching for patterns that drive trading decisions.
- Financial institutions often use time series databases to analyze high-frequency market data.
- In this post, we walk through a practical implementation using KDB-X MCP server integration with Amazon Quick, demonstrating how traders and analysts can ask questions using conversational language and receive actionable insights from datasets.
- You can apply this same integration pattern across various domains, from financial market analysis to IoT sensor monitoring to DevOps performance dashboards, where you need to simplify access to time series insights.
-
Solution overview¶
Amazon Quick is a comprehensive, generative AI-powered business intelligence service that you can use to analyze data, create visualizations, automate workflows, and collaborate across your organization.
内容结构¶
- Solution overview
- Prerequisites
- Configuration of MCP server
- Amazon Bedrock AgentCore Gateway integration with MCP
- Integration with Amazon Quick actions
- Interaction with the chat agent
- Clean up
- Conclusion
技术要点¶
- agent架构: 本文在agent方向提出的设计理念与实现路径
- 工程挑战: 实际落地中面临的关键问题与应对策略
- architecture趋势: 相关技术演进方向与新兴范式
关联实体¶
- 存之有序治之有矩Agent 记忆系统的工程实践与演进
- Karpathy 最新访谈从 Vibe Coding 到 Agentic Engineering
- Openclaw 完全指南这可能是全网最新最全的系统化教程了32W字建议收藏
- Karpathy Vibe Coding Agentic Engineering
- Agentops Operationalize Agentic Ai At Scale With Amazon Bedr
- 两万字详解Claude Code源码核心机制
实践启示¶
- 工程落地: agent领域方案需关注可观测性、可维护性和成本效率
- 技术选型: 根据场景选择合适的技术栈,避免过度设计或盲目追新
- 持续迭代: 建立数据驱动的反馈闭环,持续优化系统表现
- 风险管控: 引入新技术需评估对现有系统稳定性的影响,做好降级预案
Ch14.025 Metric Semantic Layer: How Lyft Governs and Scales Key Data Definitions¶
📊 Level ⭐⭐ | 3.2KB |
entities/metric-semantic-layer-how-lyft-governs-and-scales-key-data-definitions.md
Metric Semantic Layer: How Lyft Governs and Scales Key Data Definitions¶
Markdown Content:
Written byRohit ChanneandSimran Mirchandaniat Lyft.
At Lyft, data isn’t just a resource — it’s woven into everything we do. Metrics drive key forecasts, steer operational decisions, and put our boldest hypotheses to the test. But as Lyft scaled, products launched and evolved, and team members came and went, we found ourselves at risk of different teams using different definitions for a given metric. What did “Metric ABC” actually mean? The answer often depended on the context and application of the team you asked.
The consequences were predictable. Without centralized version control or a shared standard, outdated metric definitions crept into decision-making.
Our solution was to build an internal Metric Semantic Layer (MSL): a centralized repository that serves as a single, authoritative home for every metric’s definition — providing both a clear, plain-English description and the definitive SQL code. No more hunting across codebases or tribal knowledge — just one place to store and access a standardized, agreed-upon definition. With MSL, we have a single source of truth — consistent terminology and assumptions across every team, so everyone is genuinely speaking the same language. We achieve this through three key principles:
- Simplified onboarding and change management — update a metric definition once, and the change automatically and frictionlessly flows through every downstream application that depends on it
- Intentional governance— clarified ownership, defined scope, clear accountability for data quality, and a structure resilient enough to survive org changes, team rotations, and attrition
- Transparency and accessibility — definitions are easy for both technical and non-technical users (and downstream applications) to find and integrate into day-to-day workflows
Taking the above principles into account, we implemented the Metrics Semantic Layer as a Python package:
→ 原文存档
Ch14.026 Write-Ahead Intent Log: a Foundation for Efficient CDC at Scale¶
📊 Level ⭐⭐ | 3.1KB |
entities/write-ahead-intent-log-a-foundation-for-efficient-cdc-at-scale.md
Write-Ahead Intent Log: a Foundation for Efficient CDC at Scale¶
Markdown Content: InfoQ HomepagePresentationsWrite-Ahead Intent Log: a Foundation for Efficient CDC at Scale
/presentations/write-ahead-intent-log/en/slides/Doi-1781788191276.jpg)
Vinay Chella and Akshat Goel discuss the challenges of running traditional CDC across heterogeneous databases during peak order traffic. They explain how Debezium hit limits under high load and share how they built Write-Ahead Intent Log (WAIL) - a custom architecture that utilizes a dumb producer proxy and a smart consumer pattern to cleanly separate the intent from the state payload.
Vinay Chella is an Engineering Leader at DoorDash, where he leads the Storage and Streaming Infrastructure organization that powers mission-critical systems across the marketplace. Akshat Goel is a Staff Software Engineer at DoorDash, where he builds the Storage Access Platform, a unified abstraction layer powering all online data stores.
Software is changing the world. QCon San Francisco empowers software development by facilitating the spread of knowledge and innovation in the developer community. A practitioner-driven conference, QCon is designed for technical team leads, architects, engineering directors, and project managers who influence innovation in their teams.
/filters:no_upscale()/sponsorship/eventsnotice/7dd71c7c-4b0e-4760-b97d-232ac1816637/resources/1NeuBirdWebinarJune25-Transcripts-1777458459989.png) June 25th, 2026, 1 PM EDT
June 25th, 2026, 1 PM EDT
Architecting for Autonomous Reliability: Embedding AI into Your Observability Stack¶
Presented by: Justin Griffin - Head of Product at NeuBird AI
/filters:no_upscale()/sponsorship/eventsnotice/0b46c1f1-7263-457d-82d9-12be6fa07fbd/resources/1DatadogWebinarJuly9-Transcripts-1779204853394.png) July 9th, 2026, 12 PM EDT
July 9th, 2026, 12 PM EDT
Rethinking Logs in the Age of AI Analysis¶
→ 原文存档
Ch14.027 The Data Operating System for the Foundation Model Era — Data Juicer¶
📊 Level ⭐⭐ | 3.0KB |
entities/the-data-operating-system-for-the-foundation-model-era-data-juicer.md
The Data Operating System for the Foundation Model Era — Data Juicer¶
Markdown Content:



Multimodal | Cloud-Native | AI-Ready | Large-Scale
Data-Juicer (DJ) transforms raw data chaos into AI-ready intelligence. It treats data processing as composable infrastructure—providing modular building blocks to clean, synthesize, and analyze data across the entire AI lifecycle, unlocking latent value in every byte.
Whether you’re deduplicating web-scale pre-training corpora, curating agent interaction traces, or preparing domain-specific RAG indices, DJ scales seamlessly from your laptop to thousand-node clusters—no glue code required.
🚀 Quick Start#¶
→ 原文存档
Ch14.028 verify-data:一个端到端的数据验数 Agent Skill¶
📊 Level ⭐⭐ | 2.8KB |
entities/verify-data-agent-skill-data-validation.md
verify-data:一个端到端的数据验数 Agent Skill¶
→ 原文存档
深度分析¶
verify-data:一个端到端的数据验数 Agent Skill 涉及agent领域的核心技术议题。
核心观点¶
-
verify-data:一个端到端的数据验数 Agent Skill¶
前置说明¶
Agent Skill 是一种给 AI Agent 定义的可复用能力包——可以理解为"Agent 的 SOP"。 2. 一个 Skill 定义了 Agent 在特定场景下应该做什么、怎么做、有哪些约束和红线。 3. 当用户用自然语言触发后,Agent 会按照 Skill 定义的流程自动执行,而不是靠模型临时发挥。 4. verify-data 就是这样一个 Skill:它把数据验数的全部流程——从信息收集、SQL 生成、执行到报告产出——编码成了一套可复用、可迭代的 Agent 能力。 5. "** "验数"是指数据表上线前的人工review环节——评审人员需要看到完整的验证证据,确认数据逻辑正确、口径一致、无异常后才允许发布上线。
内容结构¶
- verify-data:一个端到端的数据验数 Agent Skill
- 前置说明
- 数据层术语
- 一、背景与痛点
- 二、verify-data 是什么
- 核心优势
- 5大场景识别
- 效率提升
技术要点¶
- agent架构: 本文在agent方向提出的设计理念与实现路径
- 工程挑战: 实际落地中面临的关键问题与应对策略
- architecture趋势: 相关技术演进方向与新兴范式
关联实体¶
- 存之有序治之有矩Agent 记忆系统的工程实践与演进
- 你不知道的 Agent原理架构与工程实践 V2
- Openclaw 完全指南这可能是全网最新最全的系统化教程了32W字建议收藏 V2
- Karpathy 最新访谈从 Vibe Coding 到 Agentic Engineering
- Openclaw 完全指南这可能是全网最新最全的系统化教程了32W字建议收藏
- 一文带你弄懂 Ai 圈爆火的新概念Harness Engineering
实践启示¶
- 工程落地: agent领域方案需关注可观测性、可维护性和成本效率
- 技术选型: 根据场景选择合适的技术栈,避免过度设计或盲目追新
- 持续迭代: 建立数据驱动的反馈闭环,持续优化系统表现
- 风险管控: 引入新技术需评估对现有系统稳定性的影响,做好降级预案
Ch14.029 ai 驱动的大数据工程 从平台驱动到 aidlc 的范式迁移¶
📊 Level ⭐⭐⭐ | 14.5KB |
entities/ai-驱动的大数据工程-从平台驱动到-aidlc-的范式迁移.md
ai 驱动的大数据工程 从平台驱动到 aidlc 的范式迁移¶
摘要:本文阐述了数据工程正从"平台驱动"的数据中台范式向"AI 驱动"的 AIDLC 范式迁移,其核心在于控制面从平台功能转为知识资产、开发模式从过程式转为声明式、质量保障从后置扫描转为前置契约,并给出了落地成熟度模型与五步实施建议。
目录
深度分析¶
一、范式迁移的历史必然性¶
数据工程的四次演变(手工作坊期 → 组件拼装期 → 数据中台期 → AI 驱动期)揭示了一个核心规律:每一阶段的跃迁都在解决上一阶段的主要矛盾。手工作坊期的核心问题是"知识无法复制";组件拼装期解决了算力规模化但引入"散"的矛盾;数据中台期通过统一控制面提升了效率,但其隐形前提——"人写代码,平台托管代码"——始终未被打破,成为生产力的天花板。
AIDLC 的出现并非偶然。2024 年后基础模型和 Agent 框架的成熟,使 AI 从"代码补全工具"升级为"贯穿需求到运维的协作者"。这一转变与软件工程史上从汇编到高级语言、从命令式到 SQL/函数式的跃迁同构——都是将人从"怎么做"中解放,聚焦于更稀缺的"做什么、为什么"。
二、三层叠加架构的深层含义¶
文章提出的三层叠加结构(平台执行层、AIDLC 协作层、知识与规范层)具有深刻的架构哲学意义。传统数据工程架构只回答"链路是什么",而忽略了"链路是怎么被构建和演进的"。AIDLC 的三层结构实际上是将数据工程的核心关注点从"执行"转向"意图"。
"知识与规范层"以"AI 可执行的 Markdown"(Steering 文件)为核心,这是整个范式迁移的基石。规范从"供人类阅读"转变为"供 AI 执行",意味着团队的知识资产第一次具备了直接被机器消费的能力,且可版本控制、可 diff、可回滚、可 code review。
三、三个本质区别的结构性影响¶
控制面:从平台功能到知识资产 — 这一转变的核心影响在于资产与平台解耦。传统模式下,团队的资产体现为"配好的节点、画好的 DAG",深度绑定于特定平台;AIDLC 模式下,规范可跨平台复用,更换底层数据平台时 Steering 可以直接携带。这意味着过去的"平台绑定成本"变成了"平台选择自由度"。
开发范式:从过程式到声明式 — 这是生产力杠杆的根本性变化。过程式开发中,过程即产物,调试需要回放过程;声明式开发中,Spec 即产物,实现细节对开发者不可见也不需要关心。这一转变将开发者从"怎么做"中解放,使其能够聚焦于更稀缺的"做什么、为什么"。
质量保障:从后置扫描到前置契约 — shift-left 策略在数据工程中的典型体现。数据质量(DQ)从"开发 → 上线 → 扫描 → 发现问题 → 返工"的线性流程,转变为 Inception 阶段即定义 DQ 契约,Construction 阶段 Agent 自动生成对应 DQ 规则代码。缺陷修复成本曲线显示,口径争议等典型缺陷在 Spec Review 阶段发现的修复成本与上线后发现相比,可差两个数量级。
四、案例的典型性与局限性¶
实时 GMV 渠道归因案例具有很好的典型性——它是电商场景中的高频需求,涉及实时流、批处理、外部 API 多个数据源,且对口径一致性要求极高。两条路径的对比清晰展示了 AIDLC 的优势:交付周期从 3 周压缩到 9 天,口径争议发现点从第 3 周(成本约 100×)前移到第 2 天(成本约 1×)。
但需注意其局限性:案例的成功依赖于 Steering 文件的成熟度、业务方参与 Spec Review 的能力、以及团队对声明式开发的适应。这些在早期试点团队中往往是最大的阻力来源。
五、角色演变的社会学意义¶
文章关于团队角色演变的分析揭示了 AI 驱动数据工程的社会学维度。数据架构师的杠杆效应最为显著——过去依赖执行层自觉性,现在 Steering 文件的一次提交即可改变整个团队的 AI 产出质量,架构师第一次具备了"直接控制产线"的能力。
数据开发工程师的两极分化值得关注:能清晰表达设计意图的开发者获得更大杠杆,而单纯依赖"写得快"的开发者被暴露。这与软件工程历史上任何一次生产力跃迁后的分化模式一致——适应新范式的少数人获得超额收益,多数人经历转型阵痛。
六、成熟度模型的实操价值¶
L0-L4 成熟度模型具有明确的实操价值:L0(散点使用)和 L1(工具化)是大多数企业当前的常态;L2(规范化)是第一个实质性门槛,Steering 文件就位并在窄场景试点中跑通完整流程是核心标志;L3(生命周期化)意味着 AIDLC 成为主流开发模式且 KPI 已重定义;L4(自演化)代表运行反馈自动回流到 Steering,Agent 具备一定程度的自主优化能力。
从 L0/L1 到 L2 的跃迁是最具挑战性也最有价值的一步——这意味着团队要从"AI 被零星使用"转变为"AI 成为开发流程的有机组成部分"。
七、反模式的诊断价值¶
三个反模式(让 AI 绕过治理、Spec 变成后补文档、把 AI 当黑盒)实际上是传统组织采用新范式时的典型心理障碍的投射:
- "让 AI 绕过治理"反映的是对速度的焦虑导致的短期主义
- "Spec 变成后补文档"反映的是组织文化中"先干再说"的惯性
- "把 AI 当黑盒"反映的是对 AI 产出的盲目信任或对自身审核责任的逃避
理解这些反模式比学习正确做法更重要——因为它们是采用新范式时的必然障碍,识别它们的能力决定了团队能否顺利过渡。
实践启示¶
一、立即可启动的低风险起点¶
文章给出的务实起点极具价值:在代码仓库中新建 steering/ 目录,请资深数据架构师将"团队的分层规范"写成第一份 Markdown 文件。这个动作的杠杆极高、风险极低——不依赖任何工具升级,不改变任何开发流程,只是将隐性知识显性化。
建议按"分层规范 → 命名规则 → 核心指标字典 → 质量契约模板"的顺序推进,每份文档控制在 2000 字以内,优先覆盖最高频使用的 10 张表。不追求完美,优先可用。
二、Steering 文件的设计原则¶
有效的 Steering 文件应具备以下特征: 1. 可执行性 — 规范必须以 AI 可以理解和执行的方式书写,避免模糊的自然语言描述 2. 原子性 — 每份 Steering 文件聚焦一个主题,便于版本管理和独立演进 3. 可验证性 — 规范应包含明确的验收标准,AI 产出必须可被验证 4. 层级结构 — 从公司级到团队级到项目级,分层管理,避免单点失控
Steering 文件是 AIDLC 范式的基础设施,其质量直接决定了 AI 协作层的产出质量。
三、试点场景的选择策略¶
选择窄场景试点的原则是"边界清晰、业务方熟悉"。一个理想的试点场景应满足:
- 涉及 1-2 个数据链路,而非全链路
- 业务方愿意参与 Spec Review
- 失败影响可控,不会造成生产事故
- 成功后可量化收益(如 lead time、返工率)
"新增一张 ADS 表"的完整流程是一个推荐的起点,因为它边界清晰、频率高、收益可见。
四、KPI 重定义的必要性¶
从"上线的表数量"转向"需求到上线的 lead time"与"返工率"是 AIDLC 范式落地的关键。传统 KPI 衡量的是产出数量,而 AIDLC 范式下产出数量将由 AI 决定,团队的核心价值在于需求理解质量(Spec 的清晰度)和产出验收质量(Review 的有效性)。
KPI 不变,团队成员在现实激励下难以真正采用新范式——这是组织变革中最容易被忽视但最关键的环节。
五、AI 护栏的构建优先级¶
五条红线(权限边界、成本阈值、敏感数据保护、幻觉检测、审计日志)中,敏感数据保护和审计日志应优先构建,因为它们涉及合规风险,是 AI 驱动开发中最不容妥协的部分。权限边界和成本阈值可以逐步精细化。幻觉检测是技术挑战最高的,需要结合业务知识库和人工抽检策略。
Agent 应在治理框架内工作,而非绕过它——这是 AIDLC 范式区别于"AI 自由发挥"的关键。
六、团队能力建设的路径¶
AIDLC 转型对团队能力的要求发生根本变化:
- 数据架构师:从绘制分层转向沉淀 Steering 与 Prompt,需要学习 Prompt 工程和知识管理
- 数据开发工程师:从写代码转向撰写 Spec 与验收标准,需要强化需求理解和抽象能力
- 数据分析师:获得最大直接收益,但需要学习与 AI 协作的方式
- 数据质量团队:从"救火"转变为"立法",需要掌握契约设计和 DQ 契约的编写
- 平台 SRE:从运维 pipeline 扩展到运维 AI 系统,需要学习 AI 系统的可观测性和护栏设计
团队的能力建设应早于工具升级——AIDLC 工具的使用门槛低,但用好门槛高,关键在于团队的能力储备。
七、对行业趋势的判断¶
文章判断"未来 3 年,采用 AI 原生范式的数据团队与停留在平台驱动范式的数据团队,在人效上的差距可能拉大到 5–10 倍"。这个判断的核心依据是:基础模型的能力会在行业内快速拉平,真正的竞争优势来自"谁更早把自己的方法论变成 AI 可执行的知识"。
这意味着 AIDLC 转型不是技术升级,而是方法论竞争。那些率先将数据工程的最佳实践结构化为 Steering 文件并持续迭代的团队,将在生产效率上建立可持续的差异化优势。