How Amazon Finance streamlines regulatory inquiries by using generative AI on AWS¶
Ch11.010 How Amazon Finance streamlines regulatory inquiries by using generative AI on AWS¶
📊 Level ⭐⭐ | 31.0KB |
entities/how-amazon-finance-streamlines-regulatory-inquiries-by-using.md
"How Amazon Finance streamlines regulatory inquiries by using generative AI on AWS"¶
source: rss source_url: https://aws.amazon.com/blogs/machine-learning/how-amazon-finance-streamlines-regulatory-inquiries-by-using-generative-ai-on-aws/ ingested: 2026-05-13 feed_name: AWS China ML source_published: 2026-05-12T16:41:33Z
How Amazon Finance streamlines regulatory inquiries by using generative AI on AWS¶
Amazon's Finance Technology (FinTech) teams build and operate systems for Amazon teams to manage regulatory inquiries in compliance with different jurisdictions. These teams process regulatory inquiries from authorities, each presenting different requirements, document formats, and complexity levels. Processing these regulatory inquiries involves reviewing documentation, extracting relevant information, retrieving supporting data from multiple systems within Amazon's infrastructure, and compiling responses within regulatory timeframes. As inquiry frequency and business complexity grew, Amazon needed a more scalable approach. In this post, we demonstrate how Amazon FinTech teams are using Amazon Bedrock and other AWS services to build a scalable AI application to transform how regulatory inquiries are handled. Each team using this solution creates and maintains its own dedicated knowledge base, populated with that team's specific documents and reference materials.
Challenges¶
The scale and complexity of managing regulatory inquiries presented several interconnected challenges: Knowledge fragmentation and retrieval complexity Regulatory inquiries require synthesizing information from thousands of historical documents. These documents exist in various formats (PDF, PPT, Word, CSV) and contain domain-specific terminology. Teams needed a way to quickly locate relevant precedents and supporting information across this vast corpus while maintaining accuracy and regulatory compliance. Conversational context and state management Regulatory inquiries require multi-turn conversations where context from earlier interactions is essential for generating accurate responses. Maintaining conversational state across sessions and tracking response evolution as team members refine answers through iterative interactions presents significant complexity. Observability and continuous improvement With generative AI systems, understanding why a particular response was generated is as important as the response itself. Teams required comprehensive visibility into the retrieval process, model decisions, and user interactions to identify areas for improvement and maintain compliance with responsible AI principles. For example, teams must detect when the model hallucinates information that isn't present in source documents, or catch when the system retrieves outdated compliance guidelines that could lead to regulatory violations. AI systems experience accuracy drift over time as models, prompts, and the document corpus change, requiring continuous monitoring.
Solution overview¶
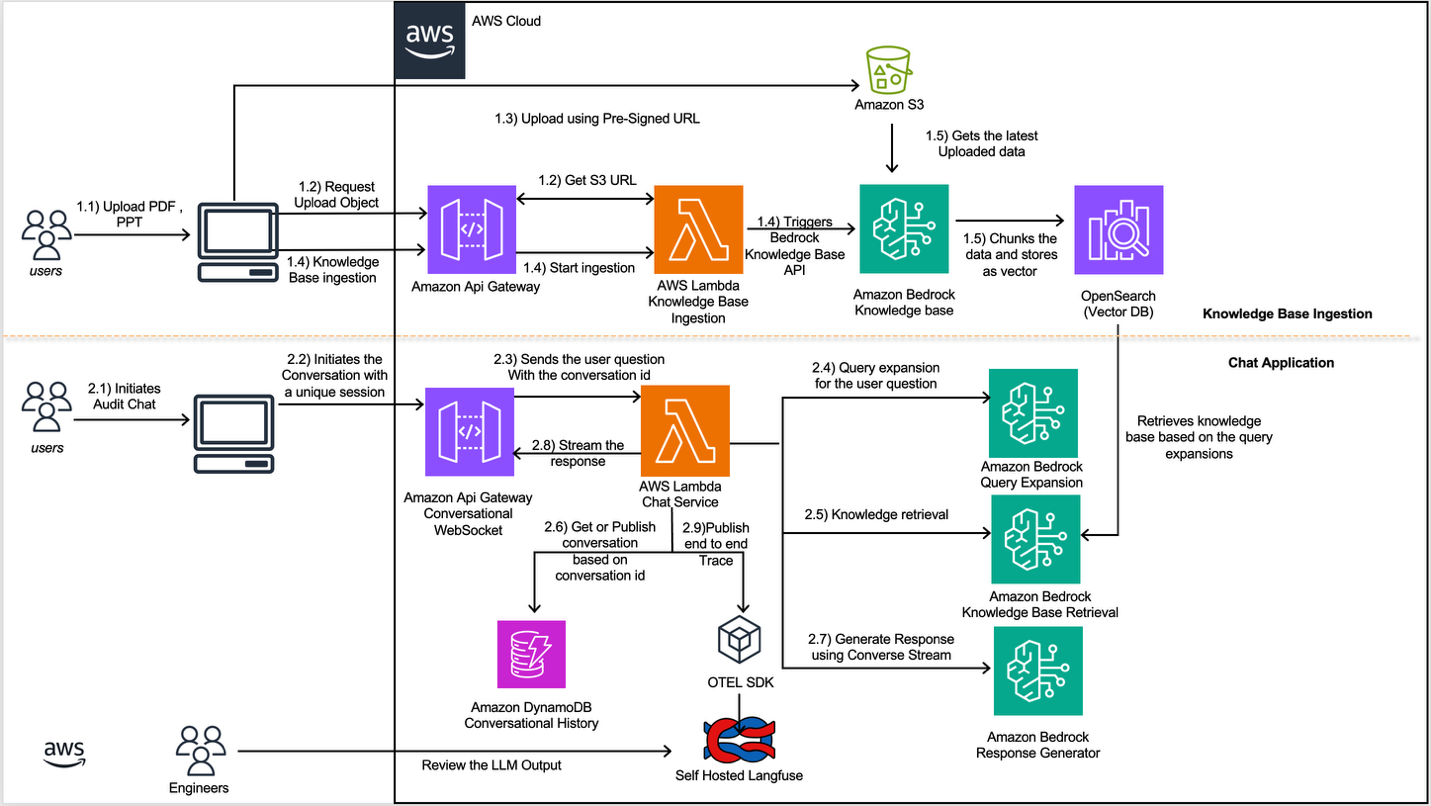
To address these challenges, Amazon FinTech team built an intelligent regulatory response automation system using Amazon Bedrock, AWS Lambda, and supporting AWS services. The solution implements Retrieval Augmented Generation (RAG) with Amazon Bedrock Knowledge Bases and Amazon OpenSearch Serverless for vector storage, enabling information retrieval from thousands of historical documents. Real-time chat interactions powered by Claude Sonnet 4.5 through the Converse Stream API, combined with Amazon DynamoDB for conversation history management, provide contextually-aware multi-turn conversations. Comprehensive observability through OpenTelemetry and self-hosted Langfuse ensures continuous monitoring and improvement of the AI system's performance. The system doesn't cache large language model (LLM) responses or intermediate results because regulatory inquiries are highly contextual and are prone to a low cache hit rate. The following diagram shows how you can use Amazon Bedrock Knowledge Bases in a workflow, alongside Converse API and other tools, to provide necessary information for regulatory inquiries:
{kind=link}
Knowledge base ingestion flow¶
The knowledge base ingestion flow provides an automated document processing pipeline that initiates after the user uploads a document. Its job is to embed the document's data into an Amazon Bedrock Knowledge Base. Here is the flow: You can use the knowledge base ingestion workflow to upload documents in bulk and transform them into searchable vector embeddings through an automated pipeline. The following detailed flow is illustrated in the previous figure. 1. Document Upload by User : Users upload documents through the client application. 2. Pre-Signed URL Generation : The client application sends a request to Amazon API Gateway, which invokes the knowledge base ingestion AWS Lambda function to generate a pre-signed S3 URL. 3. Document Upload : The client application uses the generated pre-signed URL to upload the document. 4. Ingestion Trigger and Data Processing : After the document is successfully uploaded to Amazon Simple Storage Service (Amazon S3), the client application triggers the Amazon API Gateway to initiate the document processing AWS Lambda, which handles format conversion and manages the concurrent ingestion of documents. We don't need to pre-process the images, charts, and tables in these documents because the Amazon Bedrock Knowledge Base is configured with Amazon Bedrock Data Automation (BDA) to effectively extract this multimodal content. The AWS Lambda function then calls the Amazon Bedrock Knowledge Bases. 5. Vector Storage: The Amazon Bedrock Knowledge Base chunks the document content using a hierarchical chunking strategy, generates embeddings using Amazon Titan Text Embeddings, and stores the resulting vectors in OpenSearch Serverless. Hierarchical chunking creates nested parent-child relationships that mirror the sectioned structure of financial documents. This strategy works well for structured and complex documents because it indexes small chunks for precise retrieval while returning larger parent chunks to provide sufficient context for coherent responses. Building an automated ingestion pipeline addresses the core challenge of knowledge fragmentation by efficiently processing thousands of historical documents across multiple formats while optimizing content indexing for relevant AI responses. This parallelized approach enables the system to scale effectively, accommodating the growing year-over-year regulatory inquiry activity while maintaining consistent processing performance across large document volumes.
Chat Application¶
The Chat Application provides a real-time conversation interface powered by AWS serverless architecture, enabling natural language interactions with the system. We chose to stream responses to customers so they can begin reading the AI response sooner in real-time, implementing this capability through WebSocket connections. Through these WebSocket connections and the Claude Sonnet 4.5 model, it delivers contextually relevant responses while maintaining conversation state in DynamoDB. The workflow operates as follows: 1. Initiate Chat Conversation: Users initiate or open an existing chat session through the client application. 2. WebSocket Connection : The application uses WebSockets to establish a persistent, bi-directional connection with Amazon API Gateway. 3. Message Submission : The application posts the user questions through the WebSocket connection which is propagated to the Chat service AWS Lambda function. 4. Query Enhancement : The Chat Service AWS Lambda function uses the Claude 3.5 Haiku model with a query expansion strategy to generate multiple variations of the user's question. 5. Knowledge Retrieval : The Chat Service Lambda invokes the Amazon Bedrock Knowledge Bases Retrieve API for each expanded query. The API performs vector similarity searches against the underlying OpenSearch Serverless index and returns the most relevant document chunks along with their source metadata and relevance scores. 6. Context Assembly : The Chat Service AWS Lambda function retrieves conversation history from Amazon DynamoDB (for existing conversations, based on that specific conversation ID) and combines it with the retrieved knowledge base results and the user's question. 7. Response Generation : The Chat Service AWS Lambda function uses the Converse Stream API with Claude Sonnet 4.5 and a response generator prompt to produce a contextually relevant answer based on the assembled context. 8. User Engagement: The Chat Service AWS Lambda function streams the generated response back to the client application in Markdown format through the WebSocket connection and stores all the conversation in the Conversational History Table by Amazon DynamoDb. 9. Observability : Throughout the process, the Chat Service publishes end-to-end traces to a self-hosted Langfuse instance using the OpenTelemetry (OTEL) SDK. This captures detailed telemetry data including latency metrics, token usage, prompt templates, and model responses.
Multi-turn conversational experience¶
Regulatory inquiry discussions often progress through multiple exchanges as teams refine responses and reference additional data sources. To support this iterative process, the Amazon FinTech team implemented a multi-turn conversational workflow using Amazon API Gateway (WebSocket APIs), AWS Lambda, and Amazon DynamoDB, integrated with the Amazon Bedrock ConverseStream API for low-latency, context-aware dialogue. Each chat session is securely authenticated through Amazon Cognito and assigned a unique conversation ID. DynamoDB stores messages in chronological order to preserve context across sessions, so users can resume prior discussions seamlessly and maintain continuity. When a user submits a query, the system sanitizes inputs to prevent prompt injection attacks. After sanitization, the system classifies intent and determines whether retrieval from the Amazon Bedrock Knowledge Base is required. This determination is made through an LLM call that classifies the user query as either conversational or knowledge intensive. For complex, knowledge-intensive questions, the workflow employs a query expansion strategy that addresses the prevalent use of acronyms and abbreviated questions by users. This layer generates up to five query variations using Claude 3.5 Haiku, then makes parallel Retrieve API calls to the Knowledge Base, retrieving relevant results using OpenSearch vector similarity search. To maintain performance at scale, the workflow implements parallel processing for these retrieval calls using multi-threading. This optimization reduced retrieval latency from 10 seconds (sequential processing) to under 2 seconds, enabling responsive conversations. The retrieved information—combined with recent conversation history—is passed to Claude Sonnet 4.5 through the ConverseStream API augmented with Amazon Bedrock Guardrails, that implement sensitive information filters to automatically detect and remove PII and financial data from both inputs and outputs. This is critical for protecting regulatory documentation. When prompt injection attempts are detected, the system responds with "Sorry, the model cannot answer that question," maintaning secure and compliant interactions while maintaining conversational fluency. This architecture delivers continuity, transparency, and scalability. Users receive real-time, streaming responses with status updates throughout the retrieval and generation phases, improving engagement and reducing latency. Persistent logs in DynamoDB provide an immutable audit trail for compliance review, while the serverless and event-driven design scales automatically to support concurrent sessions. Together, these capabilities enable Amazon FinTech team to conduct complex, iterative conversations—producing contextually relevant, secure, and regulatory-compliant responses powered by Amazon Bedrock.
Observability¶
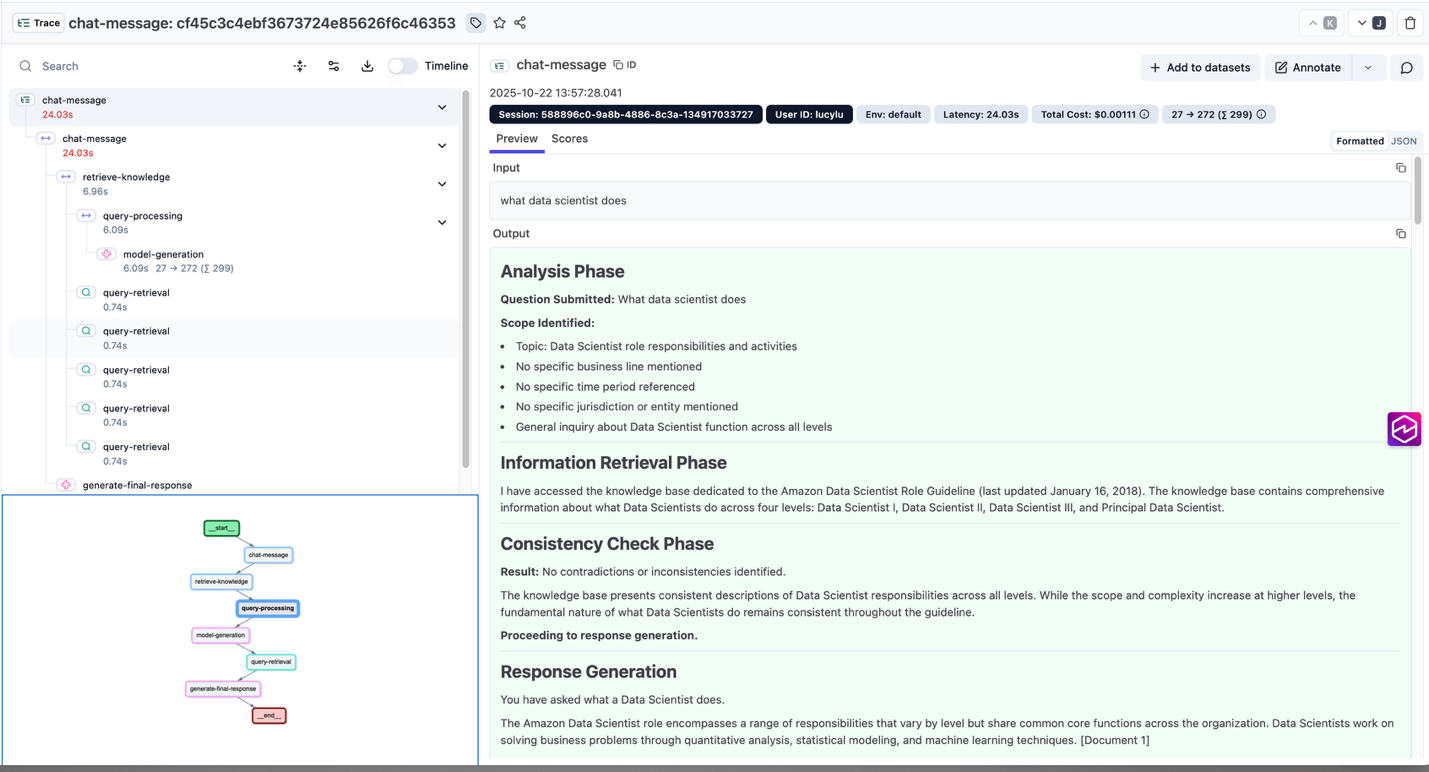
Observability plays a critical role in understanding and improving AI-driven workflows. To achieve complete visibility into the regulatory inquiry response system, the Chat Service AWS Lambda integrated OpenTelemetry (OTEL) with a self-hosted Langfuse instance to capture detailed, end-to-end traces of each interaction. This setup provides engineers and applied scientists with fine-grained telemetry on how prompts are processed, knowledge is retrieved, and responses are generated. This enables nearly continuous refinement of the system's performance and accuracy. The decision to use OTEL over the native Langfuse SDK provides vendor-neutral flexibility, allowing telemetry data to be routed to multiple observability backends and adapted to evolving monitoring requirements. At runtime, each stage of the Chat Service AWS Lambda is manually instrumented using the OTEL Java SDK to record latency, token usage, model decisions, and prompt metadata in OTEL Generative AI semantic standard. Spans are published to Langfuse in near real time, giving the team a transparent view of how the Amazon Bedrock ConverseStream API, Knowledge Base retrieval, and Claude Sonnet 4.5 interact within a single request. The detailed telemetry allows the team to identify performance bottlenecks, optimize prompt strategies, and enhance retrieval precision while maintaining responsible AI practices. This observability framework maintains trust and accountability in the system's behavior. Engineers can correlate user actions with model outcomes, trace data lineage across multiple services, and fine-tune configurations without disrupting operations. By combining OpenTelemetry's interoperability with Langfuse's visualization and analytics, Amazon FinTech team gains a scalable, extensible foundation for evaluating generative AI systems at scale—turning every interaction into actionable insight for continuous improvement. The following screenshot illustrates an end-to-end trace captured in Langfuse, showcasing how the observability solution captures the complete workflow—from query expansion and knowledge retrieval to model prompts, responses, and latency metrics. It also highlights source document citations, offering a transparent view of how contextual information flows through the system during response generation Reference: End-to-End Trace Posted in Langfuse
{kind=link}
Conclusion¶
In this post, you saw how Amazon FinTech team built a scalable AI solution using Amazon Bedrock, designed to support regulatory inquiries by automating knowledge retrieval, conversational workflows, and response generation. By combining a document ingestion pipeline, multi-turn stateful conversations, and detailed observability via OpenTelemetry and Langfuse, the architecture empowers teams to handle regulatory inquiries in governed, traceable and compliant manner. Because the entire stack is built on AWS serverless services, it offers the operational scalability, security, and elasticity required for enterprise-grade deployment. Whether you're dealing with legal compliance, regulatory inquiries, or high-volume internal knowledge workflows, this pattern offers a practical foundation that you can tailor and extend to your business domain. If you're ready to modernize your knowledge-intensive processes with generative AI, explore the Amazon Bedrock documentation to discover how you can begin building your own secure, governed, and scalable AI-powered workflows.
About the authors¶
{kind=link}
Balajikumar Gopalakrishnan¶
Balajikumar is a Principal Engineer at Amazon Finance Technology. He has been with Amazon since 2013, solving real-world challenges through technology that directly impact the lives of Amazon customers. Outside of work, Balaji enjoys hiking, painting, and spending time with his family. He is also a movie buff!
{kind=link}
Biswajit Mohapatra¶
Biswajit is a Senior Data Engineer at Amazon , where he leverages his 7 years of developer experience to build end to end solutions that help compliance processes . Prior to Amazon , Biswajit worked a lot building real time streaming solutions for HealthCare systems . When he's not engineering solutions, Biswajit enjoys traveling and discovering local cuisines.
{kind=link}
Pramodh Korukonda¶
Pramodh is a Senior Software Development Engineer at Amazon Finance Technology. He is an Amazonian since 2013, began his journey solving problems for Amazon vendors and small businesses, and now focuses on Amazon's Finance teams. Outside work, he enjoys cooking for loved ones and exploring local food through his travels.
{kind=link}
Jeff Rebacz¶
Jeff is a Senior Software Development Engineer at Amazon building data and document gathering automation for tax audit processes since 2019. Prior to Amazon, Jeff worked in the industrial automation space developing a time-series database for asset monitoring. Jeff enjoys staying active through volleyball and hiking. He also has a hands-on hobby of fixing cars.
{kind=link}
Yunfei Bai¶
Yunfei is a Principal Applied AI Architect at AWS. With a background in AI/ML, data science, and analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs AI/ML and data analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei has a PhD in Electronic and Electrical Engineering. Outside of work, Yunfei enjoys reading and music.
深度分析¶
1. RAG 架构在合规场景中的独特价值 这篇文章揭示了 RAG(检索增强生成)在一个高风险、合规密集型场景中的具体落地方式。与通用 RAG 应用不同,Amazon Finance 的方案有几个值得注意的设计决策:① 采用层级分块(hierarchical chunking)策略,保留文档的章节结构,这对于财务文档的多层嵌套结构至关重要;② 使用 DynamoDB 而非缓存来管理对话历史,因为监管问询的上下文高度差异化,缓存命中率极低;③ 明确不缓存 LLM 响应或中间结果,这是对监管场景"每一条回复都必须可追溯"需求的直接响应。这些决策反映出一个核心原则:在合规敏感场景中,架构选择必须优先考虑审计能力而非性能优化。 2. Query Expansion 作为"首字大写缩写词"问题的解决方案 文章提到了一个容易被忽视的技术细节:监管领域充斥着首字母缩写词(如 AML、KYC、GDPR),用户提问时往往会使用这些缩写。Amazon 采用了 Query Expansion 策略——用 Claude 3.5 Haiku 生成多达 5 个查询变体,并行调用检索 API。这不仅解决了缩写词问题,还通过多路召回提升了召回率。关键工程优化在于并行处理:延迟从顺序处理的 10 秒降至并行处理的 2 秒以下。这个优化揭示了一个重要的工程直觉——在 RAG 系统中,检索延迟往往是用户体验的瓶颈,而并行化是降低延迟的最直接手段。 3. 可观测性不是事后添加,而是架构内建 这篇文章将 OpenTelemetry 与 Langfuse 的结合置于核心位置,而非作为补充说明。这反映出一个重要的架构趋势:在生成式 AI 系统中,"理解为何生成某个回复"与"生成回复本身"同等重要。文章指出 AI 系统会经历"精度漂移"——模型、提示词和文档语料库都在变化,导致系统准确性随时间下降。这不是一次性问题,而是需要持续监控的运营挑战。OpenTelemetry 在这里的选择并非偶然——它提供了厂商中立的可观测性数据路由能力,避免了与单一供应商的 Langfuse 实例深度绑定。 4. 安全与合规的多层防御体系 文章详细描述了从输入清理到 Guardrails 的多层安全机制:输入端检测 prompt 注入攻击、输出端过滤 PII 和财务数据、Bedrock Guardrails 实现敏感信息过滤器。这不是单一安全措施,而是覆盖了 AI 系统在合规场景中的主要攻击面。值得注意的是,这些安全措施是在模型调用层面实现的,而非依赖应用层逻辑——这确保了即使模型更换,安全策略仍然一致。
实践启示¶
1. 在构建 RAG 系统时,先做"分块策略"评估 层级分块(hierarchical chunking)并非对所有文档类型都最优。对于高度结构化的文档(财务报表、监管函、合同),保留层级结构能显著提升检索质量;但对于非结构化文本(新闻、社交媒体),重叠的滑动窗口分块可能更有效。建议在系统设计阶段就用实际文档样本测试多种分块策略,用召回率作为评估指标,而非假设一种策略适用所有文档类型。 2. Query Expansion 的变体数量需要根据领域特点调优 文章使用 5 个变体是一个经验值,但不同领域的缩写词密度差异巨大。金融监管领域可能需要更多变体来覆盖各种缩写组合;而在医疗领域,同一术语可能有多种表达方式(如"心肌梗塞"、"心脏病发作"、"MI")。建议在上线前用领域特定的测试集评估 Expansion 数量对召回率的影响,找到准确率与成本的平衡点。 3. 可观测性数据应先于系统上线被定义 在 AI 系统上线后再添加可观测性,代价极高——需要重新追踪数据流、修改代码、重新运行测试。建议在系统设计阶段就定义清楚:每个 Span 应该记录哪些属性(延迟、token 消耗、检索结果数量、相关性分数)?这些数据如何关联到具体的业务指标(问询响应时间、合规通过率)?Langfuse 的文档中提到了"source document citations"作为透明度的基础——这个功能应该在第一版就实现,而非作为后期增强。 4. 防御 Prompt 注入应成为 AI 系统的标准 Checklist 项 文章中"检测到 Prompt 注入时返回固定回复"的设计反映了一种防御哲学:宁可拒答,不可误答。对于面向外部用户的 AI 系统,这应该是标准配置。但需要注意:检测本身可能产生误判(用户正常询问中包含类似攻击的词汇),需要有机制让用户申诉或重试。建议将这一防御机制设计为可配置的,允许在不同安全级别下调整阈值。
相关实体¶
- Aws 一周综述Amazon Bedrock Agentcore 付款适用于 Aws 的 Agent 工具套件等2026 年 5 月 11 日
- Integrating Aws Api Mcp Server With Amazon Quick Suite Using Amazon Bedrock Agen
- Using Amazon Bedrock Agentcore Openclaw Multi 5
- Using Amazon Bedrock Agentcore Openclaw Multi 2
- Introducing Claude Platform On Aws