Building AI agents for business support using Amazon Bedrock¶
Ch04.064 Building AI agents for business support using Amazon Bedrock¶
📊 Level ⭐⭐ | 19.3KB |
entities/building-ai-agents-for-business-support-using-amazon-bedrock.md
Building AI agents for business support using Amazon Bedrock¶
Summary: 使用Amazon Bedrock构建企业业务支持AI Agent的架构与实现指南
核心内容¶
Building AI agents for business support using Amazon Bedrock AgentCore¶
Developing AI agents for business support presents unique challenges that many organizations face when trying to automate routine HR tasks. Works Human Intelligence (WHI) develops, sells, and supports the integrated HR system "COMPANY" for major Japanese corporations and public interest corporations.
In this post, we share how the AWS Generative AI Innovation Center (GenAIIC) collaborated with Works Human Intelligence (WHI) to build two AI agents using Amazon Bedrock AgentCore. We discuss the challenges encountered and the solutions that reduced costs by up to 97% while improving operational efficiency.
Customers using HR systems must respond to numerous situations, such as organizational changes, revisions to HR systems, and updates to employee information. For organizations facing similar challenges with HR system operations, AI agents can significantly reduce workload and improve productivity. When WHI embarked on building products using AI agents, several challenges arose. To resolve these issues, we at GenAIIC worked closely with the WHI team to provide new perspectives and support in creating a high-quality product.The scope of this project covers two AI agents designed to support the work of operational departments. The Commuting Allowance Agent handles the approval of commuting allowance applications that arise during events like moving. The Browser Operation Agent "COMPANY" on behalf of the customer. We discuss the challenges and solutions for these two agents in the following sections.
Commuting allowance agent¶
This agent automates the approval of commuting allowance applications, which is a routine task that arises during events like employee relocations.
Challenge¶
The Commuting Allowance Agent supports the routine task of approving commuting allowance applications. WHI was already proceeding with a proof of concept (PoC) using LangGraph, Amazon Elastic Container Service (Amazon ECS), and AWS Fargate. However, because Amazon Bedrock AgentCore was released during development, the team began considering a migration. WHI wanted to work with us to build a solution with AgentCore that would realize an AI agent integrated with "COMPANY". Additionally, they wanted to migrate to an integrated multi-agent environment and implement authentication and authorization using AWS Fargate and Amazon Cognito, which were currently under development.
Solution overview¶
The Commuting Allowance Agent was being developed using LangGraph and Amazon ECS, but the team had concerns about the monolithic configuration where everything ran as the same Amazon ECS task. Therefore, we worked together to change the architecture so that sub-agents are launched individually on the AgentCore Runtime. Because multi-tenancy support was required, we decided to manage tenants using Amazon DynamoDB and Amazon Cognito to maintain the flexibility for WHI to build and manage it.
Architecture¶
Slack serves as the entry point for calling the Commuting Allowance Agent, so the system is designed to perform authentication at the time of the call, and then the appropriate sub-agents process the request.
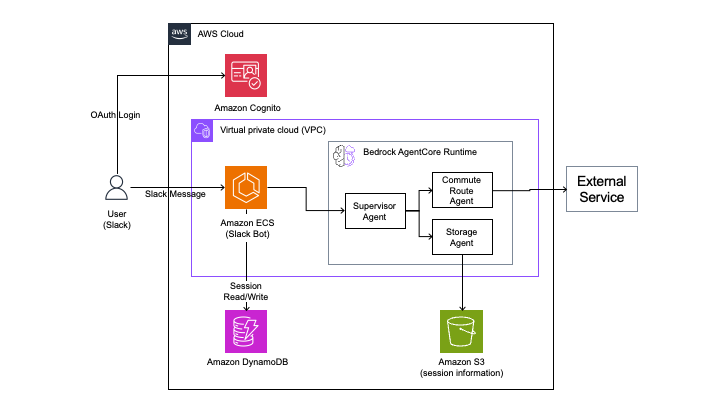
Results and impact¶
With AgentCore becoming generally available (GA) during the project, we were able to use it effectively. While the Commuting Allowance Agent continues to use LangGraph, we modified it so that sub-agents run on a separate Runtime. This change facilitates the future expansion of sub-agents. We are also considering changing the supervisor agent that bundles the sub-agents to Strands Agents in the future. Additionally, although WHI previously hosted Langfuse to check the status of agents, incurring operational costs, switching to AgentCore Observability has reduced this burden.
Browser operation agent¶
This agent uses a browser to access the HR system, check content, perform operations, and collect evidence on behalf of customers.
Challenge¶
The second agent uses a browser to access "COMPANY", checks the content, performs operations, and acquires evidence. Construction was proceeding with LangGraph and Playwright Model Context Protocol (MCP). The team confirmed an 88% reduction in browser operation tokens through the following approaches:
- Removing past unnecessary parts from the agent loop (conversation history between AI and Playwright MCP).
- Removing unnecessary parts for browser operation from the return values of Playwright MCP.
- Using prompt caching for the TOOL part.
However, because it relied on a proprietary implementation, the team faced challenges such as difficulty in migrating to Strands Agents. They were also considering methods to further reduce tokens. It was in this context that GenAIIC began collaborating with WHI.
Solution overview¶
We built the agent using Strands Agents. After testing several browser operation tools and confirming successful processing, we focused on reducing the number of tokens used. The workflow begins by searching for the optimal operation template from the knowledge base according to user instructions. Next, it replaces placeholders in the acquired template with information obtained from another knowledge base to create an operation manual. The agent then operates the browser based on this manual to check the current information. Based on the information obtained (such as CSV), it creates a change proposal and presents it to the user. Finally, upon user approval, it operates the browser again based on the change proposal to execute the changes.Although a basic workflow is defined, the agent can flexibly handle cases where user input is insufficient or where only partial tasks are performed, based on its own autonomous judgment.
Architecture¶
Access to "COMPANY" from the agent is restricted by IP address. To address this, we placed the AgentCore Runtime within a virtual private cloud (VPC) and configured it to access through a fixed IP address using a NAT gateway. We also built a knowledge base to store operation templates and auxiliary information for creating operation procedures. We used an Amazon Simple Storage Service (Amazon S3) bucket to save short-term information.
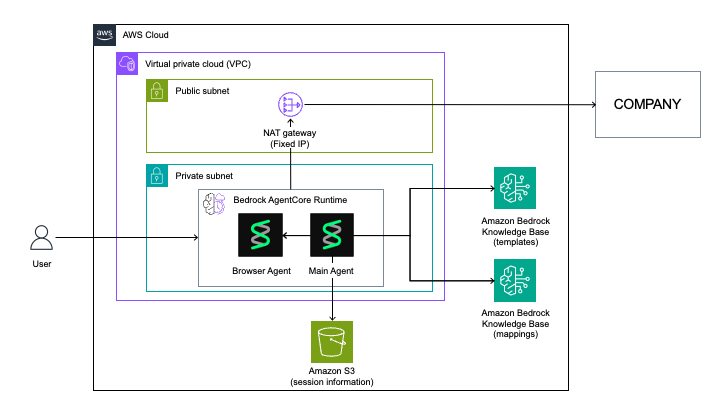
Results and impact¶
The Browser Operation Agent was built using Strands Agents. We tested browser operation tools including browser-use, Playwright, and fast playwright, confirming that fast playwright consumed the fewest tokens. In addition, by collaborating on improvements such as using Amazon Bedrock prompt caching and modifying system prompts, we succeeded in reducing the cost per process by up to 97%.The main improvement measures were as follows:
- Using prompt caching for user messages: Enabled Amazon Bedrock's prompt caching feature ($14.5 -> $2.1).
- Optimizing agent behavior: Improved sub-agent prompts to reduce unnecessary operations ($2.1 -> $1.0).
- Changing models: Changed the model from Claude Sonnet 4.5 to Haiku 4.5 ($1.0 -> $0.4).
Through these improvements, we optimized costs while successfully handling more complex tasks. These include scenarios that execute multiple changes in succession or scenarios where the agent asks the human questions when instructions are ambiguous.
关键要点¶
- 来源: AWS Machine Learning Blog
- 技术栈: Amazon Bedrock, Amazon Quick
- 应用场景: 企业可观测性、业务支持自动化、云端支持
深度分析¶
1. LangGraph 到 Strands Agents 的迁移动因与多智能体架构演进¶
从 LangGraph 迁移到 Strands Agents 的决策并非单纯追逐新框架,而是有其深层技术动因。
LangGraph 的单体式配置——所有逻辑运行在同一个 Amazon ECS Task 中——在业务复杂度增长时成为瓶颈。当子智能体数量增加时,单体架构导致扩展困难、隔离性差、以及运维复杂度线性膨胀。迁移的核心目标是将子智能体独立部署到 AgentCore Runtime,使每个子智能体成为独立扩展单元。
更关键的驱动因素是供应商锁定问题。使用 LangGraph 配合专有实现(proprietary implementation)导致团队在尝试迁移到 Strands Agents 时遇到显著困难——这不是框架本身的问题,而是抽象层缺失导致的耦合。多智能体系统应从设计初期就考虑Multi Agent Collaboration Patterns的标准化,使核心业务逻辑与底层编排框架解耦。
2. 成本削减 97% 的三层优化框架¶
成本优化并非单一手段实现,而是跨越三个技术层次的系统性工程。
第一层:提示词缓存 — 通过 Bedrock 的 Prompt Caching 功能,识别用户消息中可复用的上下文模式,将这部分成本从 $14.5 降至 $2.1,降幅 86%。提示词缓存的本质是减少重复计算,对抗大模型推理中的上下文冗余。
第二层:智能体行为精简 — 通过重写子智能体提示词(sub-agent prompts),减少不必要的操作步骤,将成本从 $2.1 降至 $1.0。这属于Inference Optimization的范畴——在模型调用层面而非模型选择层面的优化。
第三层:模型分层 — 将 Claude Sonnet 4.5 替换为 Haiku 4.5,将成本从 $1.0 降至 $0.4。这反映了Inference Optimization中"任务特化模型选择"的核心原则:简单分类/路由任务不需要大模型的推理能力。97% 的总体降幅中,模型替换贡献了约 60%。
三层优化的递进关系揭示了一个重要的 Agent 成本设计原则:先优化提示词和流程,再考虑模型降级。模型降级是最简单但也可能引入质量风险的手段,应在其他优化充分实施后再评估。
3. 浏览器操作智能体的稳定性挑战¶
浏览器操作智能体面临的核心挑战不是"如何操作",而是"如何保证长时间运行的稳定性"。
88% 的 token 削减来自三个关键技术手段:去除对话历史中不必要的部分(conversation history between AI and Playwright MCP)、精简 Playwright MCP 返回值、以及对 TOOL 部分使用提示词缓存。第一个措施本质上是对Agent Memory Lifecycle Philosophies的简化应用——浏览器操作任务不需要跨会话的完整对话历史。
但稳定性问题需要超越"削减 token"的视角来审视。对于需要长时间运行的浏览器操作任务,关键设计包括:操作超时检测与自动重试、页面元素变更的适应机制、以及必要时的人类介入通道。Browser Operation Agent 的"三步骤工作流"(搜索模板→生成手册→执行操作)之所以值得借鉴,正是因为它将复杂的长任务分解为可管理、可监控的阶段。
4. 企业级 Agent 部署的网络隔离与访问控制模式¶
HR 系统等企业核心系统通常有严格的 IP 白名单要求,这对 AI Agent 的部署架构提出挑战。
解决方案是在 VPC 内部署 AgentCore Runtime,并通过 NAT 网关使用固定 IP 访问外部被限制的系统。这是一个经典的企业Enterprise Ai Adoption模式:安全约束(IP 白名单)不应成为障碍,而应被视为架构设计的输入条件。
配合这一模式的知识库架构(存放操作模板和辅助信息)本质上是一个Retrieval Augmented Generation Rag系统——知识库的内容质量直接决定了 Agent 操作手册的质量,进而影响操作成功率。
5. 多租户隔离与可观测性:企业级 Agent 平台的两大基础设施¶
Commuting Allowance Agent 案例揭示了企业级 Agent 平台建设的两个关键技术决策。
多租户隔离 — 使用 Amazon DynamoDB + Amazon Cognito 管理租户,实现租户间的数据隔离和认证授权。这一选择的关键考量是"保持灵活性"——让 WHI 能够自主构建和管理租户系统,而不是被某个锁定方案约束。这呼应了Agent Backend Unification的主题:统一的后端抽象支撑上层的差异化业务逻辑。
可观测性替换 — 从自托管的 Langfuse 迁移到 AgentCore Observability,消除了运营负担(服务器维护、监控配置等),同时获得了更集成的日志和追踪能力。这是"用托管服务替代自运维"思路的典型案例,在 AI Agent 平台建设中具有普遍参考价值。
实践启示¶
1. 模型分层降本:从 Haiku 到 Sonnet,按任务复杂度选型¶
成本削减 97% 的核心手段是模型降级($14.5→$2.1→$1.0→$0.4),但这并非简单的"用便宜模型替代贵模型"。
关键原则是任务-模型匹配度:简单路由和分类任务(如判断用户请求类型、提取结构化字段)交给 Haiku;复杂推理和决策任务(如生成变更提案、处理模糊指令)留给 Sonnet/Claude。实践中建议为每个 Agent 任务建立明确的能力矩阵,标注哪些步骤必须用大模型、哪些可以用小模型替代。
2. 浏览器操作 Agent 的三步骤工作流设计¶
Browser Operation Agent 的工作流设计值得直接复用:搜索最优操作模板→填充模板占位符生成操作手册→浏览器执行操作。
这一模式的普适性在于它将知识密集型操作(模板搜索和选择)与执行密集型操作(浏览器操作)分离,使两者可以独立优化。构建类似 Agent 时,应先识别哪些步骤是知识检索型的、哪些是动作执行型的,再为各类型设计专门的优化策略(如知识库的召回精度 vs 浏览器操作的速度和稳定性)。
3. 提示词缓存的适用条件与实施边界¶
提示词缓存在本案例中实现了 $14.5→$2.1 的降幅,但它的适用有明确条件:用户消息中存在可识别的重复上下文模式。
对于业务支持场景,用户的请求往往有稳定的结构(如"帮我查一下员工XXX的信息"),这使得提示词缓存的价值得以发挥。但在请求高度个性化、每句话都不重复的场景中(如开放式对话),缓存效果会大打折扣。实施前应评估请求的重复度,并监控缓存命中率。
4. 访问受限系统时的固定 IP 方案¶
当目标系统要求 IP 白名单时,在 VPC 内部署 AgentCore Runtime 并通过 NAT 网关使用固定 IP 是标准解法。
这一方案的工程要点包括:VPC 子网规划(需考虑 Agent 数量扩展)、NAT 网关的可用区冗余、以及与目标系统白名单的协调。在设计阶段就应将网络约束纳入考量,而不是在部署时被迫调整架构。
5. 多租户隔离的 DynamoDB + Cognito 组合拳¶
DynamoDB + Cognito 的组合提供了企业级多租户隔离的参考实现。
DynamoDB 的优势在于弹性扩展和细粒度的分区键设计,适合租户数据的水平扩展;Cognito 则处理身份认证和授权,使业务逻辑专注于租户隔离而非认证实现。这一组合的选择提示我们:在 Agent 平台建设中,身份认证和数据隔离应作为基础设施能力提前规划,而不是作为后期补丁添加。
相关实体¶
- Amazon Bedrock Agentcore Gateway Mcp Extension
- Build Ai Agents For Business Intelligence With Amazon Bedrock Agentcore
- Building Multi Tenant Agents With Amazon Bedrock Agentcore
- Secure Ai Agents Policy Lambda Interceptors Aws
- Amazon Bedrock Agentic Payments Guardrails
→ 原文存档