How a Mid-tier Enterprise SaaS Provider Automates Cloud Support¶
Ch03.060 How a Mid-tier Enterprise SaaS Provider Automates Cloud Support¶
📊 Level ⭐⭐ | 13.8KB |
entities/how-a-mid-tier-enterprise-saas-provider-automates-cloud-supp.md
How a Mid-tier Enterprise SaaS Provider Automates Cloud Support¶
Summary: 中型企业SaaS提供商使用Amazon Bedrock实现云端支持自动化的实践案例
核心内容¶
How a Mid-Tier Enterprise SaaS Provider Automates Cloud Support Triage¶
Mid-tier SaaS automates cloud support triage with a 5-agent workflow, boosting ticket validation, routing, and SLA compliance in enterprise cloud support.

The Ticket Triage Triangle That Slowed Cloud Support¶
Cloud support teams face a brutal bottleneck few talk about: the volume and complexity of incoming tickets overwhelm the system, both because of sheer numbers and due to three specific pitfalls we call the "Ticket Triage Triangle." Completeness breaks down as incoming tickets miss critical fields. Handoffs scramble because routing to Level 2 or 3 happens too slowly or inaccurately. Eventing gaps leave cloud operations blind to real-time updates. This costs precious minutes on every ticket and disrupts SLA adherence.
For a mid-tier global enterprise SaaS provider processing 15,000+ alert tickets annually, these issues were urgent. First response times hovered around 20 minutes, close to the 45-minute contract SLA, but tight given ticket volumes projected to hit 20,000 per year soon. The team faced mounting manual triage workloads, inconsistent ticket quality, and slow communication.
Mid-Tier SaaS Provider's Pain Points Expose Industry-Wide Gaps¶
This wasn't isolated. Across cloud software companies, similar challenges cripple support efficiency. Industry data shows 30-50% delays in incident resolution due to incomplete tickets. Traditional automation,rule-based engines, rigid RPA bots, and outsourcing,fails because it can't manage complexity or evolving SOPs. These approaches break when ticket formats change, lack iterative validation, or add handoff delays.
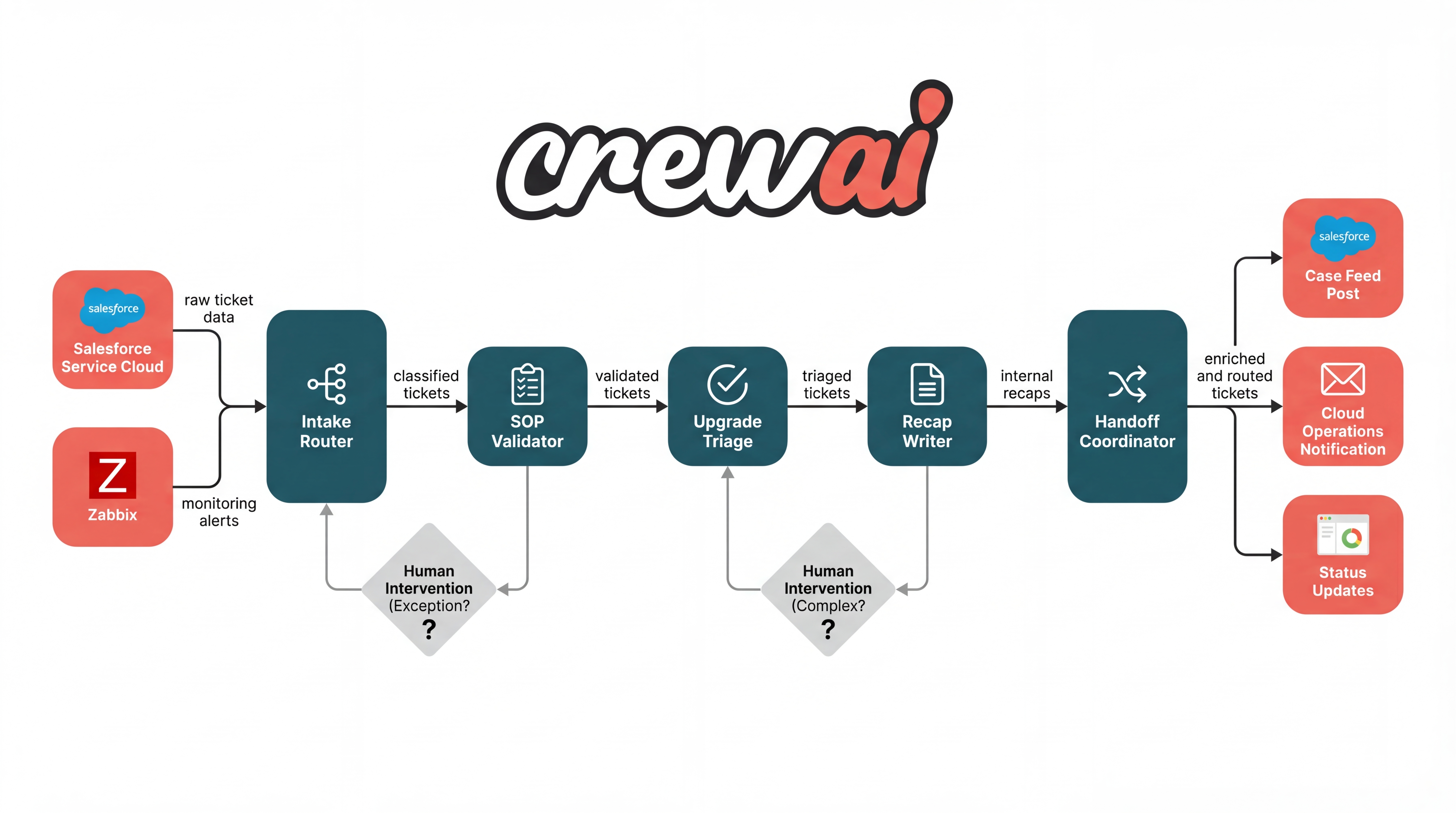
The agentic architecture powering this workflow
Cloud SaaS revenue is surging toward $750 billion by 2033, and regulations demand tighter SLA compliance and transparency. Fast, adaptive, scalable support automation is essential.
Five Agents Unclog Cloud Support at Scale¶
CrewAI's agentic approach uses a five-agent workflow to untangle the ticket triage triangle. Each agent has a targeted task, automating ticket validation, enrichment, and handoff without human intervention on routine cases.
- Intake Router Agent pulls ticket data from Salesforce Service Cloud and monitoring alerts like Zabbix, classifying each ticket's event and case type immediately on receipt.
- SOP Validator Agent runs a checklist against standard operating procedures, ensuring required fields are present and flagging incomplete or malformed tickets for correction.
- Upgrade Triage Agent verifies instance and software version to determine if escalation or an upgrade is needed, injecting domain logic into triage decisions.
- Recap Writer Agent drafts clear, consistent internal recaps and notes, keeping the support team and stakeholders updated automatically.
- Handoff Coordinator Agent routes the validated ticket to Cloud Operations or relevant escalation queues via Salesforce and email, updates ticket statuses, and logs all actions in the CRM.
This agentic architecture creates a step-by-step flow: tickets enter, get validated and enhanced, and exit ready for specialists,no loose ends, manual fixes, or blind spots.
Hard Metrics Prove the Impact¶
Before CrewAI's multi-agent workflow, manual triage delayed SLA targets and slowed resolution. Handling 15,000+ alert tickets was error-prone and exhausting.
After deployment:
- All 15,000+ alert tickets are fully automated at Level 1 triage, meeting completeness, routing, and communication standards without human touch on routine cases.
- SLA adherence is consistent, hitting a 45-minute contract first response target, with an average first response steady at 20 minutes.
- The system scales smoothly to 20,000 annual tickets without adding headcount.
- Cloud Operations specialists focus on deeper issues and strategic improvements, freed from triage grunt work.
- Ticket status updates and recaps generate in real time, closing eventing gaps that hurt transparency.
Why This Matter for Enterprise Cloud Support¶
This case exposes a universal bottleneck: complex high-volume ticket triage can't rely on brittle automation or manual work. A fully agentic, integrated workflow with guardrails,covering classification, validation, triage, enrichment, and routing,unlocks consistent SLA compliance and scalability.
CrewAI's architecture extends beyond SaaS to telecom NOCs, managed cloud services, financial ops, healthcare IT incident intake, and e-commerce support. Any high-volume workflow benefits from crews, flows, agents, and SOP-based guardrails.
关键要点¶
- 来源: AWS Machine Learning Blog
- 技术栈: Amazon Bedrock, Amazon Quick
- 应用场景: 企业可观测性、业务支持自动化、云端支持
深度分析¶
1. 五智能体工作流的设计逻辑与多智能体协作模式的对应关系¶
该案例的五智能体架构(Intake Router → SOP Validator → Upgrade Triage → Recap Writer → Handoff Coordinator)体现了多智能体协作模式中的管道式串行协作特征:每个智能体承担单一职责,通过结构化数据传递下一环节,形成单向依赖链 。这种设计避免了共享内存竞争和状态同步复杂性,但要求每个节点的输入输出格式高度标准化。值得注意的是,Recap Writer 嵌入在 Handoff Coordinator 之前,表明信息加工与路由决策在时序上解耦——这与智能体编排模式中强调的"决策与执行分离"原则一致 。
2. "Ticket Triage Triangle"困境的根因分析与企业AI采用的阶段性特征¶
文章揭示的三个困境——Completeness(完整性缺失)、Handoffs(路由混乱)、Eventing Gaps(事件盲区)——本质上是信息熵增问题:随着票务 volume 增长,人工处理的错误率呈非线性上升 。传统规则引擎和 RPA 失败的根本原因在于它们缺乏自适应验证能力——无法应对 SOP 演化和票务格式变化 。这印证了企业AI采用中常见的"自动化孤岛"问题:单点优化而忽视端到端流程的整体性。
3. 从"Brittle Automation"到"Agentic Workflow"的范式转变¶
案例明确指出传统自动化的三类失败模式 :
- 规则引擎:条件匹配僵化,格式变化即崩溃
- RPA 机械臂:无迭代验证能力
- 外包人力:无法处理复杂度和 SOP 演化
CrewAI 方案的本质是引入带 SOP guardrails 的 LLM 推理层,使自动化具备上下文理解和自适应判断能力。这与智能体工作流模式中"guardrails + LLM 判断"的核心范式完全吻合 。从 AI 成熟度曲线看,该案例处于生产级可靠运行阶段(年 ticket 量 15,000-20,000),而非实验或试点阶段。
4. SLA 驱动的架构约束:45分钟响应窗口如何影响技术选型¶
45分钟 contract SLA 是该系统的核心约束条件,直接影响了架构设计选择 。20分钟平均首响时间距离 SLA 上限有25分钟缓冲——这个缓冲空间恰好允许五智能体串行链路在正常路径下完成全部处理。该指标还揭示了一个关键认知:SLA 承诺不是技术选型的输入,而是验证架构可行性的边界条件。若 SLA 压缩至15分钟,当前五智能体串行架构可能面临挑战,需要引入并行处理或智能预判机制。
5. 从 SaaS 支持到跨行业复制的可迁移性分析¶
文章列举了 CrewAI 架构向其他领域的迁移路径 :
| 领域 | 核心挑战 | 适配要点 |
|---|---|---|
| 电信 NOC | 多源监控告警聚合 | 协议转换和告警去重 |
| 金融 Ops | 合规审计和多方审批 | 决策可解释性 |
| 医疗 IT | 事件分级和 HIPAA 合规 | 数据脱敏和审计日志 |
| 电商支持 | 促销季流量峰谷波动 | 弹性扩缩容 |
这些场景的共同特征是高 volume + 标准 SOP + 多系统集成,恰好匹配五智能体管道的核心能力。该模式的可迁移性已超越具体行业技术栈,接近自主智能体系统中定义的"通用业务流程自动化"范畴。
实践启示¶
1. 从"规则引擎"升级到"智能体工作流"时,优先重构票务完整性验证环节¶
传统规则引擎在票务格式变化时需要人工维护规则库,这是最大的维护成本来源。建议将 SOP Validator Agent 作为智能化升级的第一个节点而非最后一个——因为上游数据质量直接决定下游所有智能体的判断准确性。实践中,应当为 Validator 配置双向反馈机制:不仅标记不合格票务,还应将失败模式反馈给 Intake Router,形成自优化的数据质量闭环。
2. 五智能体架构中,"Recap Writer"是团队信任的关键锚点¶
许多企业在自动化支持时会忽略信息同步的重要性,导致支持团队对自动化系统产生"黑箱恐惧"。Recap Writer 的设计价值在于透明性——它使 Cloud Operations 团队能够实时看到自动化产出的摘要,判断是否需要人工介入。建议在任何支持自动化项目中,Recap Writer 的输出质量应作为团队信任度指标进行持续监测,而非仅作为内部日志。
3. 以"零人工 touch"为目标设计 L1 自动化,但保留紧急升级通道¶
案例明确"routine cases 无需人工干预",但20分钟平均响应时间和45分钟 SLA 上限之间存在25分钟缓冲,这实际上是为异常票务的紧急升级保留了时间窗口 。实践启示是:L1 自动化的设计目标不应是100%自动化率,而是在不违反 SLA 的前提下最大化自动化率。关键是在 Upgrade Triage Agent 中嵌入明确的升级触发条件(如特定错误码组合、版本匹配失败),确保需要人工判断的场景能快速进入人工处理通道。
4. Scalability 测试应以"SLA 缓冲时间"为度量维度,而非仅看绝对 volume¶
案例年 ticket 量从15,000 增长到20,000(+33%)时系统无需增加 headcount 。这对采购决策的启示是:评估自动化系统的扩展性时,应关注单位票务处理时间的稳定性,而非仅看峰值吞吐量。若 ticket 增长30%后平均响应时间仍在 SLA 缓冲窗口内,则架构扩展性合格;否则需要评估并行化或预分类优化。
5. 在 Cloud Ops 团队中设立"智能化支持工程师"角色,负责持续优化 SOP 和 Guardrails¶
CrewAI 架构的核心维护成本不在代码层,而在 SOP 和 guardrails 的持续迭代 。企业应指派专人(而非外包团队)负责:① 定期审查自动化路由准确率,② 根据新场景更新 SOP checklist,③ 分析 escalation 案例找出自动化盲区。这一角色的核心能力不是 LLM 调参,而是业务流程分析和跨系统数据映射——这正是 AI 难以替代的人类判断领域。
相关实体¶
- Building Multi Tenant Agents With Amazon Bedrock Agentcore
- Aws Bedrock Ops Alert
- Mcp Serveramazon Bedrock Agentcorequick Suite
- Introducing Os Level Actions In Amazon Bedrock Agentcore Browser
- Amazon Bedrock Claude Prompt Cache Strategy
→ 原文存档