GLM-5.2: Built for Long-Horizon Tasks¶
Ch01.633 GLM-5.2: Built for Long-Horizon Tasks¶
📊 Level ⭐⭐ | 5.2KB |
entities/z-glm-5.2.md
GLM-5.2: Built for Long-Horizon Tasks¶
背景:从 newsletter candidates 提取,2026-06-18 v×c=64 stars=4 通过评分门槛。 URL: https://z.ai/blog/glm-5.2
核心要点¶
Markdown Content: We're introducing GLM-5.2, our latest flagship model for long-horizon tasks. It marks a substantial leap in long-horizon task capability over its predecessor GLM-5.1 and, for the first time, delivers that capability on a solid 1M-token context. GLM-5.2's new capabilities include:
- Solid 1M Context: A solid 1M-token context that stably sustains long-horizon work
- Advanced Coding with Flexible Effort: Stronger coding capabilities with multiple thinking effort levels to balance performance and latency
- Improved Architecture: We propose IndexShare, which reuses the same indexer across every four sparse attention layers, reducing per-token FLOPs by 2.9× at a 1M context length. We also improve GLM-5.2’s MTP layer for speculative decoding, increasing the acceptance length by up to 20%
- Pure Open: An MIT open-source license — no regional limits, technical access without borders
Supporting long-horizon tasks starts with making long context engineering-usable: the model must maintain quality across long, messy coding-agent trajectories, not just accept more tokens. A 1M context is easy to claim, but much harder to keep reliable under real engineering pressure. To this end, we substantially expanded 1M-context training for coding-agent scenarios, covering large-scale implementation, automated research, performance optimization, and complex debugging. The result is a long-context system that is not only wide in scope, but solid in execution: a practical substrate for sustained engineering work.
This capability is reflected in GLM-5.2's performance on three long-horizon coding benchmarks. FrontierSWE measures whether an agent can complete open-ended technical projects at the scale of hours to tens of hours, spanning systems optimization, large-scale code construction, and applied ML research. On this benchmark, GLM-5.2 trails Opus 4.8 by only 1%, while edging out GPT-5.5 by 1% and Opus 4.7 by 11%. On PostTrainBench, where each agent is given an H100 GPU and evaluated by how much it can improve small models through post-training, GLM-5.2 outperforms both Opus 4.7 and GPT-5.5, ranking second only to Opus 4.8. On SWE-Marathon, an ultra-long-horizon software engineering benchmark covering tasks such as building compilers, optimizing kernels, and developing production-grade services, GLM-5.2 still has room to grow, trailing Opus 4.8 by 13% while remaining second only to the Opus series. Across all three benchmarks, GLM-5.2 is the highest-ranked open-source model, showing that its 1M context has translated into practical long-horizon delivery capability.
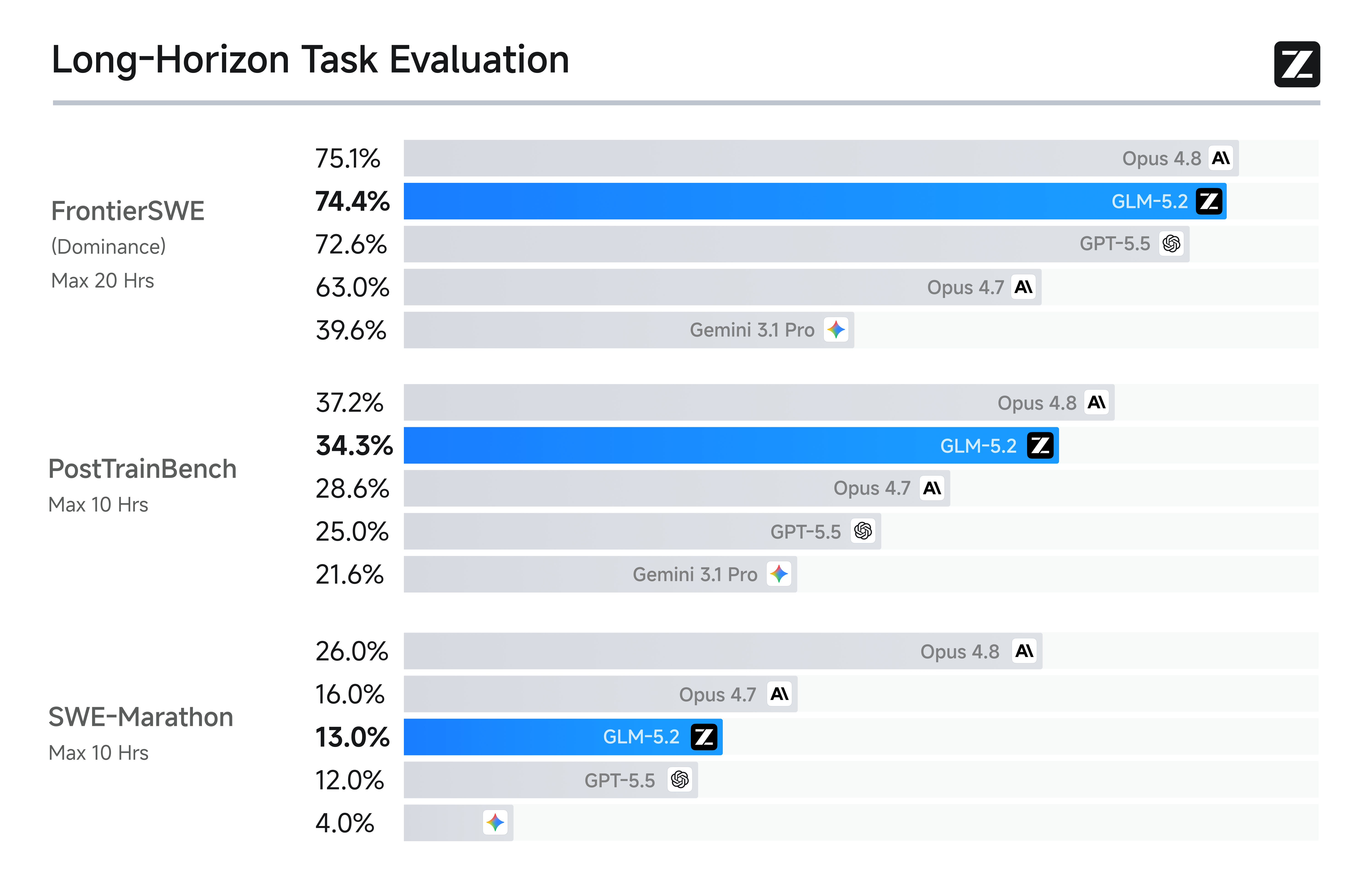
On standard coding benchmarks, GLM-5.2 is the strongest open-source model,
评估理由¶
- value=8: Genuinely technical: describes IndexShare sparse attention architecture (2.9× FLOPs reduction at 1M context), MTP layer improvements for speculative decoding (20% acceptance length increase), and deta
- confidence=8: 详细程度与来源可信度
- stars=4: 独特技术洞察评分
第二来源:HuggingFace Model Card¶
- 同样的 IndexShare 稀疏注意力架构、MTP 层改进
- 模型权重与推理配置
相关¶
Interconnects 分析视角(Nathan Lambert)¶
来源:Interconnects newsletter,2026-06-22
为什么是"step change"¶
Nathan Lambert 认为 GLM-5.2 代表了开源 agent 模型的质变: - Long-horizon task 首次在开源中可靠实现:1M context 不仅是数字,而是在真实工程压力下保持稳定 - 对 open agents 生态的影响:首次让开源社区能构建需要长时间运行的 agent(如 multi-step coding、automated research) - IndexShare 架构创新:每 4 层 sparse attention 共享 indexer,1M context 下 FLOPs 降低 2.9×
与闭源模型的竞争定位¶
文章分析了 GLM-5.2 在 open vs closed 模型竞争格局中的位置: - 开源模型首次在 long-horizon agent 任务上接近闭源水平 - MIT 许可证消除了区域限制,对全球开发者开放 - 对 Anthropic/OpenAI 的 agent 生态构成直接竞争
→ 原文存档