Latest open artifacts (#20): New orgs! New types of models! With Nemotron Super, Sarvam, Cohere Transcribe, & others¶
Ch01.204 Latest open artifacts (#20): New orgs! New types of models! With Nemotron Super, Sarvam, Cohere Transcribe, & others¶
📊 Level ⭐⭐ | 17.5KB |
entities/interconnects-latest-open-artifacts-20-new-orgs-new-types-of-models-with-nemotron-super-sarvam.md
type: entity - raw/articles/latest-open-artifacts-20-new-orgs-new-types-of-models-with-n tags: [interconnects] - article - open-models - model-zoo title: 'Latest open artifacts (#20): New orgs! New types of models! With Nemotron Super, Sarvam, Cohere Transcribe, & others' type: entity updated: '2026-06-08'
type: entity
Latest open artifacts (#20): New orgs! New types of models! With Nemotron Super, Sarvam, Cohere Transcribe, & others¶
相关实体¶
- Latest Open Artifacts 21 Open Model Bonanza Gemma 4 Deepseek
- Interconnects What Comes Next With Open Models
- Latest Open Artifacts 19 Qwen Glm Minimax Interconnects
- U Of T Ai Worm Cleverhans Papernot 2026
- How Far Behind Are Open Models 2026
→ 原文存档
Latest open artifacts (#20): New orgs! New types of models! With Nemotron Super, Sarvam, Cohere Transcribe, & others¶
This Artifacts Log post is unusual in how many diverse, quirky models there are across use-cases and modalities. Normally these model roundups are dominated by big models from the likes of Qwen, DeepSeek, Kimi, etc. There are models for all sorts of different use-cases in this post, from optical character recognition (OCR), RAG search, audio transcription, computer-use, code-editing, math theorem proving, and more. The artifacts covered this month also come from a much broader list of open model builders.
This gives us a lot of hope for the future of open models, where we see the need for domain-specific, cheap models as being crucial tools to complement the strongest, closed agents. When the top few models get the headlines, this vast, industry-scale tinkering can easily be forgotten. Reading this post gives a technically grounded, broad coverage of the many directions the industry is pushing specific models for. Expect more like this!
To encourage people to take a look at the diversity of models in this issue, the core part of the update is not paywalled. An otherwise quiet month at the top end of open models really delivered.
Artifacts Log¶
Our Picks¶
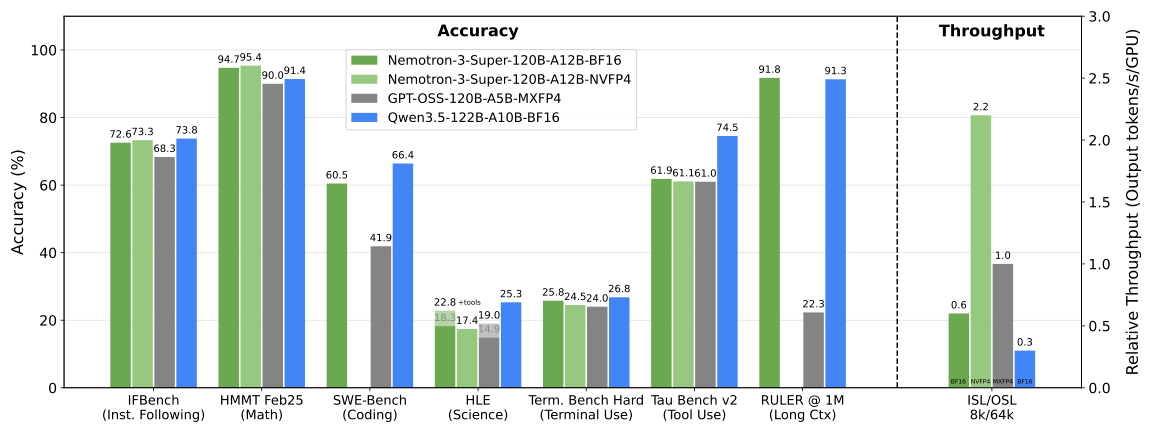
- NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4 by nvidia: The long-awaited mid-sized model from NVIDIA is finally here: 120B total params with 12B active, a 1M context window, and support for multiple popular languages. Furthermore, the model is based on LatentMoE and uses NVFP4 during pre-training, which is a first for open models. Like other things from NVIDIA, it comes with an in-depth tech report plus pre-training and post-training datasets, with the vast majority of the data being openly released.
{kind=link}
-
cohere-transcribe-03-2026 by CohereLabs: A speech-to-text model by Cohere based on the conformer architecture, similar to NVIDIA's Parakeet. It features 14 different languages, including some AIPAC languages and Arabic. Performance-wise, Cohere claims it beats similarly sized open and closed models. To top it all off: The model is released under Apache 2.0! Previous open models by Cohere were released under a non-commercial license.
-
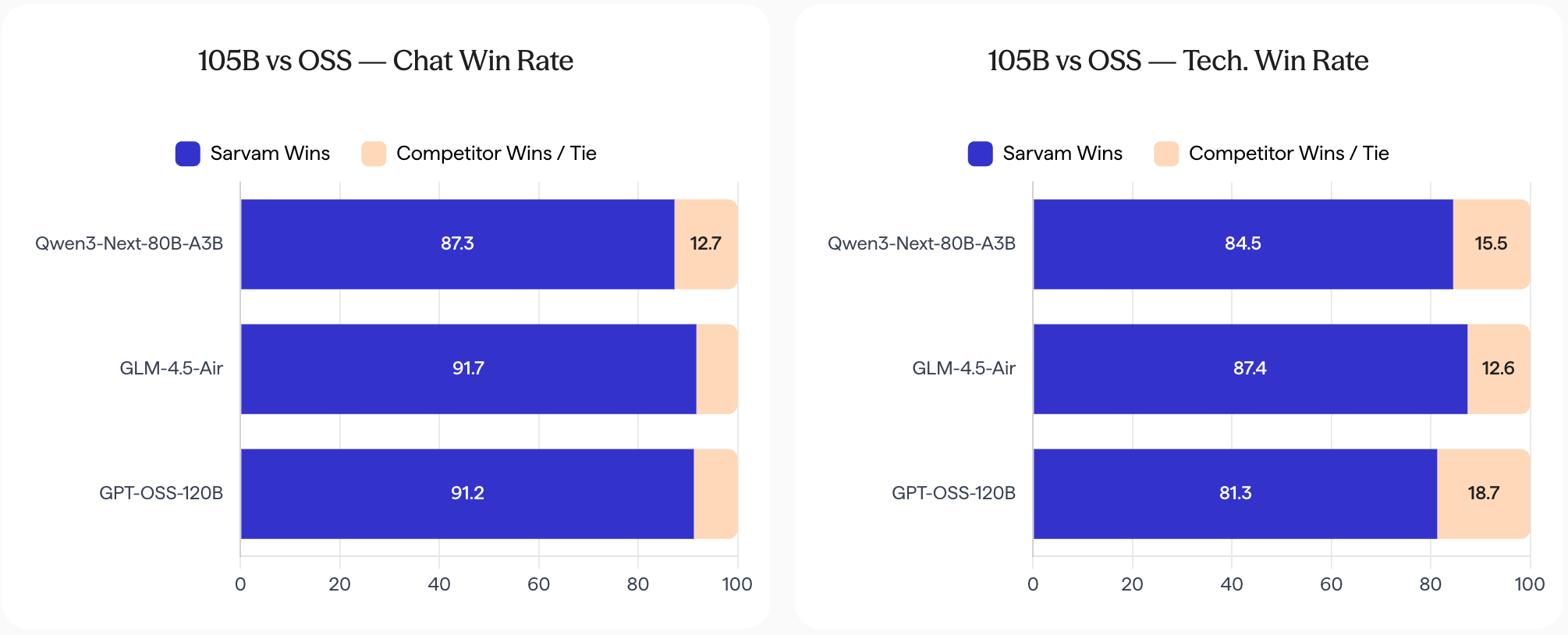
sarvam-105b by sarvamai: The Indian startup Sarvam, which trained open models in the past, has scaled up everything for its new flagship models in terms of dataset size (12-16T tokens) and model size (30B-A2B, 105B-10A). As a result, they come close to or even surpass a lot of open models with similar sizes. The release also shows why sovereign AI is so important, something that few other countries have internalized yet: In comparison with SOTA open models, the Sarvam models are vastly more preferred in Indic languages.
{kind=link}
-
Mistral-Small-4-119B-2603 by mistralai: A 119B-A7B model by Mistral, combining their previous model generations into one as a hybrid reasoning model with coding abilities.
-
zeta-2 by zed-industries: The open source code editor Zed has released their edit prediction model openly in the past, which we featured a year ago. While the previous version was based on open data, the new version, based on Seed-Coder-8B, is trained on open source code by users who explicitly opted into data collection.
Models¶
General Purpose¶
-
gpt-oss-puzzle-88B by nvidia: A pruned expert version of GPT OSS 120B. It also replaces some global attention layers with window attention. Puzzle is "a post-training neural architecture search (NAS) framework, with the goal of significantly improving inference efficiency for reasoning-heavy workloads while maintaining or improving accuracy across reasoning budgets."
-
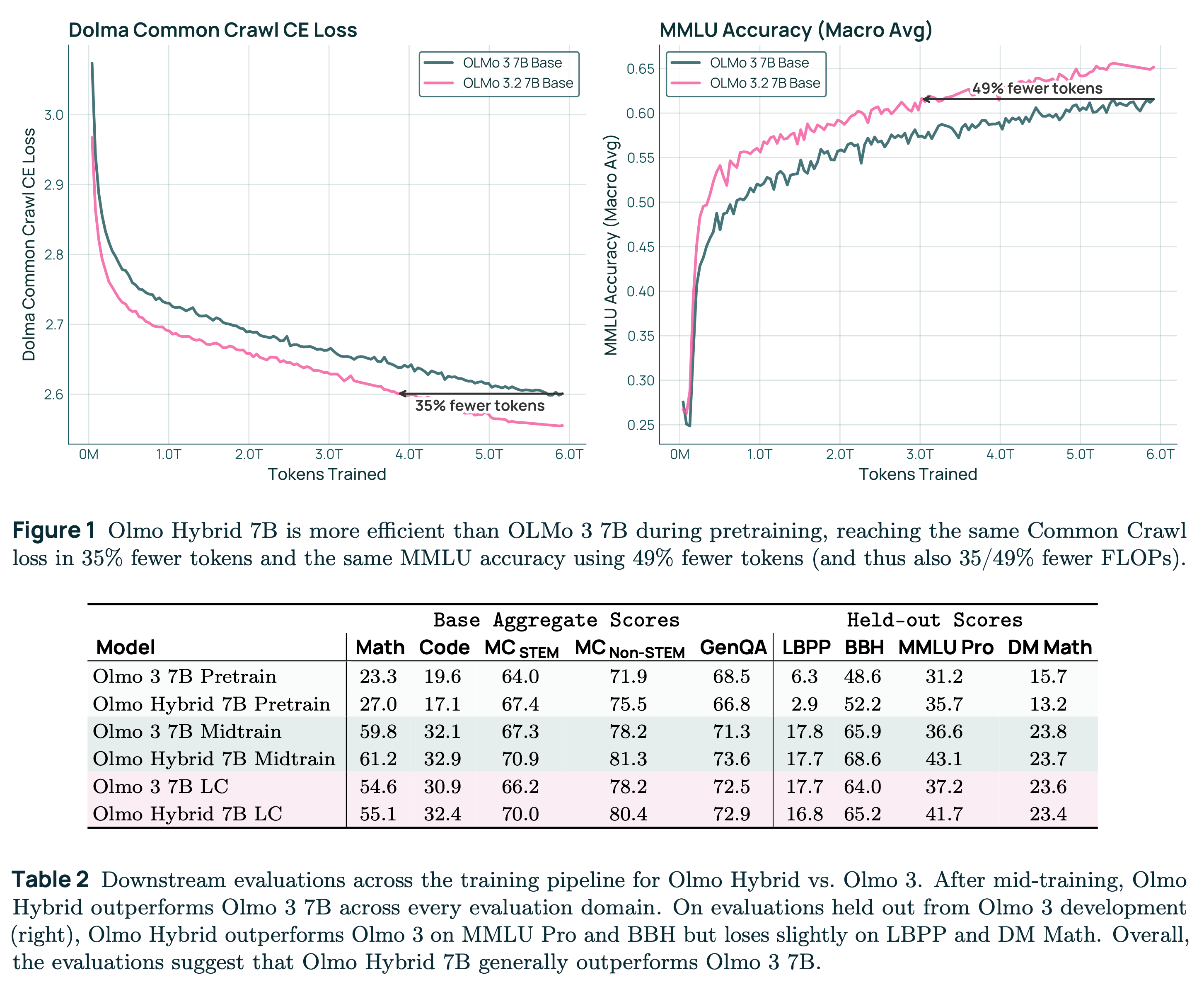
Olmo-Hybrid-7B by allenai: A hybrid attention + GDN (gated DeltaNet) model. See our blog post for more insights about the architecture and its challenges.
{kind=link}
- NVIDIA-Nemotron-3-Nano-4B-BF16 by nvidia: A compressed version of NVIDIA-Nemotron-Nano-9B-v2, which itself is a compressed version of NVIDIA-Nemotron-Nano-12B-v2. Nvidia has been pushing this direction more than anyone else with open models.
Multimodal¶
-
Yuan3.0-Ultra by YuanLabAI: A 1T multimodal model by the relatively unknown Yuan Lab. They pre-trained a 1.5T model on 2.2T tokens and subsequently pruned experts with a new technique, outlined in the tech report.
-
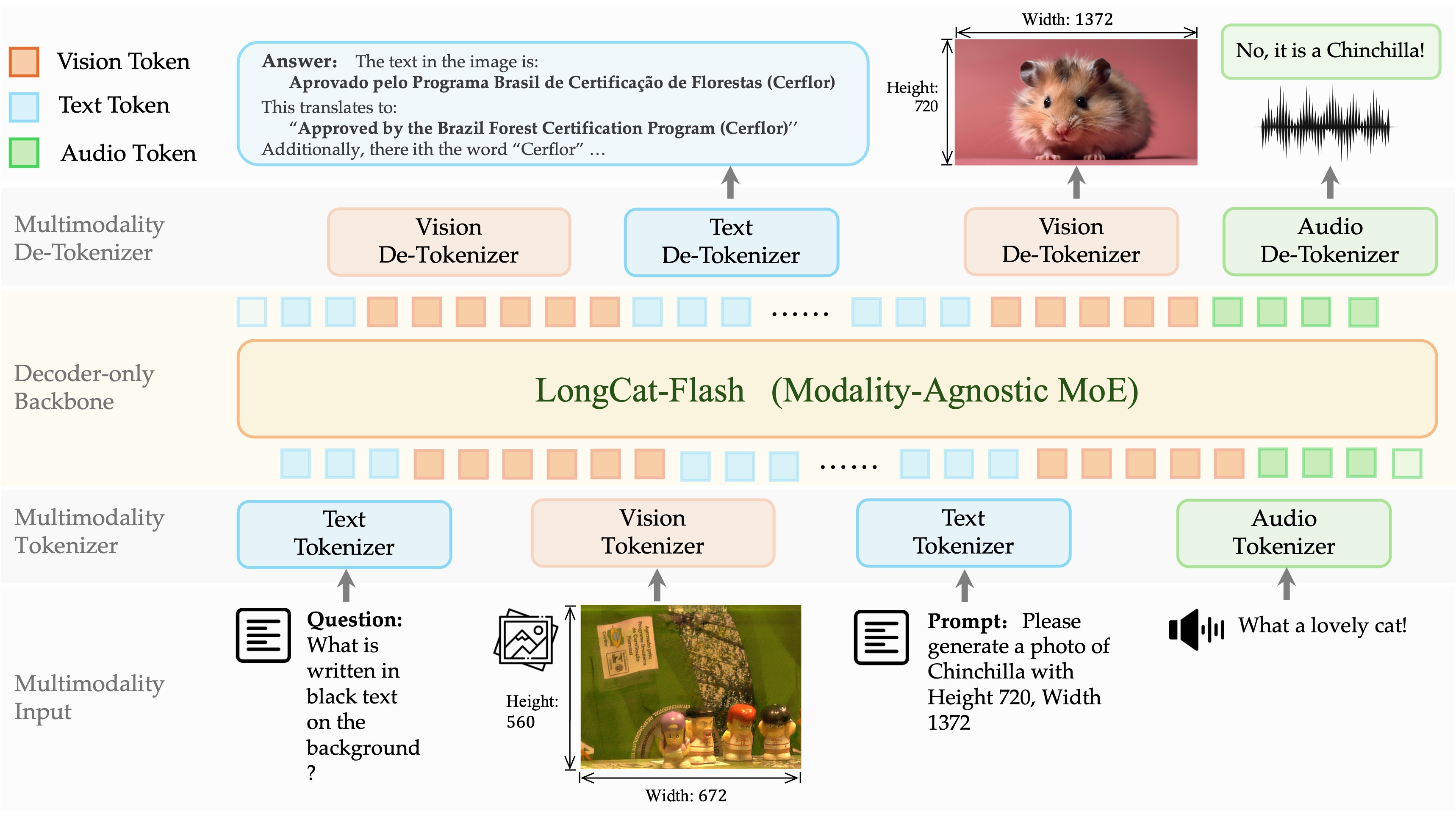
LongCat-Next by meituan-longcat: A multimodal model which can process text, vision, and audio as both inputs and outputs.
{kind=link}
-
granite-4.0-1b-speech by ibm-granite: A small speech-to-text model supporting six languages. It also supports the generation of English audio for translation.
-
Phi-4-reasoning-vision-15B by microsoft: A Phi model which uses the SigLIP-2 vision encoder.
Special Purpose¶
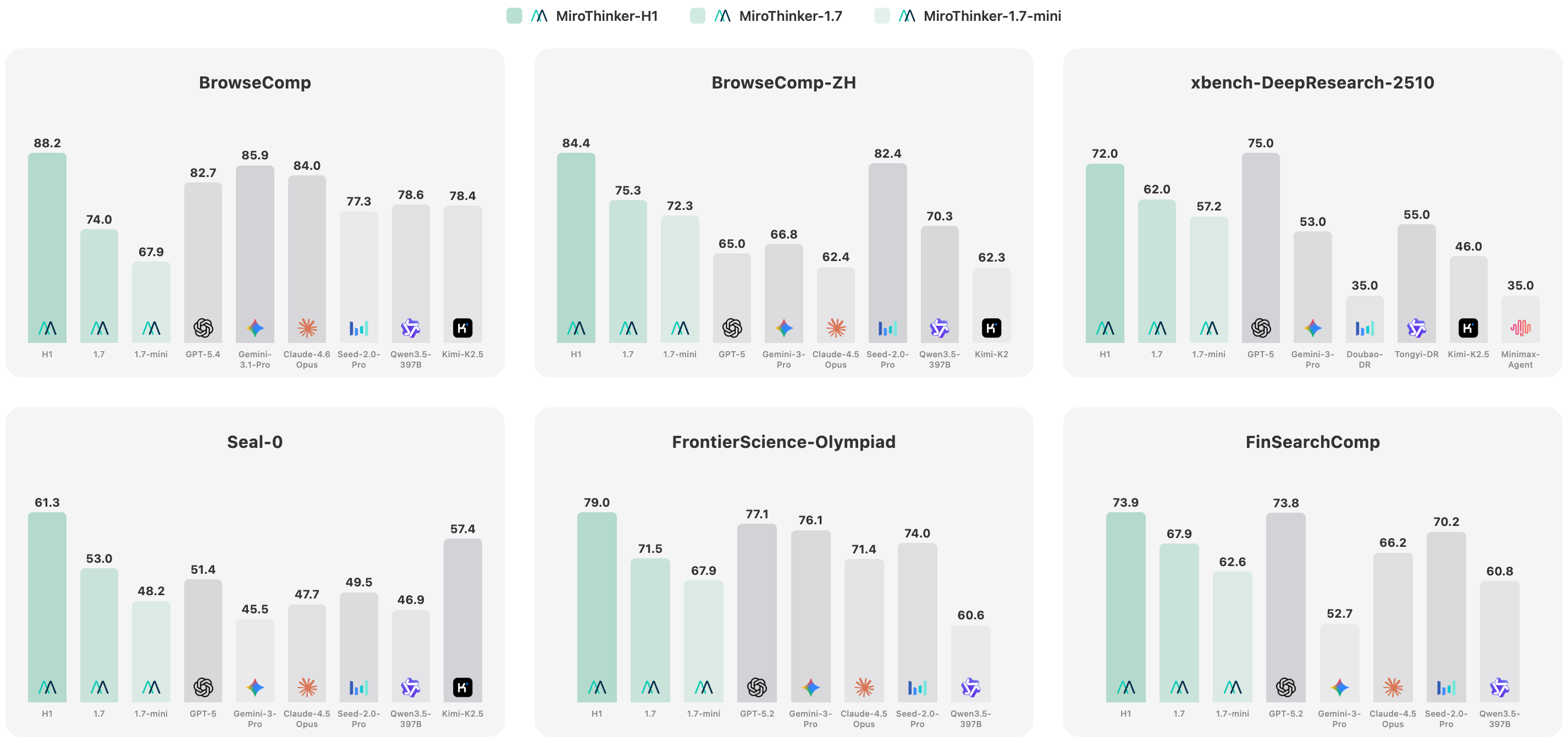
- MiroThinker-1.7 by miromind-ai: A fine-tuned version of Qwen 235B for agentic workflows, especially research.
{kind=link}
-
tabpfn_2_6 by Prior-Labs: An update to the popular tabular prediction model, which is slightly larger than its predecessor. Its license allows research and internal evaluation only.
-
sam3.1 by facebook: An update to SAM 3, carrying the same restrictive license.
-
Holotron-12B by Hcompany: A policy model for CUA agents.
-
LongCat-Flash-Prover by meituan-longcat: A Lean4 fine-tune of the large LongCat model.
-
Leanstral-2603 by mistralai: A Lean4 fine-tune of the new Mistral Small 4.
-
reka-edge-2603 by RekaAI: A model for robotics, beating models such as Cosmos-Reason2. Its noncommercial license converts into Apache 2.0 after two years.
RAG¶
-
Qianfan-OCR by baidu: There have been a lot of great OCR models lately. This one is from Baidu and is licensed under Apache 2.0.
-
chandra-ocr-2 by datalab-to: An update to the Chandra OCR model, released under a restrictive license.
-
Reason-ModernColBERT by lightonai: A SOTA retrieval model released under a non-commercial license. However, there is also code to re-generate the data, allowing the training of a commercially viable version.
-
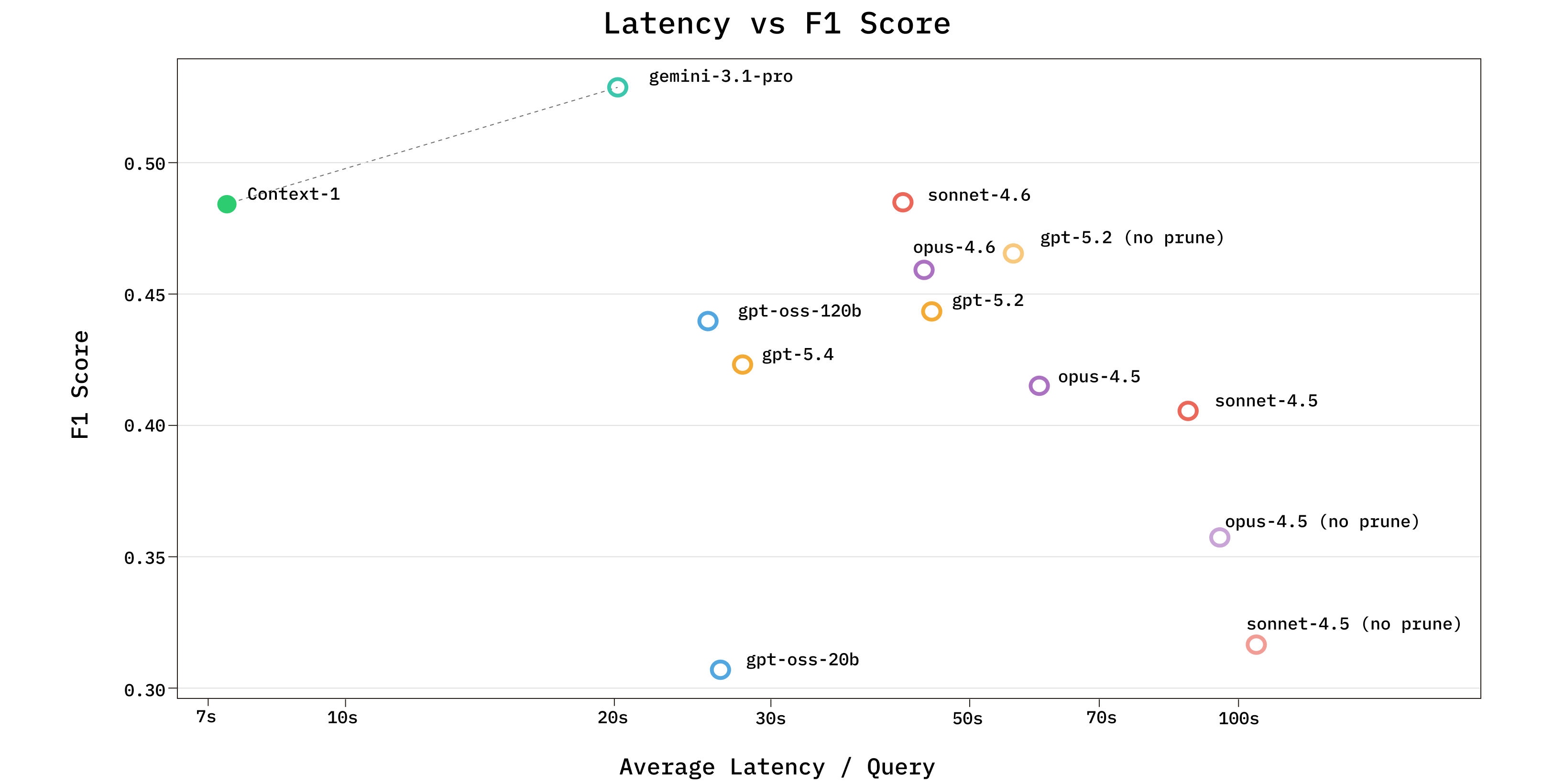
context-1 by chromadb: A fine-tuned version of GPT-OSS for agentic search with an in-depth tech report. It also marks the debut of Chroma into the open model space. Trained with Thinking Machine's Tinker.
{kind=link}
- dots.mocr by rednote-hilab: The beloved dots.ocr model has been updated and supports SVG outputs. However, on top of the general MIT license, the model comes with additional usage restrictions, just like its predecessor.
深度分析¶
1. 开源模型生态的结构性分散¶
本期 Artifacts Log 最显著的特征是模型发布者的高度分散化。与往常被 Qwen、DeepSeek、Kimi 等少数大厂主导的格局不同,本次覆盖的模型来自 NVIDIA、Cohere、Sarvam、Mistral、Zed Industries、IBM、Meituan、百度等二十余个不同的组织,其中不乏首次进入开源模型领域的参与者。这种分散化反映了 AI 模型能力正在从「少数超强模型统治一切」向「大量专用模型各司其职」的结构性转型。大型语言模型依然重要,但行业整体正在向「模型组合」而非「模型单选」的方向演进。
2. LatentMoE 与 NVFP4:量化预训练的新前沿¶
NVIDIA-Nemotron-3-Super-120B-A12B 是本期最值得关注的技术突破。该模型首次在开源模型中采用 NVFP4(NVIDIA FP4)进行预训练,结合 LatentMoE(潜在混合专家)架构,实现了 120B 总参数量但仅 12B 活跃参数的高效配置。1M 的上下文窗口进一步扩展了其适用场景。更重要的是,NVIDIA 同步公开了完整的预训练和后训练数据集,这在开源大模型中属于罕见的透明度。MoE 架构配合超低精度量化训练的组合,暗示了未来中等尺寸高性能模型的一条可行路径。
3. 主权 AI 的实证:Sarvam 的 Indic 语言突破¶
Sarvam(印度创业公司)发布的 105B 和 30B 模型,在 12-16T tokens 的数据集规模上训练,其核心意义不在于参数量的竞争,而在于展示了「主权 AI」的实质性价值。与现有 SOTA 开源模型相比,Sarvam 模型在印度语言(Indic languages)上的偏好度遥遥领先。这揭示了一个被大多数国家尚未充分认识的事实:通用大模型在特定语言和文化场景中的表现存在根本性短板,只有在本土数据上训练的模型才能真正满足主权 AI 的需求。印度此举与全球范围内对数据本地化和 AI 主权的关注形成呼应。
4. 从通用到专用:专用模型的功能域扩张¶
本期覆盖的模型类型远超以往任何一期:从 OCR(RAG 类下的 Qianfan-OCR、chandra-ocr-2、dots.mocr)、语音转文本(cohere-transcribe-03-2026、granite-4.0-1b-speech)、代码编辑(zeta-2)、CUA 代理策略(Holotron-12B)到 Lean4 数学定理证明(LongCat-Flash-Prover、Leanstral-2603),专用模型的疆域正在快速扩张。尤其是多个组织同时在 Lean4 形式化证明领域发力,暗示了 AI for Math 在开源社区正在形成一个新的技术热点。
5. 许可证博弈:开源许可证生态的微妙变化¶
Cohere 将其语音转文本模型从非商业许可证升级为 Apache 2.0,Reka Edge 的非商业许可证承诺两年后转为 Apache 2.0,而大多数 OCR 和专用模型仍然维持限制性许可证。这些不同的许可证策略背后反映了各自不同的生态定位:希望借助社区力量快速迭代的倾向于宽松开源,而需要保护数据优势或商业利益的则维持限制性条款。许可证的多样性本身就是开源模型生态成熟度的一个侧面反映。
实践启示¶
1. 为特定任务域选择专用模型而非追求最大通用模型¶
当业务场景涉及 OCR、语音转录、代码编辑或数学证明等明确任务时,应优先调研本期覆盖的专用模型,而非默认使用通用大模型。例如,需要开源 OCR 能力时,百度 Qianfan-OCR(Apache 2.0)是一个值得优先评估的选项,相比通用模型 + API 的组合,专用模型在特定任务上的精度和成本效率通常更具优势。
2. 关注 LatentMoE + 低精度量化组合的实用价值¶
NVIDIA-Nemotron-3-Super-120B 的技术路径(MoE + NVFP4 预训练)为中等规模组织在自有硬件上部署高性能模型提供了新思路。如果拥有 NVIDIA 兼容硬件,可以参考其技术报告中的预训练/后训练数据集构建流程,探索在自有领域数据上复现类似架构的可行性,以在特定领域获得比通用模型更好的精度的同时控制推理成本。
3. 在多语言或本土化场景中评估 Sarvam 类主权模型¶
对于面向印度市场或需要处理 Indic 语言的应用,Sarvam 模型系列提供了明显优于通用开源模型的表现。在构建多语言产品时,应将目标市场的本地化专用模型纳入评估矩阵,而非假设 GPT-4 或 Qwen 等通用模型能够良好覆盖所有语言。主权 AI 在特定地区的实质性优势是真实存在的工程事实。
4. 利用 Chroma Context-1 提升 RAG 系统的检索质量¶
Chroma 首次进入开源模型领域,发布的 context-1 模型针对代理搜索场景进行了优化,配合 Thinking Machine 的 Tinker 方法进行训练。对于正在构建 RAG 系统的团队,context-1 提供了一个在检索阶段即可引入大模型能力的新选项,有助于减少 RAG 系统中检索与生成两阶段的精度损失。
5. 跟踪 Lean4 形式化证明生态作为 AI for Math 前沿指标¶
多个组织(Meituan、Mistral)同时发布 Lean4 微调模型,表明形式化数学证明正在成为开源 AI 的一个新增长点。对于教育科技或科研自动化领域的从业者,这是一个值得持续关注的技术方向:开源社区在形式化证明上的活跃度通常先于工业应用落地,关注这一生态可以更早识别 AI for Math 的实用化时间点。